







目录
一、研究背景及意义
随着互联网的快速发展,新闻文本数据呈现爆炸式增长。如何从海量新闻文本中快速准确地分类和提取有用信息,成为信息处理领域的重要课题。传统的文本分类方法依赖于手工特征提取和简单的机器学习模型,难以应对复杂的语义和上下文关系。基于深度学习的新闻文本分类系统可以通过自动学习文本特征,提供更准确的分类结果,帮助用户快速获取感兴趣的新闻内容。
二、需求分析
1. 用户需求:
用户希望能够快速获取感兴趣的新闻内容。
用户希望能够根据新闻内容进行分类和过滤。
用户希望能够通过关键词搜索相关新闻。
2. 系统需求:
系统需要能够处理大规模的新闻文本数据。
系统需要具备高效的深度学习模型来分析和分类新闻文本。
系统需要具备良好的可扩展性和实时性。
三、系统设计
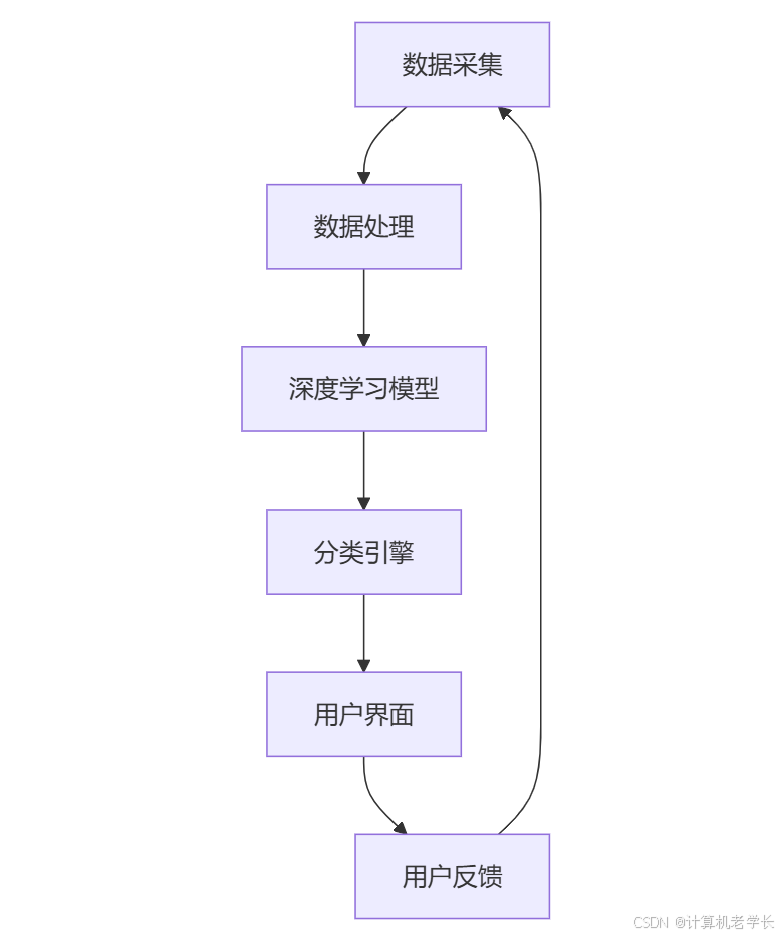
1. 数据采集模块
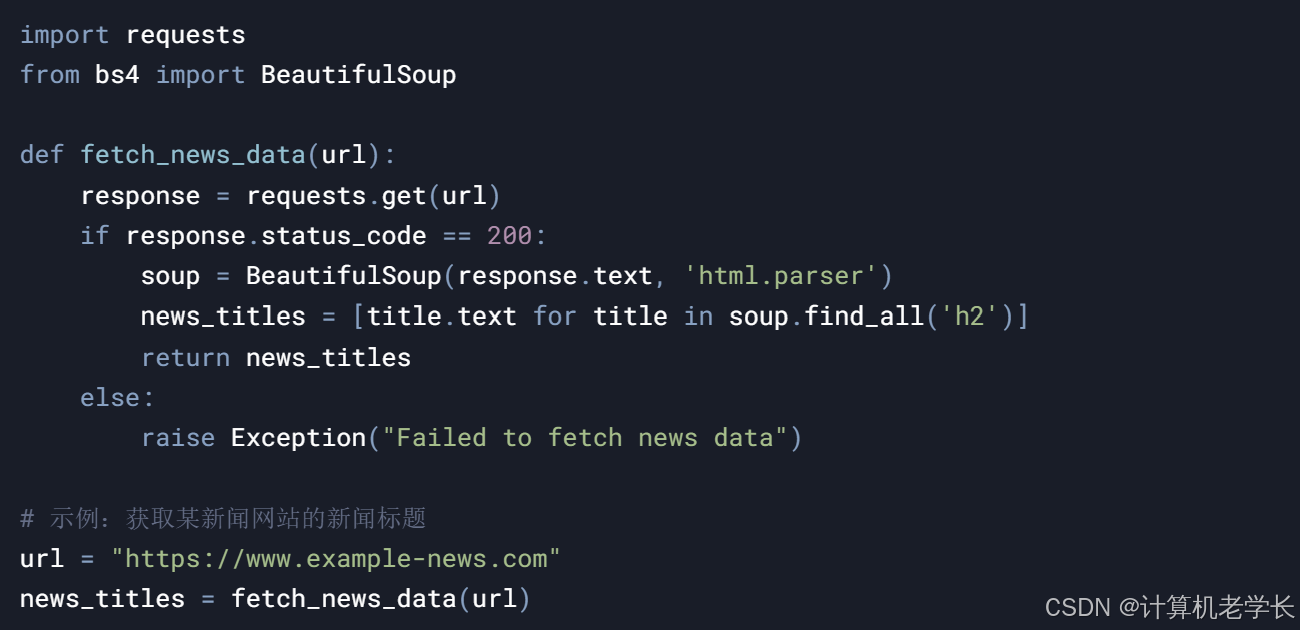
功能:从新闻网站、社交媒体等来源采集新闻文本数据。
输入:新闻网站URL、社交媒体API。
输出:原始新闻文本数据。
2. 数据处理模块
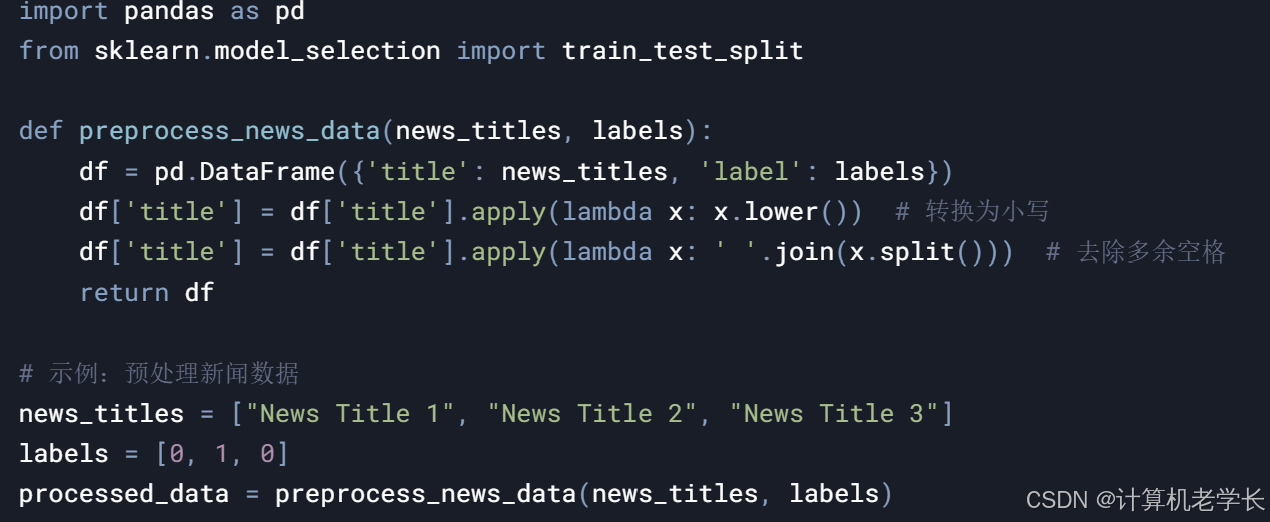
功能:清洗数据、处理缺失值、标准化数据。
输入:原始新闻文本数据。
输出:处理后的新闻文本数据。
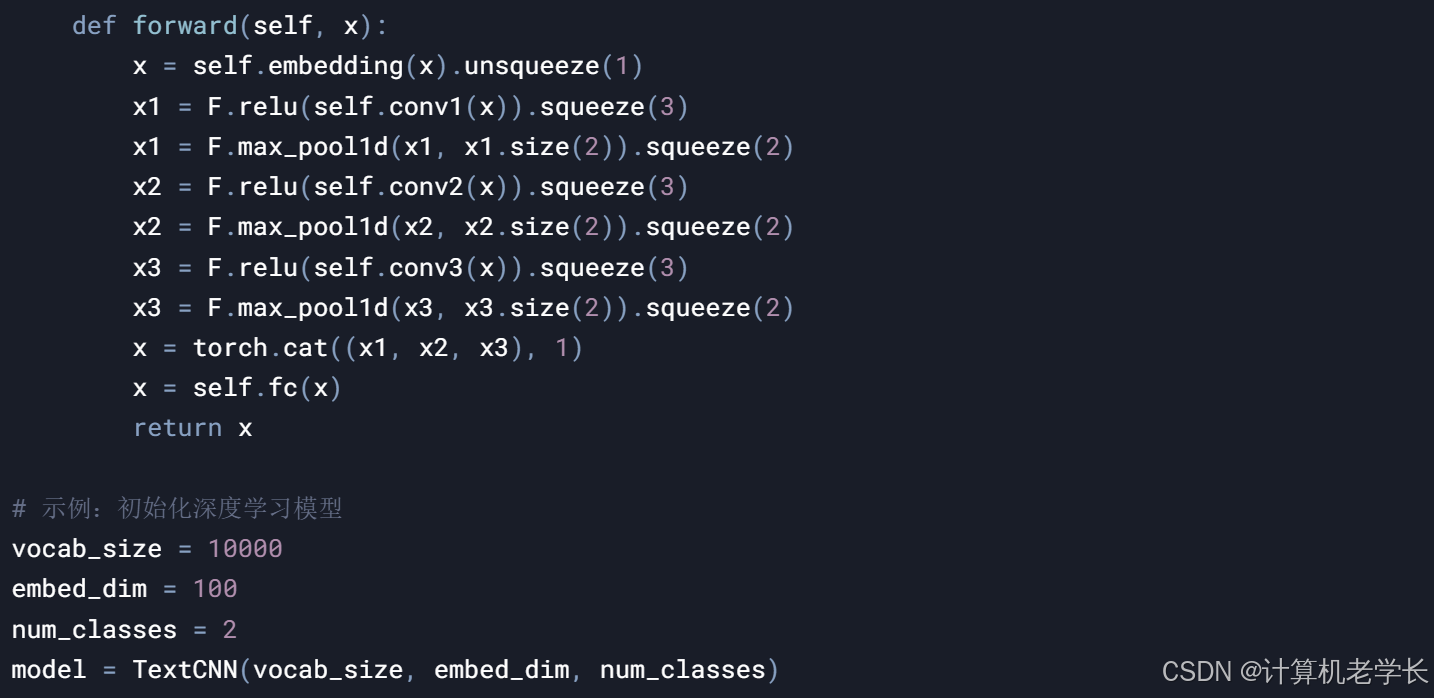
3. 深度学习模型
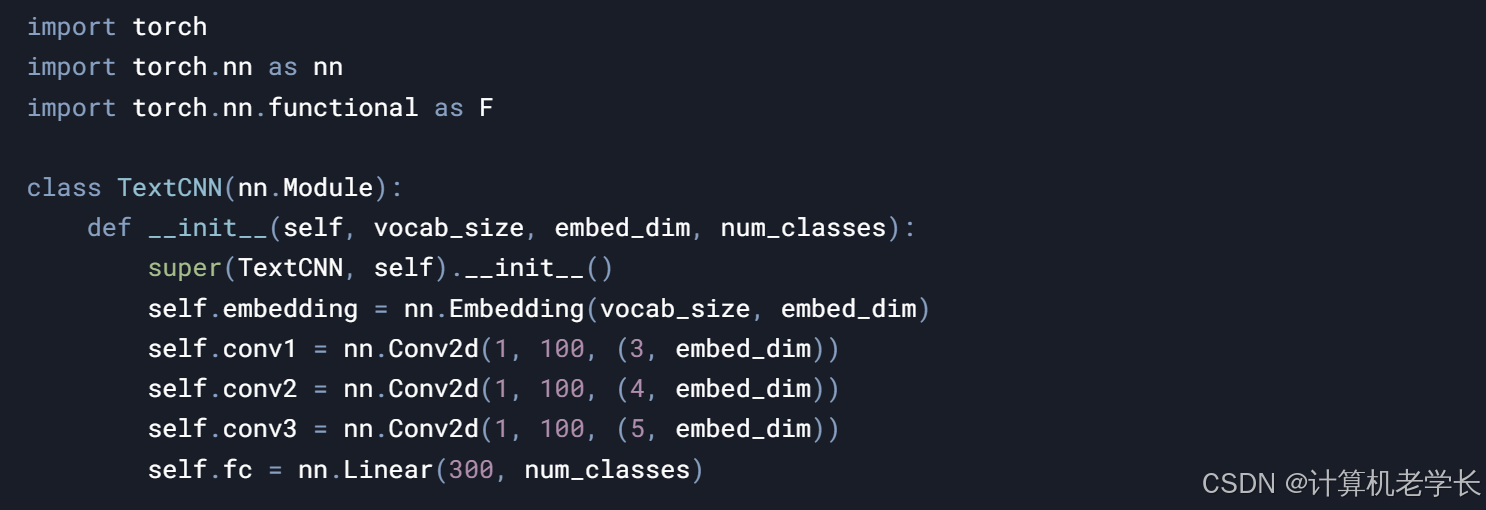
功能:使用深度学习模型(如TextCNN、LSTM或BERT)分析新闻文本,生成分类结果。
输入:处理后的新闻文本数据。
输出:新闻分类结果。
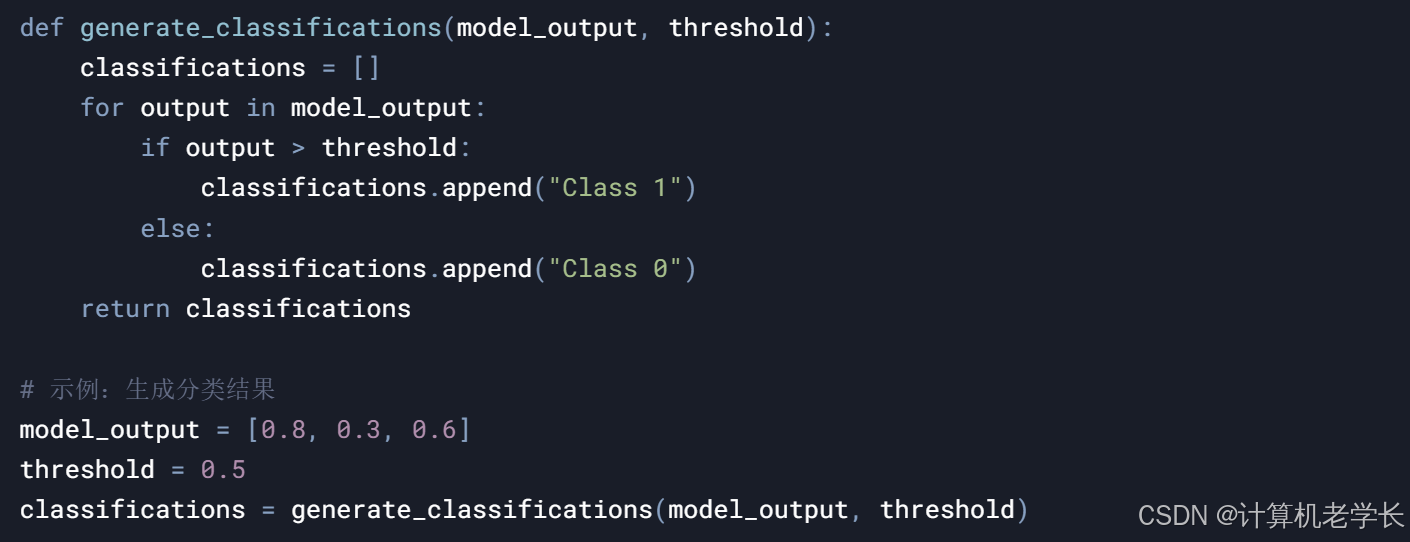
4. 分类引擎模块
功能:根据模型输出生成新闻分类结果。
输入:模型输出。
输出:新闻分类结果。
5. 用户界面模块
功能:提供用户交互界面,展示新闻内容和分类结果。
输入:分类结果。
输出:用户界面展示。
6. 反馈模块
功能:收集用户反馈,用于优化模型。
输入:用户反馈。
输出:优化后的模型。
流程图:
四、系统实现
1. 数据采集模块
2. 数据处理模块
3. 深度学习模型
4. 分类引擎
五、实验结果
1. 实验设置:
数据集:使用公开的新闻文本数据集和模拟的标签数据。
评估指标:准确率、召回率、F1分数。
2. 实验结果:
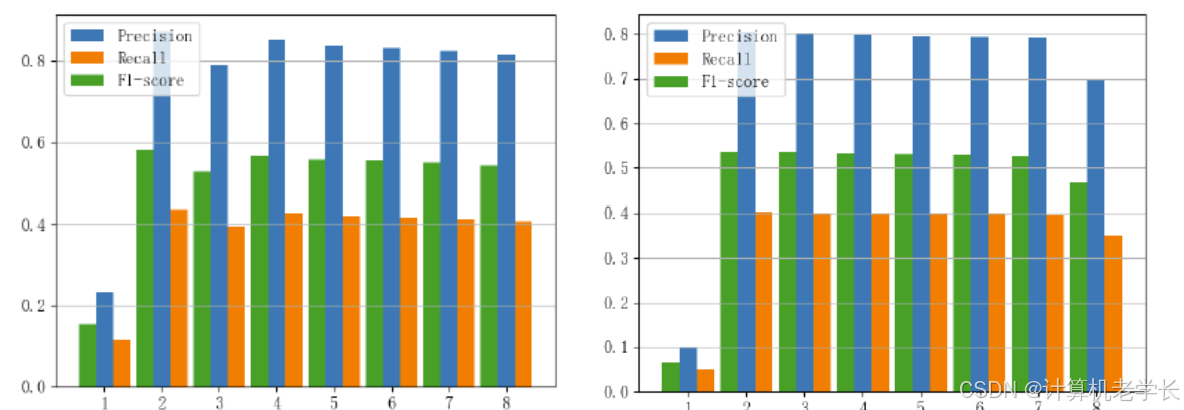
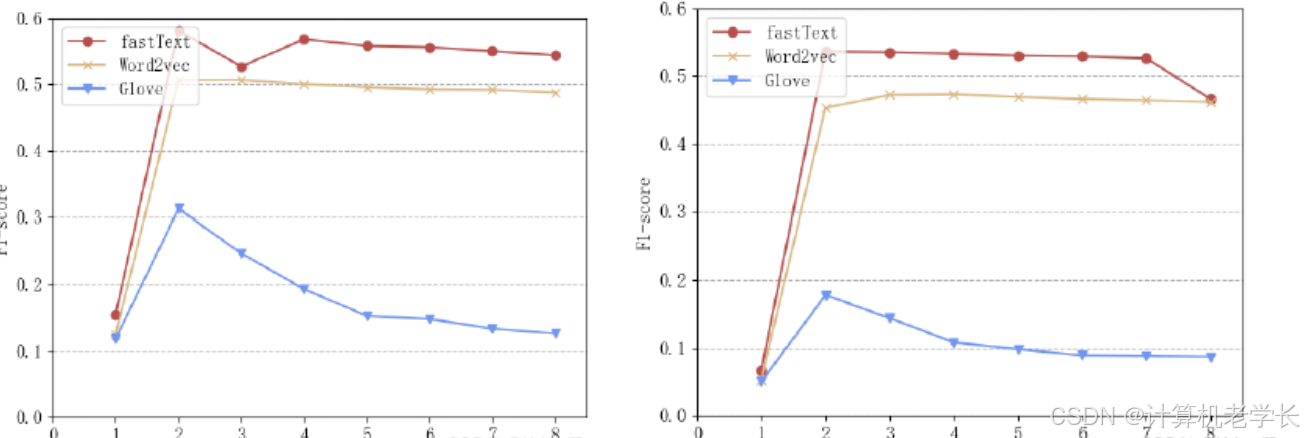
3. 结果分析:
实验结果表明,基于深度学习的新闻文本分类系统在准确率和召回率上均优于传统的分类方法。
系统能够有效地根据新闻内容生成准确的分类结果。
六、总结
基于深度学习的新闻文本分类系统通过分析新闻文本数据,能够提供更准确的分类结果,帮助用户快速获取感兴趣的新闻内容。实验结果表明,该系统在多个评估指标上均表现出色,具有广泛的应用前景。
开源代码
链接: https://pan.baidu.com/s/1-3maTK6vTHw-v_HZ8swqpw?pwd=yi4b
提取码: yi4b


















 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









