







文章目录
前言
学习过程,记录一下SiamRPN论文每一部分对应代码,以便之后用。一、SiamRPN and SiamRPN+ + 整体结构
SiamRPN


整体流程为:
template frame和detection frame经过相同的Siamese Network得到一个feature,然后经过RPN的classification branch和regression branch,做一个互相关操作。- 分类分支的作用就是预测原图上的哪些anchor会与目标的IoU大于一定的阈值,他们对应最后的feature map上的点就是 1;回归分支就是预测每个anchor与target box的xywh的偏移
SiamRPN ++

SiamRPN++,结构跟上图类似,不过SiamRPN用的是卷积最后的结果,这里是获得了三层的结果进行加权,Xcorr(互相关层)采用新的。
Backbone - ResNet 50
作者嫌弃原来ResNet的stride过大,从而在conv4和conv5中将stride=2改动为stride=1。但是同时为了保持之前的感受野,采用了空洞卷积,dilation=1时即为默认的卷积方式,没有空洞;dilation=2表示卷积时cell与cell间空出1个cell。
resnet-50 有四组block,每组分别是 3 4 6 3个block,每个block里面有三个,另外这个网络的最开始有一个单独的卷积层,(3+4+6+3)*3+1=49。
取样层没有要学习的参数,平时我们所谓的层,指的是有参数要学习的层。
# 位于 pysot.pysot.models.backbone.resnet_atrous
def resnet50(**kwargs):
# Constructs a ResNet-50 model.
model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs) # 这里调用Bottleneck,
return model
改动后ResNet50各层如下:
在每一个layer的第一个Bottleneck模块里进行downsample,因为第一次调用该模块的时候会使得output channel不等于input channel,导致x与经过卷积后的x无法直接相加,所以做一个下采样使得维度保持一致。
layer1:dilation=1, self.inplanes=64*4=256,output channel:64 => 256
layer2:dilation=1, self.inplanes=1284=512,output channel:256 => 512, self.feature_size = 128 * block.expansion = 1284 = 512
layer3:扩大感受野dilation=2, self.inplanes=256*4=1024,output channel:512 => 1024, self.feature_size = (256+128) * block.expansion = (256+128)*4 = 1536
layer4:扩大感受野dilation=4, self.inplanes=5124=2048,output channel:1024 => 2048, self.feature_size = 512 block.expansion = 512*4 = 2048
以下是ResNET 50 层数
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(3, 3), stride=(1, 1), padding=(2, 2), dilation=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(4, 4), dilation=(4, 4), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
)
二、 Neck
neck层是为了backbone和head更好的衔接。
SiamRPN
RPN的话,只是用的最后一层的结果
- 使用Resnet的layer 4 层的输出(也就是论文图中的conv 5 层)作为输入
- 在config文件中定义了输出为256,输入为
layer 4输出的维度,(2048 =>256)。
若是训练RPN,config.yaml里面配置
ADJUST:
ADJUST: true
TYPE: "AdjustLayer"/这里不改也可以继续用AdjustAllLayer,因为在里面会判断一次 in_channels 的长度,若是1,直接执行一次,一样的效果。
KWARGS:
in_channels: [2048]
out_channels: [256]
class AdjustLayer(nn.Module):
def __init__(self, in_channels, out_channels, center_size=7):
super(AdjustLayer, self).__init__()
self.downsample = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
)
self.center_size = center_size
#训练调用forward函数时,会对经过downsample层处理过后的特征进行判断,是否执行crop:
def forward(self, x):
x = self.downsample(x)
if x.size(3) < 20: # 模板帧经过layer234后变为15*15
l = (x.size(3) - self.center_size) // 2
r = l + self.center_size
x = x[:, :, l:r, l:r]
return x
SiamRPN ++

- 上图可以看到,作者使用Resnet的layer2 3 4 层的输出(也就是论文图中的conv3 4 5 层)作为输入
- 在config文件中定义了输出为256(保证他们输出一样),输入为
layer2 3 4输出的维度,即(512 =>256)、(1024 =>256)、(2048 =>256)。 - 因为从三个不同的层数提取信息,所以neck层也会有三个AdjustLayer模块,通过self.add_module()方法添加模块,这三个模块分别称为downsample2/downsample3/downsample4;
class AdjustAllLayer(nn.Module):
def __init__(self, in_channels, out_channels, center_size=7):
super(AdjustAllLayer, self).__init__()
self.num = len(out_channels) # len = 3
if self.num == 1:
self.downsample = AdjustLayer(in_channels[0],
out_channels[0],
center_size)
else:
for i in range(self.num): 可以看到三次循环,每次都是用的Adjustlayer操作,具体操作在下面
self.add_module('downsample'+str(i+2),
AdjustLayer(in_channels[i],
out_channels[i],
center_size))
- 具体操作为使用11的卷积核做了 downsample,对于模板帧经过layer234后hw变为1515,为了减轻计算量,还进行了从中心点开始裁减77的区域作为模板特征。
class AdjustLayer(nn.Module):
def __init__(self, in_channels, out_channels, center_size=7):
super(AdjustLayer, self).__init__()
self.downsample = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
)
self.center_size = center_size
# 训练调用forward函数时,会对经过downsample层处理过后的特征进行判断,是否执行crop:
def forward(self, x):
x = self.downsample(x)
if x.size(3) < 20:
l = (x.size(3) - self.center_size) // 2
r = l + self.center_size
x = x[:, :, l:r, l:r]
return x
三、RPN
SiamRPN
SiamRPN 选 Up_Channel Cross Correlation
SiamRPN ++

- 在neck中,提取了三层结果,维度相同为 [256, 256, 256 ],因此,这里也是三个RPN头。
config.yaml 中的配置:
RPN:
TYPE: 'MultiRPN'
KWARGS:
anchor_num: 5
in_channels: [256, 256, 256]
weighted: true
head中的__init__:
RPNS = {
'UPChannelRPN': UPChannelRPN,
'DepthwiseRPN': DepthwiseRPN, # 这个就是一个RPN头,采用这个的话,就是属于RPN内容
'MultiRPN': MultiRPN # 循环三次,三个层,RPN ++
}
循环代码如下:
class MultiRPN(RPN):
def __init__(self, anchor_num, in_channels, weighted=False):
super(MultiRPN, self).__init__()
self.weighted = weighted
for i in range(len(in_channels)):
self.add_module('rpn'+str(i+2), # 这边类似 neck的构建,多个rpn MultiRPN也是循环使用 DepthwiseRPN
DepthwiseRPN(anchor_num, in_channels[i], in_channels[i]))
if self.weighted:
self.cls_weight = nn.Parameter(torch.ones(len(in_channels)))
self.loc_weight = nn.Parameter(torch.ones(len(in_channels)))
对应neck输出的3层,每层都进行DepthwiseRPN,然后定义可训练的权重参数self.cls_weight 、self.loc_weight (nn.Parameter()参考pysot基础知识讲解)送入softmax层得到权重值,最后将这三层得到的结果进行加权平均分别得到分类分支和回归分支的特征。
在 DepthwiseRPN里,使用DepthwiseXCorr得到输入256,隐藏层256,输出2*5=10的分类feature和输入256,隐藏层256,输出4 * 5=20的位置feature。
DepthwiseXCorr具体操作为模板帧和检测帧分别经过一个(3 ,3)的卷积,输入输出维度不变保持256,然后以模板帧为卷积核,进行深度互相关操作,self.head运算就是升维运算(到2k或者4k),即经过2个1*1的卷积输出输出2k或者4k的feature,可以看出,其发生在xcorr_depthwise之后,进行维度提升。与Siamese RPN网络不同,Siamese RPN++提升网络通道数为2k或者4k的操作是在卷积操作( Cross Correlation)之后,而Siamese RPN网络是在卷积操作之前,这样就减少了大量的计算量。
class DepthwiseXCorr(nn.Module):
def __init__(self, in_channels, hidden, out_channels, kernel_size=3, hidden_kernel_size=5):
# 其中,in_channels=256, out_channels=256;
# 对应DepthwiseXCorr.init(in_channels=256, hidden=256, out_channels=10(或20), kernel_size=3)
super(DepthwiseXCorr, self).__init__()
# 对于模板分支(in:256,out:256)
self.conv_kernel = nn.Sequential(
nn.Conv2d(in_channels, hidden, kernel_size=kernel_size, bias=False),
nn.BatchNorm2d(hidden),
nn.ReLU(inplace=True),
)
# 对于搜索分支(in:256,out:256):
self.conv_search = nn.Sequential(
nn.Conv2d(in_channels, hidden, kernel_size=kernel_size, bias=False),
nn.BatchNorm2d(hidden),
nn.ReLU(inplace=True),
)
# self.head运算就是升维运算(到2k或者4k),即经过2个1 * 1的卷积输出输出2k或者4k的feature
# 进行维度提升在卷积操作之后,减少了计算量
self.head = nn.Sequential(
nn.Conv2d(hidden, hidden, kernel_size=1, bias=False),
nn.BatchNorm2d(hidden),
nn.ReLU(inplace=True),
nn.Conv2d(hidden, out_channels, kernel_size=1)
)
深度互相关操作具体为:搜索帧拉成1个batchsize * channel × H × W ,模板帧拉成batchsize * channel 个1× H × W 的卷积核,然后将搜索帧分为batchsize * channel个组,进行卷积操作(分组卷积参考这篇博客),这里其实相当于输入每个通道分别和一个卷积核进行卷积了,变成一对一的关系。最后在把结果变回(B,C,H,W)

四、load_pretrain 加载预训练模型的参数
模型已经存在,主要是加载各个层里的参数,可以加载没训练的,也可以加载别人与训练好的,继续训练。
def load_pretrain(model, pretrained_path): # 加载模型,一般五步
logger.info('load pretrained model from {}'.format(pretrained_path))
# 1.初始化device
device = torch.cuda.current_device() # 返回当前设备索引,直接使用GPU
# 2.加载模型 载入GPU
pretrained_dict = torch.load(pretrained_path,
map_location=lambda storage, loc: storage.cuda(device)) # 进行模型加载
# 3.移除module前缀(一般用于多GPU分布式训练后的模型)
if "state_dict" in pretrained_dict.keys():
pretrained_dict = remove_prefix(pretrained_dict['state_dict'],
'module.')
else:
pretrained_dict = remove_prefix(pretrained_dict, 'module.')
# 4.检查键完整性:即判断当前构建的模型参数与待加载的模型参数是否匹配
try:
check_keys(model, pretrained_dict)
except:
logger.info('[Warning]: using pretrain as features.\
Adding "features." as prefix')
new_dict = {}
for k, v in pretrained_dict.items():
k = 'features.' + k
new_dict[k] = v
pretrained_dict = new_dict
check_keys(model, pretrained_dict)
# 5.装载参数
model.load_state_dict(pretrained_dict, strict=False)
return model
五、build_data_loader 构建训练集
def build_data_loader():
logger.info("build train dataset")
# train_dataset 构建训练集
train_dataset = TrkDataset()
logger.info("build dataset done")
train_sampler = None
# if get_world_size() > 1:
# train_sampler = DistributedSampler(train_dataset)
train_loader = DataLoader(train_dataset,
batch_size=cfg.TRAIN.BATCH_SIZE,
num_workers=cfg.TRAIN.NUM_WORKERS,
pin_memory=True,
sampler=train_sampler)
return train_loader
主要内容在 TrkDataset():
class TrkDataset(Dataset):
def __init__(self,):
super(TrkDataset, self).__init__()
desired_size = (cfg.TRAIN.SEARCH_SIZE - cfg.TRAIN.EXEMPLAR_SIZE) / \
cfg.ANCHOR.STRIDE + 1 + cfg.TRAIN.BASE_SIZE
if desired_size != cfg.TRAIN.OUTPUT_SIZE:
raise Exception('size not match!')
# create anchor target
self.anchor_target = AnchorTarget()
# create sub dataset
self.all_dataset = []
start = 0
self.num = 0
for name in cfg.DATASET.NAMES:
subdata_cfg = getattr(cfg.DATASET, name)
sub_dataset = SubDataset( #SubDataset是构建数据集更具体的类
name,
subdata_cfg.ROOT,
subdata_cfg.ANNO,
subdata_cfg.FRAME_RANGE,
subdata_cfg.NUM_USE,
start
)
start += sub_dataset.num #每个数据集开始的下标
self.num += sub_dataset.num_use #from 0 to +num_use_VID/+num_use_COCO/+num_use_YTB/+num_use_DET
sub_dataset.log()
self.all_dataset.append(sub_dataset) #self.all_dataset保存加载好的数据集对象
# data augmentation 数据扩充
self.template_aug = Augmentation(
cfg.DATASET.TEMPLATE.SHIFT,
cfg.DATASET.TEMPLATE.SCALE,
cfg.DATASET.TEMPLATE.BLUR,
cfg.DATASET.TEMPLATE.FLIP,
cfg.DATASET.TEMPLATE.COLOR
)
self.search_aug = Augmentation(
cfg.DATASET.SEARCH.SHIFT,
cfg.DATASET.SEARCH.SCALE,
cfg.DATASET.SEARCH.BLUR,
cfg.DATASET.SEARCH.FLIP,
cfg.DATASET.SEARCH.COLOR
)
videos_per_epoch = cfg.DATASET.VIDEOS_PER_EPOCH
self.num = videos_per_epoch if videos_per_epoch > 0 else self.num
self.num *= cfg.TRAIN.EPOCH
self.pick = self.shuffle() # #打乱顺序的index列表,shuffle有洗牌的意思
1、 AnchorTarget()
语句:
# create anchor target
self.anchor_target = AnchorTarget()
#3.将上一步得到的anchors作为Anchors实例属性all_anchors保存anchor的信息
self.anchor_target = AnchorTarget()
# TrkDataset:anchor_target => AnchorTarget:anchors => Anchors:all_anchors
class AnchorTarget:
def __init__(self,):
# 根据stride/ratios/scales生成anchors
self.anchors = Anchors(cfg.ANCHOR.STRIDE,
cfg.ANCHOR.RATIOS,
cfg.ANCHOR.SCALES)
self.anchors.generate_all_anchors(im_c=cfg.TRAIN.SEARCH_SIZE//2,
size=cfg.TRAIN.OUTPUT_SIZE)
下面是生成anchor
class Anchors:
"""
This class generate anchors.
"""
def __init__(self, stride, ratios, scales, image_center=0, size=0):
self.stride = stride
self.ratios = ratios
self.scales = scales
self.image_center = image_center
self.size = size
self.anchor_num = len(self.scales) * len(self.ratios)
self.anchors = None
self.generate_anchors()
通过generate_anchors根据设定参数算出每种不同尺度 Bbox 锚框,生成五种不同尺度的锚框
#1. 根据stride/ratios/scales生成anchors(5,4),5:anchor数量; 4:x1,y1,x2,y2.
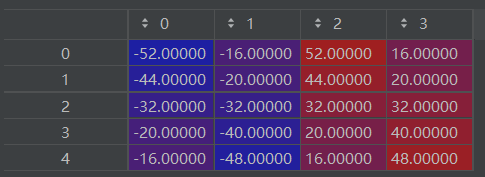
(0,1,2,3)分别对应锚框的(x1,y1,x2,y2)
def generate_anchors(self):
"""
generate anchors based on predefined configuration
"""
self.anchors = np.zeros((self.anchor_num, 4), dtype=np.float32) # 生成 5行 4列的表格,放锚框数据
size = self.stride * self.stride
count = 0
for r in self.ratios:
ws = int(math.sqrt(size*1. / r))
hs = int(ws * r)
for s in self.scales:
w = ws * s
h = hs * s
self.anchors[count][:] = [-w*0.5, -h*0.5, w*0.5, h*0.5][:]
count += 1
#2. 在25x25的数组中的每一个位置都生成5个anchor_box,每个anchor_box都用(x1,y1,x2,y2)表示,且这里的x1,y1,x2,y2均表示5个anchor_box在25个点映射回原图的坐标

def generate_all_anchors(self, im_c, size):
"""
im_c: image center -> cfg.TRAIN.SEARCH_SIZE//2
size: image size -> cfg.TRAIN.OUTPUT_SIZE
"""
# 2. 在25x25的数组中的每一个位置都生成5个anchor_box,每个anchor_box都用(x1,y1,x2,y2)表示,且这里的x1,y1,x2,y2均表示5个anchor_box在25个点映射回原图的坐标`
if self.image_center == im_c and self.size == size:
return False
self.image_center = im_c
self.size = size
# ori就是featuremap上最左上点映射回detection frame(255x255)上最左上角的位置
a0x = im_c - size // 2 * self.stride # 127-(25//2*8)=31
ori = np.array([a0x] * 4, dtype=np.float32) #[31. 31. 31. 31.]
zero_anchors = self.anchors + ori
# 这里的self.anchors就是一个位置上的K(5)个anchors
x1 = zero_anchors[:, 0]
y1 = zero_anchors[:, 1]
x2 = zero_anchors[:, 2]
y2 = zero_anchors[:, 3]
x1, y1, x2, y2 = map(lambda x: x.reshape(self.anchor_num, 1, 1),
[x1, y1, x2, y2])
cx, cy, w, h = corner2center([x1, y1, x2, y2]) # cx.shape=(5,1,1)
# disp_x.shape(1,1,25),因为要从feature映射到搜索帧上的坐标,所以乘以步长
disp_x = np.arange(0, size).reshape(1, 1, -1) * self.stride
disp_y = np.arange(0, size).reshape(1, -1, 1) * self.stride
# cx.shape=(5,1,25),cx每行元素加到每个disp_x中每个元素,cx共5行,重复5次
cx = cx + disp_x
cy = cy + disp_y
# broadcast 广播
zero = np.zeros((self.anchor_num, size, size), dtype=np.float32)
cx, cy, w, h = map(lambda x: x + zero, [cx, cy, w, h])
x1, y1, x2, y2 = center2corner([cx, cy, w, h])
# cx.shape=(5, 25, 25),每行cx都重复25次,5种anchor,分别在25x25个像素点上画
self.all_anchors = (np.stack([x1, y1, x2, y2]).astype(np.float32),
np.stack([cx, cy, w, h]).astype(np.float32))
return True
2、create sub dataset 创建子数据集
循环cfg.DATASET.NAMES 中的几个训练集,创建他们。
# create sub dataset
self.all_dataset = []
start = 0
self.num = 0
for name in cfg.DATASET.NAMES:
subdata_cfg = getattr(cfg.DATASET, name)
sub_dataset = SubDataset( #SubDataset是构建数据集更具体的类
name,
subdata_cfg.ROOT,
subdata_cfg.ANNO,
subdata_cfg.FRAME_RANGE,
subdata_cfg.NUM_USE,
start
)
start += sub_dataset.num #每个数据集开始的下标
self.num += sub_dataset.num_use #from 0 to +num_use_VID/+num_use_COCO/+num_use_YTB/+num_use_DET
sub_dataset.log()
self.all_dataset.append(sub_dataset) #self.all_dataset保存加载好的数据集对象
3、 data augmentation 数据扩充
对数据进行扩充
# data augmentation 数据扩充
self.template_aug = Augmentation(
cfg.DATASET.TEMPLATE.SHIFT,
cfg.DATASET.TEMPLATE.SCALE,
cfg.DATASET.TEMPLATE.BLUR,
cfg.DATASET.TEMPLATE.FLIP,
cfg.DATASET.TEMPLATE.COLOR
)
self.search_aug = Augmentation(
cfg.DATASET.SEARCH.SHIFT,
cfg.DATASET.SEARCH.SCALE,
cfg.DATASET.SEARCH.BLUR,
cfg.DATASET.SEARCH.FLIP,
cfg.DATASET.SEARCH.COLOR
)
videos_per_epoch = cfg.DATASET.VIDEOS_PER_EPOCH
self.num = videos_per_epoch if videos_per_epoch > 0 else self.num # 每个epoch使用给定个数视频,或者全部视频
self.num *= cfg.TRAIN.EPOCH # 所有epoch的视频数量
self.pick = self.shuffle() # #打乱顺序的index列表,shuffle有洗牌的意思
4、 build_opt_lr( ) opt–>optimizer SGD优化器 lr–> lr_scheduler
构建SGD优化器optimizer所需要的参数有:可训练参数列表、动量、权重衰减
构建学习率调整器lr_scheduler所需要的参数有:优化器、训练epochs总数
def build_opt_lr(model, current_epoch=0):
for param in model.backbone.parameters():
param.requires_grad = False
for m in model.backbone.modules():
if isinstance(m, nn.BatchNorm2d):
m.eval()
if current_epoch >= cfg.BACKBONE.TRAIN_EPOCH:
for layer in cfg.BACKBONE.TRAIN_LAYERS:
for param in getattr(model.backbone, layer).parameters():
param.requires_grad = True
for m in getattr(model.backbone, layer).modules():
if isinstance(m, nn.BatchNorm2d):
m.train()
# 构建过程分为以下几步: 1.搜集可训练参数写入python列表
trainable_params = []
trainable_params += [{'params': filter(lambda x: x.requires_grad,
model.backbone.parameters()),
'lr': cfg.BACKBONE.LAYERS_LR * cfg.TRAIN.BASE_LR}]
if cfg.ADJUST.ADJUST:
trainable_params += [{'params': model.neck.parameters(),
'lr': cfg.TRAIN.BASE_LR}]
trainable_params += [{'params': model.rpn_head.parameters(),
'lr': cfg.TRAIN.BASE_LR}]
if cfg.MASK.MASK:
trainable_params += [{'params': model.mask_head.parameters(),
'lr': cfg.TRAIN.BASE_LR}]
if cfg.REFINE.REFINE:
trainable_params += [{'params': model.refine_head.parameters(),
'lr': cfg.TRAIN.LR.BASE_LR}]
# 2.构建优化器
optimizer = torch.optim.SGD(trainable_params,
momentum=cfg.TRAIN.MOMENTUM,
weight_decay=cfg.TRAIN.WEIGHT_DECAY)
# 3.构建学习率调整器
lr_scheduler = build_lr_scheduler(optimizer, epochs=cfg.TRAIN.EPOCH)
# 4.更新学习率
lr_scheduler.step(cfg.TRAIN.START_EPOCH)
return optimizer, lr_scheduler
六、loss
下图就是论文中提到损失函数的部分:可以看到:
- 分类分支利用
交叉熵损失来监督预测值,使得在目标周围与target IoU大于一定阈值的anchor对应的feature map上的位置能够是1,能够在track phase更容易选中这些anchor,去更可靠地回归出target位置 - 回归分支这里公式写的不是很严谨,δ 这里其实学习的目标,也就是anchor和target的偏差,包括归一化后的cx,cy,w,h偏差,而我们就是去预测这个offsets,所以利用了smooth L1 loss

6.1、Cross Entropy Loss
经典的二分类交叉熵损失函数,只不过需要注意两点:
- 这里的pred已经经过F.log_softmax函数,所以这里只要经过 F.nll_loss就行了
- 因为label里面还有ignored -1部分,所以这里就选取1的正位置和0的负位置部分计入损失
def get_cls_loss(pred, label, select):
if len(select.size()) == 0 or \
select.size() == torch.Size([0]):
return 0
pred = torch.index_select(pred, 0, select)
label = torch.index_select(label, 0, select)
return F.nll_loss(pred, label)
def select_cross_entropy_loss(pred, label):
"""
:param pred: (N,K,17,17,2)
:param label: (N,K,17,17)
:return:
"""
pred = pred.view(-1, 2)
label = label.view(-1)
pos = label.data.eq(1).nonzero().squeeze().cuda() # (#pos,)
neg = label.data.eq(0).nonzero().squeeze().cuda() # (#neg,)
loss_pos = get_cls_loss(pred, label, pos)
loss_neg = get_cls_loss(pred, label, neg)
return loss_pos * 0.5 + loss_neg * 0.5
6.2、L1 Loss
代码里面并没有使用smooth L1 loss,而是直接使用了L1 loss,即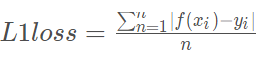
这里也有注意的点:
- 这里的loss_weight其实也就没有把负位置的点算入回归损失,并且对正位置出损失做了归一化
- L1 loss不要忘记最后除以batch size
def weight_l1_loss(pred_loc, label_loc, loss_weight):
"""
:param pred_loc: (N,4K,17,17)
:param label_loc: (N,4,k,17,17)
:param loss_weight: (N,K,17,17)
:return:
"""
b, _, sh, sw = pred_loc.size()
pred_loc = pred_loc.view(b, 4, -1, sh, sw)
diff = (pred_loc - label_loc).abs()
diff = diff.sum(dim=1).view(b, -1, sh, sw)
loss = diff * loss_weight
return loss.sum().div(b)
七、track
这一部分在pysot\tracker\siamrpn_tracker.py里,主要实现两个方法:init和track:
7.1、 init
这部分就是利用第一帧的先验信息,包括第一帧图片和ground truth bbox,相当于一个one-shot detection,这个template frame就固定了,相当于一个kernel
def init(self, img, bbox):
"""
args:
img(np.ndarray): BGR image
bbox: (x, y, w, h) bbox
"""
# 之后要更新self.center_pos和self.size
self.center_pos = np.array([bbox[0]+(bbox[2]-1)/2,
bbox[1]+(bbox[3]-1)/2])
self.size = np.array([bbox[2], bbox[3]])
# calculate z crop size
w_z = self.size[0] + cfg.TRACK.CONTEXT_AMOUNT * np.sum(self.size)
h_z = self.size[1] + cfg.TRACK.CONTEXT_AMOUNT * np.sum(self.size)
s_z = round(np.sqrt(w_z * h_z))
# calculate channle average
self.channel_average = np.mean(img, axis=(0, 1))
# get crop
z_crop = self.get_subwindow(img, self.center_pos,
cfg.TRACK.EXEMPLAR_SIZE,
s_z, self.channel_average)
self.model.template(z_crop)
7.2、 track
这里就是输入一张subsequent frame,然后根据预测值,加以scale和ratio的penalty,然后用cosine window来suppress large displacement,然后根据分类分数的最高值对应的anchor来回归预测目标位置:
def track(self, img):
"""
args:
img(np.ndarray): BGR image
return:
bbox(list):[x, y, width, height]
"""
w_z = self.size[0] + cfg.TRACK.CONTEXT_AMOUNT * np.sum(self.size)
h_z = self.size[1] + cfg.TRACK.CONTEXT_AMOUNT * np.sum(self.size)
s_z = np.sqrt(w_z * h_z)
scale_z = cfg.TRACK.EXEMPLAR_SIZE / s_z
s_x = s_z * (cfg.TRACK.INSTANCE_SIZE / cfg.TRACK.EXEMPLAR_SIZE)
x_crop = self.get_subwindow(img, self.center_pos,
cfg.TRACK.INSTANCE_SIZE,
round(s_x), self.channel_average)
outputs = self.model.track(x_crop)
score = self._convert_score(outputs['cls'])
pred_bbox = self._convert_bbox(outputs['loc'], self.anchors)
def change(r):
return np.maximum(r, 1. / r)
def sz(w, h):
pad = (w + h) * 0.5
return np.sqrt((w + pad) * (h + pad))
# scale penalty
s_c = change(sz(pred_bbox[2, :], pred_bbox[3, :]) /
(sz(self.size[0]*scale_z, self.size[1]*scale_z)))
# aspect ratio penalty
r_c = change((self.size[0]/self.size[1]) /
(pred_bbox[2, :]/pred_bbox[3, :]))
penalty = np.exp(-(r_c * s_c - 1) * cfg.TRACK.PENALTY_K)
pscore = penalty * score
# window penalty
pscore = pscore * (1 - cfg.TRACK.WINDOW_INFLUENCE) + \
self.window * cfg.TRACK.WINDOW_INFLUENCE
best_idx = np.argmax(pscore)
bbox = pred_bbox[:, best_idx] / scale_z
lr = penalty[best_idx] * score[best_idx] * cfg.TRACK.LR
cx = bbox[0] + self.center_pos[0]
cy = bbox[1] + self.center_pos[1]
# smooth bbox
width = self.size[0] * (1 - lr) + bbox[2] * lr
height = self.size[1] * (1 - lr) + bbox[3] * lr
# clip boundary
cx, cy, width, height = self._bbox_clip(cx, cy, width,
height, img.shape[:2])
# udpate state
self.center_pos = np.array([cx, cy])
self.size = np.array([width, height])
bbox = [cx - width / 2,
cy - height / 2,
width,
height]
best_score = score[best_idx]
return {
'bbox': bbox,
'best_score': best_score
}
因为之前撒anchor的时候是以原图中心为原点(而不是左上角),所以在上面的【47-48行 cx,cy】的时候,是直接加到上一帧的中心pos结果上。
八、forward
构建好模型后,在train环节,训练代码:
outputs = model(data)
loss = outputs['total_loss']
进入model_builder的forward通路:
def forward(self, data):
""" only used in training
传入的data包含training image pairs、label_cls、label_loc、label_loc_weight****
(这些参数key-value pairs会在构建数据集的时候写入)
首先将template/search pairs传入上述构建的模型得到分类结果cls和位置结果loc,
然后将cls送入log_softmax得到softmax value:cls;再将cls、label_cls送入select_cross_entropy_loss得到分类损失cls_loss;
将loc, label_loc, label_loc_weight送入weight_l1_loss得到回归损失loc_loss。返回ouputs=[ total_loss, cls_loss, loc_loss ]
"""
template = data['template'].cuda()
search = data['search'].cuda()
label_cls = data['label_cls'].cuda()
label_loc = data['label_loc'].cuda()
label_loc_weight = data['label_loc_weight'].cuda()
# get feature ,获得特征
zf = self.backbone(template) # 在进入各自对应的forward中,这里的zf,输出的是 p2,p3,p4 卷积的2,3,4层三个输出
xf = self.backbone(search) # 同理
if cfg.MASK.MASK:
zf = zf[-1]
self.xf_refine = xf[:-1]
xf = xf[-1]
if cfg.ADJUST.ADJUST:
zf = self.neck(zf) # 在进入各自对应的forward中
xf = self.neck(xf)
cls, loc = self.rpn_head(zf, xf) # 在进入各自对应的forward中
# get loss
cls = self.log_softmax(cls)
cls_loss = select_cross_entropy_loss(cls, label_cls)
loc_loss = weight_l1_loss(loc, label_loc, label_loc_weight)
outputs = {}
outputs['total_loss'] = cfg.TRAIN.CLS_WEIGHT * cls_loss + \
cfg.TRAIN.LOC_WEIGHT * loc_loss
outputs['cls_loss'] = cls_loss
outputs['loc_loss'] = loc_loss
if cfg.MASK.MASK:
# TODO
mask, self.mask_corr_feature = self.mask_head(zf, xf)
mask_loss = None
outputs['total_loss'] += cfg.TRAIN.MASK_WEIGHT * mask_loss
outputs['mask_loss'] = mask_loss
return outputs















 2564
2564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









