







EMA注意力机制
EMA注意力机制,基于跨空间学习的高效多尺度注意力模块,ICASSP2023推出,效果优于ECA、CBAM、CA ,小目标涨点明显。
论文地址:Efficient Multi-Scale Attention Module with Cross-Spatial Learning
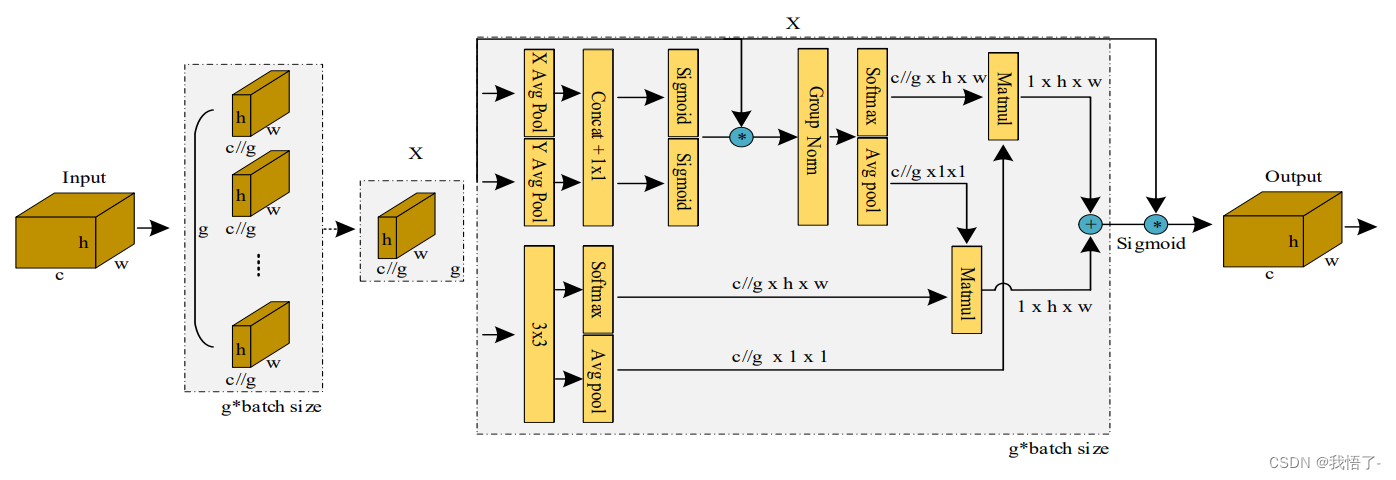

在各种计算机视觉任务中,通道或空间注意力机制在产生更清晰的特征表示方面的显著有效性得到了证明。然而,通过通道降维来建模跨通道关系可能会给提取深度视觉表示带来副作用。提出了一种新的高效的多尺度注意力(EMA)模块。以保留每个通道上的信息和降低计算开销为目标,将部分通道重塑为批量维度,并将通道维度分组为多个子特征,使空间语义特征在每个特征组中均匀分布。具体来说,除了对全局信息进行编码以重新校准每个并行分支中的通道权重外,还通过跨维度交互进一步聚合两个并行分支的输出特征,以捕获像素级成对关系。对图像分类和目标检测任务进行了广泛的消融研究和实验,使用流行的基准(如CIFAR-100、ImageNet-1k、MS COCO和VisDrone2019)来评估其性能。
代码实现:
import torch
from torch import nn
class EMA(nn.Module):
def __init__(self, channels, factor=8):
super(EMA, self).__init__()
self.groups = factor
assert channels // self.groups > 0
self.softmax = nn.Softmax(-1)
self.agp = nn.AdaptiveAvgPool2d((1, 1))
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups)
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1, padding=0)
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1, padding=1)
def forward(self, x):
b, c, h, w = x.size()
group_x = x.reshape(b * self.groups, -1, h, w) # b*g,c//g,h,w
x_h = self.pool_h(group_x)
x_w = self.pool_w(group_x).permute(0, 1, 3, 2)
hw = self.conv1x1(torch.cat([x_h, x_w], dim=2))
x_h, x_w = torch.split(hw, [h, w], dim=2)
x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid())
x2 = self.conv3x3(group_x)
x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x12 = x2.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x22 = x1.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)
return (group_x * weights.sigmoid()).reshape(b, c, h, w)



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











