







CoTAttention注意力机制
CoTAttention网络是一种用于多模态场景下的视觉问答(Visual Question Answering,VQA)任务的神经网络模型。它是在经典的注意力机制(Attention Mechanism)上进行了改进,能够自适应地对不同的视觉和语言输入进行注意力分配,从而更好地完成VQA任务。
CoTAttention网络中的“CoT”代表“Cross-modal Transformer”,即跨模态Transformer。在该网络中,视觉和语言输入分别被编码为一组特征向量,然后通过一个跨模态的Transformer模块进行交互和整合。在这个跨模态的Transformer模块中,Co-Attention机制被用来计算视觉和语言特征之间的交互注意力,从而实现更好的信息交换和整合。在计算机视觉和自然语言处理紧密结合的VQA任务中,CoTAttention网络取得了很好的效果。
论文地址:https://arxiv.org/pdf/2107.12292.pdf
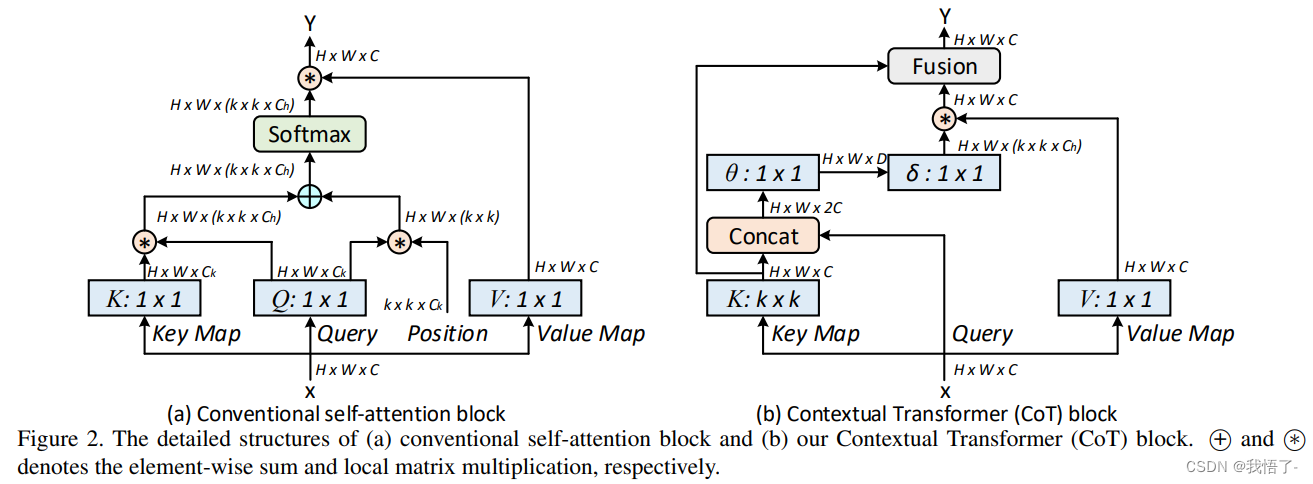
代码如下:
import numpy as np
import torch
from torch import flatten, nn
from torch.nn import init
from torch.nn.modules.activation import ReLU
from torch.nn.modules.batchnorm import BatchNorm2d
from torch.nn import functional as F
class CoTAttention(nn.Module):
def __init__(self, dim=512, kernel_size=3):
super().__init__()
self.dim = dim
self.kernel_size = kernel_size
self.key_embed = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=kernel_size, padding=kernel_size // 2, groups=4, bias=False),
nn.BatchNorm2d(dim),
nn.ReLU()
)
self.value_embed = nn.Sequential(
nn.Conv2d(dim, dim, 1, bias=False),
nn.BatchNorm2d(dim)
)
factor = 4
self.attention_embed = nn.Sequential(
nn.Conv2d(2 * dim, 2 * dim // factor, 1, bias=False),
nn.BatchNorm2d(2 * dim // factor),
nn.ReLU(),
nn.Conv2d(2 * dim // factor, kernel_size * kernel_size * dim, 1)
)
def forward(self, x):
bs, c, h, w = x.shape
k1 = self.key_embed(x) # bs,c,h,w
v = self.value_embed(x).view(bs, c, -1) # bs,c,h,w
y = torch.cat([k1, x], dim=1) # bs,2c,h,w
att = self.attention_embed(y) # bs,c*k*k,h,w
att = att.reshape(bs, c, self.kernel_size * self.kernel_size, h, w)
att = att.mean(2, keepdim=False).view(bs, c, -1) # bs,c,h*w
k2 = F.softmax(att, dim=-1) * v
k2 = k2.view(bs, c, h, w)
return k1 + k2
if __name__ == '__main__':
input = torch.randn(50, 512, 7, 7)
cot = CoTAttention(dim=512, kernel_size=3)
output = cot(input)
print(output.shape)

















 4589
4589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











