







为什么要随机初始化权重
对于logistic回归,可将权重初始化为0,但如果将神经网络的各参数数组全初始化为0,再使用梯度下降算法,那会完全无效。
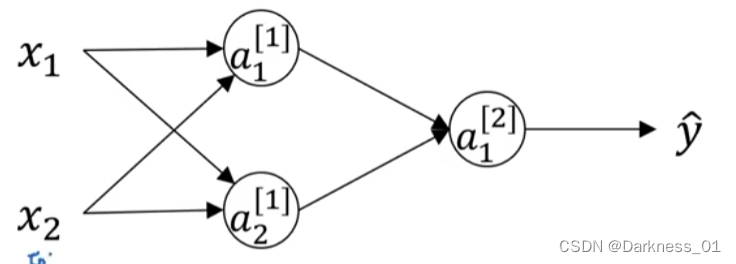
那上述神经网络模型来进行说明
首先有两个输入特征,即
有两个隐藏单元,即
因此,和隐层相关的矩阵是(2,2)的,将其初始化为
将偏置项b初始化为0,即
以上将b初始化为0是可行的,
但是,把W初始化全0,就存在有问题
其所存在的主要问题为,无论给该网络输入任何样本,输入所得到的a1,a2均为相同的
即所得到两个激活函数是完全一样的
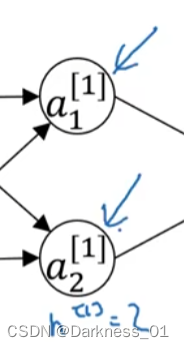
因为两个隐藏单元都在做完全一样的计算
当做反向传播的时候,出于对称性dz1,dz2所得到的结果也是相同的

这两个隐藏单元会以同样方式初始化,
技术上,假如说输出的权重也是一样的,所以w2就等于0,即
如果以上述这样的方式进行初始化,所得到的两个隐藏单元完全一样,这就是所谓的完全对称
意味着节点计算完全一样的函数
可通过数学归纳法进行证明,经过多次迭代后,两个隐藏单元仍然在计算完全相同的函数
因此在这儿种情况下,多个隐藏单元没有意义,因为计算的都是同样的东西
对于更大的神经网络,或者输入有三个特征,或者隐藏单元的数目非常多
如图:
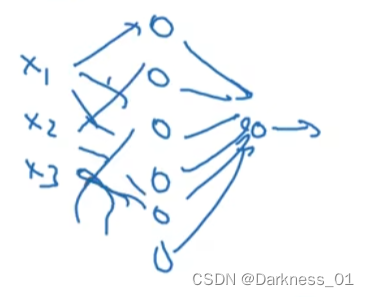
可以用类似的昂啊证明如果把所有权重都初始化为0,那么所有的隐藏单元都是对称的,不管跑多久梯度下降它们都在计算一样完全一样的函数,所以没有什么用,因为需要不同的隐藏单元计算不同的函数
解决方案
因此针对此问题的解决方案就是随机初始化所有参数
W^[1]=np.random.randn((2,2))这可以产生参数为(2,2)的高斯分布随机变量
然后再乘以一个很小的数字,例如0.01,就可以将权重初始化为很小的随机数
对于参数b而言,b完全没有这个对称性问题,没有破坏性对称问题
所以可以将b初始化为0
b^[1]=np.zeros((2,2))类似地对于w2,也可以同w1进行随机初始化,b2也可以初始化为0
tips:为什么是0.01,而不用100或1000之类的数字
通常我们喜欢将权重矩阵初始化为很小很小的随机值
因为,如果用的额是tanh或者sigmoid激活函数,或者在输出层有一个sigmoid函数,如果权重太大,当计算激活函数值时
根据公式
然后,是应用于z^[1]的额激活函数
所以如果w很大,z就会很大,或者z值会很大或很小,在这种情况下,结合tanh和sigmoid函数图像可得到,最后的值可能落在其平缓部分,梯度的效率非常小,梯度下降法会很慢,学习就会很慢。

所以,如果w一开始很大,就会在训练时就落在z很大的区域,导致tanh或sigmoid激活函数接近饱和,从而减慢学习速度。
但如果神经网络当中没有任何sigmoid或tanh激活函数,可能问题没有那么大
但是如果在做二分类时,如果输出单元是sigmoid函数,那么初始参数就不要太大,0.01就较为合理,或者任意其他小数字,对于初始化w2也是同样的道理
实际上,有时也有比0.01更好用的常数
当训练一个单隐层神经网络时,是一个相对较浅的神经网络,没有太多隐藏层,设为0.01也还是可以,但是在训练一个很深的神经网络时,可能会尝试0.01以外的常数。
但不管怎样,初始化参数一般都会很小。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









