







注意力机制:
父母在学校门口接送孩子的时候,可以在人群中一眼的发现自己的孩子,这就是一种注意力机制。
为什么父母可以在那么多的孩子中,找到自己的孩子?
比如现在有100个孩子,要被找的孩子发型是平头,个子中等,不戴眼镜,穿着红色上衣,牛仔裤
通过对这些特征,就可以对这100个孩子进行筛选,最后剩下的孩子数量就很少了,就是这些特征的存在,使得父母的注意力会主要放在有这些特征的孩子身上,这就是注意力机制。
注意力机制
Query 被找孩子的特征
Key 100个孩子,通过特征进行筛选,得到这100个孩子的可能性
Value 100个孩子中,找到自己孩子的可能性
attention = softmax(Q、K之间进行计算) * V
Q、K之间的计算方式不同,这就导致了不同的注意力机制。

最后一种就是Transformer中的一种注意力的计算机制。
实际应用中的理解
一般在自然语言处理应用里会把Attention模型看作是输出Target句子中某个单词和输入Source句子每个单词的对齐模型。
目标句子的每个单词 与输入句子中的每个单词 计算权重,计算注意力权重
类似于机器翻译中的短语对齐步骤
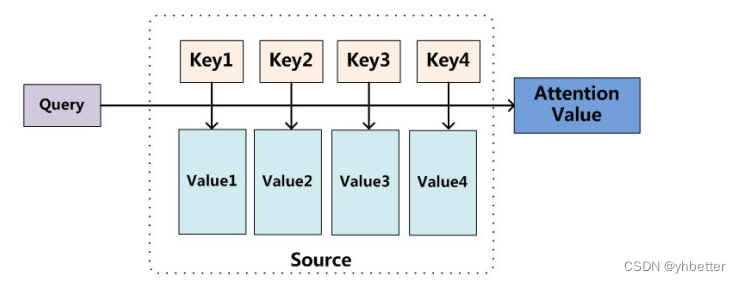
可以看到里面的 Q K V
QK之间的计算就是计算QK之间的相关性,或者说特征的相似性
这样就可以得到每个key对应的value的权重系数,然后与V相乘
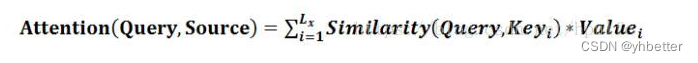
Lx=||Source||代表Source的长度
计算过程
1.计算QK之前的相似度

2.softmax 归一化
3.对value进行加权求和**
代码实现
第一步:根据注意力计算规则,对Q,K,V进行相应的计算.
第二步:根据第一步采用的计算方法,如果是拼接方法,则需要将Q与第二步的计算结果再进行拼接,如果是转置点积,一般是自注意力,Q与V相同,则不需要进行与Q的拼接.
第三步:最后为了使整个attention机制按照指定尺寸输出,使用线性层作用在第二步的结果上做一个线性变换,得到最终对Q的注意力表示
第一步就是使用第一种计算的方式,获取注意力机制的权重,就是上边所说的孩子的特征占100个孩子权重
第三部就是为了获得指定尺寸的输出
import torch
from torch import nn
import torch.nn.functional as F
# input = torch.randn(10, 3, 4)
# mat2 = torch.randn(10, 4, 5)
# res = torch.bmm(input, mat2)
# x = res.size()
# print(x)
class Attention(nn.Module):
def __init__(self,query_size, key_size, value_size1, value_size2, output_size):
super(Attention, self).__init__()
self.query_size = query_size
self.key_size = key_size
self.value_size1 = value_size1
self.value_size2 = value_size2
self.output_size = output_size
# 第一种方式
# 先拼接 然后进行线性变换 然后softmax
# 最后乘V
# 初始化注意力机制第一步
# 两个size相加,是直接把矩阵拼接
# 拼接后进行线性变换使用 (64,32)
self.attn = nn.Linear(self.query_size + self.key_size, self.value_size1)
# 最后乘V后 输出使用
# 初始化注意力机制第三步
# 线性变换 (96,64)
self.attn_combine = nn.Linear(self.query_size + self.value_size2, self.output_size)
# Q K 都是三维数据 维度是相同的 (1,1,32)
def forward(self, Q, K, V):
# 采用上述第一种计算规则
# 先进性QK的拼接以及线性变换,再经过softmax处理获得结果
# 这里QKV都是三维张量
# (1,32) (1,32) 在维度1 上的cat的维度为(1,64)
# (1,64) * (64,32)
# 结果为(1,32) 这是第一个线性变换的结果 然后在32这个维度上进行 softmax 最后的维度还是不变的
attn_weights = F.softmax(self.attn(torch.cat((Q[0], K[0]), 1)), dim=1)
# 然后将结果 与 V相乘 (1,1,32) @ (1,32,64)= (1,1,64)
attn_applied = torch.bmm(attn_weights.unsqueeze(0), V)
# 第二步,将Q与第一步的结果再进行拼接
# (1,32) (1,64) 在第1个维度进行拼接 结果为(1,96)
output = torch.cat((Q[0], attn_applied[0]), 1)
# (1,96) * (96,64)=(1,64)
# 经过unsqueeze (1,1,64)
# 第三步,得到输出
output = self.attn_combine(output).unsqueeze(0)
return output, attn_weights
# (1, 1, 64) (1,32)
query_size = 32
key_size = 32
value_size1 = 32
value_size2 = 64
output_size = 64
attn = Attention(query_size, key_size, value_size1, value_size2, output_size)
Q = torch.randn(1, 1, query_size)
print("---")
K = torch.randn(1, 1, key_size)
print(torch.cat((Q[0], K[0]), 1).shape)
V = torch.randn(1, value_size1, value_size2)
out = attn(Q, K, V)















 4589
4589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









