







激活函数
在神经网络中,激活函数分为两种:隐藏层激活函数和输出层激活函数。函数是决定神经网络模型输出的数学方程。换句话说,激活函数是在人工神经网络中添加的一种函数,用于帮助网络学习数据中的复杂模式。它接收来自上一个单元的输出信号,并将其转换为下一个单元可以接受的形式。
所有隐藏层通常使用相同的激活函数。输出层通常会使用与隐藏层不同的激活函数,这取决于模型所需的预测类型。激活函数通常也是可微分的,这意味着可以计算给定输入值的一阶导数。这是必要的,因为神经网络通常使用误差反向传播算法进行训练,该算法需要预测误差的导数来更新模型的权重。(取自:微信公众号@地遥学子 GISer and RSer)
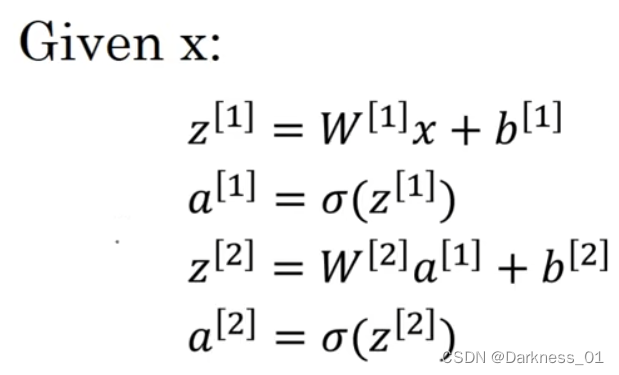
我们在神经网络正向传播当中
这里的sigmoid函数就是激活函数
sigmoid函数
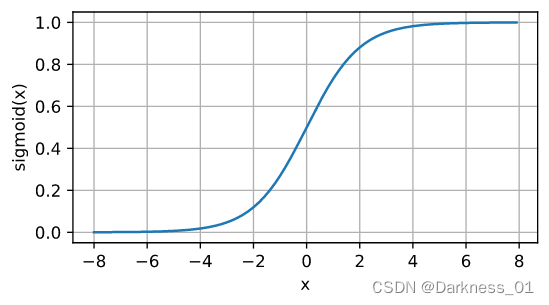
其中下图就是sigmoid函数的图像以及表达式
其中,在不同的情况下,我们可以选择不同的激活函数来进行建立模型,比如,我们可以将下列表达式中的激活函数sigmoid换成其他函数,比如g函数
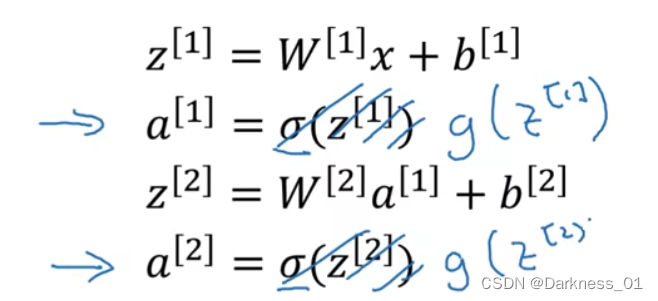
而其中sigmoid函数的值域位于0到1之间
在使用Sigmoid函数作为隐藏层的激活函数时,通常使用“Xavier Normal”或“Xavier Uniform”的权重初始化方法(也称为Glorot初始化,以Xavier Glorot的名字命名),并在训练之前将输入数据缩放到0-1的范围内(例如,与激活函数的范围相同)。这是一种良好的实践。
Tanh函数
而在激活函数当中,始终有一个激活函数的表现要比他好一些
就是tanh函数,或者叫双曲正切函数
Tanh函数接受任意实数值作为输入,并将输出值限定在-1到1的范围内。输入越大(更正向),输出值越接近于1.0;而输入越小(更负向),输出值越接近于-1.0。


从函数图像我们不难看出,tanh函数实际上就是sigmoid函数图像平移后得来
在使用Tanh函数作为隐藏层的激活函数时,通常使用“Xavier Normal”或“Xavier Uniform”的权重初始化方法(也称为Glorot初始化,以Xavier Glorot的名字命名),并在训练之前将输入数据缩放到-1到1的范围内(例如,与激活函数的范围相同)。这是一种良好的实践。
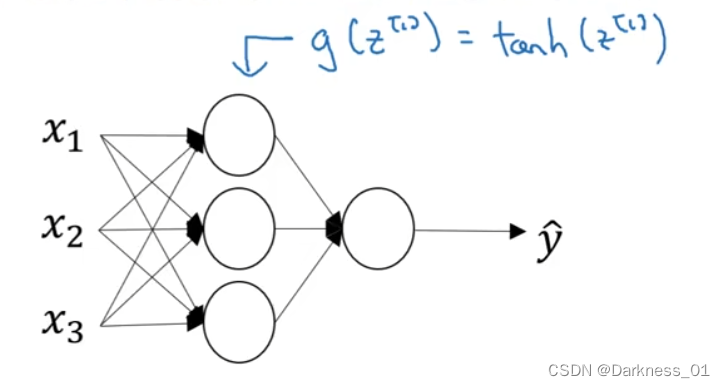
而事实证明,对于隐藏单元,如果将g(z)=tanh(z),这几乎总比sigmoid函数好
因为现在的函数介于-1和1之间,函数的平均值就更接近于0
使用tanh函数而不是sigmoid函数也有类似数据中心化的效果,使得数据的平均值更接近0而不是0.5,这实际上可以让下一层的学习更方便一些。
tanh函数几乎要在任何场合下都比sigmoid函数优越
但是,一个例外是输出层
因为如果y是0或1
那么希望y帽介于0-1之间更合理而不是-1到1之间
而使用sigmoid函数的例外场合则是,当应用二元分类时
在这种场合下可以用sigmoid激活函数来作为输出层

在这个例子中可以用,隐层可以用tanh激活函数,输出层用sigmoid函数
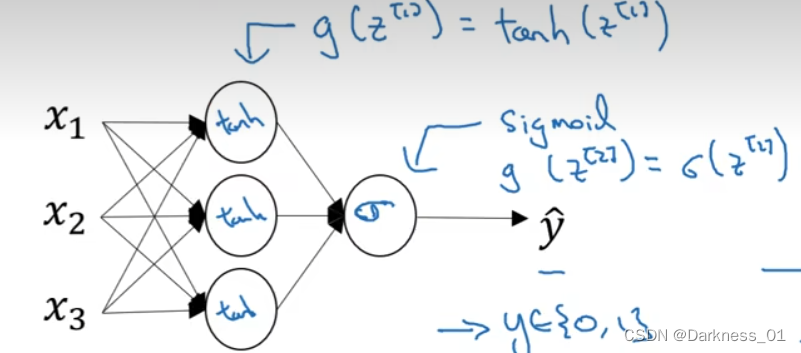
所以不同层的激活函数可以不一样
有时候为了表示不同层的激活函数,我们会选择上标加以区分
面对以上两种激活函数都有一个共同的缺点
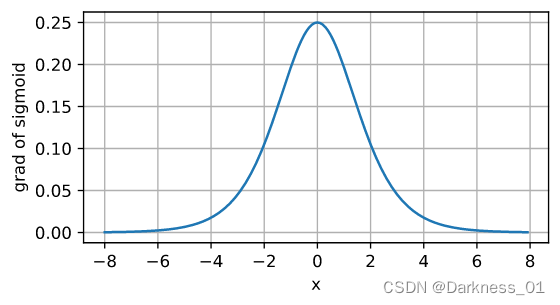
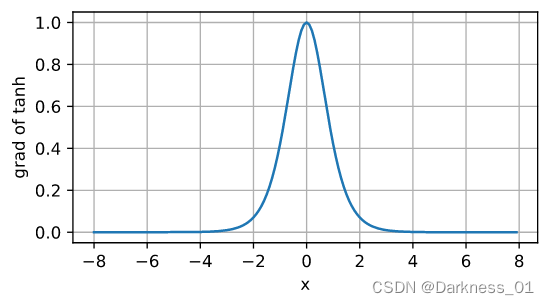
就是当Z非常大或非常小的时候,tanh和sigmoid激活函数的梯度或者斜率都接近于0,这样会拖慢梯度下降算法
sigmoid梯度函数
tanh梯度函数
修正线性单元:ReLU函数
函数图像为
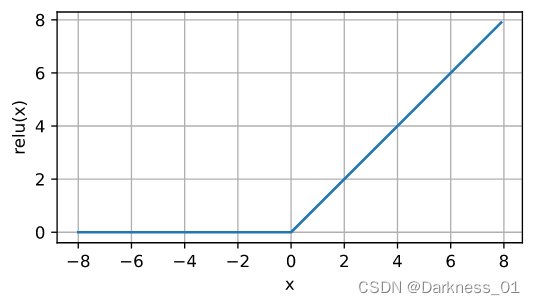
表达式为a=max(0,z)
只要z为正导数就是1,为负数时,斜率就是0
在实际使用中时,如果z刚好为0,导数是没有定义的
但在编程实现的过程当中
Z恰好为0.00000000的概率很低
所以实践中一般不需要担心此问题
可以在Z=0时给导数赋值,可以赋值1或0
在使用ReLU函数作为隐藏层的激活函数时,使用“He Normal”或“He Uniform”的权重初始化方法,并在训练之前将输入数据缩放到0-1的范围(归一化),是一种良好的实践。
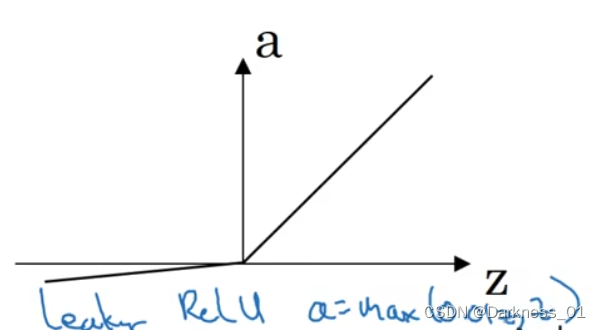
带泄露的ReLU
ReLU还有另一个版本,叫做带泄露的ReLU
即在z为负数时,导数不在为0,而是一个很平缓的斜率
这通常比ReLU激活函数效果更好
不过实际使用的频率不高
选择激活函数
经验法则
如果你输出值是0和1,即在做二元分类时
那么sigmoid函数很适合作为输出层的激活函数
然后其他所有单元都用ReLU,默认选择
如果不确定隐藏用什么激活函数,那就用ReLU
有时候人们也会用tanh函数
ReLU有个缺点就是,当Z为负数时,他的导数为0
在实践中没什么问题
在使用ReLU和带泄露的ReLU时,好处在于对于很多z空间,激活函数的导数,其斜率和0差很远,在实践中使用ReLU激活函数,神经网络的学习速度通常会很快,比tanh和sigmoid函数快得多。
主要原因在于ReLU没有这种函数接近0的时,减慢学习速度的效应
非线性激活函数
为什么神经网络需要非线性激活函数
首先什么是线性激活函数,就那下图为例
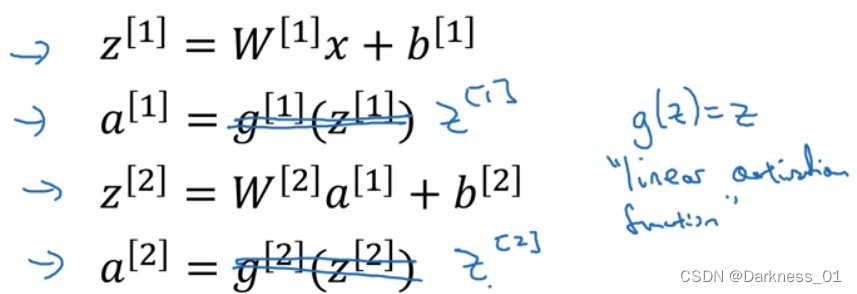
为什么不直接写明a=z或者另g(z)=z
像上述这种格式输出,就叫做线性激活函数,也叫恒等激活函数
因为上述这种格式直接将输入值进行输出了
如果安装上图中这样做,
那么这个模型的输出y或y帽不过是输入特征x的线性组合
如图
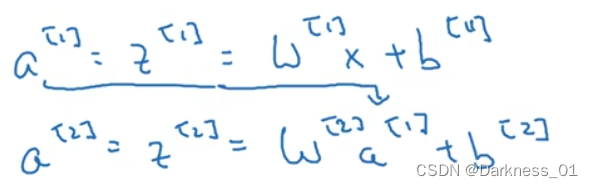
将1式代入2式可得
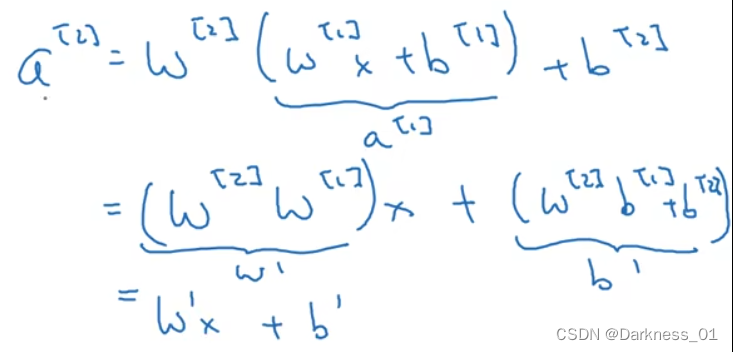
如果使用线性激活函数或恒等激活函数输出,那么神经网络只是把输入线性组合再输出
如果要使用线性激活函数或者没有激活函数,那么神经网络无论有多少层,一直做的只是线性激活函数,所以此时不如直接去掉隐藏层

如果在隐藏层使用线性激活函数,而输出层使用sigmoid函数,那么最后模型的复杂度和没有隐藏层时的标准逻辑logistic回归的复杂度是一样的,线性隐层一点用都没有
只有一个地方可以使用线性激活函数g(z)=z
就是在输出层使用线性激活函数
除此之外,会在隐藏层使用激活函数的情况是可能除了与压缩有关的一些非常特殊的情况,使用线性激活函数非常少见
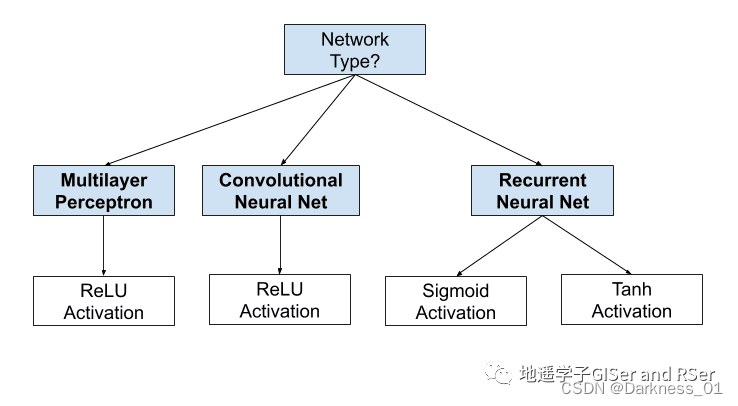
如何选择隐藏层激活函数
现代神经网络模型,如MLP和CNN,通常使用ReLU激活函数或其扩展。循环网络仍然常用Tanh或Sigmoid激活函数,甚至两者兼用。例如,LSTM常用Sigmoid激活函数用于循环连接,而Tanh激活函数用于输出。
以上部分内容源自微信公众号@地遥学子 GISer and RSer)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









