







一 前言
在前一篇文章 机器学习之回归(Regression)再理解 中小编提到了梯度下降,我们知道在设定好损失函数后,只要loss函数是可微分的,我们就可以通过Gradient Descent 进行参数优化,不断的调整参数的值,使得loss函数的值越来越小。
 梯度下降参数更新 梯度下降参数更新
|
 梯度下降参数更新 梯度下降参数更新
|
在参数更新的过程中有一个参数很重要,那就是学习率 learning rate,学习率的大小对模型能否很好的收敛有很大影响,若学习率太大,参数可能会在loss最低点附近来回震荡甚至还会导致loss越来越大;反之若学习率太小,那么参数的更新速率就很慢,模型训练的时间很长。因此我们需要选择一个合适的学习率!但是就算我们在网络一开始的训练中选择了一个合适的learning rate,这个一成不变的学习率真的好吗?真的一直符合训练的要求吗?
答案显然是否定的 !
就算一开始选择的学习率是合适的,但是随着训练的进行,这样的学习率也是不再符合之后的训练;并且在调整参数的时候,不同的参数其更新时所采用的学习率也各不相同。因此,我们平时在使用梯度下降的时候常常会动态调节学习率的大小 (Adaptive learning rate)。常识告诉我们,刚开始训练的时候,当前点距离最优点会比较远,所以一开始训练的时候学习率可以大一点,而在训练了几个epoch之后,我们距离最优点就比较近了,所以此时步子放慢一点,学习率就小一点。关于 Adaptivate learning rate,这其中有一系列的方法,这里我们就介绍最简单的一种——AdaGrad。
二 自适应梯度算法之AdaGrad
一句话概括AdaGrad算法:设置全局学习率之后,参数更新时需要除以该参数之前所有微分值平方和的平方根,示意图如下:
 AdaGrad 参数更新 AdaGrad 参数更新
|
 AdaGrad 参数更新 AdaGrad 参数更新
|
相信大家很好理解,那么AdaGrad算法会带来哪些效果呢?一共这么几点:1. 学习率的动态变化,显然随着参数的不断更新,上图中 σ \sigma σ 是不断的变化的。2. 不同参数有不同的学习率,这一点也很好理解, loss函数对不同参数求偏微分得到的值是不一样的,所以不同参数的除以的值也各不相同,最终得到的学习率的值也各不相同。3. AdaGrad的数学形式意味着,若该参数的更新的幅度比较大或者说变动比较大,则该参数此时的学习率较小,若参数的变化比较小或者说比较平稳,此时学习率就会较大 (简单来说就是越崎岖,步伐越小;越平滑,步伐越大)
AdaGrad虽好,但也是有问题的。AdaGrad会记录之前所有的微分值,因此学习越深入,更新的幅度就会越小。实际上若无止境的学习下去,最终参数的更新量就会无穷接近0,也就是参数无法再继续更新。(这个问题可以被 RMSProp 解决,RMSProp并不是一视同仁的将过去所有的梯度都用起来,而是会逐渐的遗忘过去的梯度)
在Adaptive learning rate 中除了AdaGrad (2011年提出)算法还有其他几种常用的算法——RMSProp (2013年提出)、Adam (2015正式提出,实际出来的时间是2014年),关于这些算法,这里就不再详细的说明,找时间小编会专门说一说的。
 RMSProp RMSProp
|
 Adam Adam
|
目前来说Adam算法应该是最优秀的optimizer,它在训练初期loss下降的速度较快,唯一不太优秀的就是最终模型收敛的值不是太好,而SGDM算法最终收敛的值较低并且比较稳定,所以现在有些人在训练的时候采用 begin with Adam, end with SGDM的策略进行训练。
三 随机梯度下降法SGD
随机梯度下降 SGD,全称Stochastic Gradient Descent,SGD和传统的梯度下降算法的不同就在于参数更新时的损失函数不一样。传统梯度下降的方法中 我们会统计所有样本的损失值,并将其累加求和,之后根据这个值求偏导再进行参数的更新,但是这样做有一个缺点,那就是如果样本数量太大,那这个计算的过程就会非常的耗时。所以SGD就没有统计所有样本的损失值,而是从所有样本中随机挑选出一个样本 (随机梯度下降中的随机二字就来源于此),计算这个样本的loss,然后根据这个样本的loss值求偏导进行参数的更新。
 SGD SGD
|
 SGD SGD
|
从上面右图我们可以看出SGD相比于传统的梯度下降法,优点是很快。但是SGD有一个缺点,在挑选样本计算loss的时候,这个loss有很大的随机性。有时候我们选择了一个样本,若该样本是一个噪声,那么如果我们以该样本为依据进行参数更新,此时显然参数更新的方向是错的。因此SGD在解决某些问题上可能有较好的性能,但是在解决某些问题时,其表现就像是一个喝醉了酒的醉汉,走的跌跌撞撞,前进的速度反而不快。
针对这个问题,人们又提出mini-batch SGD,其大致意思就是:既然传统的梯度下降统计了所有样本的损失值,这太慢了,而SGD又只用了一个样本,随机性太强,那我就折中一下吧,我选择一部分的样本来计算loss,这样不至于太慢,又不至于随机性太强。
在SGD的基础上提出来SGDM (Stochastic Gradient Descent with Momentum) 带动量的随机梯度下降算法,这里就不详细说了,见下图。
 SGD SGD
|
 SGD SGD
|
四 特征缩放 Feature Scaling
在使用Gradient Descent时,特征缩放是一个实用的小tip,可以帮助模型尽快的收敛。
我们举一简单的例子,如下是一个线性回归的例子,假设函数是
y
=
w
1
∗
x
1
+
w
2
∗
x
2
+
b
y = w1 * x1 + w2 * x2 + b
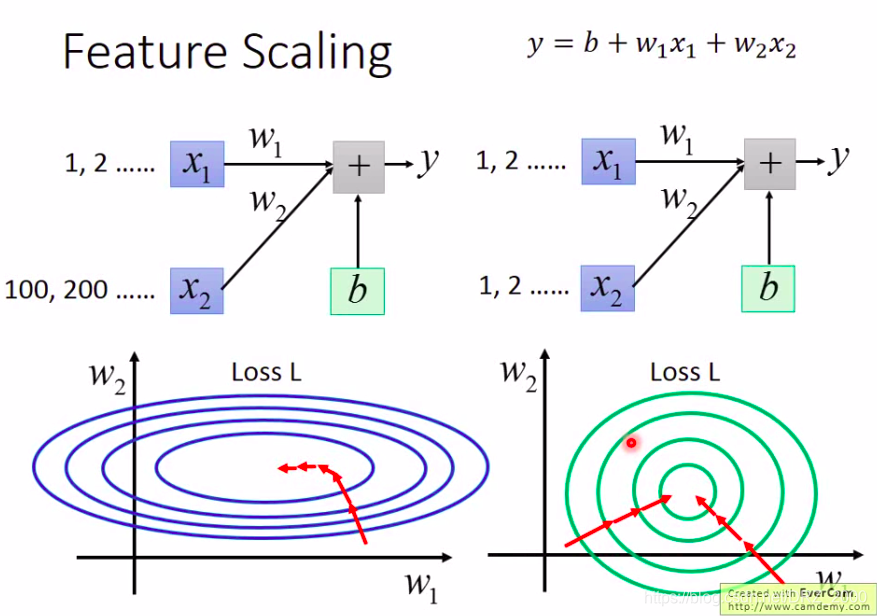
y=w1∗x1+w2∗x2+b,其中输入的x1的值相对于x2的值小很多,那么显然在进行参数调整时,若w2改动一点点,对整个结果的值会有比较大的影响。我们画出这个loss函数的等高线图像,显然是一个椭圆。这样的话,在进行参数调整时,第一,这样两个参数需要不同的学习率,若采用固定的学习率是不行的,我们需要用诸如AdaGrad这样的optimizer;第二,模型最终收敛所需要的时间也比较长。而若我们进行特征缩放,即对输入的x2的值进行调整,得到如下图右侧的结果,此时loss等高线是一个圆形。这对模型的训练是有好处的,上面的说的两个问题也都会很好的解决。
那么我们应该如何进行特征缩放呢?特征缩放的方法有很多,这里介绍一种常见的方式
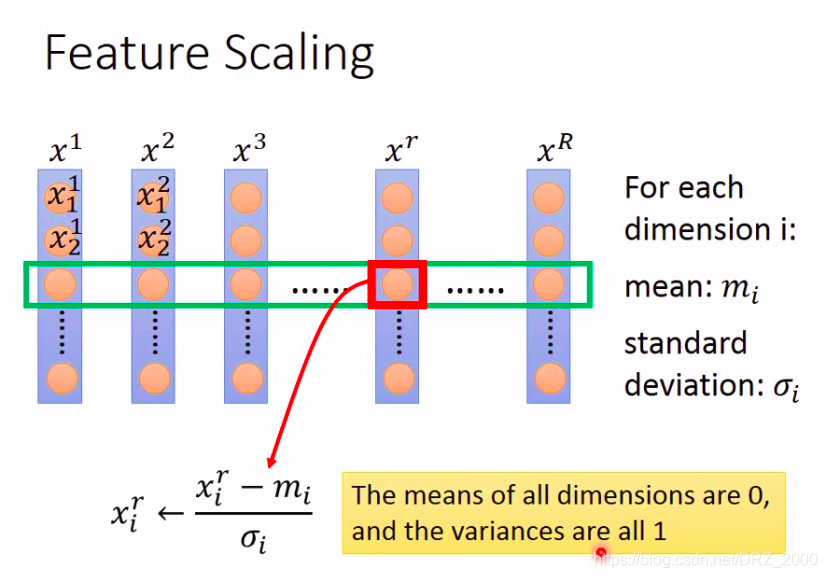
如上图,现在我们手上有
X
1
X^1
X1,
X
2
X^2
X2 …
X
R
X^R
XR共R个样本,每一个样本中有若干个元素 (这里需要弄清楚昂,R是样本的个数,其中每一个样本中都有多个元素,这些元素就是
y
=
w
1
∗
x
1
+
w
2
∗
x
2
+
b
y = w1 * x1 + w2 * x2 + b
y=w1∗x1+w2∗x2+b 中的x1, x2,也就是上图中同一列中的元素),现在我们需要对所有样本中的X2的值进行特征缩放,那么具体的做法就是:求出所有X2分布的均值和标准差,然后对于每一个样本中的X2,都将其减去均值再除以均方差 (其实和将非标准正态分布转换为标准正态分布的做法是一样的),这样操作之后,得到的所有样本中的X2值的均值都为0,标准差都为1。
五 Gradient Descent 背后的数学原理 (重要!!!)
这个部分写着写着就很多,为了避免文章太长,小编就放在另一篇文章里面:
Gradient Descent 背后的数学原理 ,在里面详细介绍了梯度下降中参数更新公式的推导过程。
六 结束语
- 本文中的所有图片均来自于台湾大学李宏毅教授 2020 machine learning 课程中的PPT。
- 小编目前毕竟还是本科生,若文章有问题,欢迎大家在评论区中指出。
- 文章编写不易,若对您有帮助,希望您可以点一个小小的赞。路漫漫其修远兮,吾将上下而求索,与君共勉 !!!














 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









