







 Faster R-CNN是目标检测领域的重要里程碑,它结合了特征抽取、区域提议网络(RPN)、ROI Pooling和分类回归,显著提升了检测速度和准确性。本文详细介绍了Faster R-CNN的网络结构、RPN的工作原理、锚点(Anchor)机制、bounding box回归及ROI Pooling层的作用,展示了如何通过这个框架进行目标检测和训练。
Faster R-CNN是目标检测领域的重要里程碑,它结合了特征抽取、区域提议网络(RPN)、ROI Pooling和分类回归,显著提升了检测速度和准确性。本文详细介绍了Faster R-CNN的网络结构、RPN的工作原理、锚点(Anchor)机制、bounding box回归及ROI Pooling层的作用,展示了如何通过这个框架进行目标检测和训练。
目录
1.4 新出炉的pytorch官方Faster RCNN代码导读
3 Region Proposal Networks(RPN)
3.3 单通道与多通道图像卷积基础知识介绍以及1×1卷积核介绍
4.3 为何有ROI Pooling还要把输入图片resize到固定大小的MxN
1 前言
Faster RCNN将特征抽取(feature extraction),proposal提取,bounding box regression,classification都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。

图1 Faster RCNN基本结构(来自原论文)
1.1 图1展示了Faster RCNN的4个主要内容
从图中可以看出:
- 卷积层(conv layers),用于提取图片的特征,输入为整张图片,输出为提取出的特征,简称为feature maps。具体来说,作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享,用于后续RPN网络和全连接层。
- RPN网络(Region Proposal Network),用于生成候选区域(region proposals),RPN代替了之前的search selective。输入为第一步中生成的featrue maps,输出为多个候选区域。具体来说,RPN将输入样本映射成一个概率值和四个坐标值。其中,概率值反应anchors中有物体的概率(即该层通过softmax判断anchor box属于foreground或者background,即是否有物体,这是一个二分类问题),四个坐标值用于回归定义物体的位置。最后,将二分类和坐标回归的损失统一起来,进行RPN网络的训练,以获得精确的proposals。
- ROI Pooling。该层收集输入的feature maps和proposals,综合这些信息后,提取proposal feature maps,得到固定尺寸的feature map,然后送入后续全连接层判定目标类别。
- 分类和回归(Classification and regression),这一层的输出是最终目的,输出候选区域所属的类,和候选区域在图像中的精确位置。利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练,从而得到proposal的类别,同时获得检测框最终的精确位置。
接下来,以上面四部分内容为切入点,详细介绍Faster RCNN网络。
1.2 图2展示了基于VGG16模型的网络结构
从图中可以看出:
- 对于一副任意大小的图像
,首先缩放至固定大小
,并将其送入网络
- Conv layers中包含13个conv层+13个relu层+4个pooling层
- RPN网络首先经过3x3卷积,再分别生成positive anchors和对应bounding box regression偏移量,然后计算出proposals
- ROI Pooling层利用proposals和feature map,生成proposal feature map,然后将其送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)

图2 faster RCNN网络结构
图2网络的详细版如下:

1.3 Faster RCNN目标
给定一张图片, 找出图中的有哪些对象,以及这些对象的位置和置信概率:

图3 目标检测样例
1.4 新出炉的pytorch官方Faster RCNN代码导读
https://zhuanlan.zhihu.com/p/145842317
2 Conv layers
Conv layers包含了conv,pooling,relu三种层。以python版本中的VGG16模型中的faster_rcnn_test.pt的网络结构为例,如图2,Conv layers部分共有13个conv层,13个relu层,4个pooling层。这里有一个非常容易被忽略但是又无比重要的信息,在Conv layers中:
- 所有的conv层都是:kernel_size=3,pad=1,stride=1
- 所有的pooling层都是:kernel_size=2,pad=0,stride=2
为何重要?在Faster RCNN Conv layers中对所有的卷积都做了扩边处理( pad=1,即填充一圈0),导致原图变为 (M+2)x(N+2)大小,再做3x3卷积后输出MxN 。正是这种设置,导致Conv layers中的conv层不改变输入和输出矩阵大小。如图4:

图4 卷积示意图
类似的是,Conv layers中的pooling层kernel_size=2,stride=2。这样每个经过pooling层的MxN矩阵,都会变为(M/2)x(N/2)大小。综上所述,在整个Conv layers中,conv和relu层不改变输入输出大小,只有pooling层使输出长宽都变为输入的1/2。
那么,一个MxN大小的矩阵经过Conv layers固定变为(M/16)x(N/16),这样Conv layers生成的feature map中都可以和原图对应起来。
3 Region Proposal Networks(RPN)
3.1 RPN整体介绍
经典的检测方法生成检测框都非常耗时,如OpenCV adaboost使用滑动窗口+图像金字塔生成检测框;或如R-CNN使用SS(Selective Search)方法生成检测框。而Faster RCNN则抛弃了传统的滑动窗口和SS方法,直接使用RPN生成检测框,这也是Faster R-CNN的巨大优势,能极大提升检测框的生成速度。

图5 RPN网络
上图5展示了RPN网络的具体结构。
可以看到,feature map经过3×3卷积后,分成了两条线:
第一条线:通过softmax分类anchors获得foreground(positive)和background(negative),其中检测目标是foreground。因为是2分类,所以它的维度是2k score。
第二条线:计算对于anchors的bounding box regression偏移量,以获得精确的proposal。它的维度是4k coordinates。
而最后的Proposal层则负责综合positive anchors和对应bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。
现在详细看一下第二条线,如下图所示:

上图的卷积,在caffe prototxt中的定义格式如下:
layer {
name: "rpn_bbox_pred"
type: "Convolution"
bottom: "rpn/output"
top: "rpn_bbox_pred"
convolution_param {
num_output: 36 # 4 * 9(anchors)
kernel_size: 1 pad: 0 stride: 1
}
}可以看到,其 num_output=36,即经过该卷积输出图像为WxHx36,在caffe blob存储为[1, 4x9, H, W],这里相当于feature maps每个点都有9个anchors,每个anchors又都有4个用于回归的变换量,即:
对应VGG输出的feature map,大小为的特征,对应设置
个anchors,而RPN输出为:
- 大小为
的positive/negative softmax分类特征矩阵
- 大小为
的regression坐标回归特征矩阵
恰好满足RPN完成positive/negative分类+bounding box regression坐标回归.
img_info的解释:
对于一副任意大小PxQ图像,传入Faster RCNN前首先reshape到固定MxN,im_info=[M, N, scale_factor]则保存了此次缩放的所有信息。然后经过Conv Layers,经过4次pooling变为WxH=(M/16)x(N/16)大小,其中feature_stride=16则保存了该信息,用于计算anchor偏移量。
3.2 RPN模块介绍
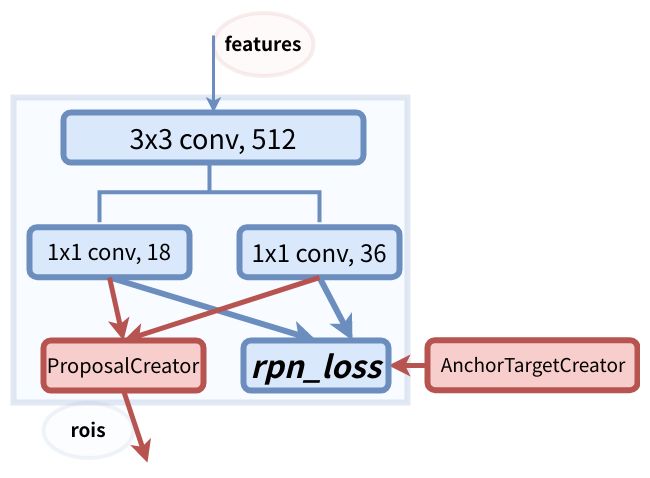
图6 RPN模块介绍
anchor的数量和feature map相关,不同的feature map对应的anchor数量也不一样。
RPN在<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2945
2945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









