







论文下载链接:https://arxiv.org/pdf/2310.14021.pdf
摘要
VectorSearch
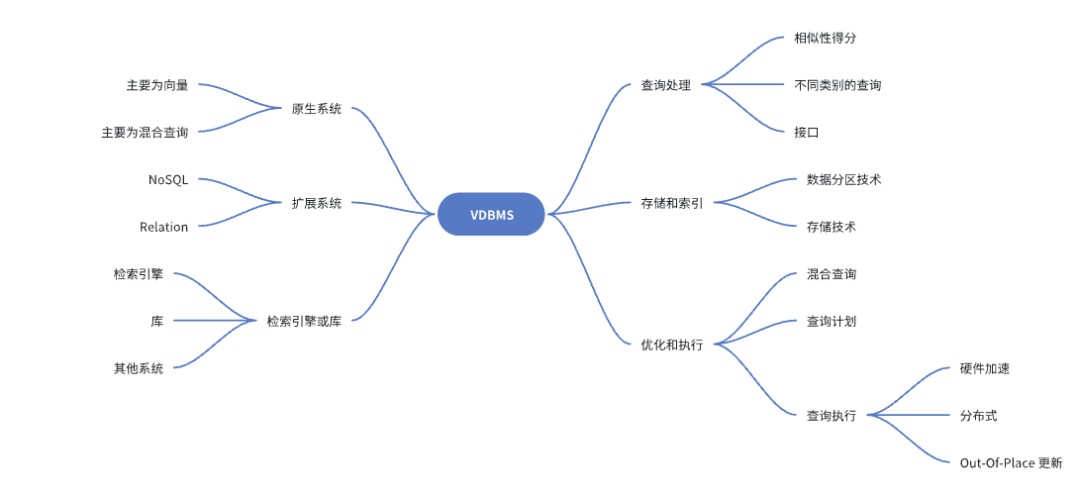
大模型的场景下,需要越来越多的非结构化数据。而如何提供更可靠、安全、快速的查询处理能力,是当下各种VDBMS(vector database management systems)主要做的工作。本篇综述提供了一个全面的调研来评估这些技术和系统。本文的主要结构由下图所示,同时文章提出了 VDBMS 搭建过程中最重要的五个问题分别是:
(1) 模糊的搜索标准。结构化查询使用精确的布尔谓词,但向量查询依赖于难以准确捕捉的模糊语义相似性概念。
(2) 更多代价的的计算。属性谓词(如 <、>、= 和 ∈)大多可在 O(1) 时间内计算,但相似性比较通常需要 O(D) 时间,其中 D 是向量维度。
(3) 内存消耗大。结构化查询通常只访问少量属性,因此可以设计高效的存储结构,如列存储。但向量搜索需要完整的特征向量。向量有时甚至跨越多个数据页,使得磁盘检索效率更低,同时也增加了内存压力。
(4) 缺乏结构。结构化属性主要是可排序或顺序排列的,可通过数字范围或类别进行分区,从而用于设计搜索索引。但矢量没有明显的排序顺序,也不是顺序性的,因此很难设计出既准确又高效的索引。
(5) 与属性不兼容。对多个属性索引的结构化查询可以使用简单的集合操作(如联合或相交)将中间结果收集到最终结果集中。但向量索引通常会在找到 k 个最相似的矢量后停止,并将这些向量与结果集结合起来。
查询处理
VectorSearch
相似性得分
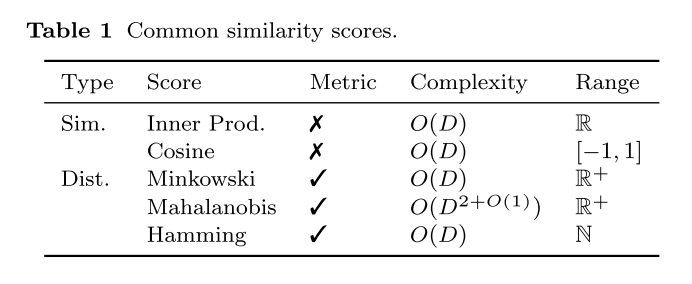
在向量检索领域,通常使用距离来度量相似度。距离函数则服从度量公理即恒等式(d(a,a)= 0)、非负性(如果a != b,则 d(a,b)> 0)、对称性(d(a,b)= d(b,a))和三角不等式(对于任意三个向量a,b,c,d(a,c)≤ d(a,b)+d(b,c))。通常 VDBMS 中支持以下距离度量方法。
有时,真实世界实体由向量集合中的多个向量表示。例如,对于面部识别,面部可以由从不同角度拍摄的多个图像表示,从而产生 m 个特征向量 x1。..xm。给定一个查询向量 q,找到与 q 最相似的向量集合称为多向量搜索。解决这个问题的一种方法是使用一个总分数,它定义了如何将各个分数组合起来以产生可以比较的单个值。具体方法包括聚合或取平均等。
总结:
到目前为止,还没有指导分数选择的原则,因此,分数选择往往更多地基于从经验中提炼出来的非正式规则,而不是严格的理论。许多 VDBMS 都将距离的选择权交给用户,如何支持自动分数选择仍然是一个待解决的问题。最近的一项工作,根据社交媒体内容推荐的查询动态调整分数。更严格来说,向量搜索不仅受到相似性分数的影响,而且还受到 embedding 的性质和查询的语义的影响。因此,本文设想未来的解决方案将更加全面,除分数选择之外的各个方面统筹起来考虑这个问题。例如,EuclidesDB 允许用户在多个嵌入模型和分数上进行相同的搜索,以选择最有语义意义的设置。
不同类别的查询
ANN
近似最近邻检索,找到一个大小为 k 的子集 S′ ∈ S,使得对所有 x′ ∈ S′,d(x′,q)≤ c(minx∈S d(x,q))。如果 k = 1,我们称这个查询为近似最近邻搜索。当 c = 1 时,我们称之为精确查询。c = 1,k = 1 的情况对应于最近邻搜索,并且当 c = 1,k > 1 时,查询被称为 k-最近邻(k-NN)查询。
范围查询
范围查询由半径 r 来决定召回,而不是要返回的邻居数。
谓词查询
在谓词搜索查询或混合查询中,每个向量都与一组属性值相关联,并且这些值上的布尔谓词必须为结果集中的每个记录求值为 true。下面是一个例子:

在这个例子中,d 是一个由查询 q 参数化的距离函数,结果集中的每个成员都必须满足在 k 个最近的成员中并且服从谓词 attr < c 的条件。
批查询
对于批处理查询,同时向系统提交多个查询,并且 VDBMS 可以以任何顺序回答它们。这些查询特别适合于硬件加速的查询。
多向量查询
一些 VDBMS 还通过聚合函数支持多向量搜索查询。有三种可能的子类型:在多查询单特征(MQSF)查询中,查询由多个向量表示,真实世界的实体由单个特征向量表示;在多查询多特征(MQMF)查询中,查询和实体都由多个向量表示;在单查询多特征(SQMF)查询中,只有实体由多个向量表示。
总结:
对一个 VDBMS 的搜索能力进行评估,通常需要评估查询精度和性能。为了评估准确性,经常使用精确度和召回率。精确度被定义为结果集中相关结果的数量与结果集大小之间的比率,召回率被定义为检索到的相关结果的数量与所有可能的相关结果之间的比率。为了评估性能,使用延迟和吞吐量。延迟是 VDBMS 在收到查询后应答查询所需的时间,而吞吐量是单位时间内应答的查询数量,通常用 QPS。
查询接口
原生的 VDBMS 和基于 NoSQL 的 VDBMS 倾向于依赖于 API。例如,Chroma 提供了一个只有九个命令的 Python API,包括添加,更新,删除和查询。另一方面,在关系型数据库基础上构建的扩展 VDBMS 倾向于利用 SQL 扩展。例如在 pgvector 中,k-NN 或 ANN查询表示为:

语法 R <->s 返回 R 和向量 s 的所有元组之间的欧式距离,并且通过其他符号支持其他距离函数。如果在 items 表上创建了 ANN 索引,则如果使用该索引执行,则此查询将返回近似结果。类似地,范围查询使用 where 表示:

存储和索引
VectorSearch
数据分区技术
随机:旨在利用多个独立事件的概率放大,使索引能够更好地区分真正相似的向量和不相似的向量。
学习分区:基于模型学习的能力旨在识别S的内部结构,以便它可以按照结构划分。这些技术可以是有监督的或无监督的。
可导航分区:可导航索引不是固定在绝对分区上,而是设计成可以轻松遍历S的不同区域。
注意如果对数据的更新改变了数据的分布,那么基于数据依赖策略的索引最终可能会随着时间的推移而变得不平衡。在许多情况下,这只能通过重建索引来解决。
存储和索引技术
量化:量化器将向量映射到更节省空间的表示上。量化通常是有损的,目的是最小化信息损失,同时最小化存储成本。
磁盘驻留:与只最小化比较次数的内存驻留索引相比,磁盘驻留索引还旨在最小化检索次数。
一个特定的索引可能使用多种技术的组合,因此下面会根据索引的结构对索引进行分类,然后指出哪些技术在哪些索引中使用。有三种基本结构:
表将 S 划分为包含相似向量的桶;
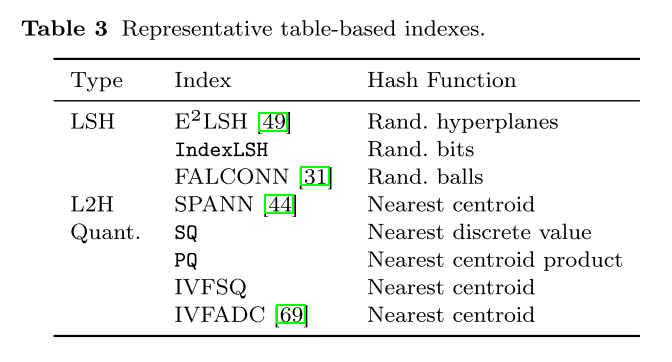
树是表的扩展;
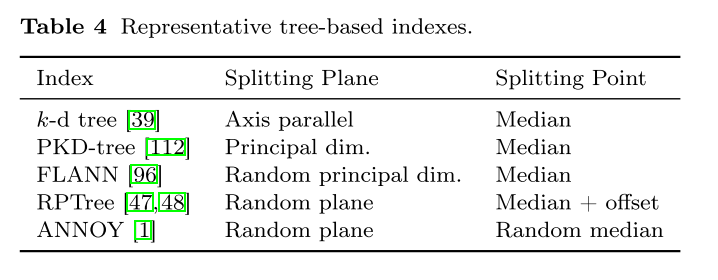
图用虚拟边连接相似向量,然后即可遍历;
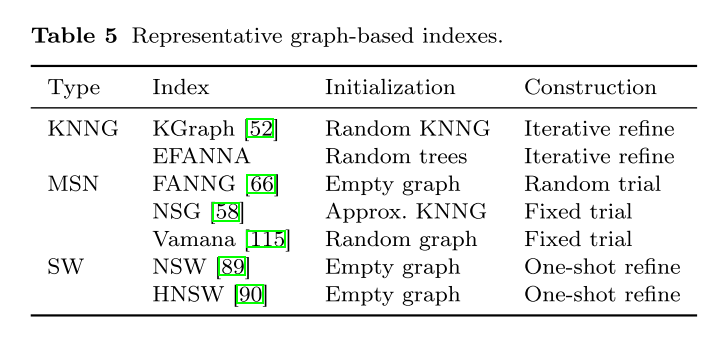
总结:
从下面的可以看出,HNSW 提供了许多更优的特性。它易于构造,可以更新,并支持快速查询。因此,它得到许多商业 VDBMS 的支持也就不足为奇了。存储成本可能仍然是非常大的一个问题,但有一些工作也在解决这个问题。当然在某些情况下,其他索引可能会更合适。对于批量查询或查询属于 S 的工作负载,KNNG 可能是首选,因为一旦它们被构造,它们可以在 O(1)时间内回答这些查询。KGraph 很容易构建,但 EFANA 更适合任何在线查询。对于在线工作负载,选择取决于几个因素。如果错误保证很重要,那么可以考虑基于 LSH 的索引或 RPTree。如果内存有限,则基于磁盘的索引(如 SPANN 或 MANN)可能是合适的。如果工作负载是 write-heavy 的,那么基于表的索引可能是首选,因为它们通常可以有效地更新。其中,E2LSH 是数据独立的,不需要重新平衡。对于 read-heavy 的工作负载,树或图索引可能是首选,因为它们通常提供对数搜索复杂度。
除了这些索引之外,一些工作还混合结构以实现更好的搜索性能。例如,NGT 索引使用树来初始划分向量,然后在每个叶节点上使用图索引。
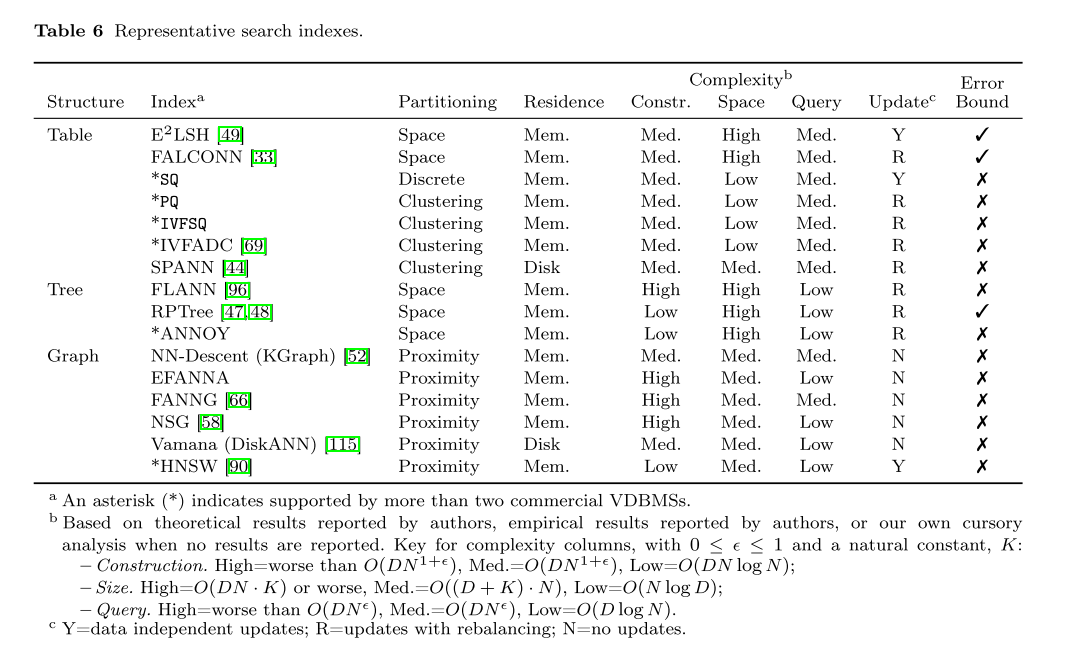
优化和执行
VectorSearch
可以有多种方式来执行给定查询。查询优化器的目标是选择最佳查询计划,通常是延迟最小化计划。要实现此目标,第一步是计划枚举,然后是计划选择,最后是查询执行。对于谓词查询,向量索引不能很方便的与同一计划中的属性过滤器组合,这就需要开发新的混合运算符。
混合运算符
谓词查询可以通过在向量搜索之前应用谓词过滤器来执行,称为“预过滤”;在搜索之后,称为“后过滤”;或者在搜索期间,称为“单级过滤”。
如果搜索是使用索引实现的,那么需要有一种机制来通知索引某些向量被过滤掉了。对于预过滤,块优先扫描的工作原理是在进行扫描之前“屏蔽”索引中的向量。扫描本身正常进行,但只在非阻塞向量上进行。对于单级过滤,访问优先扫描的工作原理是像正常情况一样扫描索引,但同时根据谓词条件检查每个访问过的向量
计划枚举
由于向量检索来说往往由少量运算符组成,因此在许多情况下,预定义查询计划不仅可行而且高效,因为它节省了在线枚举计划的开销。但对于旨在支持更复杂查询的系统,计划无法预先确定。对于基于关系型数据库的扩展型 VDBMS,可以使用关系代数来表示这些查询,从而允许自动枚举。
预定义
对于预定义计划,主要考虑的是为哪个查询指定哪个计划。有些系统以特定工作负载为目标,因此每个查询只关注一个计划。其他系统则包含多个计划。
单一计划:单一计划可以非常高效,因为它除了枚举之外还减少了计划选择的开销,但是如果预定义的计划不适合特定的工作负载,则可能是一个缺点。
多计划:对于非谓词查询,不同的索引会有多个计划。例如,AnalyticDBV 支持基于 PQ 或 VGPQ 的暴力扫描和基于表的索引扫描。这允许使用这两种方法中的任何一种来执行 k-NN 查询。
谓词查询可以通过预过滤、后过滤或单级过滤来查询。但是不同的向量搜索索引,再加上属性索引的存在与否,会使可能的计划的数量会成倍增加。
自动枚举
对于自动枚举,一些基于关系型数据库的 VDBMS 利用底层关系优化器来执行计划枚举和选择。例如,pgvector 和PASE 都利用了 PostgreSQL 对用户扩展的支持。
计划选择
Rule Based:如果计划的数量较少,则可以使用基于规则来决定执行哪个计划。下图显示了 Qdrant 和 Yahoo Vespa 使用的两个示例。
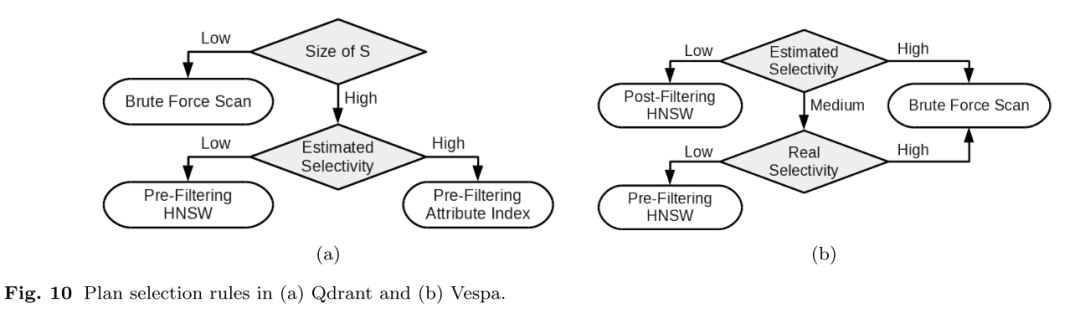
Cost Based:还可以使用成本预测来进行执行计划的选择,选择具有最小估计成本的计划。在 AnalyticDB-V 和 Milvus 中,cost 模型将各个运算符的预估成本相加,以产生每个计划的成本预测。运算符的预估成本取决于距离计算的数量以及运算符执行的内存和磁盘检索。对于谓词查询,这些数字是根据谓词的选择性估计的。但是它们也依赖于所需的查询准确性,这是作为一个可调整的参数向用户公开的。离线确定不同精度水平对运算符开销成本的影响。
查询执行
硬件计算
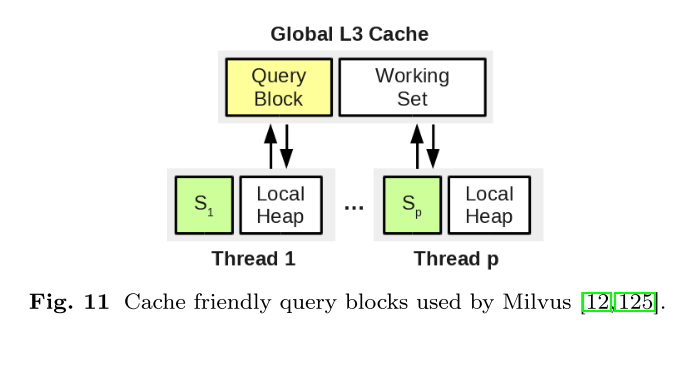
CPU Cache
如果数据不在处理器缓存中,则必须从内存中检索,从而导致处理器阻塞。如下图 所示,Milvus 通过将查询划分为查询块,将成批查询的缓存缺失降到最低。查询一次回答一个块,多个线程可同时用于处理查询。由于每个线程在执行搜索时都会引用整个数据块,因此根据常见的驱逐策略,数据块不会被驱逐。
Single Instruction Multiple Data (SIMD)
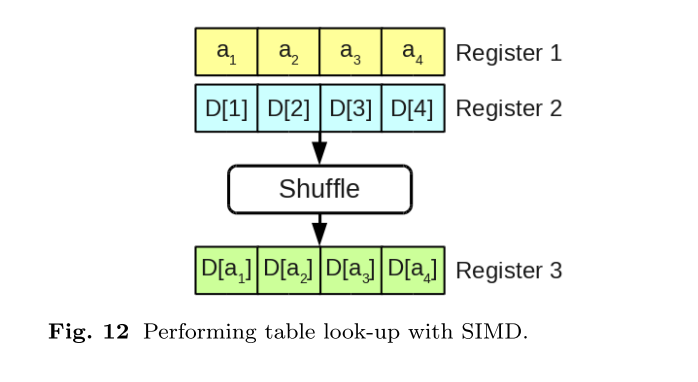
原始 ADC 算法执行一系列表查找和求和。虽然 SIMD 指令可以简单地并行化求和,但查找需要内存检索(在缓存未命中的情况下),并且更难以加速。但是在一些工作中,SIMD 指令被巧妙地利用来在单个 SIMD 处理器内并行化这些查找。这种技术在 Faiss 中实现。基本思想如下图所示。查找索引加上整个查找表存储在 SIMD 寄存器中。然后使用 shuffle 操作符重新排列表寄存器的值,以便第 i 个条目包含第 i 个索引处的值,将随后的加法的值排列起来。
Graphical Processing Units (GPUs)
GPU 由大量的处理单元以及内存组成。处理单元内的线程被分组在“线程束”中,并且每个线程束可以访问跨线程共享的多个32位寄存器。在一些工作中,给出了 GPU 的 ADC 搜索算法,也是 Faiss 的一部分。与 SIMD 算法类似,GPU 算法同样尝试避免内存检索,这次是从 GPU 设备内存中检索。它还通过在寄存器内执行表查找来实现这一点,利用称为“warp shuffle”的 shuffle 操作符。
分布式
分布式搜索许多 VDBMS 利用分布式集群来扩展到更大的数据集或更大的工作负载。一些云服务利用了分散的架构,以提供高弹性。
为了执行分布式搜索,首先将向量集合划分为多个分片。集合可以被划分为相等的分片,其中分片中的向量是相同分布的,或者基于其他特征来划分,例如基于使用基于表的索引分桶的集合的索引键。然后可以为每个分片构建本地索引,并且分片及其本地索引也可以被复制以提供容错并增加吞吐量,因为可以在副本上同时执行多个查询。
分布式向量搜索遵循分散-聚集模式。首先将查询分散到所有相关的分片,然后通过聚合每个分片的结果来获得结果集。例如,对于 k-NN 查询,每个分片产生一个结果集,其中包含查询的 k 个最近邻居,然后通过合并这些结果以产生最终结果集。
Out-Of-Place Updates
索引的更新问题也是大家比较在意的。如果采用立刻更新索引的策略会中断搜索查询。如果更新需要很长时间这些中断的后果可能会很严重。
副本
复一些 VDBMS 通过将向量集合划分为分片和副本来缓解这个问题,然后在每个副本上构建本地索引。通过这种方式,如果一个副本上的索引正在进行更新或重建,则查询可以由其他副本处理,而不会造成任何中断。但是,存储(内存)需求乘以副本的数量,并且由于分散-聚集,搜索查询可能会有额外的开销。
Log-Structured Merge (LSM) Tree
另一种方法是将更新流到一个单独的结构中,然后在更方便的时候根据索引进行协调。LSM 树解决了读友好的索引不能支持快速写入的问题,而写友好的更新结构不能支持快速读取。在 Milvus 和 Manu 中,在 LSM 树的每个片段上构建向量搜索索引,以支持快速读取。每当段变满或合并时,都会创建一个新索引。
其他技术
在 Vald 中,更新被流式传输到一个简单的队列中,然后在队列满了或基于其他条件时批量加入到本地索引。类似地,在 AnalyticDB-V 中,更新保存在内存中,并定期与磁盘上保存的旧记录合并
系统
VectorSearch
原生系统
原生系统的特点是通过查询API、由少量组件组成的简单处理流程和基本存储模型。
Mostly Vector
EuclidesDB
Vald
Vearch
Mostly Mixed
Milvus & Manu
Qdrant
NucliaDB and Marqo
Weaviate
扩展系统
在传统的数据库上扩展向量检索。
NoSQL
Vespa
Cassandra
Databricks
Relational
SingleStore
PASE
Pgvector
AnalyticDB-V
ClickHouse and MyScale
检索引擎或库
检索引擎
搜索引擎。Apache Lucene 是一个可插入的搜索引擎,为嵌入式应用程序提供了复杂的搜索功能。最新版本提供矢量搜索,由 HNSW 支持。虽然 Lucene 本身缺乏更高级别的功能,如多租户,分布式搜索和管理功能,但其中许多都是由构建在 Lucene 之上的搜索平台提供的,包括 Elasticsearch,OpenSearch 和 Solr 。这些功能可以使 Lucene 成为大多数矢量原生 VDBMS 的有吸引力的替代品,因为它提供了类似的功能,并且可以很容易地与现有基础设施集成。
库
有一些库直接实现了特定的索引。例如,KGraph 是 NN-Descent KNNG 的实现。微软的空间划分树和图(SPTAG)库将包括 SPANN 和 NGT 在内的多种技术结合到一个可配置的索引中。LSH 的库也可用,包括 E2 LSH 和 E2 LSH。同样,Meta Faiss 提供了一系列索引,包括 HNSW、汉明距离的 LSH 家族和基于量化的索引。
其它系统
Applureform 是一个针对数据集管理的中间件。与关系 ETL 工具类似,它提供了一种组织工作流的方法,将原始数据源转换为由下游应用程序使用的数据集。Applureform 通过其 API 公开了其中一些下游函数。例如,它提供了一个向量搜索端点,该端点通过已配置的提供程序(如 Pinecone)执行 k-NN 查询。另一方面,Activeloop、Deep Lake 直接在向量仓库上提供向量操作,使其能够在仓库内执行向量搜索。
总结:
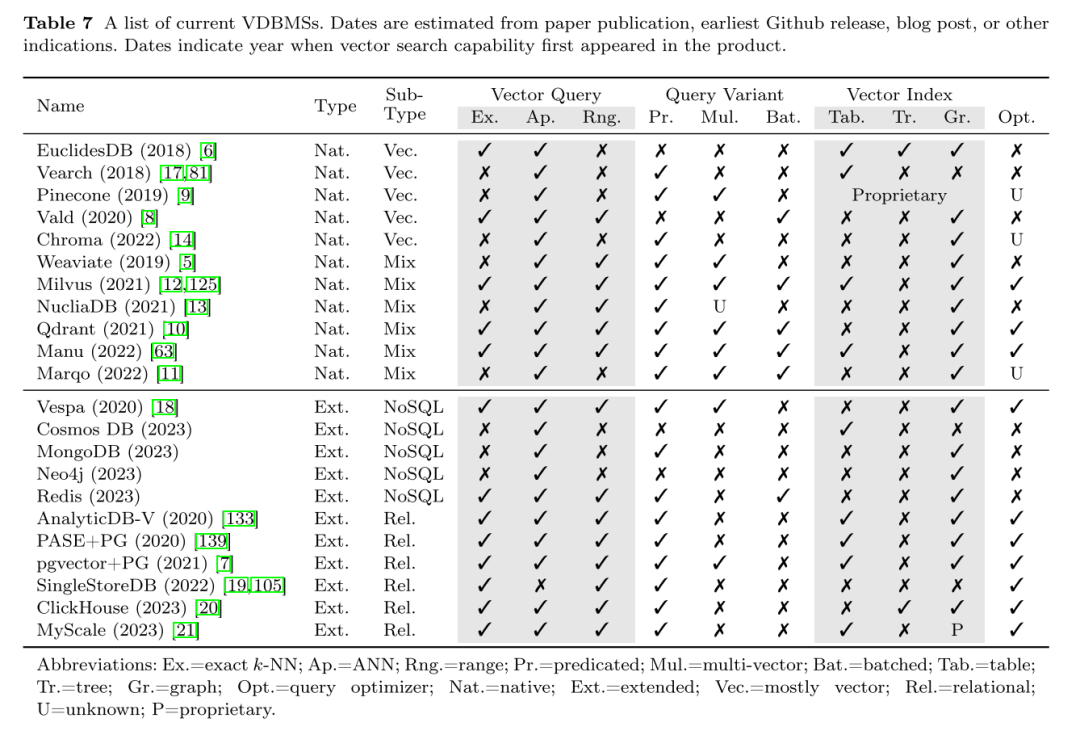
这些数据库的设计涵盖了涉及查询处理和向量存储的一系列特性,表现为一系列性能和功能,如下所示。本文提出几点笼统的意见。原生的大多数向量系统广泛地提供高性能,但针对特定的工作负载,有时甚至是特定的查询,具有相对有限的能力。同时,原生的大多数混合系统提供了更多的功能,特别是谓词查询,一些如 Milvus、Qdrant 和 Manu 也执行查询优化。扩展的 NoSQL 系统,在高性能和搜索能力之间实现了比较好的平衡。另一方面,扩展关系型数据库提供了最多的功能,但性能可能较差。但是,正如在其他地方提到的那样,关系型数据库已经是工业数据基础设施的主要组成部分,能够在不向基础设施引入新系统的情况下进行向量搜索是一个引人注目的优势。
Benchmarks
VectorSearch
在论文 Approximate nearest neighbor search on high dimensional data — Experiments, analyses, and improvement 中,大量的 ANN 算法在一系列实验条件下统一实施和评估。这些算法包括 LSH、L2H、基于量化的方法、基于树的技术和基于图的技术。实验在18个数据集上进行,从几千个向量到1000万个向量,维度从100到4096。这些特征向量来源于真实世界的图像、文本、视频和音频集合,以及合成生成的。算法是根据查询延迟以及基于精度、召回率和其他两个衍生指标的结果集质量来衡量的。在论文 ANN-Benchmarks: A benchmarking tool for approximate nearest neighbor algorithms 中,评估扩展到包括完整的 VDBMS。
挑战和解决的问题
VectorSearch
相似性评分的选择问题
不同相似度分数的语义质量仍然难以理解,并且对于如何为哪些场景选择哪个分数没有严格的指导。像EuclidesDB这样的系统可以用于实验性地确定最佳得分和嵌入模型。
运算符的设计
设计高效和有效的混合运算符仍然具有挑战性。对于图索引,块优先扫描可能会导致图断开连接,这些组件要么需要修复,要么需要新的搜索算法来处理这种情况。现有的离线阻塞技术仅限于少量属性类别。对于访问优先扫描,由于不可预测的回溯,估计扫描的成本是具有挑战性的,使计划选择复杂化。
增量搜索
一些应用程序,如电子商务和推荐平台,使用增量k-NN搜索,其中k实际上非常大,但以小增量检索,以便结果看起来无缝地交付给用户。虽然存在这种类型的搜索技术,但目前还不清楚如何在向量索引中支持这种搜索。
多向量检索
多向量搜索对于某些应用(如人脸识别)也很重要。现有技术倾向于使用聚合分数,但这可能是低效的,因为它会增加距离计算的数量。通用的多属性topk技术也很难适应向量索引,并且没有关于MQMF查询的工作。
安全和隐私
随着向量搜索变得越来越关键,数据安全和用户隐私变得越来越重要,特别是对于提供托管云服务的VDBMS。因此,需要能够支持私有和安全的高维向量搜索的新技术。
总结
VectorSearch
在本文中,总结了向量数据库管理系统,旨在快速,准确的进行向量搜索,开发更实用的应用程序,如 LLM 应用。我们回顾了查询处理过程中的所有注意事项,包括相似性分数,查询类型和基本运算符。还回顾了关于向量搜索索引的设计、搜索和维护注意事项。我们描述了查询优化和执行的几种技术,包括计划枚举、计划选择、谓词或“混合”查询的运算符以及硬件加速。最后,本文讨论了几个商业系统和用于比较的主要基线。


















 1485
1485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









