







摘要
本文主要在数据集上综合运用kNN、决策树与朴素贝叶斯,并作对比。
目录
一、问题描述
消费者产生买车需求是一切的缘由。在选车时纠结,这源于人类天生具有的比较心理。在面临多种选择时,会比来比去。此外,买车是一笔不菲投入,这导致人们选择时更加谨慎,压力山大。选车纠结是当前消费者的痛点所在。一旦考虑到买车后的维护费,更是让人头痛。
人人后希望花更少的钱,买到一辆性价比高的车,使买的车有宽坦的空间、后备箱,还可以容纳更多人,而且上下车是可以随手开门。每一个人都希望有部安全可靠的车。但汽车的种类是那么繁多,一部车与安全部分有关的零件又是那么繁多。
到底该选择哪一部车呢?
受各种条件和客观因素限制,在一般的选车过程中,人们不可能都对这些情况了如指撑。因此了解专业人士如何对汽车进行综合评价,应该是购车者掌握“如何判断汽车是否合适自己”最基本、最简捷的好办法。
请收集国内外某些专业人士对汽车的综合评价,利用kNN算法、决策树、朴素贝叶斯算法这三种算法或模型,来帮消费者根据实际情况选择适合自己的汽车,并比较这三种算法或模型的优劣性。
二、数据获取与预处理
2.1 数据的获取
在此从UCI数据库中选取汽车评价数据集Car Evaluation Database,本数据集专业汽车评价人士对于1728单买卖的实际情况进行综合评价,并给出顾客的买车建议。专业人士就顾客对于买车价格(共4个等级)、维护费(共4个等级)、车门数(共4个等级)、载人数(共3个等级)、后备箱大小(共3个等级)、安全性(共3个等级)等方面的看法进行专业评价,并给出合适的建议:不可接收、可以接受、好、非常好。数据集部分原始数据截图如图1所示。

2.2 数据预处理
2.2.1 字符分割
原始的数据参杂评价等级和标点符号,这使得数据集不能直接使用,所示,先将评价等级和标点符号分割开来,使用Python中split函数,并逐行读取后,以“,”作为分割点将每行字符串分割后保存在另一文件中。分割完成后的数据集部分数据截图如图2所示。
2.2.2 评价等级量化
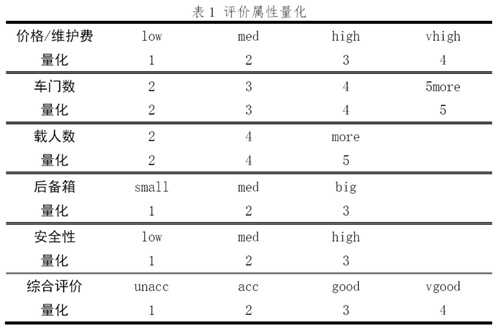
为得到6个评价属性和综合评价之间较精确的数学关系,在此应该使用数字的序号作为评价等级以代替原来的文字评价等级。考虑到人们习惯上认为属性的数值越大则属性越好,于是,对于这6个评价属性中各评价等级应该等价地认同为:
对于这6个评价属性,在不同情况下便使用不同的形式。在数值类计算情况下比如kNN算法,便是使用数值化后的评价属性。在类别分类情况下比如决策树,可以应用文字属性等级的形式。
2.2.3 缺失数据和异常数据的检测
逐行检测数据集中的数据,检查是否含有缺失值和异常值。幸运的是,本汽车评价数据集中不含缺失数据和异常数据,所以可以进行下一步处理。
2.3 数据可视化
对于汽车评价数据集中1728个数据,考虑到综合评价值只是包含4个等级:不可接收、可以接受、好、非常好,每种等级的数据的数量不一定相同,而且不一定具有庞大的数量。为了接下来的测试和计算的严谨性,应该先对综合评价等级进行统计,其统计结构如图3和图4所示。
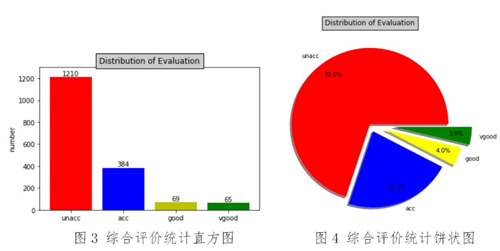
从图3和图4中可以看出,在1728个数据中,含综合评价为好、非常好的数据只是占不超过8%,数量只为69、65,而数据集中大部分的数据为综合评价为不可接受的数据。考虑到在数据测试时,若是选取80%、90%的训练集作为测试集,而剩下的作为测试集,这是有可能在训练集中将综合评价为好、非常好的数据排除在外或者它们的影响较大。
于此,为确保训练集包含每一种综合评价等级的数据,应该在选取训练集时,将按照各种综合评价等级的数据选取相应的比例的数据作为训练集,而剩下的作为测试集。
三、算法的简要介绍
3.1 kNN算法
3.1.1 kNN算法介绍
k近邻分类算法(k-Nearest Neighbor,kNN),是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。k近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这k个实例的多数属于某个类,就把该输入实例分类到这个类中。
3.1.2 计算步骤
(1)计算测试对象与训练集中所有对象的距离,选取欧式距;
(2)找出上步计算的距离中最近的k个对象,作为测试对象的k个邻居;
(3)找出K个邻居中类别出现频率最高的对象,其所属的类别就是该测试对象所属的类别。
3.2 决策树
3.2.1 决策树介绍
决策树是将所要处理的数据看做是树的根,相应的选取数据的特征作为一个个节点(决策点),每次选取一个节点将数据集分为不同的数据子集,可以看成对树进行分支,直到最后无法可分停止。
3.2.2 构造决策树
(1)选取香农熵的信息增益作为根据进行划分,使得划分在同一集合中的数据具有共同的特征;
(2)按照给定特征划分数据集并进行简单的测试,接下来我们遍历整个数据集,循环计算香农熵,找到最好的划分方式并简单测试;
(3)递归构建决策树,将每一个划分的数据看成是原数据集,那么之后的每一次划分都可以看成是和第一次划分相同的过程。递归结束的条件是:程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都有相同的分类;
(4)使用matplotlib注解绘制树形图。
3.3 朴素贝叶斯算法
3.3.1 朴素贝叶斯算法介绍
朴素贝叶斯算法的原理是通过某对象的先验概率,利用贝叶斯公式计算出它的后验概率(对象属于某一类的概率),选取具有最大后验概率的类作为该对象所属的类。
对于随机变量 A
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 981
981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









