






↑↑↑关注后"星标"Datawhale
每日干货 & 每月组队学习,不错过
Datawhale学术
作者:太子长琴,Datawhale意向成员
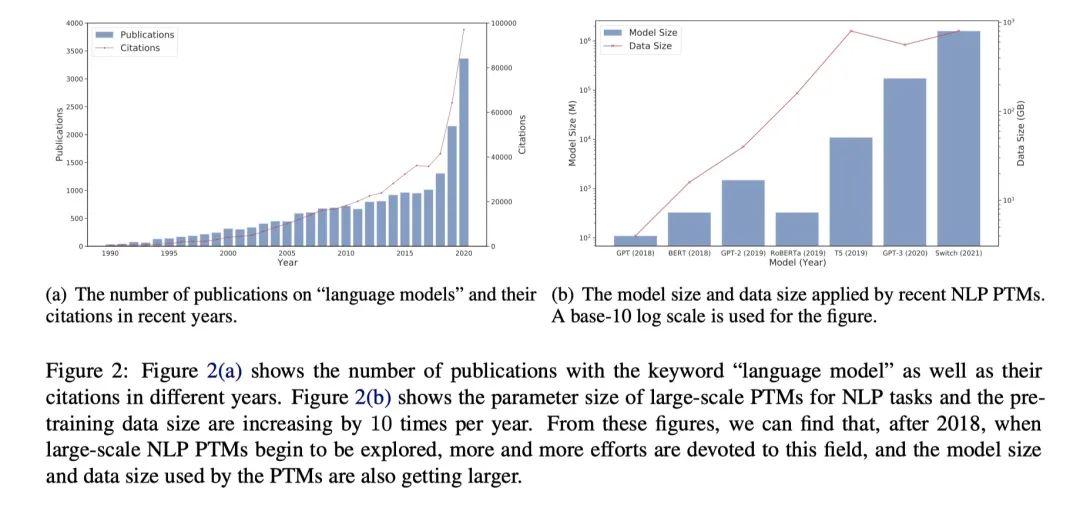
如何在有限数据下训练出高效的深度学习模型?本文深入研究了预训练的前世今生,并带领读者一起回顾PTM取得的最新突破,与未来的研究方向(文末附90分钟解读视频)。
利用深度学习自动学习特征已经逐步取代了人工构建特征和统计方法。但其中一个关键问题是需要大量的数据,否则会因为参数过多过拟合。但是这个成本非常高昂,因此长久以来,我们都在研究一个关键问题:如何在有限数据下训练高效的深度学习模型?
一个重要的里程碑是转移学习——受人类启发,不是从大量数据中从头开始学习,而是利用少量样例来解决问题。转移学习有两个阶段:预训练+微调,微调阶段就是转移预训练阶段学到的知识到特定任务上。这一方法首先在计算机视觉(CV)领域取得成功,这是对预训练模型(PTMs)的第一波探索浪潮。
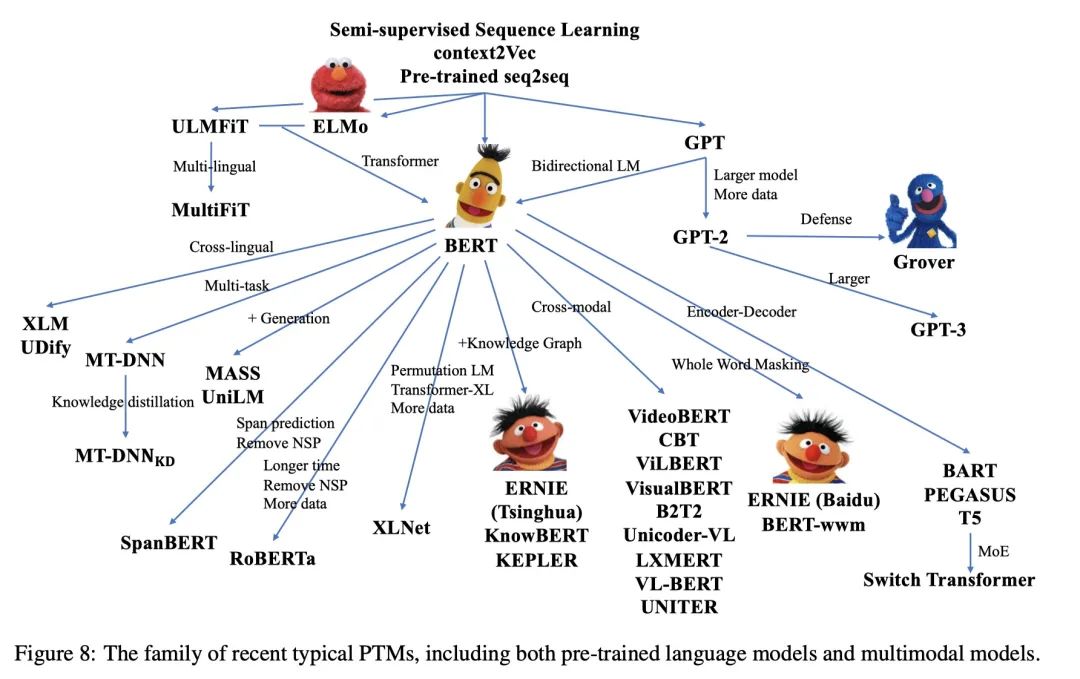
自然语言处理(NLP)领域采用了自监督学习进行预训练,其动机是利用文本内在关联作为监督信号取代人工标注。最初的探索聚焦在浅层预训练模型获取词的语义,比如 Word2Vec 和 Glove,但它们的局限是无法很好地表征一词多义。自然而然地,就想到了利用 RNN 来提供上下文表征,但彼时的模型表现仍受限于模型大小和深度。2018 年 GPT 和 BERT 横空出世,将 NLP 的 PTM 带入了新时代。
这些新模型都很大,大量的参数可以从文本中捕捉到一词多义、词法、句法结构、现实知识等信息,通过对模型微调,只要很少的样例就可以在下游任务上取得惊人的表现。到了现在,在大规模 PTMs 上对特定任务进行微调已经成为业界共识。尽管已经取得了很大的成功,但还有一些基本的问题:我们仍然不清楚隐藏在大量模型参数中的本质,训练这些庞然大物的巨大计算成本也阻碍了我们进一步探索。PTMs 已经将 AI 研究者推到了一个十字路口。
 论文标题:
论文标题:
Pre-Trained Models: Past, Present and Future
论文链接:
https://arxiv.org/abs/2106.07139
01 背景
1.1 转移学习和监督预训练
转移学习目标是从多种资源任务中捕捉重要的知识然后将其应用到特定任务。通常有两种预训练方法:特征迁移和参数迁移。前者在多个领域和任务上预训练特征表征来预编码知识;后者基于原始任务和目标任务可以共享模型参数的直觉假设,因此将知识预编码进共享的模型参数。从某种程度上说,这两种方法都为 PTMs 奠定了基础。比如词向量、ELMo 基于特征转移,BERT 基于参数转移。
从 AlexNet 到 VGG 再到 GoogleNet,网络变得越来越深,表现也越来越好。但是训练这样深度的模型并不容易,堆叠太多层会带来梯度消失和梯度爆炸的问题,而且很快就会到达天花板。于是,ResNet 出现了,它通过向参数初始化和隐藏层添加归一化并引入残差连接缓解了问题。再加上大规模数据集 ImageNet,在标注数据集上预训练模型出现一波浪潮。受此启发,NLP 领域也探索了监督预训练,最有代表的作品是 CoVE——采用机器翻译作为预训练目标,源语言的编码器可以作为下游任务的支柱。
1.2 自监督学习和自监督预训练
迁移学习有四种子集:
inductive transfer learning
transductive transfer learning
self-taught learning
unsupervised transfer learning
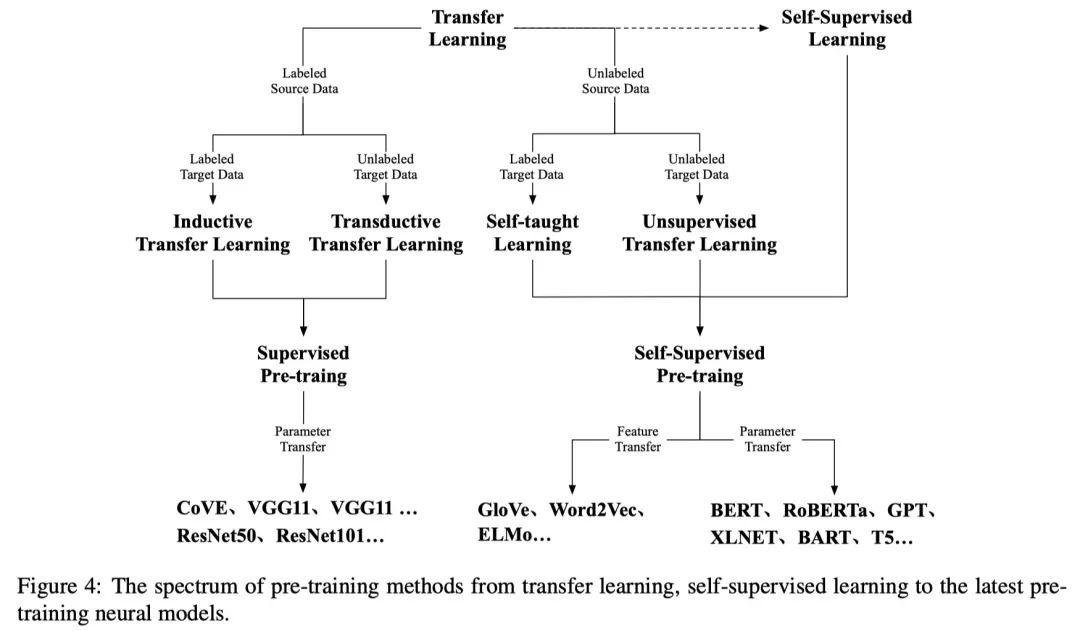
由于 NLP 领域有大量的无标注文本,研究中心逐渐从前两者转移到后两者。基于自监督的预训练通过将输入的数据本身作为标签进行学习,它可以看作是无监督学习的分支。不过无监督学习主要聚焦在发现数据的模式(聚类、社群发现、异常检测),而自监督学习依然是有监督的范式。虽然 CoVE 取得了不错的成绩,但要想在 NLP 领域标注一个像 ImageNet 的数据集几乎不太可能。这是因为标注文本数据比图像要复杂得多。所以使用无标签数据自监督学习就成了最好的选择。
早期的词向量就是这样做的,一段时间一直作为词的初始化参数,然后是序列级别的 ELMo 解决了一词多义问题,再就是 Transformer 时代的 GPT、BERT,以及后继者 XLNet、RoBERTa、BART、T5 等。使用基于 Transformer 的 PTMs 已经成为了业界基操,而且同时也被使用到 CV 领域。
1.3 Transformer 和预训练代表
主要是指 GPT 和 BERT,分别使用自回归语言模型和自编码语言模型作为预训练目标,分别对应 NLP 两大不同任务:生成和理解。
Transformer
Self-Attention
可以并行
Encoder 时上下文,Decoder 时按只上文
GPT
第一个结合 Transformer 架构(Decoder)和自监督预训练目标的模型
Model-Based(参数迁移),预训练模型作为任务网络的一部分参与任务学习(相比 ELMo),简化了下游任务架构设计
缺点:单向预训练,只有词向量无句向量
BERT
基于 Transformer Encoder 的交互式双向语言模型
Token(MLM)+ 句子级别任务(NSP)
Feature-Based + Model-Based,但后者效果好
缺点:难以学到词、短语、实体的完整语义
GPT 和 BERT 后
RoBERTa
去掉 NSP 任务
更多的训练步骤、更大的 batch size、更多的数据
更长的句子
动态 MASK
ALBERT
将输入的词向量分解成两个比较小的张量
层级参数共享
用 SOP 替换 NSP
改进模型架构和预训练任务:
XLNet
UniLM
MASS
SpanBERT
ELECTRA
更丰富的数据:多语种语料、知识图谱、图像
更大的模型:GPT 系列、Switch Transformer
计算效率优化
02 设计高效架构
两种动机:
统一序列建模
认知启发架构
2.1 统一序列建模
NLP 的下游任务一般可以归为三大类:
自然语言理解:语法分析、句法分析、词/句/段分类,QA,常识/事实推理
开放文本生成:对话生成、故事生成、data-to-text
非开放文本生成:机器翻译、摘要、完形填空
不过三者区别并不明显,生成和理解的界限也很模糊。因此,很多架构就朝着统一不同类型任务的方向探索。
结合自回归和自编码建模
PLM
先行者:XLNet,使用 PLM(permutated language modeling)
跟随者:MPNet,改进了 XLNet 在预训练时不知道句子长度但下游任务时知道的差异
Multi-Task Training
给定变长 mask span,不告诉模型 MASK token 的数量,让模型去生成 mask 掉的 token
第一个在所有类型任务上达到最优的模型
UniLM:联合训练不同的语言模型:非双向、双向、seq2seq
GLM:
使用通用的 Encoder-Decoder
GLM 之前,BERT 或 GPT 都不能解决变长完形填空问题。前者是因为 MASK token 的数量会泄露信息,后者是因为它们只能在序列后面生成。
MASS:将 masked-prediction 策略引入 encoder-decoder 架构,但并未解决变长完形填空问题
T5:通过使用一个 MASK token 去 mask 变长的 span,然后让 decoder 恢复整个被 masked 掉的序列
BART:对源序列进行多种操作,如截断、删除、替换、shuffle、mask 等,而不是只 mask
seq2seq 任务:PEGASUS、PALM
Encoder-Decoder 的挑战:
更多的参数
在 NLU 上表现并不好
2.2 认知启发架构
核心模块 Self-Attention 的灵感来自于人类认知系统的微观和原子操作,只负责感知功能。为了追求人类智能,理解认知功能的宏观架构包括决策、逻辑推理、反事实推理和工作记忆等至关重要。
可维护的工作记忆
人类没有表现出如此长的注意力机制,而是保持工作记忆,不仅记忆和组织,同时也会遗忘,类似 LSTM。
Transformer-XL 第一个引入片段级别重复和相对位置编码来实现这个目标,但这种重复只是隐式地模拟了工作记忆
CogQA提出在多跳阅读时维护一个认知图,由两个系统组成:系统 1 基于 PTMs,系统 2 基于 GNNs 为多跳理解建模认知图。具现是系统 1 依然基于固定大小窗口
CogLTX 使用了一个 MemRecall 语言模型来选择应该被维护在工作记忆中的句子,使用另一个模型来回答或分类
可持续的长期记忆
有研究已经发现 Transformer 能够记忆,他们通过使用一个大的 key-value 记忆网络替换 Transformer 层中的前馈网络,结果依然不错。因此前馈网络和记忆网络是等价的。但是 Transformer 的记忆能力是有限的,人类智能除了用来决策和推理的工作记忆,长期记忆在回想事实和经验方面同样扮演了关键角色。
REALM 先行探索如何为 Transformer 构建一个可持续的外部记忆,作者逐句张量整个维基百科,并检索相关句子作为掩码预训练的上下文。 针对给定数量的训练步骤异步更新张量化的维基百科。
RAG 扩展掩码预训练为自回归生成。
此外,还有张量已有知识库实体和三元组的(使用外部记忆网络的 embedding 替换内部 Transformer 层的实体 embedding)。
以及,从头开始维护一个虚拟知识,并在其上提出可区分的推理训练目标。
2.3 其他变体
主要集中在提升 NLU 的表现上。
提高 mask 策略(可以看作是一种数据增强)
SpanBERT:使用 span 边界目标(SBO)mask 连续随机长度的 span
ERNIE:mask 实体
NEZHA
WWM:Whole Word Masking
将遮掩预测的目标变难
ELECTRA 将 MLM 转换为替换 Token 检测 (RTD) 目标,其中生成器将替换原始序列中的 Token,而鉴别器将预测 Token 是否被替换。
03 使用多来源数据
3.1 多语言预训练
重要前提:虽然大家说不同的语言,但可以表达相同的意思。即语义与符号系统独立。用一个模型表征多种语言模型效果更好。
BERT 前主要有两种方式:
通过参数共享学习,比如使用多语言对训练多语言 LSTMs
另一种方法是学习与语言无关的约束,例如使用 WGAN 框架将语言表示解耦为语言特定和语言无关的表示
这两种方式都使模型能够应用于多语言场景,但仅限于特定任务(类似 ELMo)。
BERT 时代使用两阶段,多语言任务可以分为理解和生成任务,前者关注句子或词级别分类,后者关注句子生成。
理解任务首先被用在非平行多语言语料上训练多语言预训练模型
mBERT(MMLM 任务),结果显示能够很好地学到跨语言表征
XLM-R 使用更大语料 CC-100,结果比 MBERT 更好(数据更多结果更好)
平行语料
CLWR:跨语言词恢复 cross-lingual word recovery,通过利用注意力机制,使用目标语言的 embedding 表征源语言的 embedding,目标是恢复源语言的 embedding,让模型学习不同语言词级别的对齐
CLPC:跨语言释义分类 cross-lingual paraphrase classification,通过将对齐的句子对作为正例,采样的非对齐句子对作为负例执行句子级别分类,让模型预测输入的句子对是否对齐
XLM:使用双语对执行翻译语言建模任务(TLM),TLM 把两个语义匹配的句子合并成一个,然后随机同时 mask 两个部分,这鼓励模型将两种语言的表示对齐在一起。
TLM 以外的两种方法
ALM:从平行句子自动生成代码切换序列并对其执行 MLM,迫使模型仅基于其他语言的上下文进行预测
InfoXLM:从信息论视角分析 MMLM 和 TLM,鼓励模型在对比学习框架下区分对齐的句子对和未对齐的负例对
HICTL:扩展了使用对比学习来学习句子级和单词级跨语言表征的想法
ERNIE-M:提出了回译掩码语言模型(BTMLM),并通过回译机制扩展了平行语料的规模
生成模型
使用 MLM 和 TLM 训练 encoder
固定 encoder 使用 DAE 和 XAE 训练 decoder
DAE:denoising autoencoding 是典型的生成任务,将噪声加入到输入,然后用 decoder 恢复原始句子。一般包括两个操作:将 span 的 token 替换为 MASK 或重新排列 token 的顺序。
通过在 encoder 输入的结尾和 decoder 输入的开头之间添加特殊标记让模型知道被编码还是生成,扩展了 DAE 让其支持多语言。
MASS:随机 mask 一段 token,然后使用自回归方式预测
mBART:
XNLG:提出跨语言自编码任务(XAE),encoding 输入和 decoding 输出不再是同一种语言。分两个阶段:
3.2 多模态预训练
统称 V&L,视频和图像属于 Vision,文本和语音属于 Language。最大的难点是将非文本信息融合进 BERT。
ViLBERT:任务无关联合表征,两路输入,两个 encoder,然后使用 Transformer 层得到联合 attention 结果
首次提供学习视觉和语言关系的新方法
包括三个预训练任务:MLM,SIA(sentence-image alignment),MRC(masked region classification)
在五个下游任务进行评估:VQA(visual question answering),VCR(visual commonsense reasoning),基础引用表达式(grounding referring expressions),ITIR(image-text retrieval),ZSIR(zero-shot image-text retrieval)
LXMERT:与 ViLBERT 架构相似
但使用了更多预训练任务:MLM,SIA,MRC,MRFR(masked region feature regression),VQA
在三个下游任务测试:VQA,GQA(graph question answering),NLVR2(natural language for visual reasoning)
VisualBERT:最小地扩展了 BERT,简答高效的 BaseLine
Transformer 层暗示了输入文本和图像区域的对齐元素
两个预训练任务:MLM,IA
四个下游任务:VQA,VCR,NLVR2,ITIR
Unicoder-VL:
将 VisualBERT 中的 offsite visual detector 移动到端到端版本中,将 Transformer 的图像标记设计为边界框和对象标签特征的总和
三个预训练任务:MLM,SIA,MOC(masked object classification)
三个下游任务:IR,ZSIR,VCR
VL-BERT:
与 VisualBERT 相似
每个输入元素要么是输入句子的一个 token,要么是一个来自输入图像的感兴趣区域(RoI,region-of-interest)
预训练任务:MLM,MOC,发现 SIA 降低模型表现
下游任务:VQA,VCR,GRE
B2T2:
解决 VQA
设计了一个早期融合文本标记和视觉对象特征之间的共同参考的模型,然后使用 MLM 和 SIA 作为预训练任务
VLP:
解决 VQA
Encoder 和 Decoder 使用共享的多层 Transformer
在 BMLP(bidirectional masked language prediction)和 s2sMLP(seq2seq masked language prediction)上预训练
UNITER
学习多模态之间的统一表征
多预训练任务:MLM,SIA,MRC,MRFR
多下游任务:VQA,IR,VCR,NLVR2,REC(referring expression comprehension),VE(visual entailment)
ImageBERT
与 Unicoder-VL 一样
设计了一种新颖的弱监督方法来从网站收集大规模的图像-文本数据
预训练任务:MLM,SIA,MOC,MRFR
下游任务:ITIR
大规模、多任务训练机制:
将通用任务分为四组:VQA,基于字幕的图像检索,基准引用表达式,多模态验证
两个预训练任务:只遮盖对齐的图像-字母对,重叠的图像区域
下游任务:VQA,GQA,IR,RE,NLVR2
X-GPT
预训练文本-图像描述生成
三个生成任务:IMLM(image-conditioned MLM),IDA(image-conditioned denoising autoencoding),TIFG(text-conditioned image feature generation)
下游任务:IC(image captioning)
Oscar:
使用在图像中检测到的对象标签作为锚点来显著简化对齐学习
下游任务:ITIR,IC,NOC(novel object captioning),VQA,GCQ,NLVR2
DALLE
零样本生成重大进步
非常早的基于 Transformer 的图像-文本两样本预训练模型
展示了多模态预训练模型在弥合文本描述和图像生成之间差距的潜力
CogView
零样本生成重大进步
引入三明治变换器和稀疏注意力机制提高了数值精度和训练稳定性
第一个中文图像-文本模型
CLIP 和 WenLan
探索为 V&L 预训练扩大网络规模数据并取得巨大成功
大规模分布式预训练
3.3 知识增强预训练
将外部先验知识融入模型。
融合结构化知识,典型的结构化知识是知识图谱。
融合实体和关系 embedding
基于维基百科实体描述,将一个语言模型和知识 embedding 的损失合在一起得到知识增强表征
直接将实体和关系对齐到原始文本会在预处理阶段引入噪声,因此直接将结构化知识转为序列化文本让模型自动学到知识-文本对齐
融合多种开放学术图谱中的结构化知识:OAG-BERT
融合非结构化知识,特定领域或任务的数据
继续训练得到领域或任务模型
吸收领域或任务标注数据
可解释融合
在下游任务中基于检索方法使用结构化知识
使用适配器在不同的带标注的知识来源上训练,以便区分知识来自哪里
04 提高计算效率
4.1 系统级别优化
两方面:计算效率和内存使用,一般都是模型无关的。
单设备优化
混合精度。模型参数如果没初始化好可能导致训练不稳定
梯度检查点方法:处理冗余的激活状态
使用 CPU 内存存储模型参数和激活状态
ZeRO-Offload 设计了精细的策略来安排 CPU 内存和 GPU 内存之间的交换,以便内存交换和设备计算可以尽可能地重叠
多设备优化
数据并行
模型并行
MegatronLM:把 Self-Attention 和前馈层分别放到不同的 GPU 上训练
Mesh-Tensorflow:支持从任意维度切割 tensor
虽然模型并行性使不同的计算节点能够存储模型参数的不同部分,但它必须在前向传递和后向传递期间插入集体通信原语,这些原语不能被设备计算重叠。 相反,数据并行中的 allreduce 集体通信操作通常可以与反向计算重叠。所以数据并行一般是首选。
ZeRO 优化器:平均分配优化的状态到每个节点,每个节点只更新自己那部分,训练步把最后所有的状态聚集起来。避免了标准数据并行时节点间数据不断复制同步造成的内存损耗浪费。
另一个高效的模型并行方法:pipeline 并行:将深度神经网络划分为多个层,然后将不同的层放在不同的节点上。每个节点计算完后,输出发送到下个节点。每个 batch 结束后等待梯度反向传播结束。
GPipe:可以将小批量中较小部分的样本发送到不同的节点
TeraPipe:可以为基于 Transformer 的模型应用 Token 级的管道机制,使序列中的每个 Token 由不同的节点处理
4.2 高效的预训练
高效的训练方法
MLM 只能从输入的一个小子集上学习,ELECTRA 使用替换 Token 检测任务,因为所有 Token 都需要被区分,因此利用了更多的监督信息。相比 MLM 同等表现需要更少的训练步骤
MLM 的随机 mask 会让训练过程没有目标且低效。因此有些研究根据重要程度有选择地进行 mask
warmup 策略:刚开始线性增加学习率然后再 decay
不同的层能够共享相似的 Self-Attention 模式,所以浅层的可以先训练然后通过复制构建模型
有些层可以直接丢球
batch size 比较大时,不同层使用不同的学习率也能加速收敛
高效的模型架构
尝试降低 Transformer 的复杂度:
设计低秩内核以在理论上近似原始注意力权重达到线性复杂度
通过将每个 Token 的视图限制为固定大小并将 Token 分成几个块,将稀疏性引入注意机制,以便在每个单独的块而不是一个完整的序列中进行注意力权重的计算。使用可学习的参数将 Token 分配到块中会导致更好的性能
结合全局和局部注意力机制,然后使用全局节点按顺序收集 Token。 这样,长序列被压缩成少量的元素,可以降低复杂度
保持原始 Transformer 的复杂度,加速模型收敛:
使用 MoE:Mix-of-Experts 可以增加参数但计算开销几乎不变
代表是 Switch Transformers:每一层添加多个 expert,在每一步前向和后向传播时选择一个 expert 计算,这和没有 expert 相差不大。基于 MoE 的模型甚至更快收敛,因为模型更大。
这块内容可以参考 Google 的这篇论文:[2009.06732] Efficient Transformers: A Survey
4.3 模型压缩
参数共享
主要是 ALBERT
模型剪枝
Transformer 中的 attention heads 其实只要一小部分就能够获得足够好的表现
CompressingBERT:裁剪 attention 和线性层
知识蒸馏
训练一个小的学生模型去复现大的教师模型。
DistillBERT
TinyBERT
BERT-PKD
MiniLM
模型量化
将较高精度的浮点参数压缩为较低精度的浮点参数。
Q8BERT:8-bit
Q-BERT:混合精度,高 Hessian 范围需要高精度,相反则用低精度
Ternary-BERT:用知识蒸馏强迫低精度模型模仿高精度模型
不过,低位表示是一种与硬件高度相关的技术。
05 解释和理论分析
5.1 预训练模型的知识
语言学知识
为了研究 PTM 的语言学知识,设计了几种方法:
表征探索:固定 PTM 参数,在 PTM 的 hidden 表征上训练一个新的线性层
模型能够学到关于 token,chunk,关系对,句法,语义,局部、远程信息等
短语特征在底层,句法特征在中间,语义特征在上面
与非上下文表示(例如 word2vec)相比,PTM 在编码句子级属性方面更好
使用 PTM 嵌入的线性变换重建语言学家给出的句子树结构并取得有希望的结果
表征分析:使用 hidden 表征计算统计指标如距离或相似度
利用句法距离的概念从单词表征构造句子的成分句法树
句子中删除一个单词如何改变其他单词的表示,以揭示一个单词对其他单词的影响
注意力分析:计算注意力矩阵的统计指标,与表征分析类似
在较低层编码位置信息,在较高层捕获分层信息
微调对 Self-Attention 的模式几乎毫无影响
生成分析:使用语言模型直接评估不同序列或词的概率
Perturbed Masking 没有使用任何额外参数从 PTM 中恢复句法树
扩展训练语料库会导致收益递减,并且训练语料库需要大到不切实际,才能使 PTM 与人类表现相匹配
世界知识
常识
在共享类别或角色反转的情况下表现良好,但在具有挑战性的推理和基于角色的事件时失败
将关系三元组转换为掩码句子,然后根据 PTM 给出的互信息对句子排名。无需进一步训练的基于 PTM 的提取方法甚至比当前的监督方法具有更好的泛化能力
学习到了各种常识特征
不能很好地建模隐式关系
事实
关系知识生成表述为填空语句的完成,结果在没有任何微调的情况下,PTM 在此任务上明显优于以前的有监督基线
从 PTM 中提取事实:LPAQA 自动通过基于挖掘和基于释义的方法搜索更好的陈述 / 提示
AutoPrompt 建议为知识探索训练离散提示
P-tuning 发现更好的提示在于连续嵌入空间,而不是离散空间
微调有利于 PTM 知识生成
知识生成的成功可能依赖于学习神经刻板关联
ELMo 捕获数字效果最好
更多细节可参考:深度探索 Bert:BERTology Paper Note | Yam
地址:https://yam.gift/2021/05/22/Paper/2021-05-22-BERTology/
5.2 预训练模型的鲁棒性
最近的工作已经使用对抗样本确定了 PTM 中的严重鲁棒性问题。
PTMs 很容易被同义词替换欺骗
不相关的伪像(例如虚词)可能会误导 PTM 做出错误的预测
human-in-the-loop 方法已被应用于生成更自然、有效和多样化的对抗样本,这带来了更大的挑战并暴露了 PTM 的更多特性和问题
总之,当我们在现实世界部署 PTM 时,这已经成为一个严重的安全威胁。
5.3 预训练模型的结构稀疏性
Transformer 有过度参数化的问题,多头注意力在很多任务上是冗余的,去掉一部分头甚至效果更好。
相同层中的大多数 heads 有相似的 Self-Attention 模式
不同 heads 的 attention 行为可以归类为一组有限的模式
低级别的修剪 (30-40%) 根本不会影响预训练损失或下游任务的性能
可以找到性能与完整模型相当的子网络
但是参数的冗余可能有益于微调
5.4 预训练模型理论分析
两个假定解释预训练的影响:
更好的优化:与随机初始化相比,预训练网络接近全局最优
更好的正则化:PTMs 的训练误差不一定比随机模型好,而 PTMs 的测试误差更好,这意味着更好的泛化能力
实验结果倾向于第二个假设,PTM 没有实现更低的训练错误。另外,与其他正则化方法如 L1/L2相比,无监督预训练正则化要好得多。
关于对比无监督表征学习:
对比学习将出现在相同上下文中的文本 / 图像对视为语义相似对,将随机采样的对视为语义不同对。 那么,相似对之间的距离应该很近,不同对之间的距离应该很远。 在语言建模的预测过程中,上下文和目标词是相似对,其他词是负样本。
桑希等人(2019)首先提供了一个新的概念框架来弥合预训练和微调之间的差距。他们引入潜在类的概念,语义相似的来自同一个潜在类。
对比学习的损失是下游任务损失的上限
06 未来方向
6.1 架构和预训练方法
新的架构:
Transformer 的计算复杂度太高,序列太长无法计算
自动方法:NAS(neural architecture search)
将 PTMs 应用到特殊场景,比如低容量设备和低延迟应用程序,其中 PTM 的效率是一个关键因素
下游任务偏好不同的架构,需要根据下游任务的类型仔细设计特定任务架构
新的预训练任务
PTM 需要更深的架构,更多的语料和有挑战的与训练任务,这些都需要更高的训练成本
训练大模型本身也有挑战,需要高超的技巧,比如分布式、混合精度等
要基于现有硬件和软件设计更高效的预训练任务,ELECTRA 是个很好的尝试
超越微调
微调的不足:参数无效率——每个下游任务都有自己的微调参数。一个改善方法是固定原始参数,为特定任务添加小的微调适配模块
新的微调方法:prompt 微调是刺激分布在 PTM 中的语言和世界知识的一种很有前途的方法。具体来说,通过设计、生成和搜索离散(Petroni 等,2019;Gao 等,2021)或连续(Liu 等,2021b;Han 等,2021;Lester 等,2021)prompts 并使用 MLM 对于特定的下游任务,这些模型可以 (1) 弥合预训练和微调之间的差距,从而在下游任务上表现更好;(2) 减少微调大量参数的计算成本。
可靠性
对抗攻击
对抗防御
6.2 多语言和多模态预训练
多模态:挑战在于如何对这两种模式中涉及的时间上下文进行建模
更有洞察力的解释:至今依然不清楚为啥视觉和语言一起有效
更多下游应用:真实世界的应用场景
转移学习:要容易适配没见过的语言;应该能处理音频;如何使用多语言多模态直接转移源语言音频到目标语言文本或音频值得探索
6.3 计算效率
自动完成设备之间的数据移动
并行策略:
数据并行非常适合参数集相对小深度学习模型
模型和 pipeline 并行适用于参数量较多的模型
大规模训练
HugeCTR,MegatronLM,DeepSpeed,InsightFace 适用不同应用
需要一个统一的通用解决方案
包装器和插件
手动编程通信操作非常复杂
Mesh-Tensorflow,FlexFlow,OneFLow,MindSpore,GSard
6.4 理论基础
不确定性
过度自信的预测:不知道自己不知道什么
OOD(out-of-distribution)数据的挑战
使用贝叶斯深度学习
泛化和鲁棒性
经典的学习理论不足以理解深度网络行为,需要新的工具
PTM 除了理论问题外,还有其他问题比如:从理论上理解预训练在提高下游任务泛化方面的作用很重要
对抗鲁棒性问题:需要更复杂的样例
6.5 Modeledge 学习
我们很难知道 PTM 生成的表示意味着什么。 因此,我们可以将存储在 PTM 中的知识称为 “Modeledge”,区别于人类形式化的离散符号知识。
知识感知任务:PTM 可以被看作知识库或开放知识图谱
Modeledge 存储和管理
Chen et al. (2020a) 首先剔除 UCKB 的概念,他们将神经网络视为参数化函数,并使用知识蒸馏来导入和导出 Modeledge
UCKB 克服了模型存储的冗余性,将各种模型的模型边存储到一个共同的连续知识库中
在超大规模数据上训练一个超大的模型
基于 MoE 将多个模型聚集成为一个大模型
如何存储和管理各种连续的 modeledge 是个挑战
是否可以构建一个通用连续知识库 (UCKB) 来存储来自各种 PTM 的 Modeledge?
6.6 认知和知识学习
知识增强:输入相关的外部知识。考虑到知识和纯文本的格式非常不同,重要的是弥合文本表示和知识表示(包括符号或向量)之间的差距,并统一使用它们的信息作为输入。这个问题的解决方案需要统一的模型架构和知识引导的预训练目标
知识支持:有了关于输入的先验知识,我们可以训练不同的子模块来处理不同类型的输入,这可以加速训练和推理的过程并有利于模型效率
知识监督:知识库存储大量结构数据,可在预训练期间用作补充来源
认知架构:人类认知系统的宏观功能和组织如何为下一代智能系统的设计提供启示
明确可控的推理:需要机器将决策过程自动规划为认知图,并像人类一样对图中的因素进行明确推理,如 InversePrompting
知识互动:PTMs 从预训练中学到的知识在很大程度上是未开发的。此外,由于我们的大脑在不同功能区的协作下工作,因此重要的是要了解 PTM 是否塑造了不同的内部功能模块以及它们如何相互作用
6.7 应用
自然语言生成:机器翻译,摘要,对话生成,故事生成,诗歌生成
对话系统:Meena,Blender,CDial-GPT,Plato,Plato-2
特定领域预训练模型:BioBERT,SciBERT
领域和任务适应:
对大 PTM 简单微调对特定领域的应用来说不够充分,最主要的原因是分布偏移——特定领域和通用领域的数据分布可能本质上不同。
对超大 PTM,在特定任务的标注数据上简单微调看起来计算效率低下,性能上也没有效果。因此,如何弥合预训练和特定任务微调之间的差距变得至关重要。此外,高效且有效的特定任务微调也是 PTM 未来应用的重要研究方向。
这篇论文从开始读到最后整理成文断断续续加起来有两天时间,很长但很有收获。最大的收获有两个,一个是以后要多读论文,发现很多自己觉得比较新颖的想法都已经有人尝试过了;第二是要多读这样的 Survey,很系统完善。
论文链接:https://arxiv.org/abs/2106.07139
解读视频 :https://www.bilibili.com/video/bv1rq4y1s7xu (点击阅读原文观看)
:https://www.bilibili.com/video/bv1rq4y1s7xu (点击阅读原文观看)
本文来自由周郴莲负责的Datawhale论文分享项目「Whalepaper」,NLP、CV、Res…每周一起解读论文!
Whalepaper介绍及加入方式:https://datawhale.feishu.cn/docs/doccnAbq5hJPaVB645IztpFPdld

点击阅读原文看解读视频

















 4338
4338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









