







CloAttention注意力机制
CloAttention注意力机制是由YOLOv8推出的CloFormer和EfficientAttention构成的,CloFormer 引入了AttnConv,这是一种结合了注意力机制和卷积运算的模块,能够捕捉高频的局部信息。相比于传统的卷积操作,AttnConv 使用共享权重和上下文感知权重,能够更好地处理图像中不同位置之间的关系。实验结果表明,CloFormer 在图像分类、目标检测和语义分割任务中具有优越的性能。
论文地址:Rethinking Local Perception in Lightweight Vision Transformer
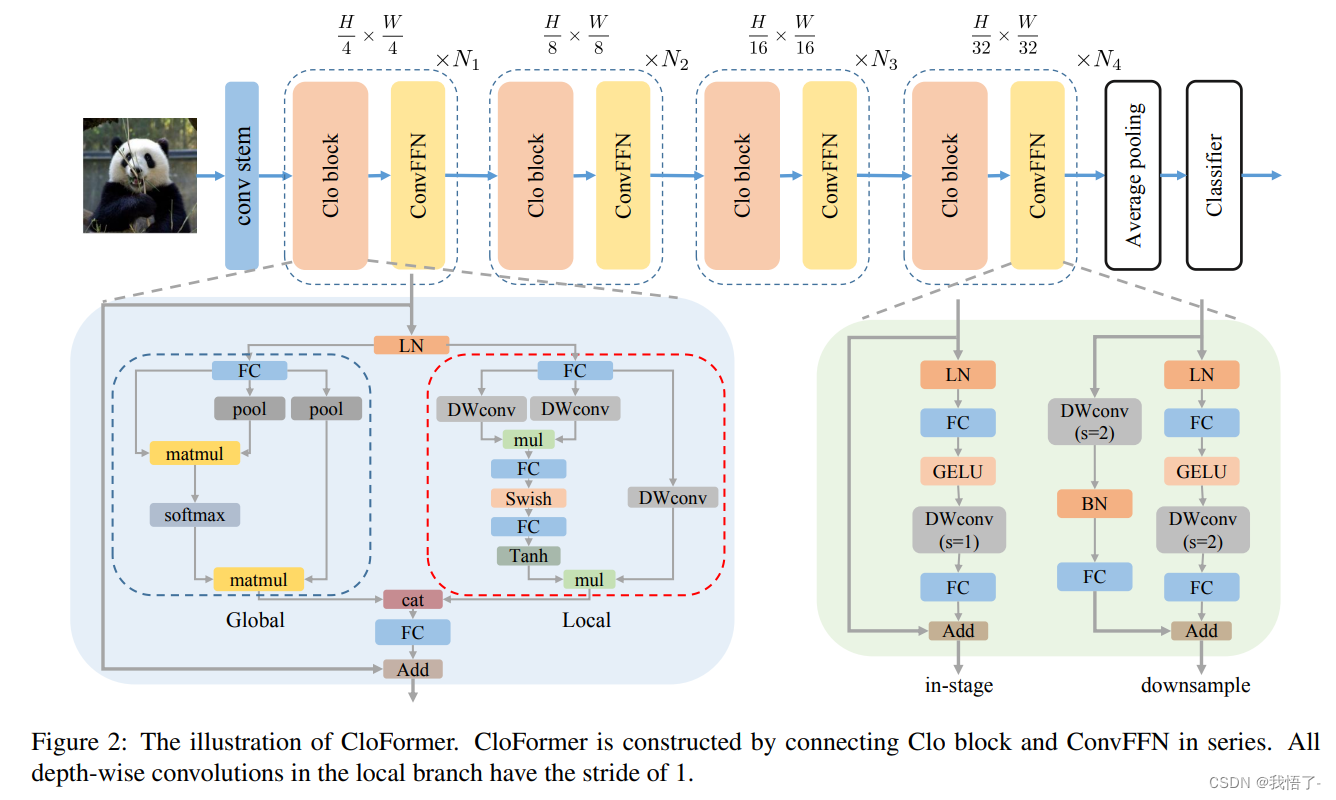
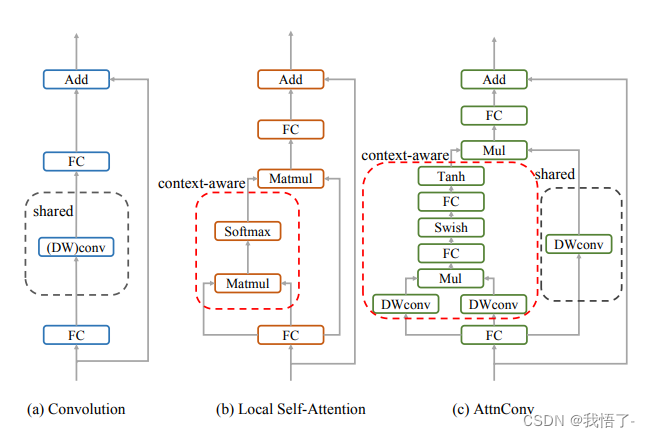
代码实现:
import torch
import torch.nn as nn
from efficientnet_pytorch.model import MemoryEfficientSwish
class AttnMap(nn.Module):
def __init__(self, dim):
super().__init__()
self.act_block = nn.Sequential(
nn.Conv2d(dim, dim, 1, 1, 0),
MemoryEfficientSwish(),
nn.Conv2d(dim, dim, 1, 1, 0)
)
def forward(self, x):
return self.act_block(x)
class EfficientAttention(nn.Module):
def __init__(self, dim, num_heads=8, group_split=[4, 4], kernel_sizes=[5], window_size=4,
attn_drop=0., proj_drop=0., qkv_bias=True):
super().__init__()
assert sum(group_split) == num_heads
assert len(kernel_sizes) + 1 == len(group_split)
self.dim = dim
self.num_heads = num_heads
self.dim_head = dim // num_heads
self.scalor = self.dim_head ** -0.5
self.kernel_sizes = kernel_sizes
self.window_size = window_size
self.group_split = group_split
convs = []
act_blocks = []
qkvs = []
#projs = []
for i in range(len(kernel_sizes)):
kernel_size = kernel_sizes[i]
group_head = group_split[i]
if group_head == 0:
continue
convs.append(nn.Conv2d(3*self.dim_head*group_head, 3*self.dim_head*group_head, kernel_size,
1, kernel_size//2, groups=3*self.dim_head*group_head))
act_blocks.append(AttnMap(self.dim_head*group_head))
qkvs.append(nn.Conv2d(dim, 3*group_head*self.dim_head, 1, 1, 0, bias=qkv_bias))
#projs.append(nn.Linear(group_head*self.dim_head, group_head*self.dim_head, bias=qkv_bias))
if group_split[-1] != 0:
self.global_q = nn.Conv2d(dim, group_split[-1]*self.dim_head, 1, 1, 0, bias=qkv_bias)
self.global_kv = nn.Conv2d(dim, group_split[-1]*self.dim_head*2, 1, 1, 0, bias=qkv_bias)
#self.global_proj = nn.Linear(group_split[-1]*self.dim_head, group_split[-1]*self.dim_head, bias=qkv_bias)
self.avgpool = nn.AvgPool2d(window_size, window_size) if window_size!=1 else nn.Identity()
self.convs = nn.ModuleList(convs)
self.act_blocks = nn.ModuleList(act_blocks)
self.qkvs = nn.ModuleList(qkvs)
self.proj = nn.Conv2d(dim, dim, 1, 1, 0, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj_drop = nn.Dropout(proj_drop)
def high_fre_attntion(self, x: torch.Tensor, to_qkv: nn.Module, mixer: nn.Module, attn_block: nn.Module):
'''
x: (b c h w)
'''
b, c, h, w = x.size()
qkv = to_qkv(x) #(b (3 m d) h w)
qkv = mixer(qkv).reshape(b, 3, -1, h, w).transpose(0, 1).contiguous() #(3 b (m d) h w)
q, k, v = qkv #(b (m d) h w)
attn = attn_block(q.mul(k)).mul(self.scalor)
attn = self.attn_drop(torch.tanh(attn))
res = attn.mul(v) #(b (m d) h w)
return res
def low_fre_attention(self, x : torch.Tensor, to_q: nn.Module, to_kv: nn.Module, avgpool: nn.Module):
'''
x: (b c h w)
'''
b, c, h, w = x.size()
q = to_q(x).reshape(b, -1, self.dim_head, h*w).transpose(-1, -2).contiguous() #(b m (h w) d)
kv = avgpool(x) #(b c h w)
kv = to_kv(kv).view(b, 2, -1, self.dim_head, (h*w)//(self.window_size**2)).permute(1, 0, 2, 4, 3).contiguous() #(2 b m (H W) d)
k, v = kv #(b m (H W) d)
attn = self.scalor * q @ k.transpose(-1, -2) #(b m (h w) (H W))
attn = self.attn_drop(attn.softmax(dim=-1))
res = attn @ v #(b m (h w) d)
res = res.transpose(2, 3).reshape(b, -1, h, w).contiguous()
return res
def forward(self, x: torch.Tensor):
'''
x: (b c h w)
'''
res = []
for i in range(len(self.kernel_sizes)):
if self.group_split[i] == 0:
continue
res.append(self.high_fre_attntion(x, self.qkvs[i], self.convs[i], self.act_blocks[i]))
if self.group_split[-1] != 0:
res.append(self.low_fre_attention(x, self.global_q, self.global_kv, self.avgpool))
return self.proj_drop(self.proj(torch.cat(res, dim=1)))

















 4479
4479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











