






import datetime
import pandas as pd
import numpy as np
today=str(datetime.date.today())
filepath='/Users/kangyongqing/Documents/kangyq/202206/季度评级月数据支持/2024Q2季度级别变化分析/'
file1='01季度级别2024Q1明细文件2024-05-11.xlsx'
file2='01季度级别2024Q2明细文件2024-05-11.xlsx'
file3='04升级明细及成本核算2024-04-24_副本2.xlsx' #为了替换过程数据X和Y得分,其实没什么用,因为上上个季度的X和Y得分也是不准确的,甚至就没有,只做了保级处理
file4='教管分区.xlsx'
df1=pd.read_excel(filepath+file1,dtype={'教师id':'object'})
df2=pd.read_excel(filepath+file2,dtype={'教师id':'object'})
print(df1.info())
print(df2.info())
# df3=pd.merge(df1,df2,on='教师id',how='inner',suffixes=('_Q1','_Q2'))
#鉴于班课修正级别教师涉及人数较多,且未修改中间过程数据,即X得分和y得分不准确,用线下表替换后分析
df31=pd.merge(df1,df2,on='教师id',how='inner',suffixes=('_Q1','_Q2'))
df32=pd.merge(df31,pd.read_excel(filepath+file3,sheet_name='修正级别定级详情',usecols=['教师id','x_score','y_score'],dtype={'教师id':'object'}),on='教师id',how='left')
df32['X指标的评分_Q2']=np.where(df32['x_score'].notnull(),df32['x_score'],df32['X指标的评分_Q2'])
df32['Y指标的评分_Q2']=np.where(df32['y_score'].notnull(),df32['y_score'],df32['Y指标的评分_Q2'])
df3=df32.copy()
#附:Q1定级使用班课教师保级策略,没有中间数据,过程分析仍然存在较大出入
df3['X变化']=df3['X指标的评分_Q2']-df3['X指标的评分_Q1']
df3['X变化标签']=pd.cut(df3['X变化'],bins=[-20,0,1,20],right=False,labels=['下降','保持','提升'])
df3['Y变化']=df3['Y指标的评分_Q2']-df3['Y指标的评分_Q1']
df3['Y变化标签']=pd.cut(df3['Y变化'],bins=[-20,0,1,20],right=False,labels=['下降','保持','提升'])
df3['级别变化']=df3['Q2教师评级']-df3['Q1教师评级']
df3['级别变化标签']=pd.cut(df3['级别变化'],bins=[-20,0,1,20],right=False,labels=['下降','保持','提升'])
print(df3.columns)
print(df3.shape)
print(df3['X变化标签'].value_counts())
print(df3['Y变化标签'].value_counts())
print(df3['级别变化标签'].value_counts())
piv0=pd.pivot_table(df3,index=('级别变化标签'),values='教师id',aggfunc='count').reset_index()
piv0['比例']=piv0['教师id']/piv0['教师id'].sum()
piv0['比例']=piv0['比例'].map(lambda x:'{:.2%}'.format(x))
print(piv0)
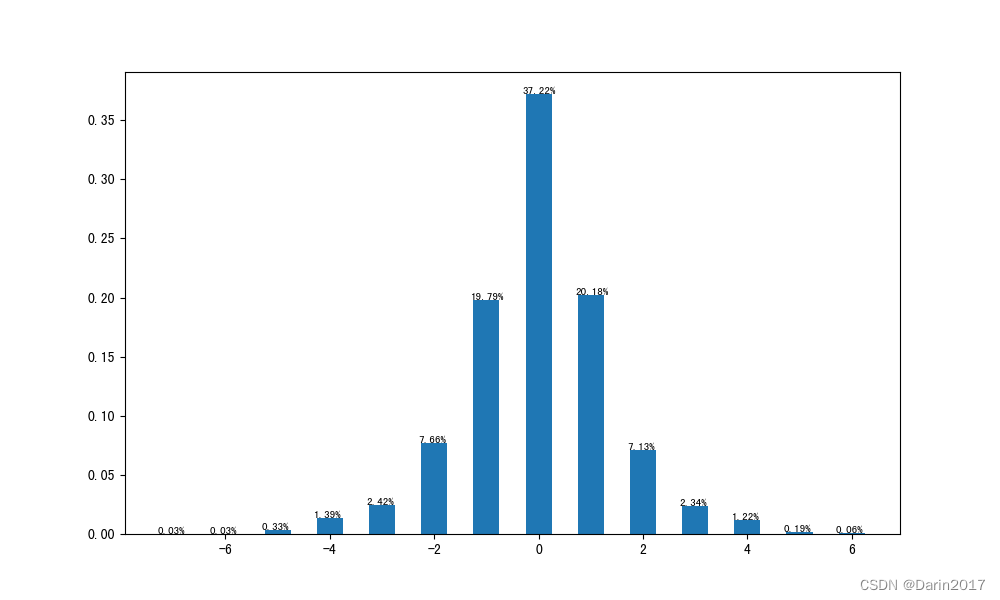
piv01=pd.pivot_table(df3,index=('级别变化'),values='教师id',aggfunc='count').reset_index()
piv01['比例']=piv01['教师id']/piv01['教师id'].sum()
piv01['比例']=piv01['比例'].map(lambda x:'{:.2%}'.format(x))
print(piv01)
piv1=pd.pivot_table(df3,index=('级别变化标签','X变化标签','Y变化标签'),values='教师id',aggfunc='count').reset_index()
piv1['类别总计']=piv1.groupby('级别变化标签')['教师id'].transform('sum')
piv1['类别分类占比']=piv1['教师id']/piv1['类别总计']
piv1['类别分类占比']=piv1['类别分类占比'].map(lambda x:'{:.2%}'.format(x))
piv1['总计']=piv1['教师id'].sum()
piv1['类别占比']=piv1['类别总计']/piv1['总计']
piv1['类别占比']=piv1['类别占比'].map(lambda x:'{:.2%}'.format(x))
print(piv1)
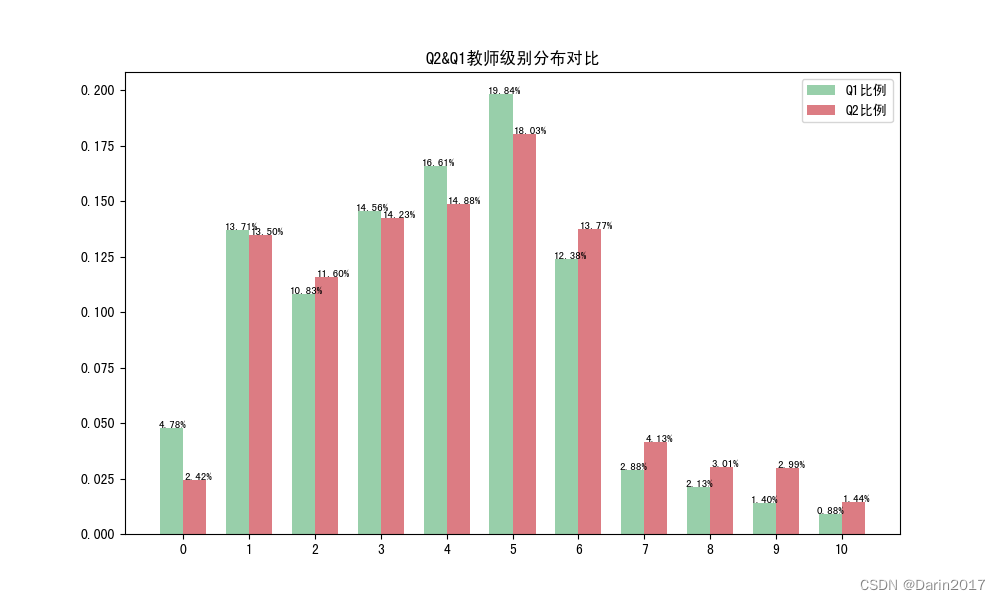
piv2=pd.pivot_table(df1,index='Q1教师评级',values='教师id',aggfunc='count').reset_index()
piv2['Q1比例']=piv2['教师id']/piv2['教师id'].sum()
piv2['Q1比例']=piv2['Q1比例'].map(lambda x:'{:.2%}'.format(x))
piv3=pd.pivot_table(df2,index='Q2教师评级',values='教师id',aggfunc='count').reset_index()
piv3['Q2比例']=piv3['教师id']/piv3['教师id'].sum()
piv3['Q2比例']=piv3['Q2比例'].map(lambda x:'{:.2%}'.format(x))
piv4=pd.concat((piv2,piv3),axis=1)
print(piv4)
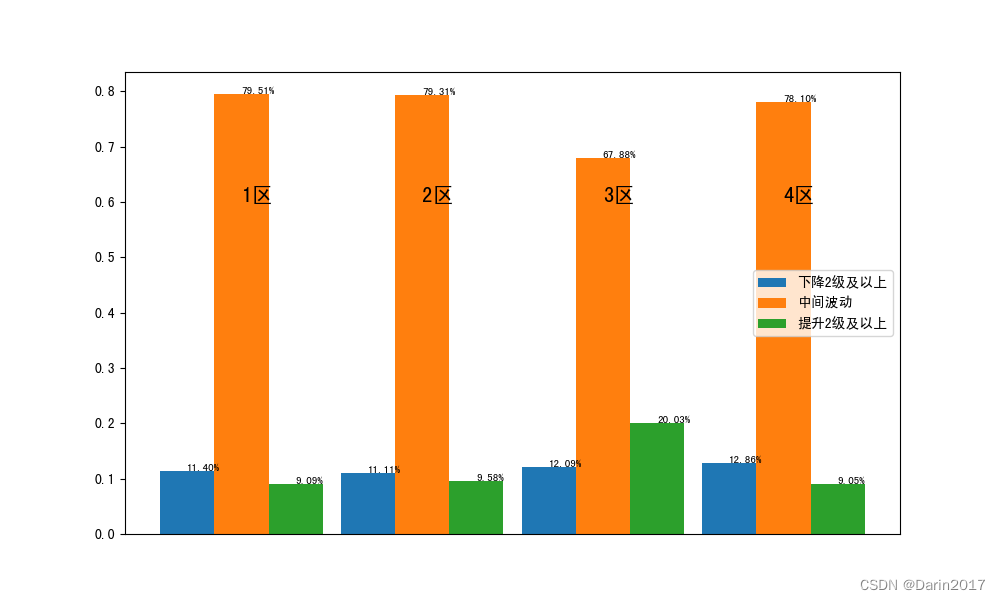
df4=pd.merge(df3,pd.read_excel(filepath+file4),left_on='教学管理_Q2',right_on='教管',how='left')
df4['级别变化标签2']=pd.cut(x=df4['级别变化'],bins=[-10,-1,2,11],right=False,labels=['下降2级及以上','中间波动','提升2级及以上'])
print(df4.columns)
print(df4.groupby(['级别变化标签2'],observed=True)['教师id'].agg('count'))
piv5=pd.pivot_table(df4,index='区域',columns='级别变化标签2',values='教师id',aggfunc='count',margins=True,margins_name='总计')
piv5.index.name=None
piv6=pd.crosstab(index=df4['区域'],columns=df4['级别变化标签2'],values=df4['教师id'],aggfunc='count',margins=True,margins_name='总计',normalize='index')
piv6.index.name=None
piv6=piv6.round(4)
# print(piv5)
# print(piv6)
piv7=pd.concat((piv5,piv6),axis=0)
print(piv7)
figdata1=pd.DataFrame(piv4.loc[:,['Q1比例','Q2比例']])
figdata1['Q1比例1']=figdata1['Q1比例'].str.rstrip('%').astype('float')/100
figdata1['Q2比例1']=figdata1['Q2比例'].str.rstrip('%').astype('float')/100
print(figdata1)
# strip()方法是去掉字符串最左和最右指定的字符,当()内为空,不含参数时,去掉空格
#
# lstrip()方法是去掉字符串最左指定的字符,当()内为空,不含参数时,去掉空格
#
# rstrip()方法是去掉字符串最右指定的字符,当()内为空,不含参数时,去掉空格
import matplotlib.pyplot as plt
fig1=plt.figure(figsize=(10,6))
plt.bar(range(len(figdata1)),figdata1['Q1比例1'],label='Q1比例',color='#98cfaa',width=0.35)
for (x,y) in zip(range(len(figdata1)),figdata1['Q1比例1'].values):
plt.text(x-0.2,y,figdata1['Q1比例'].loc[x],fontsize=8,rotation=0)
plt.bar([x+0.35 for x in range(len(figdata1))],figdata1['Q2比例1'],label='Q2比例',color='#dc7c83',width=0.35)
for (x,y) in zip(range(len(figdata1)),figdata1['Q2比例1'].values):
plt.text(x+0.2,y,figdata1['Q2比例'].loc[x],fontsize=8,rotation=0)
#添加图例
plt.legend()
#添加x轴标签
plt.xticks([x+0.175 for x in range(len(figdata1))],figdata1.index)
#添加图表标签
plt.title('Q2&Q1教师级别分布对比')
#显示图形
plt.savefig(filepath+'Q2&Q1教师级别分布对比.png')
fig2=plt.figure(figsize=(10,6))
plt.bar(piv01['级别变化'],piv01['比例'].str.rstrip('%').astype('float')/100,width=0.5)
for (x,y) in zip(piv01['级别变化'],piv01['比例'].str.rstrip('%').astype('float')/100):
plt.text(x-0.3,y,piv01.set_index('级别变化').loc[x,'比例'],fontsize=8,rotation=0)
plt.savefig(filepath+'级别变化详情.png')
fig3=plt.figure(figsize=(10,6))
plt.bar([x-0.3 for x in range(4)],piv7.iloc[5:9,0],width=0.3,label='下降2级及以上')
for (x,y) in zip([x-0.3 for x in range(4)],piv7.iloc[5:9,0]):
plt.text(x,y,'{:.2%}'.format(y),fontsize=8)
plt.bar(range(4),piv7.iloc[5:9,1],width=0.3,label='中间波动')
for (x,y) in zip(range(4),piv7.iloc[5:9,1] ):
plt.text(x,y,'{:.2%}'.format(y),fontsize=8)
plt.bar([x+0.3 for x in range(4)],piv7.iloc[5:9,2],width=0.3,label='提升2级及以上')
for (x,y) in zip([x+0.3 for x in range(4)],piv7.iloc[5:9,2]):
plt.text(x,y,'{:.2%}'.format(y),fontsize=8)
#隐藏X轴刻度
plt.xticks([])
for (x,y ) in zip(range(4),piv7.index[5:9]):
plt.text(x,0.6,y,fontsize=15)
plt.legend(loc='right')
plt.savefig(filepath+'区域级别变化.png')
# plt.legend(loc='xxx')
# xxx的取值有以下几种:
# ‘best’(默认值):自动选择最佳位置。
# ‘upper
# right’:右上角。
# ‘upper
# left’:左上角。
# ‘lower
# right’:右下角。
# ‘lower
# left’:左下角。
# ‘right’:右侧。
# ‘center
# left’:左侧中央。
# ‘center
# right’:右侧中央。
# ‘lower
# center’:底部中央。
# ‘upper
# center’:顶部中央。
# plt.show()
writer=pd.ExcelWriter(filepath+f'06季度级别变化分析{today}.xlsx',engine='openpyxl')
df3.to_excel(writer,sheet_name='明细',index=False)
piv4.to_excel(writer,sheet_name='级别分布',index=False)
piv01.to_excel(writer,sheet_name='级别变化',index=False)
piv0.to_excel(writer,sheet_name='级别变化分类',index=False)
piv1.to_excel(writer,sheet_name='级别变化下钻',index=False)
piv7.to_excel(writer,sheet_name='区域级别变化')
writer._save()
from reset_col import reset_col
reset_col(writer)
可视化展示:
知识点:
- 百分比转换为数字,
figdata1['Q1比例1']=figdata1['Q1比例'].str.rstrip('%').astype('float')/100, 补充资料:# strip()方法是去掉字符串最左和最右指定的字符,当()内为空,不含参数时,去掉空格 # # lstrip()方法是去掉字符串最左指定的字符,当()内为空,不含参数时,去掉空格 # # rstrip()方法是去掉字符串最右指定的字符,当()内为空,不含参数时,去掉空格
- 多系列图表制作,并添加标签,
import matplotlib.pyplot as plt fig1=plt.figure(figsize=(10,6)) plt.bar(range(len(figdata1)),figdata1['Q1比例1'],label='Q1比例',color='#98cfaa',width=0.35) for (x,y) in zip(range(len(figdata1)),figdata1['Q1比例1'].values): plt.text(x-0.2,y,figdata1['Q1比例'].loc[x],fontsize=8,rotation=0) plt.bar([x+0.35 for x in range(len(figdata1))],figdata1['Q2比例1'],label='Q2比例',color='#dc7c83',width=0.35) for (x,y) in zip(range(len(figdata1)),figdata1['Q2比例1'].values): plt.text(x+0.2,y,figdata1['Q2比例'].loc[x],fontsize=8,rotation=0) #添加图例 plt.legend() #添加x轴标签 plt.xticks([x+0.175 for x in range(len(figdata1))],figdata1.index) #添加图表标签 plt.title('Q2&Q1教师级别分布对比')rotation为标签偏移角度
- 隐藏X轴刻度,便于改为指定标签
plt.xticks([]) - 图例位置调整
plt.legend(loc='right')# plt.legend(loc='xxx') # xxx的取值有以下几种: # ‘best’(默认值):自动选择最佳位置。 # ‘upper # right’:右上角。 # ‘upper # left’:左上角。 # ‘lower # right’:右下角。 # ‘lower # left’:左下角。 # ‘right’:右侧。 # ‘center # left’:左侧中央。 # ‘center # right’:右侧中央。 # ‘lower # center’:底部中央。 # ‘upper # center’:顶部中央。
- 数字换为百分比展示
for (x,y) in zip([x+0.3 for x in range(4)],piv7.iloc[5:9,2]): plt.text(x,y,'{:.2%}'.format(y),fontsize=8)未完待续。。。
















 5870
5870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









