






地下暗渠作为城市的“排水动脉”,在防洪排涝、水污染防治等方面发挥着至关重要的作用。然而,随着城市的快速发展和水污染治理任务的日益紧迫,如何高效准确地获取地下暗渠的空间属性信息,成为暗渠治理与改造的关键挑战。

近期,大势智慧接到某地客户咨询,想利用SLAM激光扫描仪,提高地下暗渠扫描建模的作业效率。通过沟通了解到,该项目目前正使用架站式扫描仪进行扫描工作,工作量大,后期拼接繁琐,拖慢了项目的整体进度。智影技术团队现场踏勘,结合实际情况深入分析,制定了基于SLAM三维激光扫描仪的地下暗渠扫描解决方案。

SLAM实时定位与地图构建技术:无需GPS辅助定位,在进行移动测量时,可根据地物环境的特征与地图进行定位,同时将获取的三维空间数据用来制造增量式地图,完成地图的构建,可达到厘米级测绘精度。
方案可实现地下空间自主定位和导航,一次性采集,快速构建高精度的地下暗渠模型,并基于采集的点云+影像数据获取地下排水口的坐标、管径等信息。为城市暗渠的治理、改造及日常维护提供科学依据。具体技术方案如下图:
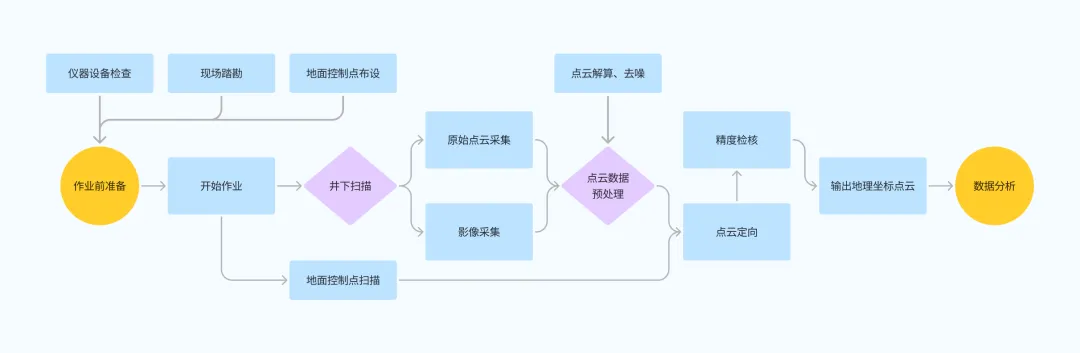
该项目的具体实施过程如下:
一、外业数据采集
1、地面控制点布设与测量
由于井下暗渠环境特殊,空间封闭且多为条状分布,因此,控制点均布设在地面上。

2、手持激光雷达采集
智影R100 Pro在暗渠内部狭小的空间易于携带,设备组装简单,开机后平稳放置于地面,静置10秒即可开始作业。
作业人员在做好防护措施后,按照技术方案流程,手持激光扫描仪完成地面控制点采集后,下到井下开始扫描。

扫描时需注意:
①为提高排水口的点云密度,可适当减慢行走速度,或调整激光头扫描姿态使其对准排水口;
②井下光线昏暗,下井前可以准备一个补光灯。
二、内业数据处理
内业数据处理阶段包括点云解算、去噪、精度核验、数据量测等步骤。
智影R100 Pro自带一站式后处理软件“智影模形”,软件集成了点云解算、点云赋色、点云去噪优化、点云裁切、双屏浏览、点云建模等多个实用功能,操作简单,无需专业经验即可上手操作。
1、点云解算
将采集的原始点云+影像数据导入智影模形中,勾选上想要的点云加工模块后,即可提交解算任务,省去了繁冗的参数设置工作。此外,智影模形还可根据不同场景的特点,提供不同的解算算法。
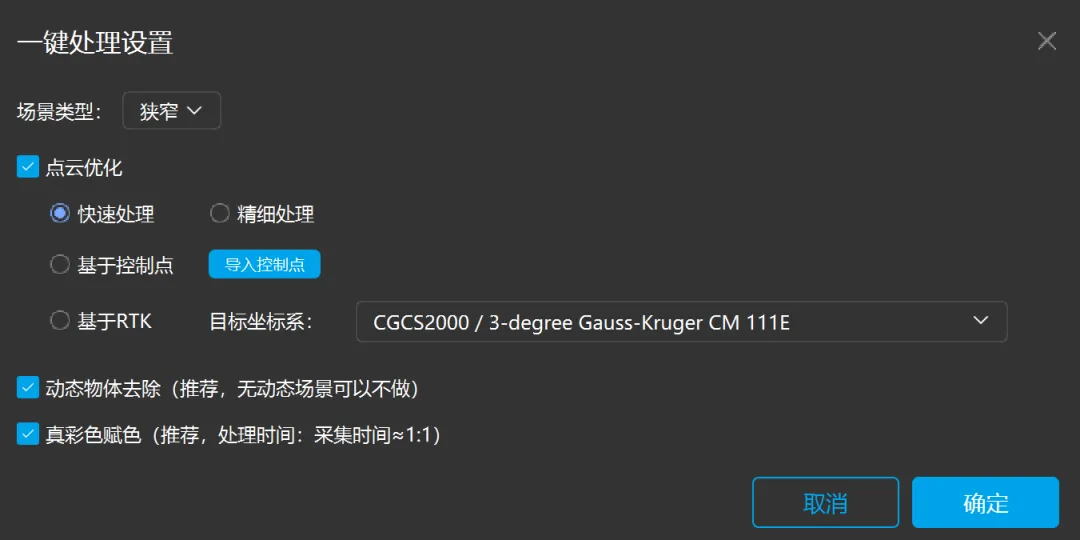
本项目扫描所用解算策略:狭窄类场景+精细处理+基于控制点+动态物体去除+真彩色赋色
基于控制点:外业采集的控制点参与点云定向的同时,也参与了点云优化,可简单理解为非刚性变换
2、点云去噪
点云解算前可勾选上动态物体去除,解算出来的即是去噪后的点云,具体去噪效果如下:

去噪前

去噪后
三、成果质检
1、点云质量检查
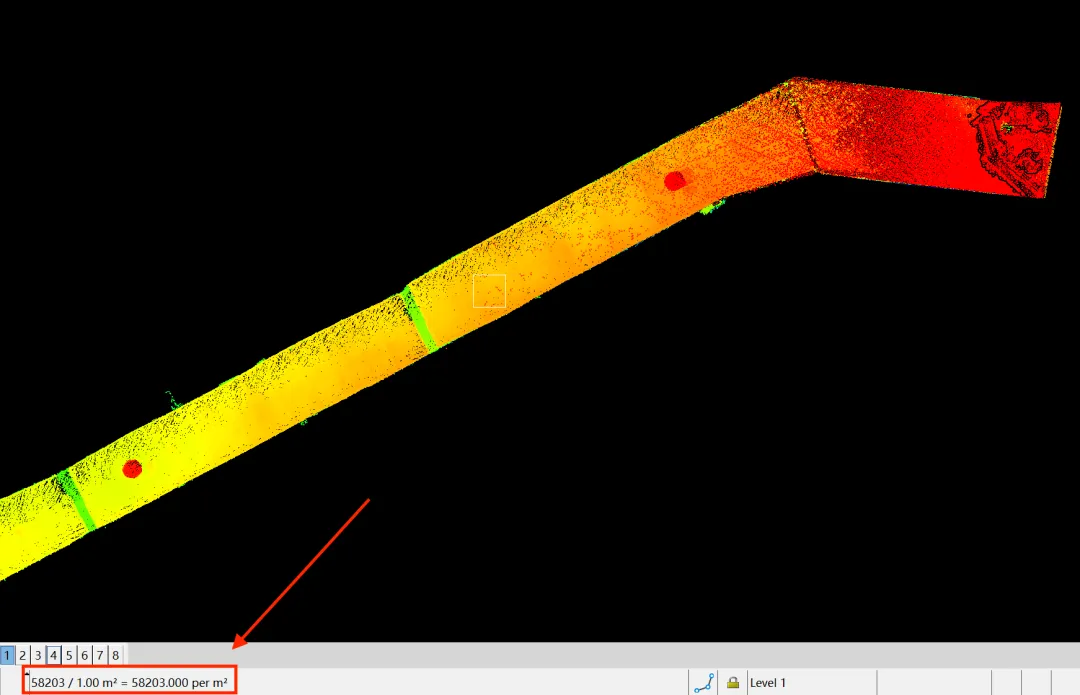
地下暗渠平均点密度:58203点/m²

排水口清晰可见

点云厚度:2cm
2、点云精度检
对点云进行定向处理后,智影模形会自动生成点云精度报告,如下图:
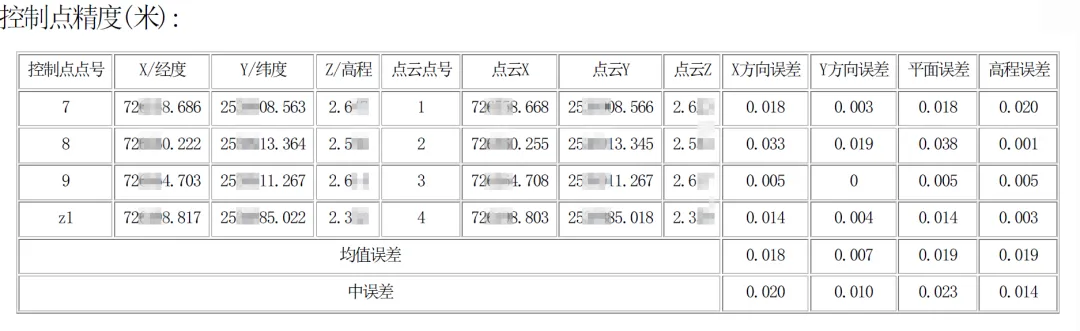
根据报告得出点云平面中误差为0.02m;高程中误差为0.01m,符合项目要求。
四、分析应用
1、照片测量,获取排水管口三维空间信息
根据项目要求,需要获取地下排水口的管径、地口坐标等信息。传统点云量测的方法是通过缩放视图、拖动视角来获取,这种方法效率较低,甚至还会出现穿透测量的问题,影响数据精度。
智影模形提供“点云+照片”预览模式,可将两种数据叠加在一起,用户能够直接在二维照片上量测排水口的圆径、底口坐标。整个量测过程中数据直观、清晰,量取的成果准确,大幅度提高了作业效率。
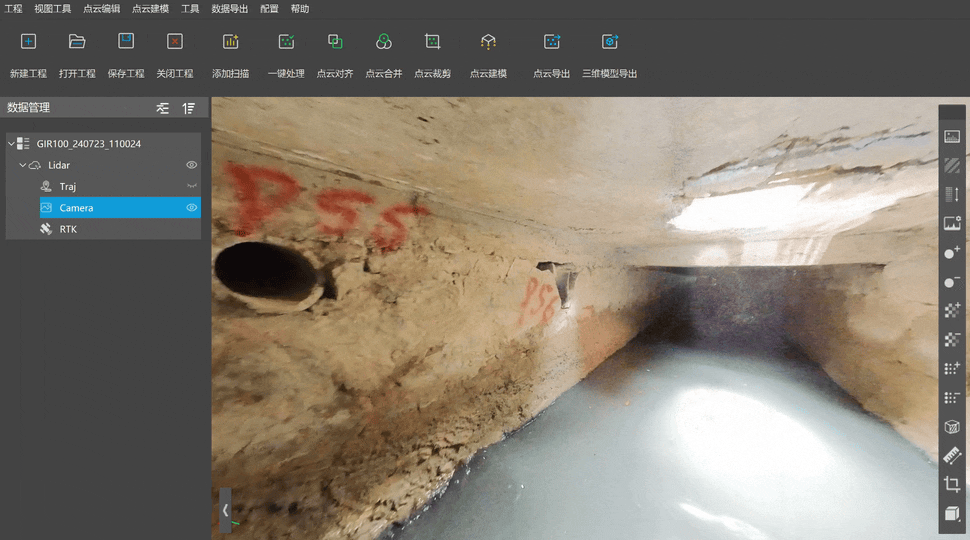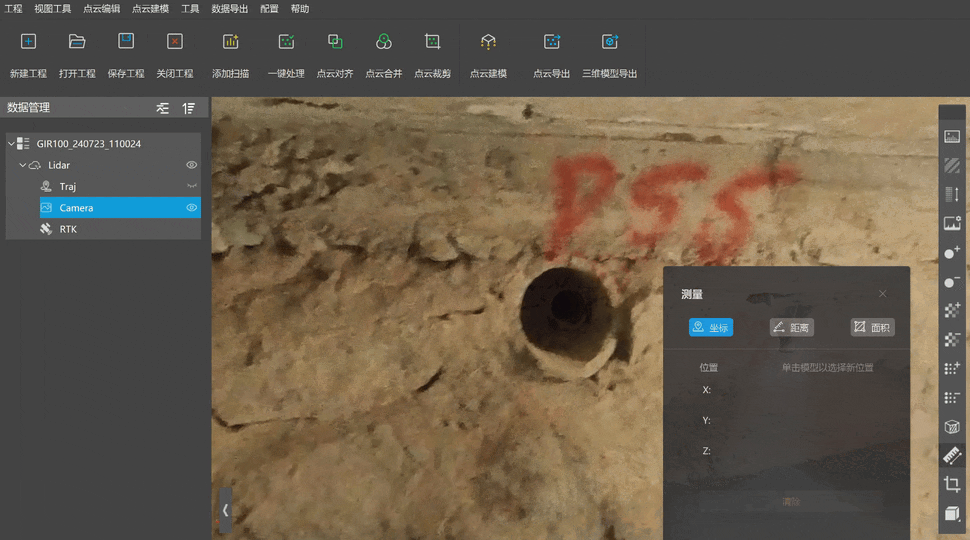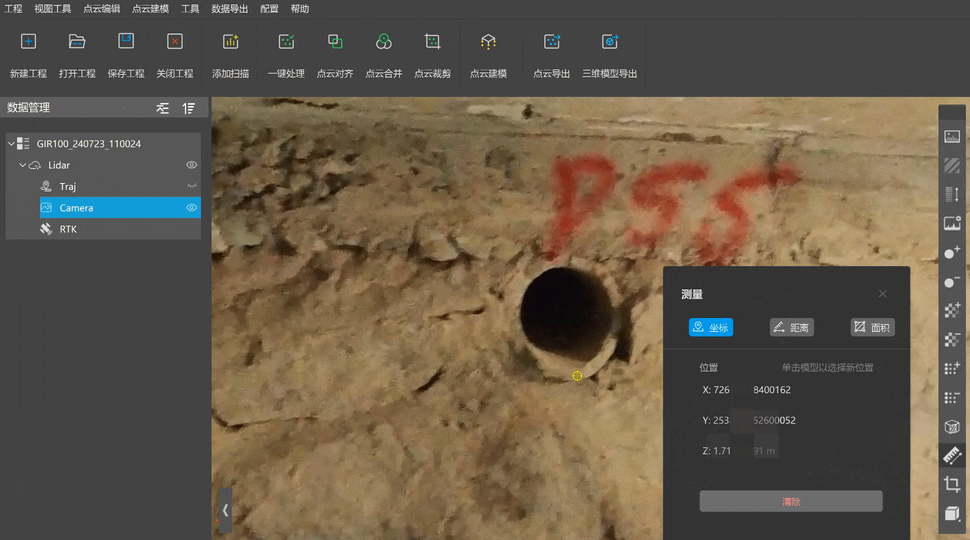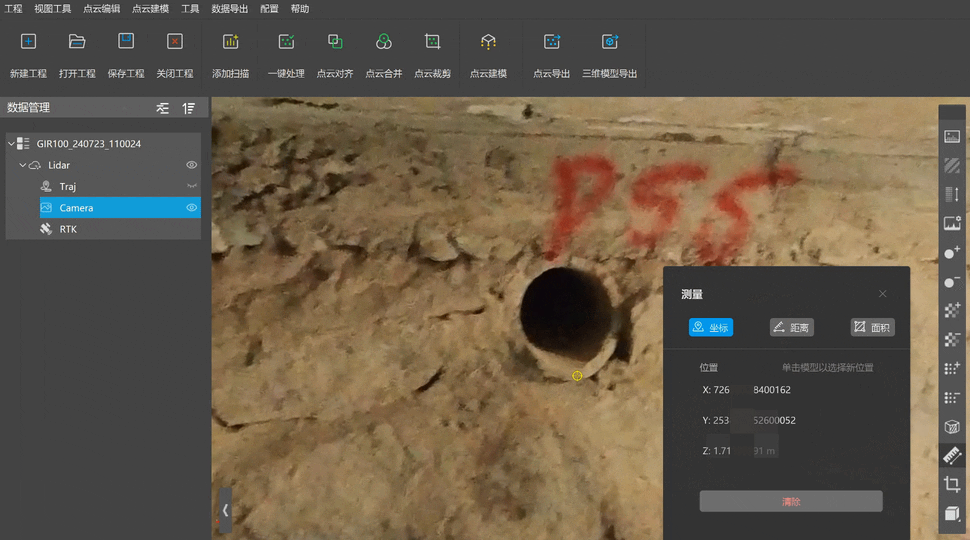
基于测量点云成果,最终得到如下信息表格,包括排水口形状、照片、点云、管底三维坐标:
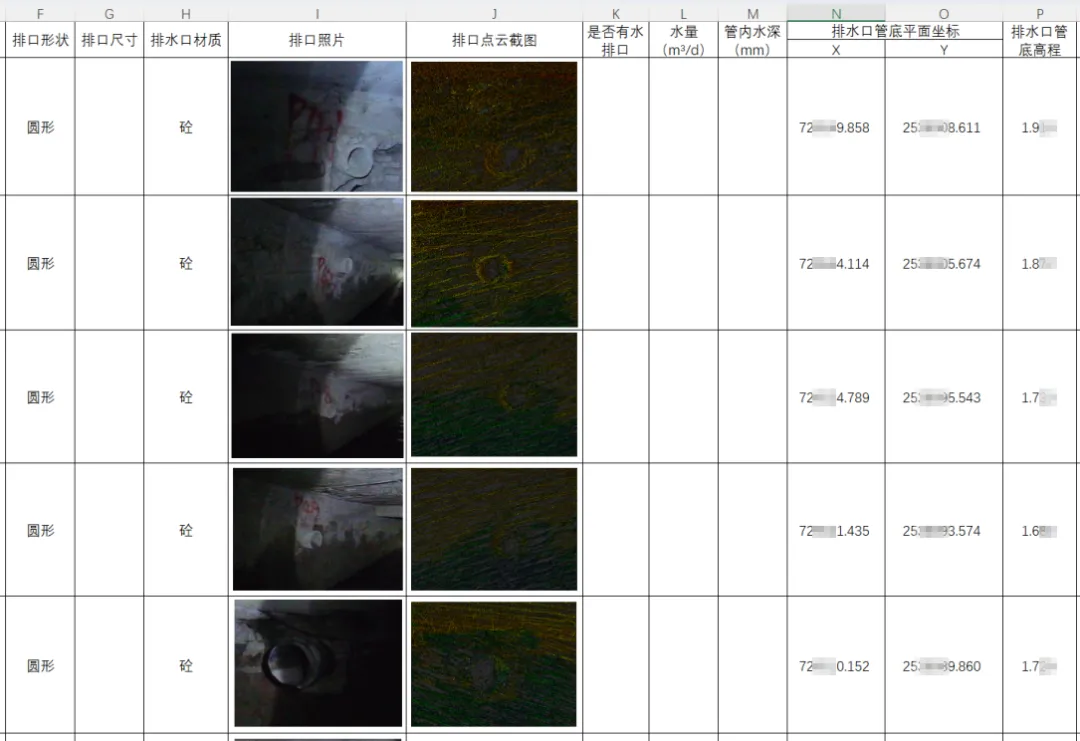
2、线划图绘制
将智影R100 Pro生成的点云成果和排水口三维坐标数据导入到第三方制图软件中绘制线划图,形成地下暗渠空间分布图,成果如下:
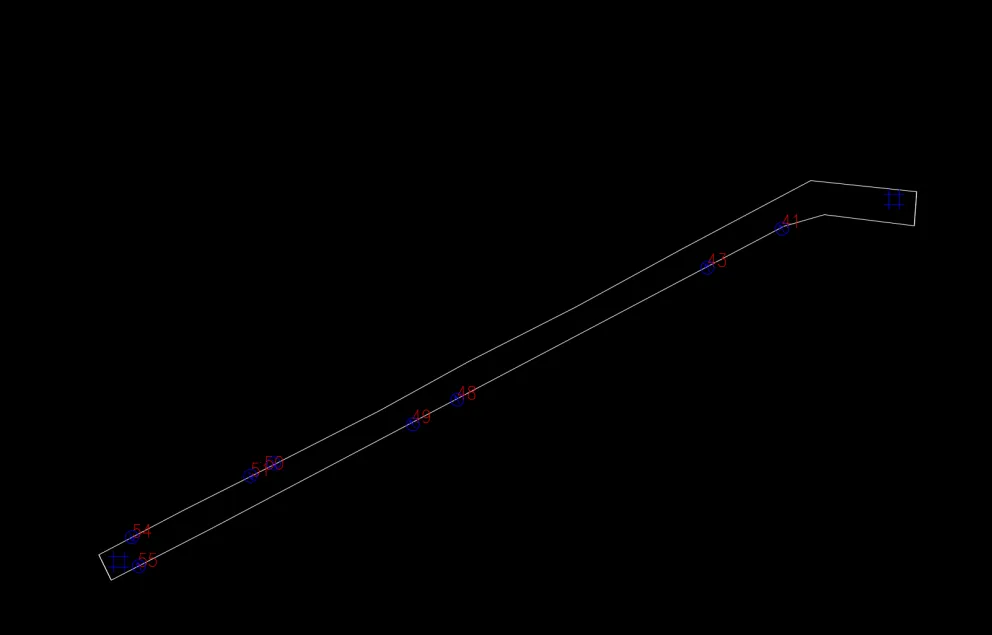
方案优势
- SLAM三维激光扫描方式,可以避免采集人员反复下井,保证人员安全;
- 技术手段便捷,作业简单,适用于复杂地下场景的高精度、高效率探测扫描;
- 布设在地面上的控制点可以参与点云定向解算,消除数据采集中积累的误差,保证数据精度;
- 智影模形支持照片三维量测、坐标定位和空间分析,创新数据分析方式,更精准直观;
- R100 Pro生成的高精度点云成果能重建井下暗渠结构特点,满足暗渠治理、改造以及地下空间规划、设计、施工等场景需求。
基于智影SLAM地下暗渠解决方案,项目成功完成了排水管口的空间测量分析和暗渠线划图绘制,成果精度满足项目要求,为当地水系污染治理和市政建设提供可靠依据。
此外,方案还可根据场景和需求的变化灵活调整,提供定制化的解决方案。我们诚挚邀请欢迎广大用户携手,一同开拓更多创新应用场景!

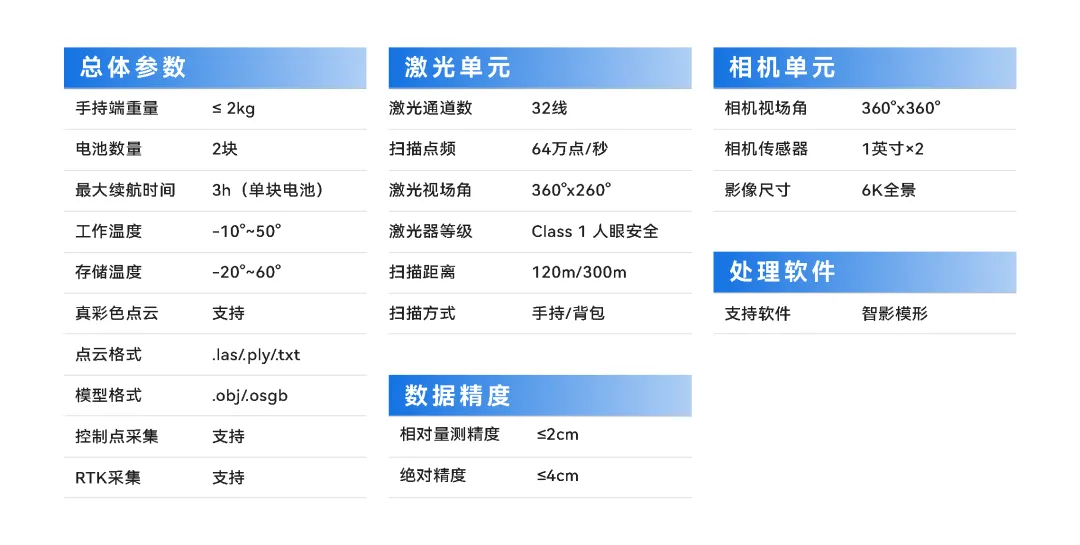
智影R100 Pro详细设备参数















 888
888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









