定义
- 开散列法,又称链地址法(拉链法或哈希桶),首先对关键码集合用散列函数计算散列地址,把具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
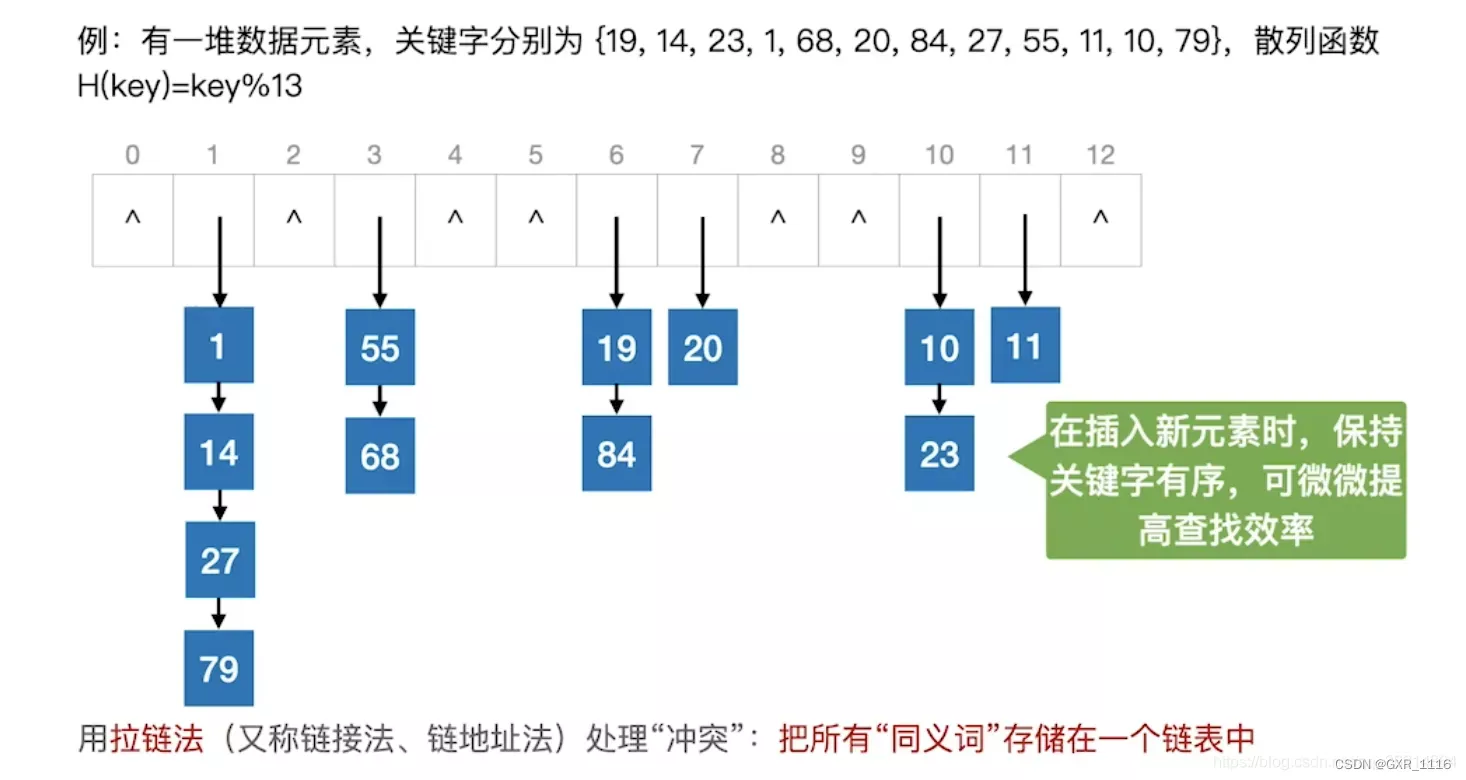
基于闭散列法实现哈希
1)实现基本框架
hashNode
template <class K, class V>
struct HashNode{
HashNode<K, V>* _next;
pair<K, V> _kv;
HashNode(const pair<K, V>& kv)
:_next(nullptr),
_kv(kv){
}
};
hashTable
template <class K, class V, class HashFunc>
class HashTable{
private:
vector<HashNode<K, V>*> _table;
size_t _n;
};
构造函数
拷贝构造
HashTable(const hashtable& ht){
_n = ht._n;
_table.resize(ht._table.size());
for (size_t i = 0; i < ht._table.size(); i++){
node* cur = ht._table[i];
while (cur){
node* newnode = new node(cur->_data);
newnode->_next = _table[i];
_table[i] = newnode;
cur = cur->_next;
}
}
}
析构函数
~HashTable(){
for (size_t i = 0; i < _table.size(); i++){
node* cur = _table[i];
while (cur != nullptr){
node* tailnode = cur->_next;
delete cur;
cur = tailnode;
}
_table[i] = nullptr;
}
}
2)实现基本操作
insert插入操作
- 判断是否需要插入-----是否需要增容(负载因子>=1)-----待插入位置-----单链表头插法插入元素
- 增容时,尽量让哈希表的表长为素数
bool insert(const pair<K, V>& kv){
node* ret = find(kv.first);
if (ret != nullptr){
return false;
}
HashFunc hf;
if (_n == _table.size()){
vector<node*> newtable;
newtable.resize(_table.size() == 0 ? 8 : GetNextPrime(_table.size()));
for (int i = 0; i < _table.size(); i++){
if (_table[i] != nullptr){
node* cur = _table[i];
while (cur){
node* curnext = cur->_next;
int index = hf(cur->_kv.first) % newtable.size();
cur->_next = newtable[index];
newtable[index] = cur;
cur = curnext;
}
_table[i] = nullptr;
}
}
swap(_table, newtable);
}
size_t index = hf(kv.first) % _table.size();
node* newnode = new node(kv);
newnode->_next = _table[index];
_table[index] = newnode;
_n++;
return true;
}
find查找操作
node* find(const K& key){
if (_table.size() == 0)
return nullptr;
HashFunc hf;
size_t index = hf(key) % _table.size();
node* cur = _table[index];
while (cur != nullptr){
if (cur->_kv.first == key)
return cur;
cur = cur->_next;
}
return nullptr;
}
erase删除操作
bool erase(const K& key){
HashFunc hf;
size_t index = hf(key) % _table.size();
node* prev = nullptr;
node* cur = _table[index];
while (cur != nullptr){
if (cur->_kv.first == key){
if (cur == _table[index]){
_table[index] = cur->_next;
}
else{
prev->_next = cur->_next;
}
delete cur;
--_n;
return true;
}
else{
prev = cur;
cur = cur->_next;
}
}
return false;
}
3)实现其迭代器
- 哈希表的底层是单链表结构,因此迭代器不需要operator–操作
template <class K, class T, class KeyOfT, class HashFunc>
class HashTable;
template <class K, class T, class KeyOfT, class HashFunc>
struct HTIterator{
typedef HashNode<T> node;
typedef HashTable<K, T, KeyOfT, HashFunc> HT;
typedef HTIterator<K, T, KeyOfT, HashFunc> self;
node* _node;
HT* _pht;
HTIterator(node* node, HT* pht)
:_node(node),
_pht(pht){
}
T& operator*(){
return _node->_data;
}
T* operator->(){
return &_node->_data;
}
bool operator!=(const self& s){
return _node != s._node;
}
bool operator==(const self& s){
return _node == s._node && _pht == s._pht;
}
self& operator++(){
if (_node->_next){
_node = _node->_next;
return *this;
}
else{
HashFunc hf;
KeyOfT kot;
size_t index = hf(kot(_node->_data)) % _pht->_table.size();
++index;
while (index < _pht->_table.size()){
if (_pht->_table[index]){
_node = _pht->_table[index];
return *this;
}
else{
++index;
}
}
_node = nullptr;
}
return *this;
}
};























 374
374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









