







Project:LERF: Language Embedded Radiance Fields
Author:UC Berkeley
摘要
人类使用自然语言来描述物理世界,并基于广泛的属性来指代特定的三维位置:视觉外观、语义、抽象联想或可操作的启示。在这项工作中,我们提出了Language Embedded Radiance Fields(LERF),这是一种将Language embedding嵌入到NeRF的方法。LERF在NeRF中学习了一个dense、多尺度的language field,通过沿着训练射线进行体素渲染CLIP embedding,跨训练视图监督这些embedding,以提供多视图的一致性和平滑language field。
方法
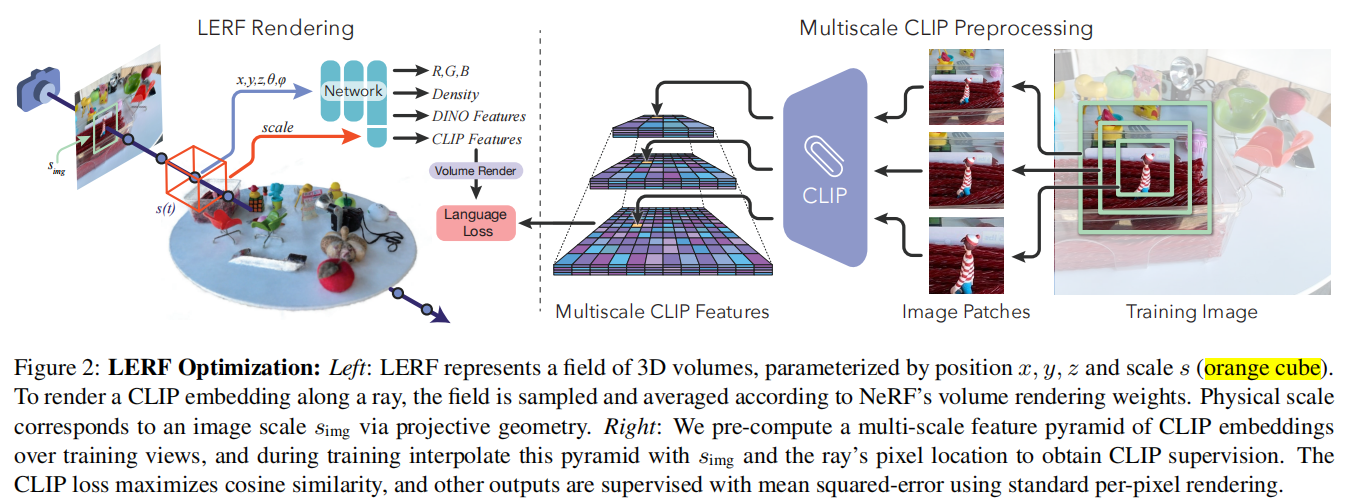
整体框架如上,对一个场景,作者渲染了两个field,一个是basic NeRF,一个是language field。
训练时,NeRF网络与基础的NeRF相同,渲染language field到一个image时,采用了[1][2]的技巧,但是增加了一个 scale 参数,具体细节需要看代码。对于一个crop image对应光线的训练,使用多个尺度下的crop image的clip embedding当作gt(使用线性插值整合到一起),然后以此来监督渲染出的language image。
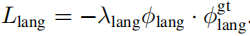
language field在整个field中充满的是language embedding,给定一个pose,language field渲染出一个language image,NeRF渲染出来一个color image 。在推理时,给定一个query,转换成embedding,就可以与language image计算relevancy score(相关性分数)。有了relevancy score后,就可以可视化在对应的color image 上。relevancy score计算方式:

与[1]相同,LERF在训练language field时,加了一个MLP输出了DINO feature,目的是利用DINO在无监督学习时对object进行解耦的能力。
个人认为,本文最创新的点就是:提出了language field的概念,并给出了一种训练language field的方法。(作者启发于[1]的feature field的概念,将language feature嵌入进field中。)
Limitations
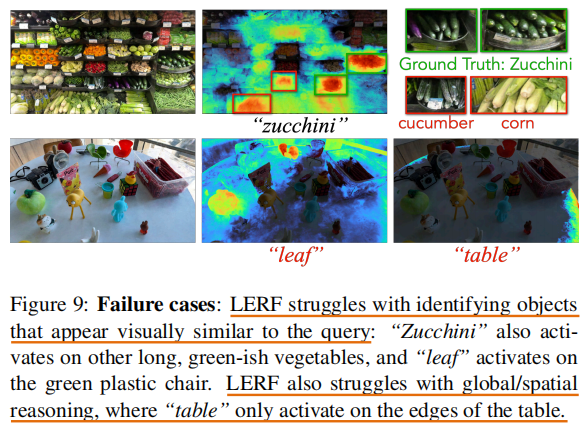
对于语义信息相似的物体,LERF会出错,并且它很难捕获objects的空间关系;
原因分析:首先在训练时,LERF是将每一个crop image对应的CLIP embedding学习进language field,但是这个CLIP embedding只是这些crop images对应的语义信息(即使multi-scale,但也只是multi-scale上的语义信息),所以最后学习到的language field中的每一个空间位置Ο,包含的只是该空间位置Ο(x,y,z)处对应的语义信息s(比如,类别、颜色是什么),并不包含该位置Ο在空间中的关系r(比如,当前位置Ο在另一个目标(沙发)前面n米,或在沙发的左侧)。如果能在训练language field时考虑属性r的监督,则有可能解决这个问题(multi-scale的embedding这里或许不是很合适,how to represent 3d spatial relations)。
这也是为什么LERF的query只是一个一个的单词,就是因为该方法只能捕捉语义信息,并以此来进行查询。所以该文章与3D Visual Grounding的工作还是有区别的,3D Visual Grounding的工作是可以从一句话中捕捉目标的空间位置信息,并align到3D vision中的。
3D Visual Grounding 任务:

也没必要非得用NeRF来进行场景表征,也可以用Transformer来进行,在其中加入空间位置的理解。
参考:
[1] Kobayashi S, Matsumoto E, Sitzmann V. Decomposing nerf for editing via feature field distillation[J]. arXiv preprint arXiv:2205.15585, 2022.
[2] Zhi S, Laidlow T, Leutenegger S, et al. In-place scene labelling and understanding with implicit scene representation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 15838-15847.















 2470
2470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









