






🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:Motion Anything: Any to Motion Generation
论文链接:https://arxiv.org/pdf/2503.06955
开源代码:https://steve-zeyu-zhang.github.io/MotionAnything

导读
近年来,由于人类运动生成在电影制作、视频游戏、增强和虚拟现实 (AR/VR) 以及用于人机交互的具身人工智能等领域具有广泛的应用,因此得到了广泛的探索。条件运动生成领域的最新进展,包括文本到运动和音乐到舞蹈模型,在 3D 运动生成方面显示出了良好的潜力。这些进展标志着在直接从文本描述和背景音乐生成运动序列方面取得了重大进展。
简介
条件运动生成在计算机视觉领域已得到广泛研究,但仍存在两个关键挑战。首先,尽管掩码自回归方法最近在性能上超越了基于扩散的方法,但现有的掩码模型缺乏一种机制,无法根据给定条件对动态帧和身体部位进行优先级排序。其次,现有的针对不同条件模态的方法往往无法有效整合多种模态,限制了生成运动的可控性和连贯性。为应对这些挑战,我们提出了“Motion Anything”,这是一个多模态运动生成框架,引入了基于注意力的掩码建模方法,能够对关键帧和动作进行细粒度的时空控制。我们的模型能够自适应地编码包括文本和音乐在内的多模态条件,提高了可控性。此外,我们还推出了文本 - 运动 - 舞蹈(Text - Motion - Dance,TMD)这一全新的运动数据集,该数据集包含2153对文本、音乐和舞蹈数据,规模是AIST++的两倍,从而填补了该领域的一个关键空白。大量实验表明,“Motion Anything”在多个基准测试中超越了现有最先进的方法,在HumanML3D数据集上的弗雷歇 inception 距离(Frechet Inception Distance,FID)指标上提升了15%,并且在AIST++和TMD数据集上也取得了持续的性能提升。
方法与模型
1. 概述
“任意动捕”(Motion Anything)提出了一种创新的任意到动作生成方法,该方法通过聚焦人体动作序列中的动态关键部分,并自适应地与不同的条件模态对齐,从而生成可控的人体动作。如图3所示,“任意动捕”可以单独或同时采用不同的模态,实现多模态条件约束,以增强可控动作生成能力,而不是依赖单一条件。这些条件首先由文本和音频编码器进行编码,然后用于指导掩码操作和动作生成。我们提出了一种基于注意力机制的掩码方法,通过选择高注意力分数作为掩码指导,在空间和时间维度上识别与条件相对应的动作中最重要的部分。然后,将引导掩码标记与条件嵌入一起输入到掩码变换器中进行引导掩码恢复。我们将掩码变换器定制为时间自适应变换器和空间对齐变换器,以自适应地将整体控制和特定动作与动作序列对齐。
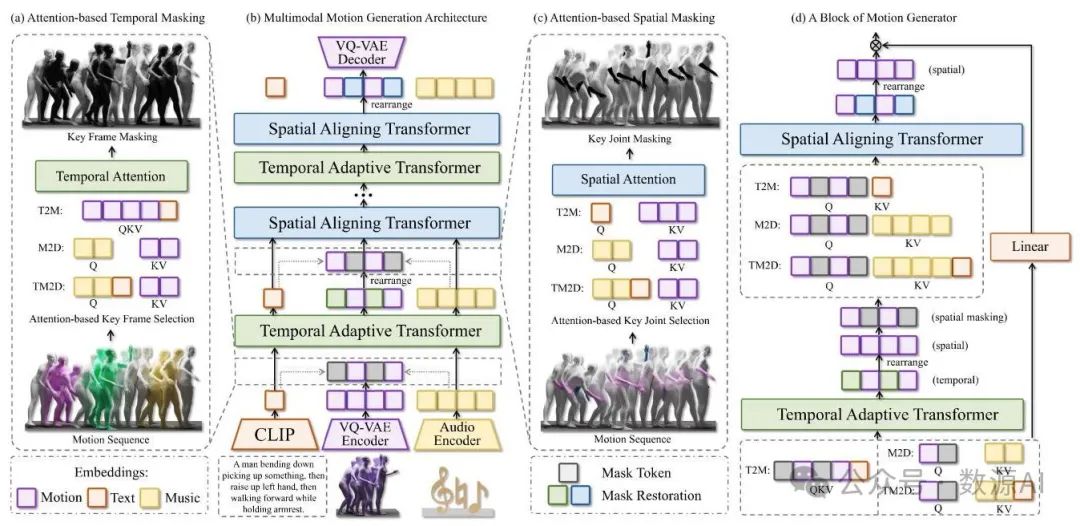
图3. 任意动作生成架构。该多模态架构由几个关键组件组成:(a) 基于时间和(c) 空间注意力的掩码,(b) 动作生成器,以及(d) 动作生成器的单个模块。这些组件使模型能够学习与给定条件相对应的关键动作,并促进多模态条件与动作特征之间的对齐。
2. 架构
基于注意力机制的掩码。基于注意力机制的掩码的核心在于引导条件模态在时间维度上选择关键帧,在空间维度上选择关键动作,从而实现对这些动作的掩码处理。如图4中的注意力图所示,时间和空间注意力均依赖于自注意力或交叉注意力机制[56],具体取决于条件模态。条件作为查询项(),动作作为键()和值(),其中条件可以是文本、音频或两者的组合。这一过程会在注意力图中突出特定区域,这些区域代表关键动作。我们在时间和空间维度上都设计了基于注意力机制的掩码,以确保模型专注于学习运动序列中与条件相对应的关键帧和关节,如图3 (a)和(c)所示。与传统的随机掩码方法[21, 64]相比,这使得模型能够学习到更稳健的运动表示。
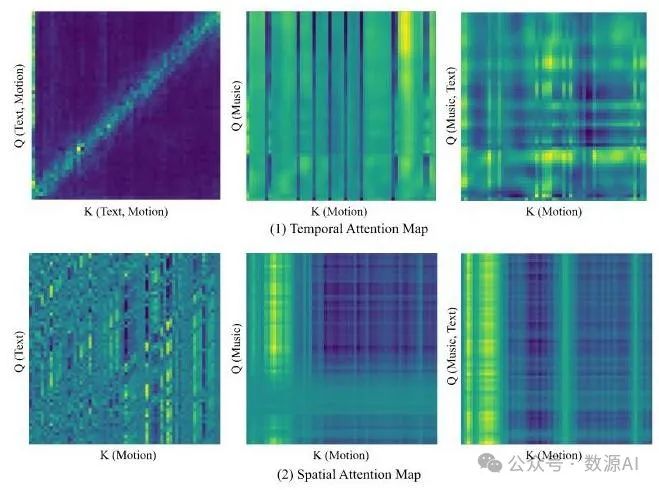
图4. 注意力图。注意力图直观展示了我们基于注意力机制的掩码方法,该方法会选择性地对运动序列中注意力得分较高的区域进行掩码处理。
如算法1所示,给定一个运动序列、一个条件和一个掩码比率,该模型会对注意力得分最高的部分进行掩码处理,这些得分代表了最重要且与相应条件最相关的运动。

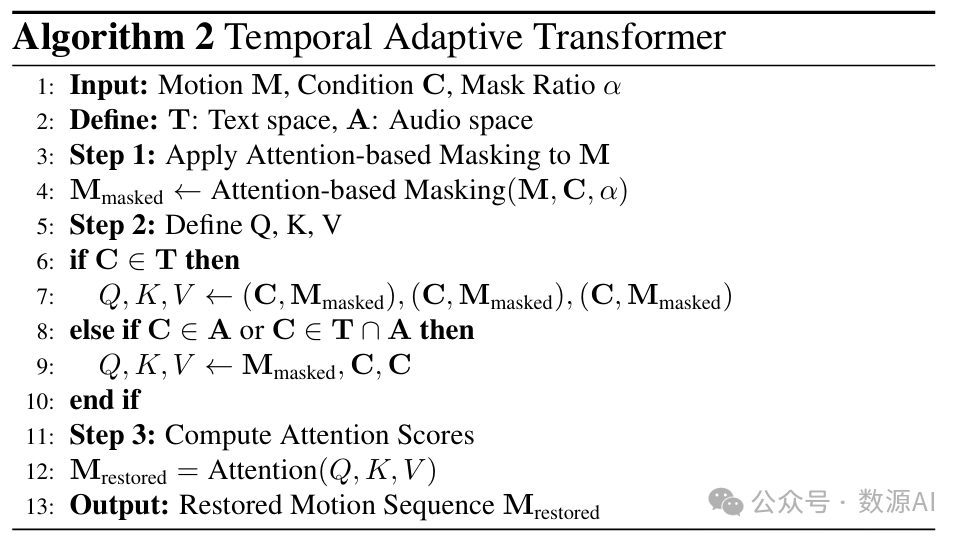
时间自适应Transformer。时间自适应Transformer(TAT)通过根据条件的模态动态调整其注意力计算,将运动序列的时间标记与时间条件对齐。这使得TAT能够将运动的关键帧与文本中的关键词以及音乐中的节拍对齐。
如算法2和图3 (d)所示,在基于注意力机制的掩码处理后,运动序列的关键帧被掩码。然后,时间自适应变换器(Temporal Adaptive Transformer,TAT)通过在条件信息的引导下恢复被掩码的帧来学习运动表示。如果条件信息仅由文本组成,那么它在时间维度上包含来自CLIP的单个标记,这使得在时间维度上使用自注意力机制更为合适。否则,运动序列作为,条件信息作为,执行交叉注意力机制以对齐运动与音乐或音乐和文本组合的时间信息。这使得时间自适应变换器能够更好地适应不同模态的输入条件,并且更加鲁棒。
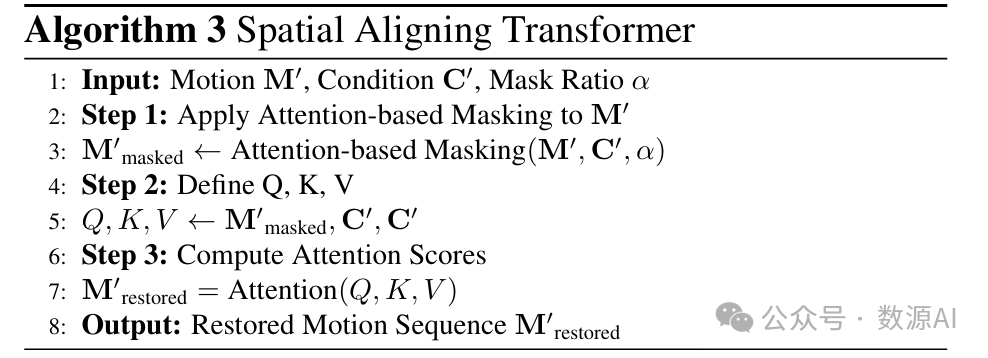
空间对齐变换器。在空间对齐变换器(SAT)中,条件嵌入和运动嵌入都被重新排列以展现空间维度。如算法3和图3(d)所示,在基于注意力的掩码操作中,每一帧中的关键动作(指空间维度中特定身体部位的关键运动)会被掩码。SAT在空间条件的引导下恢复这一特征。将每一帧中的空间姿态与空间条件对齐至关重要,尤其在文本到运动生成任务中,某些关键词会描述特定的身体部位。在音乐到舞蹈生成任务中,每个音频帧的频谱表示音乐类型 ,这对于生成合适类型的舞蹈至关重要。
实验与结果
1. 数据集和评估指标
TMD数据集。我们的文本 - 音乐 - 舞蹈(TMD)数据集引入了一个开创性的基准,包含2153对文本、音乐和动作数据。我们从Motion - X [38](包括AIST++ [34]和其他数据集)中提取舞蹈动作和相应的文本注释。对于没有音乐的动作 - 文本对,我们通过实现Stable Audio Open [14]并进行节拍调整来生成相应的音乐,并通过人类专家评估来评价生成的音乐,以确保评分者间信度。
公开基准。为确保公平比较,我们在标准基准上,将我们的方法与专门的和统一的动作生成方法进行了评估,这些基准包括用于文本到动作生成的HumanML3D [19]和KIT - ML [46],以及用于音乐到舞蹈生成的AIST++ [34]。
评估矩阵。我们采用标准评估指标来评估实验的各个方面。对于文本到动作生成任务,我们使用弗雷歇 inception 距离(FID)和 R 精度来量化生成动作的真实感和鲁棒性,使用多模态距离来衡量动作与文本的对齐程度,并使用多样性指标来计算动作特征的方差。此外,我们应用多模态性(MModality)指标来评估具有相同文本描述的动作之间的多样性。对于音乐到舞蹈生成任务,我们遵循 AIST++ [34] 从三个方面评估生成的舞蹈:质量、多样性和音乐与动作的对齐程度。对于质量评估,我们使用文献 [18] 中的工具箱计算生成舞蹈与动作序列特征(动力学特征 和几何特征 )之间的 FID。对于多样性评估,我们按照 AIST++ [34] 的方法计算平均特征距离。对于对齐程度评估,我们计算节拍对齐分数(BAS),即音乐节拍与其最近的舞蹈节拍之间的平均时间距离。
2. 模型与实现细节
我们的模型由2个TAT(Transformer Attention Transformer)和2个SAT(Self-Attention Transformer)层组成,拥有1265万个参数和137.35 GFLOPs(十亿次浮点运算)。对于所有模型,使用线性预热调度,学习率在2000次迭代后增加到。训练VQ - VAE(矢量量化变分自编码器)分词器时,小批量大小设置为512;训练掩码变换器时,小批量大小设置为64。所有实验均在主频为2.40GHz的英特尔至强铂金8360Y CPU上进行,该设备配备了单块英伟达A100 40GB GPU和32GB内存。
3. 对比研究
文本到动作转换。我们在HumanML3D [19]和KIT - ML [46]数据集上,将我们的方法与其他最先进的方法进行了比较。表2中的结果表明,我们的方法始终优于专门的文本到动作转换模型,并且超越了近期的多任务方法。
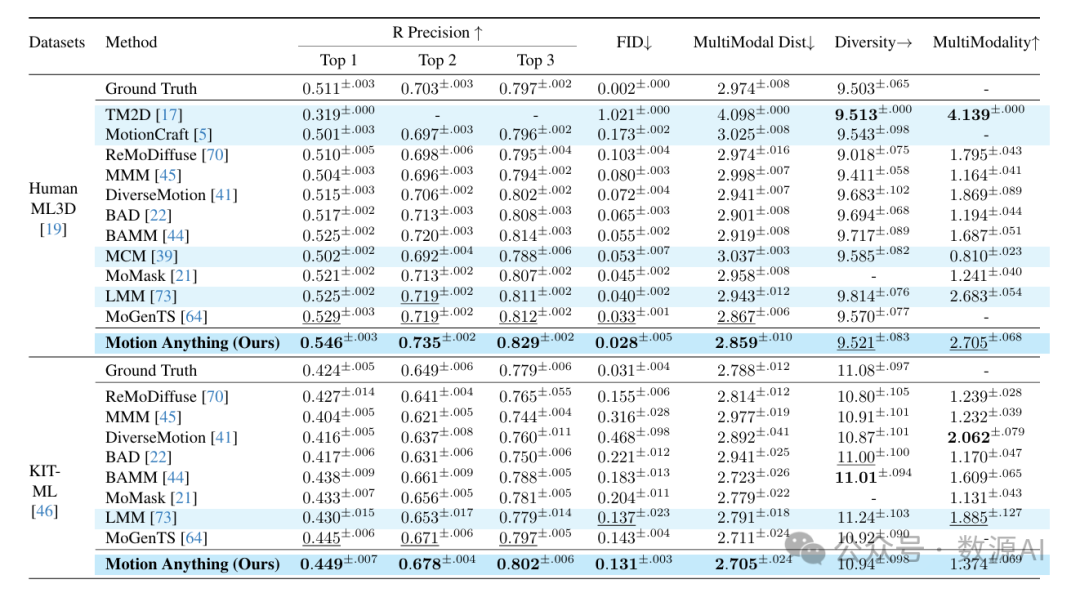
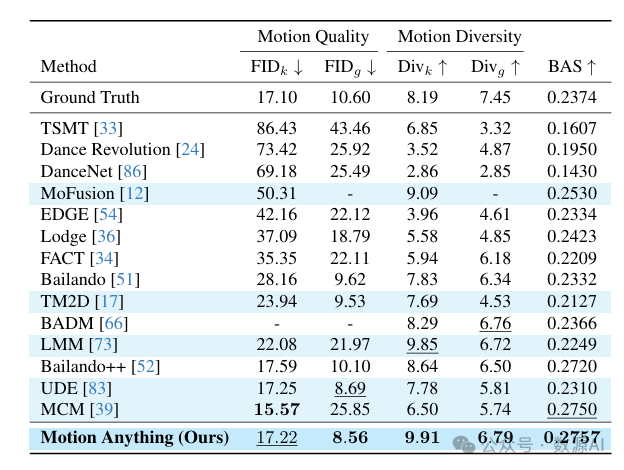
音乐到舞蹈。为了突出我们方法的音乐到舞蹈生成能力,我们在AIST++数据集 [34] 上进行了评估。表3中的结果表明,我们的方法超越了先前最先进的专门方法和统一方法,在音乐到舞蹈生成方面展现出卓越的动作质量、更高的多样性以及更好的节拍对齐
文本与音乐驱动的舞蹈生成。对于配对的文本与音乐驱动的舞蹈生成(TM2D)任务,我们通过直接组合开源多模态动作生成方法的条件嵌入来评估这些方法,并在TMD数据集上将它们与我们的方法进行比较。表
4. 消融实验
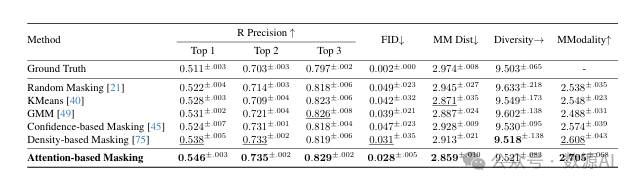
掩码策略。为了评估我们基于注意力的时空维度掩码方法的有效性,我们在HumanML3D数据集 [19] 上进行了全面实验,并将其与其他掩码策略进行了比较,如随机掩码 [21, 64]、K均值聚类(KMeans) [40]、高斯混合模型(GMM) [49]、基于置信度的掩码 [45] 和基于密度的掩码 [75]。表5中的结果表明,我们基于注意力的掩码方法在人体运动生成方面优于其他策略,为学习鲁棒的运动表示带来了有前景的结果。
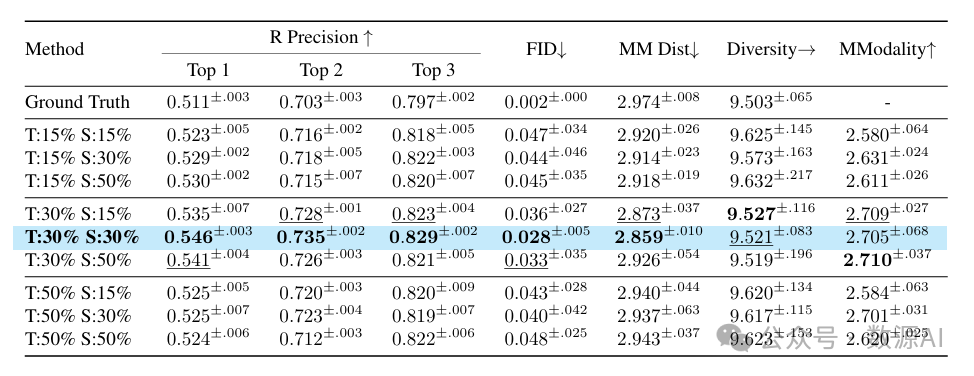
掩码比例。为了证明我们的方法在各种超参数下的鲁棒性,以及不同掩码比例对整体性能的影响,我们在人类动作三维数据集(HumanML3D)[19]上使用不同的基于注意力的掩码比例进行了全面的消融实验,如表6所示。我们分别对基于时间注意力和空间注意力的掩码比例进行了消融实验。结果表明,我们的方法在不同的掩码比例下相对鲁棒,被确定为本文中的最优设置。
用于文本到动作生成的跨模态时间自适应变换器(TAT)。为了验证时间自适应变换器(TAT)中的自注意力机制在文本到动作生成中的必要性,我们修改了TAT中的一个跨模态注意力层,使其类似于音乐到舞蹈以及文本与音乐到舞蹈生成的设置。表7中的结果表明,在人类动作三维数据集(HumanML3D)上进行文本到动作生成时,TAT中的跨模态注意力层的表现比自注意力层差。

这种性能不佳的情况可归因于以下事实:来自CLIP(对比语言-图像预训练模型)的文本嵌入在时间维度上仅由单个标记组成。因此,时间维度与运动嵌入不匹配,使其不适用于在时间上下文中与运动进行有效的跨模态融合。
多模态条件的有效性。为了评估多模态条件的有效性,我们研究了配对的文本描述是否能实现更可控的音乐到舞蹈生成,以及我们的任意到运动方法是否能无缝利用这两种条件。我们使用TMD数据集对多模态条件进行了消融实验,并将其与仅使用音乐的单条件设置进行了比较。表8中的结果表明,引入多模态条件比使用单一模态更有效,并且我们的模型能够有效且自适应地处理多模态条件。
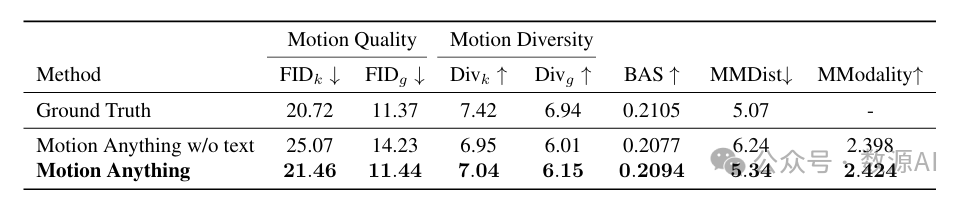
层数。为了研究在掩码变换器中改变层数 对我们模型的影响,我们在HumanML3D上进行了消融研究。表9展示了我们的模型在不同层配置下的鲁棒性。

5. 定性评估
文本到动作生成。为了定性评估我们在文本到动作生成方面的表现,我们将我们的方法生成的可视化结果与之前专门从事文本到动作生成的最先进方法(包括BAD [22]、BAMM [44]和MoMask [21])生成的结果进行了比较。文本提示是根据HumanML3D [19]测试集定制的。如图5和视频演示所示,与之前的最先进方法相比,我们的方法生成的动作质量更高、多样性更强,并且文本与动作之间的对齐效果更好。

图5. 文本到运动生成的定性评估。我们对我们的方法生成的可视化结果与BAD [22]、BAMM [44] 和MoMask [21] 生成的结果进行了定性比较。
音乐到舞蹈生成。为了评估我们的音乐到舞蹈生成的质量,我们将我们的方法生成的舞蹈与最先进方法(包括EDGE [54]、Lodge [36]和Bailando [51])生成的舞蹈进行了比较。在AIST++ [34]上进行训练,我们确保评估能够反映出多样化的音乐风格。如图6和随附视频所示,我们的方法生成的舞蹈视觉质量更好,并且与音乐的节拍和风格的对齐效果更优,超越了之前的最先进技术。

图6. 音乐到舞蹈生成的定性评估。我们对我们的方法生成的可视化结果与EDGE [54]、Lodge [36] 和Bailando [51] 生成的可视化结果进行了定性比较。
如需更多定性评估和视频,请参考补充材料。
结论
总之,“任意动作生成模型”(Motion Anything)通过实现自适应且可控的多模态条件设定,在动作生成领域取得了重大进展。我们的模型在自回归框架内引入了基于注意力机制的掩码,以聚焦关键帧和动作,解决了动态帧和身体部位优先级排序的难题。此外,该模型通过在时间和空间上对齐不同的输入模态,弥补了多模态动作生成方面的差距,增强了可控性和连贯性。为了进一步推动该领域的研究,我们推出了“文本 - 音乐 - 舞蹈”(Text - Music - Dance,TMD)数据集,这是一个具有开创性的包含配对音乐和文本的基准数据集。大量实验表明,我们的方法优于先前的方法,在多个基准测试中取得了显著改进。通过应对这些挑战,“任意动作生成模型”为动作生成建立了新的范式,为动作生成提供了一个更加通用和精确的框架。

















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









