







目录
深层网络中的符号
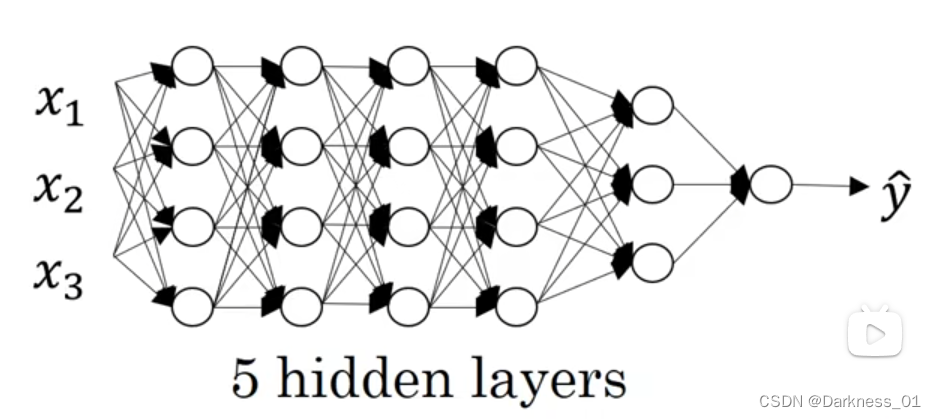
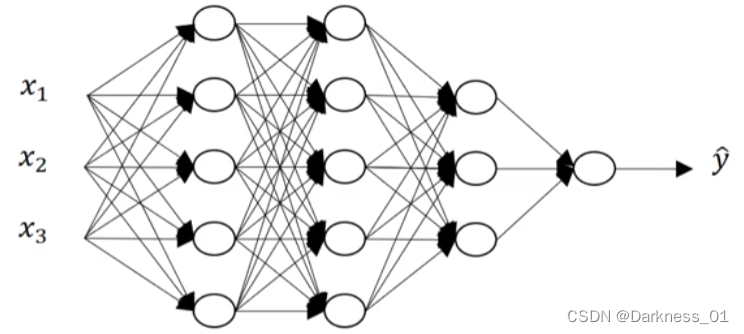
以上是几种神经网络模型,logistic模型,单隐层,双隐层,五隐藏模型
技术层面上来讲,logistic神经网络是浅层神经网络,单层网络
有些函数,只有深层模型可以学习,浅层模型通常无法学习。
所以处理一些问题时需要提前准确地判断需要多深的神经网络 。
这时先试试logistic 回归是非常合理的做法,然后逐层增加
关于神经网络中的符号
层数可以用“l”来表示,即“layer”
其中,输入层不计入,或着记作第零层
第几层的参数可以用n来表示,即第“l”层为“”
下图拿上述五层神经网络举例说明

来表示l层 中的激活函数,
约定使用X来表示特征输入,其中
最后一层的激活函数可以表示为y帽=a[l],a[l]可以用来表示预测输出
深层网络中的前向传播
拿上述深层网络举例
首先,在第一层中,需要先计算
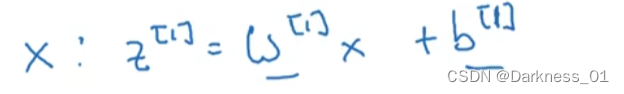
其中x作为一个训练样本,w和b就是会影响激活单元的参数
然后再计算这一 层的激活函数
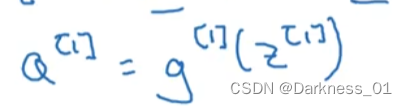
第二层也同样
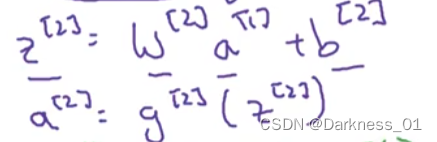
以此类推
得到最后的a[4],结果就是 想要估算的y帽 的值
据此可得知以下公式
使用向量化的方法训练整个训练集
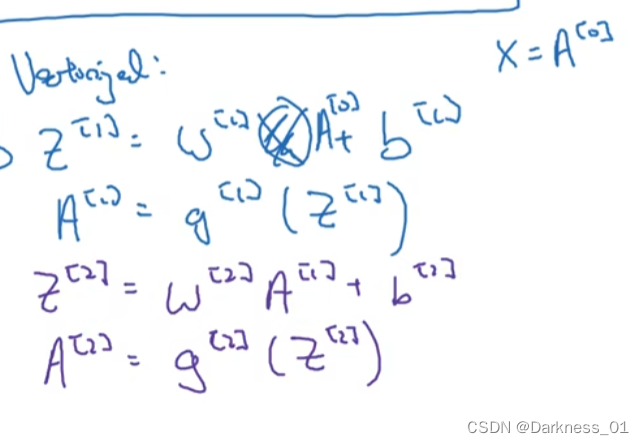
以上表示为向量化表示方法,至此都与普通方法一样
我们关键 要做的是把所有的z或者a向量叠加起来
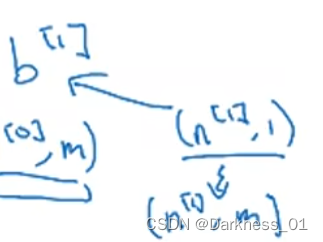
例如Z,从1到样本m进行叠加,形成 列向量,形成矩阵Z,如下图

同理,矩阵A做法也一样
向量化 之后 可以得到y帽
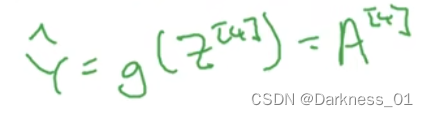
代码实现 可以利用for循环进行l从1到m的循环遍历
核对矩阵的维数
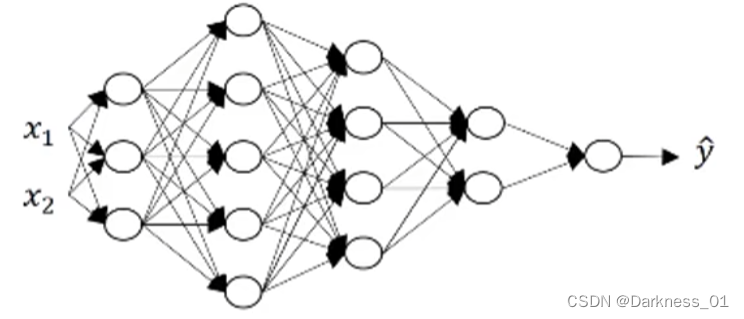
上图为一个五层神经网络模型
要想实现正向传播,首先得到下列式子
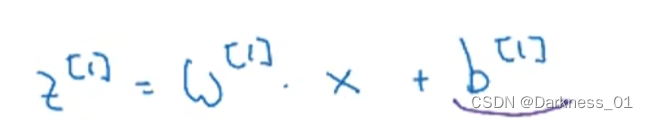
经过分析可得,我们可以得到以下参数的维度,拿上述公式举例
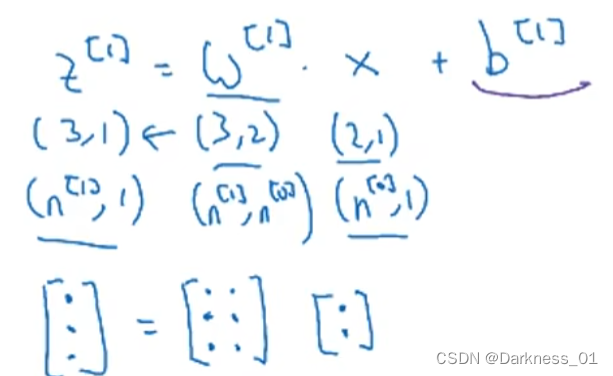
归纳可得参数维度
输入x或a[l-1]
如果在实现反向传播时
则参数dw应该和w有相同的维度
db和b有相同的维度
此外,对于z,x和a的维度
由于
所以a和z的维度相同
向量化后的维度变化
w,b和dw,db的维度始终都是一样的
但是Z,X和A的维度会发生变化
向量化前
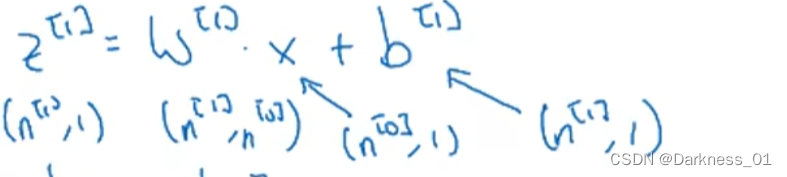
向量化后
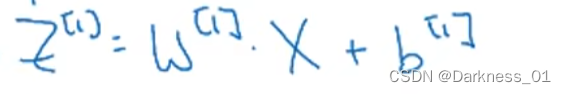
其中Z是由多个z从1到m叠加而来,X同理
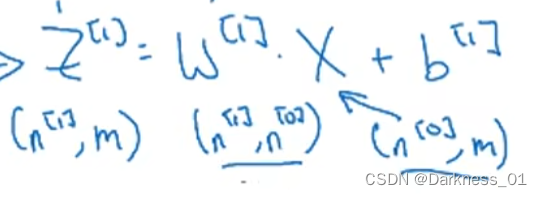
b的维度仍旧不变,但在写代码时python广播机制会改变b
在做反向传播时,dZ和dA的维度和Z和A的一样
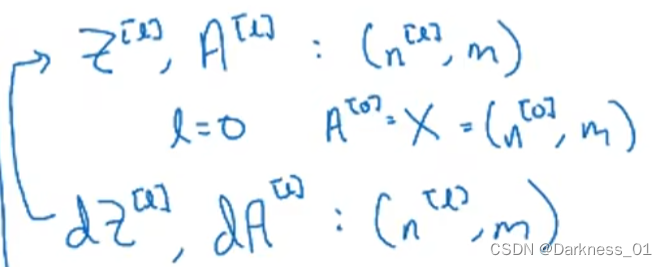
在进行计算时要确认矩阵维度前后一致
为什么深度网络好用
假设在建立一个人脸识别时
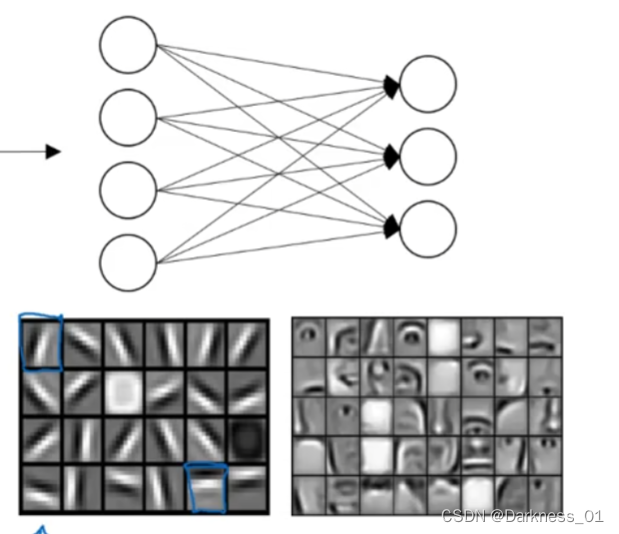
神经网络所做的事就是,第一层可以当成一个特征探测器

在该例子当中可以设立20个隐藏单元的神经网络,隐藏单元就可以是上图中的一个个小方块
可以将边缘探测到的一个个部分组合起来,组合为一个面部的不同部分
可能某个神经元去找眼睛的部分,另一个在找鼻子的部分,然后把许多的边缘结合在一起,就可以开始检测人脸的不同部分,最后再把这些部分放在一起,比如鼻子嘴巴眼睛,就可以识别不同人脸
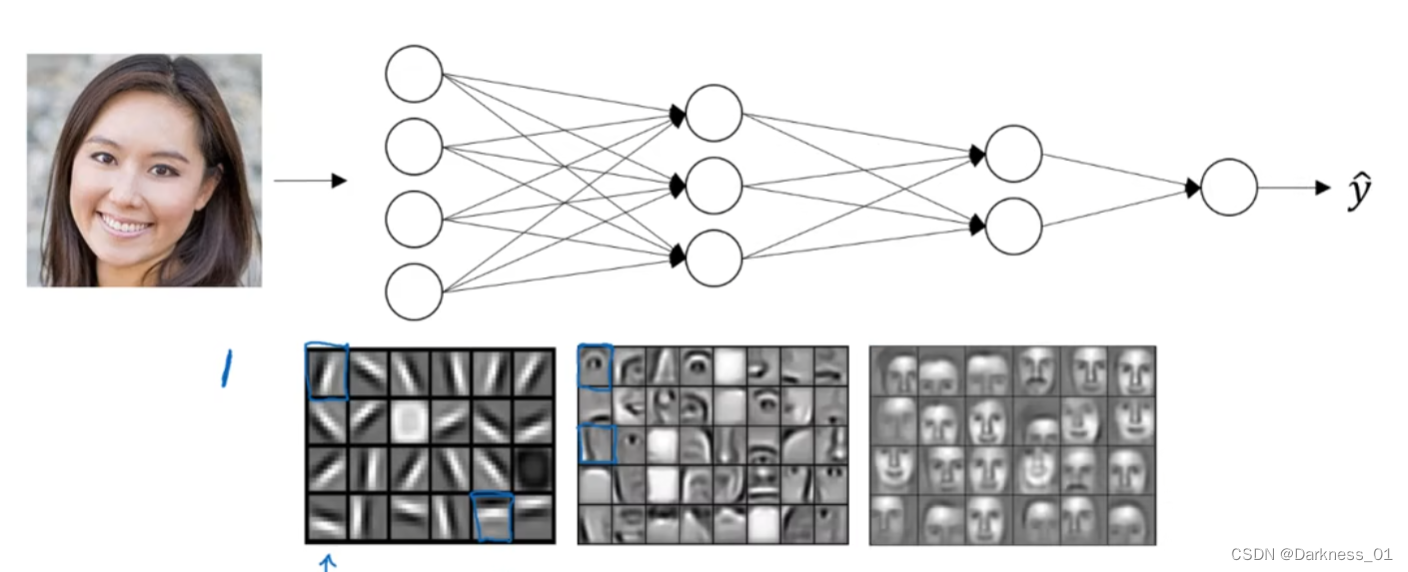
类似地,我们就可以得出,神经网络的许多隐层中,较早的前几层学习一些低层次的简单特征,等到后几层,就能把简单的特征结合起来,去探测更加复杂的东西
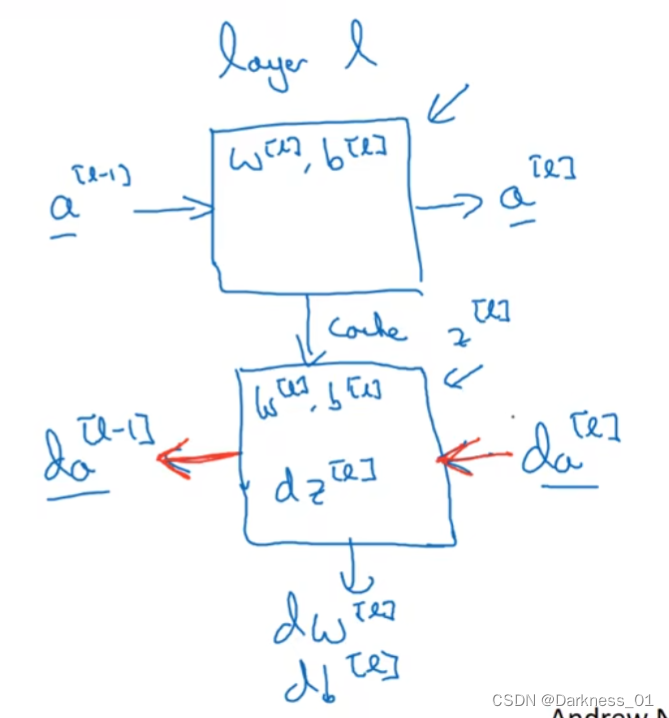
搭建深层学习网络块
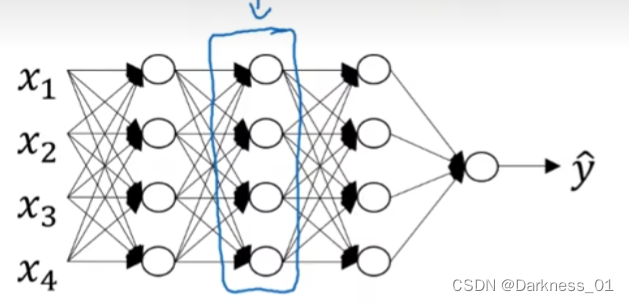
拿上图神经网络模型举例,有参数w,b

正向传播
正向传播里有输入的激活函数a[l-1],输出是a[l]
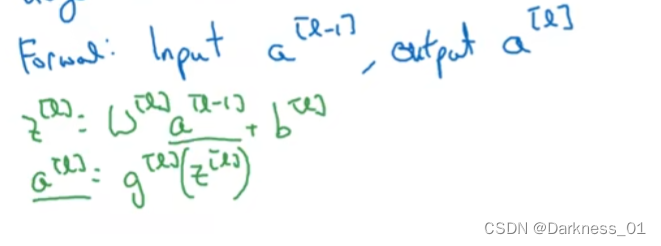
然后可以将z[l]的值存起来


向量法

x用来初始化,即第一层的输入值,对于一个样本的输入特征

反向传播
在反向步骤中
实现一个函数,输入为da[l](以及缓存的z[l]),输出为da[l-1]的函数
其中输出还有梯度,为了实现梯度下降

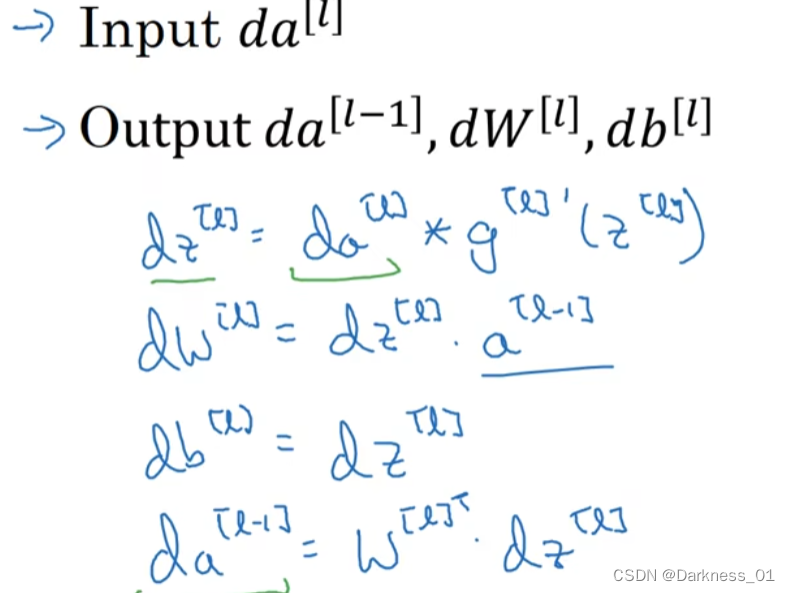
以上代入可得到

向量法
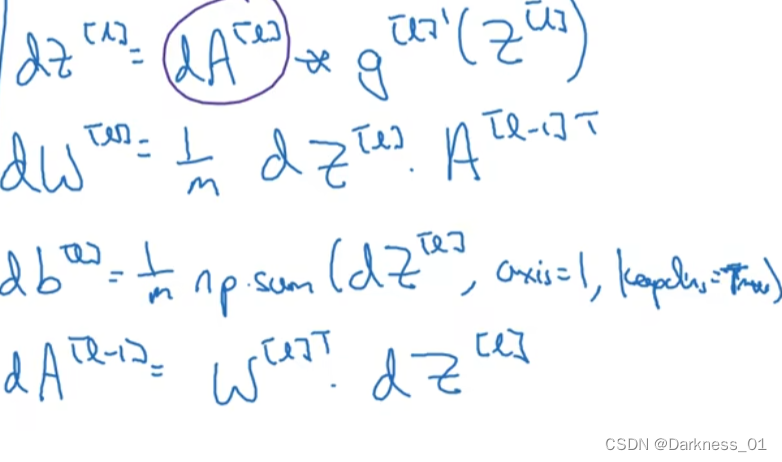
除以m是整体成本函数,不除是一个损失函数
总结
 流程图
流程图
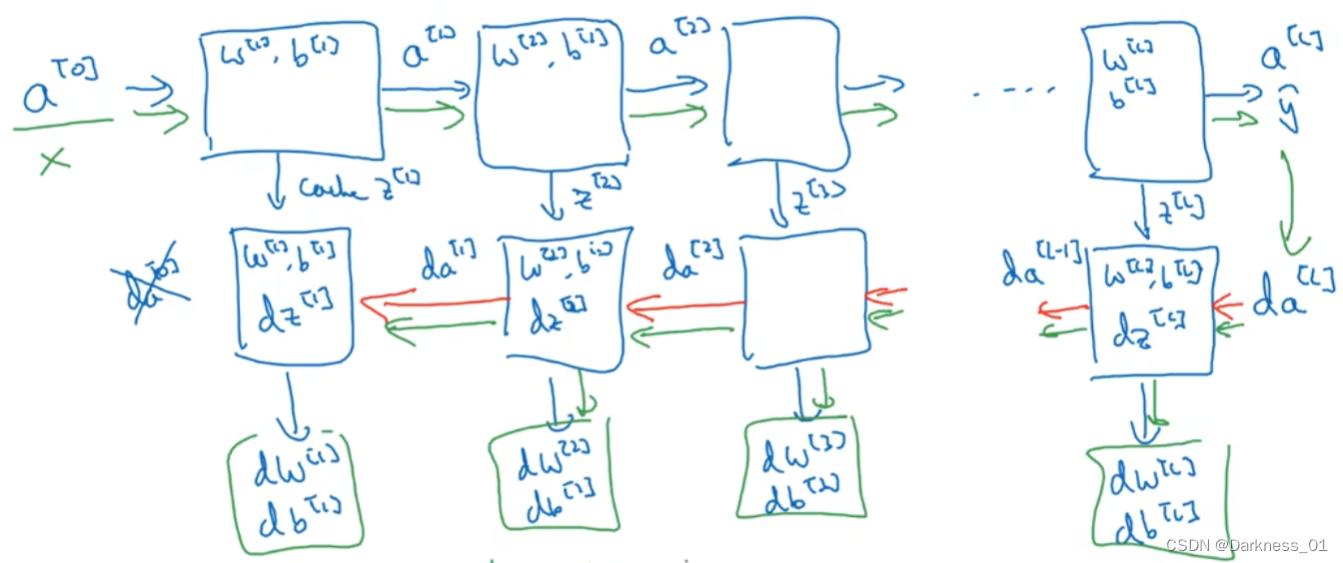
其中w也需要不断更新
每一层都进行

以上就是神经网络的一个梯度下降循环
在实现上对z,w,b的值进行缓存,在实现反向传播时很方便
如有错误还请各位大佬留言指正















 758
758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









