







Fast R-CNN
Abstract
Fast R-CNN 最主要解决的问题是如何快速地对提取的候选区进行分类
Introduction
object detection 模型需要给出物体的精确定位,所以其模型的复杂度主要有两个原因导致:
- 需要检测出很多的物体可能存在的候选区域
- 对检测出的候选区域进行调整才能得到较为准确的定位
处理这两个问题通常就会牺牲速度,模型的简洁性
本文终于不用 SVM 进行分类了,不用单独训练 SVM,本文将所有的组件都融合在一个训练流水线中了,可以同时训练所有模块。
在 R-CNN 中,训练是分散的:需要训练用于提取特征的 CNN,用于分类的 SVM,用于回归的回归器
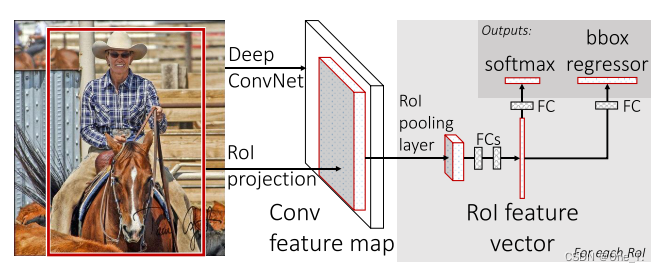
fast R-CNN 整体流程:
- 首先还是通过 SS 算法在原始图像上提取出大约2000个候选区域
- 对原始图像经过一次 CNN 得到全图特征图,该过程对一张图像只进行一次,和 R-CNN 相比,共享了参数,提高了速度
- 将每一个基于原图提取出的候选区域通过一个方法映射到对应的特征图上,将该映射区进行 ROI pooling 操作(其实就是单一 level 的 SPP)得到更小的特征图。因为该层的功能和 SPP 很相似,所以不管映射区的尺度,最后都得到的是统一大小的特征图
- 将经过 ROI pooling 处理过后的更小的特征图拉直,经过若干个全连接层,就可以得到图中红色的 ROI feature vector
- 对 vector 并行两路操作,一路进行该候选区的分类,一路对该候选区进行粗定位(后面还会精调位置)
fast R-CNN 相比于 SPPNet,进一步整合了端到端的模块,摆脱了 SVM,现在整个网络结构只有 SS 模块没有整合进整个训练流水线,所以 Faster R-CNN 就是把 SS 模块给去除了,并用 RPN 代替,最终完成了端到端的训练。
候选区分类
这个很简单,就是将 feature vector 通过 softmax 输出 k+1 维向量,k 为类别数,再加上一个背景类。得到 p=(p0, p1, p2, pk),一般 p0表示背景类别
候选区定位
将 ROI pooling 层得到的 feature vector,通过全连接层影射到 4*k维向量,为每一个类别预测一个回归框。 t i = ( t x i , t y i , t w i , t h i ) t^i = (t^i_x, t^i_y, t^i_w, t^i_h) ti=(txi,tyi,twi,thi) i=1,2,…k
这里的每个参数并不直接等于坐标值或者宽高,而是和对应x,y,w,相关的某个参数。
Multi-task Loss
每一个 ROI 都会被标注为一个类别 u 和一个 bounding box回归向量 v. 总体的 loss 有两部分组成:分类误差和回归误差
L ( p , u , t u , v ) = L c l s ( p , u ) + λ [ u ≥ 1 ] L l o c ( t u , v ) L(p,u,t^u,v)=L_{cls}(p,u)+\lambda[u\geq1]L_{loc}(t^u,v) L(p,u,tu,v)=Lcls(p,u)+λ[u≥1]Lloc(tu,v)
L c l s ( p , u ) L_{cls}(p,u) Lcls(p,u) 就是交叉熵损失,当 u ≥ 1 u\geq1 u≥1 时, λ = λ \lambda=\lambda λ=λ ,否则, λ = 0 \lambda=0 λ=0 。所以,如果该 ROI 的标签为背景则不用考虑定位误差。对于 L l o c L_{loc} Lloc 的具体定义如下:
L l o c ( t u , v ) = ∑ i ∈ { x , y , w , h } s m o o t h L 1 ( t i u − v i ) L_{loc}(t^u,v)=\sum\limits_{i\in \{x,y,w,h\}}smooth_{L_{1}}(t^u_i-v_i) Lloc(tu,v)=i∈{x,y,w,h}∑smoothL1(tiu−vi)
其中 s m o o t h L 1 ( x ) = { 0.5 x 2 i f ∣ x ∣ > 1 ∣ x ∣ − 0.5 o t h e r w i s e smooth_{L_1}(x)=\begin{cases}0.5x^2&if\ \lvert x \rvert >1\\ \lvert x \rvert -0.5&otherwise\end{cases} smoothL1(x)={0.5x2∣x∣−0.5if ∣x∣>1otherwise 利用该函数计算定位误差
总结:所有的 ROI 都计算分类误差,只有标签为前景的 ROI 才计算定位误差,每一个 ROI 会给除了背景以外的每一个类别预测一个四维回归向量,但是在计算定位误差时,只会用到对应标签类别 u 的那个四维向量和目标值 v 计算误差。损失函数为 s m o o t h L 1 smooth_{L_{1}} smoothL1 函数。
本文中,对每张图像采样 64个 ROI, 25 % 25\% 25% 为正样本, 75 % 75\% 75% 为负样本,正样本是 候选区和 ground truth 的 IOU 大于 thresh的,负样本是 候选区和 ground truth 的 IOU 小于于 thresh的。
测试阶段
测试阶段就不是只用64个ROI了,而是所有提取出的大约2000个 ROI,每一个 ROI 最终会输出一个类别概率分布和 k个回归向量,对这2000个 ROI 分别针对每个类别进行 NMS 极大值抑制,最终画出预测框。
Experiment
通过实验发现,并不是提取越多的候选框越能提升 mAP 值,超过某种界限后,反而会损失精度。

es\image-20220520153026996.png" alt=“image-20220520153026996” style=“zoom:80%;” />















 7307
7307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









