



1 Windows系统下多进程数据处理崩溃问题
错误信息:RuntimeError: One of the subprocesses has abruptly died during map operation
1.1 问题根源分析
Windows系统采用spawn方式创建子进程,与Linux的fork机制存在本质差异。这种差异导致局部函数、lambda表达式等对象无法通过pickle序列化进行进程间通信,引发RuntimeError和AttributeError。
1.2 解决方案:
设置预处理工作进程数为1,既避免多进程崩溃又满足库的最低要求。
我们只需在llamafactory中其他参数设置的额外参数处添加如下代码即可。
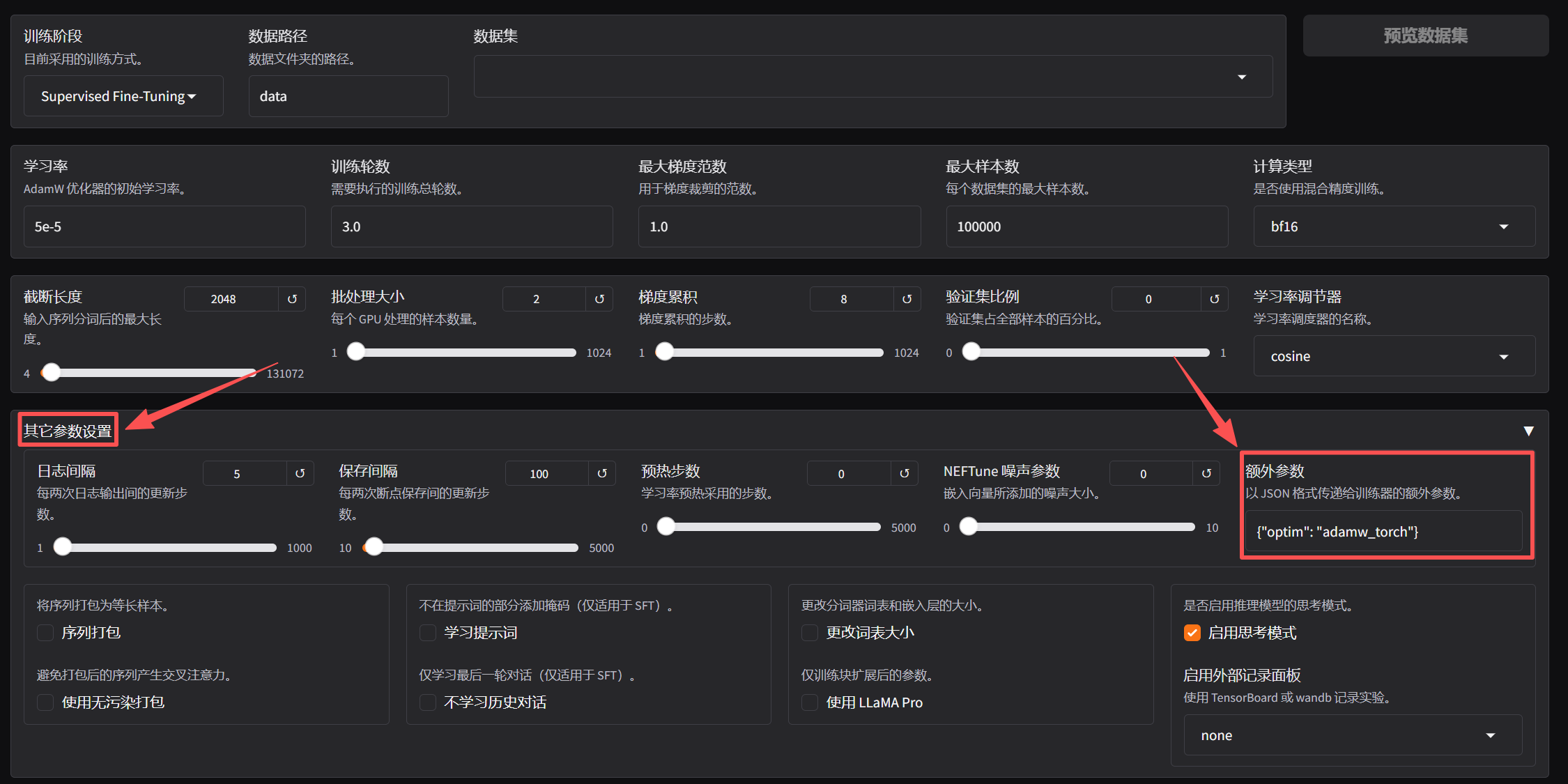
图1 llamafactory的web页面
{
"preprocessing_num_workers": 1,
"num_proc": 1
}
2 多进程DataLoader序列化错误:
错误信息:AttributeError: Can't pickle local object
2.1 问题根源分析
PyTorch/HuggingFace生态的Linux优化倾向:
1.默认配置为Linux服务器优化
2.默认启用多进程加速(num_workers > 0)
在Windows上这些优化反而会导致崩溃
2.2 解决方案:
在llamafactory的web界面中其他参数设置的额外参数设置中添加如下代码即可。
{
"dataloader_num_workers": 0, // 最关键:必须为0
"dataloader_pin_memory": false, // Windows上必须false
"gradient_checkpointing": true, // 内存优化技术
"remove_unused_columns": false // 避免数据列问题
}
3 终极方案
如果以上还未解决,可以试试这个终极解决方案:
依旧是在额外参数中添加:
{
"preprocessing_num_workers": 1,
"dataloader_num_workers": 0,
"remove_unused_columns": false,
"dataloader_pin_memory": false,
"per_device_train_batch_size": 1,
"gradient_accumulation_steps": 8,
"gradient_checkpointing": true,
"ddp_find_unused_parameters": false,
"ddp_broadcast_buffers": false
}
这串代码不仅解决了上面的两个问题,而且还降低了模型训练强度(以时间换空间)。
4 核心经验总结
Windows平台需特别注意:
(1).所有多进程参数默认归零
(2).优先保证运行稳定性
(3).内存优化技术组合使用
(4).采用增量式调试策略

















 1884
1884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









