







Datawhale干货
作者:知乎King James,伦敦国王大学
知乎 | https://www.zhihu.com/people/xu-xiu-jian-33
前言:上篇介绍了什么是强化学习,应大家需求,本篇实战讲解强化学习,所有的实战代码可以自行下载运行。
本篇使用强化学习领域经典的Project-Pacman项目进行实操,Python2.7环境,使用Q-Learning算法进行训练学习,将讲解强化学习实操过程中的各处细节。如何设置Reward函数,如何更新各(State,Action)下的Q-Value值等。有基础的读者可以直接看Part4实战部分。文章略长,细节讲解很多,适合新手入门强化学习。
01 强化学习
关于强化学习的基础介绍,可以阅读我上一篇帖子,本篇不再介绍。如果完全是零基础的读者,建议先阅读上一篇文章。里面介绍了强化学习的五大基本组成部分、训练过程、各大常见算法以及实际工业界应用等。
02 Pacman Project讲解
Pacman-吃豆人游戏,本身是上世纪80年代日本南梦宫游戏公司推出的一款街机游戏,在当时风靡大街小巷。后来加州大学伯克利分校,这所只有诺贝尔奖获得者才配在学校里面拥有固定车位的顶级公立大学,将Pacman游戏引进到强化学习的课程中,作为实操项目。慢慢地成为该领域的经典Project。
项目链接:http://ai.berkeley.edu/project_overview.html,这个项目因为时间比较久,所以整体是Python2.7的源码,没有最新的Python3源码。
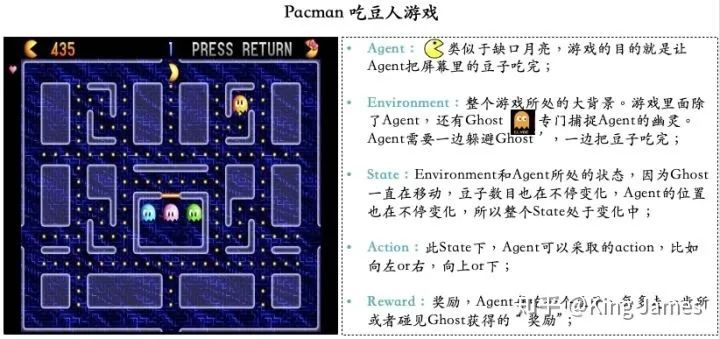
Pacman游戏目标很简单,就是Agent要把屏幕里面所有的豆子全部吃完,同时又不能被幽灵碰到,被幽灵碰到则游戏结束,幽灵也是在不停移动的。Agent每走一步、每吃一个豆子或者被幽灵碰到,屏幕左上方这分数都会发生变化,图例中当前分数是435分。
本次项目,我们基于Q-Learning算法,让Pacman先自行探索训练2000次。探索训练结束后,重新让Pacman运行10次,测试这10次中Pacman成功吃完所有屏幕中所有豆子的次数,10次中至少成功8次才算有效。
03 Q-Learning介绍
Q-Learning是Value-Based的强化学习算法,所以算法里面有一个非常重要的Value就是Q-Value,也是Q-Learning叫法的由来。这里重新把强化学习的五个基本部分介绍一下。
Agent(智能体): 强化学习训练的主体就是Agent:智能体。Pacman中就是这个张开大嘴的黄色扇形移动体。
Environment(环境): 整个游戏的大背景就是环境;Pacman中Agent、Ghost、豆子以及里面各个隔离板块组成了整个环境。
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









