






Pytorch知识
笔记整理自@我是土堆的视频(2022/08/04~2022/08/09)
PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili
Pytorch Basic
| 函数 | 作用 |
|---|---|
| dir(package) | 找到该package中所有的方法 |
| help(函数名) | 查找该函数的声明 |
tensor
Pytorch中最基本的数据类型,一个可以运行在gpu上的多维数据
# 创建方式
torch.tensor(data, dtype=None, device=None,requires_grad=False)
data - 可以是list, tuple, numpy array, scalar或其他类型
dtype - 可以返回想要的tensor类型
device - 可以指定返回的设备
requires_grad - 可以指定是否进行记录图的操作,默认为False
tensorboard
提供机器学习工作流程期间所需的测量和可视化的工具
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
# writer.add_image() # 添加图片
# writer.add_scalar() # 添加标量
# 在terminal中
..............>tensorboard --logdir "dir"
# 即可得到该图像绘制好的网址
一般地址采用相对地址(是用”\”分隔的)
如果采用绝对地址,则需要将”/“变成”//“,或在地址字符串之前加上”r“
在函数的括号内
Ctrl+P就可以知道里面要加什么变量了
-
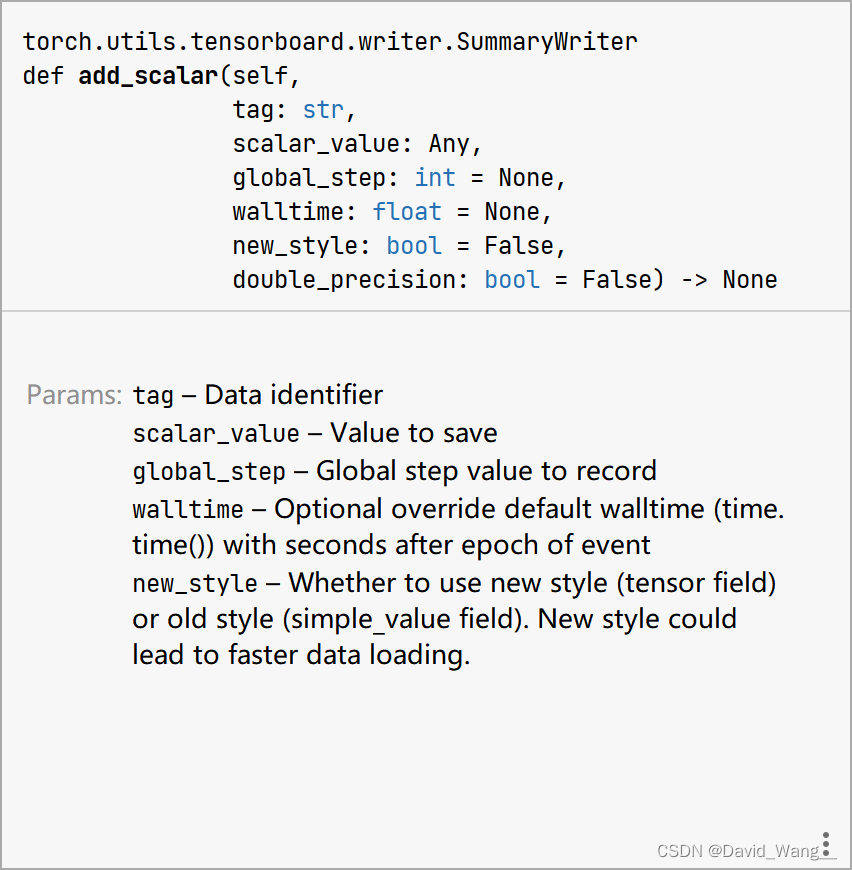
add_scaler中的参数
# tag (string): Data identifier数据标识符 简单来说就是咱给其结果图取一个名字 # scalar_value (float or string/blobname): Value to save 传入的数值(也就是结果图的y轴值) # global_step (int): Global step value to record 也就是结果图的x轴记录训练的步数 -
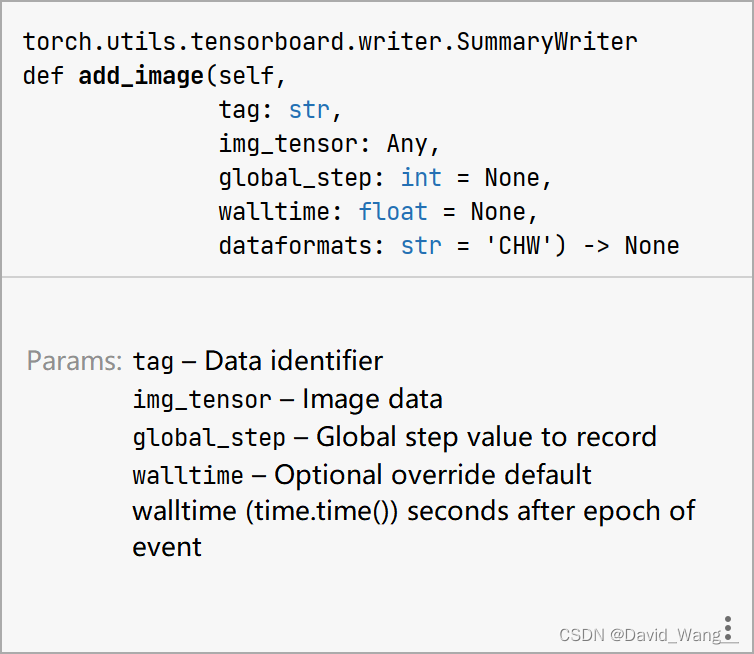
add_image中的参数
writer.add_image("test",image_array,1,dataformats='HWC') # tag (string): Data identifier 起个名字 # img_tensor (torch.Tensor, numpy.array, or string/blobname): Image data # global_step (int): Global step value to record # dataformats 表示颜色管道的方式
transforms
from torchvision import transforms # 头文件
# 1.使用方法
img_path = "address"
img = Image.open(img_path)
tensor_trans = transforms.ToTensor() # __call__方法,可以先将方法命名,再使用
tensor_img = tensor_trans(img)
可以用此方式安装第三方库(很快!)
| 方法 | 作用 |
|---|---|
| ToTensor | 将非tensor类型(PIL Image或numpy.array)的文件转化成tensor类型,便于之后机器学习的数据处理 |
| 其中的numpy.array一般是用cv2.imread(path)读进来的图像 | |
| Normalize | 标准化。通过设置RGB的标准差(standard deviation)与均值(mean)来改变图像的颜色 |
| output[channel] = (input[channel] - mean[channel]) / std[channel] | |
| Resize | 对图像进行缩放,不改变数据类型 |
| Compose | 将步骤结合。其参数是一个列表[transforms参数1,transforms参数2,transforms参数3,…] |
| 其中的参数均为已经声明过的方法,注意后一个的参数与前一个的输出相互匹配 | |
| RandomCrop | 随机裁剪。 trans_random = transforms.RandomCrop((500,1000)) |
DataLoader
把dataset中的数据打包加载到神经网络中
from torch.utils.data import DataLoader
# batch_size 表示一次取出图片的多少 how many samples per batch to load (default: 1).
# shuffle 表示是否打乱 set to True to have the data reshuffled at every epoch (default: False).
# drop_last 最后不足batch_size是否保留
test_loader = DataLoader(dataset=test_data,
batch_size=64,
shuffle=True,
num_workers=0,
drop_last=True)
# test_loader中第一个为img(打包好后的),第二个为target
神经网络(Pytorch进阶)
基本骨架—torch.nn.Module
Base class for all neural network modules.
import torch.nn as nn
import torch.nn.functional as F
# 一般在一开始先读取数据到dataset中,之后用dataloader将其打包
dataset = torchvision.datasets.CIFAR10("../data", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = torch.utils.data.DataLoader(dataset, batch_size=64)
class Model(nn.Module): # 继承了nn.Module模板
def __init__(self):
super().__init__() # 需要父类先进行初始化
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x): # 卷积->非线性->卷积->非线性
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
- input→
forward→output
卷积层—Convolution Layer
最常用二维卷积处理图像—Conv2d
# 卷积运算
import torch
import torch.nn.functional as F
F.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) → Tensor
# 卷积类
from torch import nn
from torch.nn import Conv2d
Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1,
groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
input 中注意它后面应该接着四个参数
in_channels (int) – Number of channels in the input imagestride 表示每一次进行卷积的步长,先横向走完后再纵向
padding 将tensor填充至所需要的大小(上下左右都延伸padding格)默认用0填充
out_channels 表示输出图片的通道数,会生成out_channels个卷积核
kenel_size 从分布中采样得到,会在训练当中不断更新
diation 称为空洞卷积,默认是1,每一次卷积之间会有间隔(将5X5中选3X3)
计算公式(用此公式计算padding,其他参数取默认值)
可以使用torch.reshape()将input转换为要求的格式
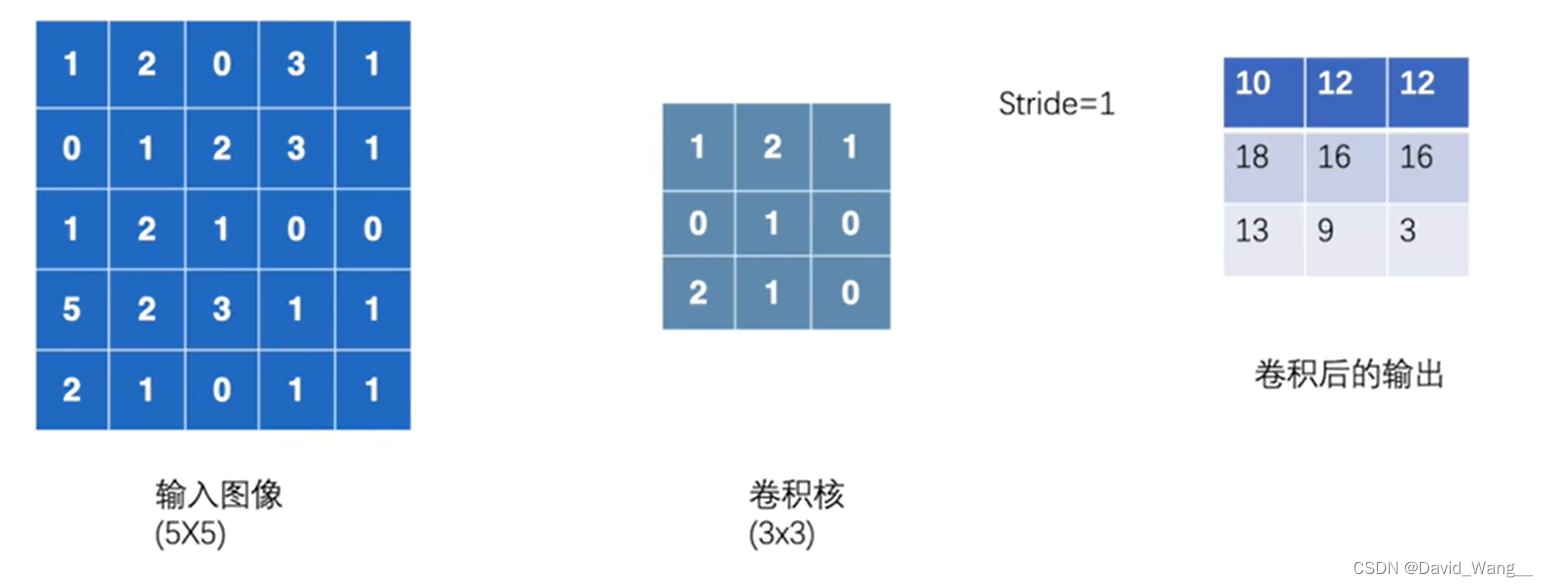
# kernel表示卷积核
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
kernel = torch.reshape(kernel, (1, 1, 3, 3))
卷积运算方式
用卷积核去选中对应的格子,进行对应格子之间乘法,之后再加和
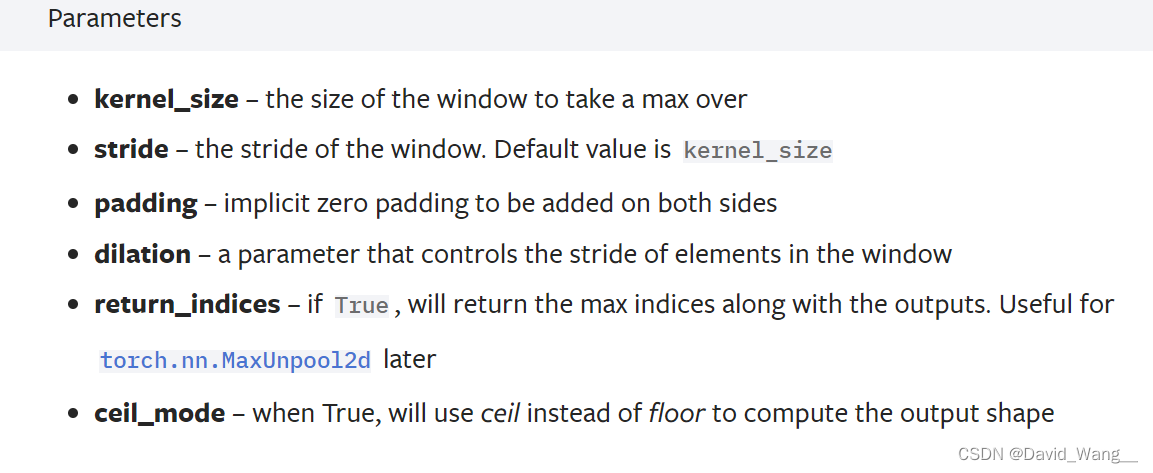
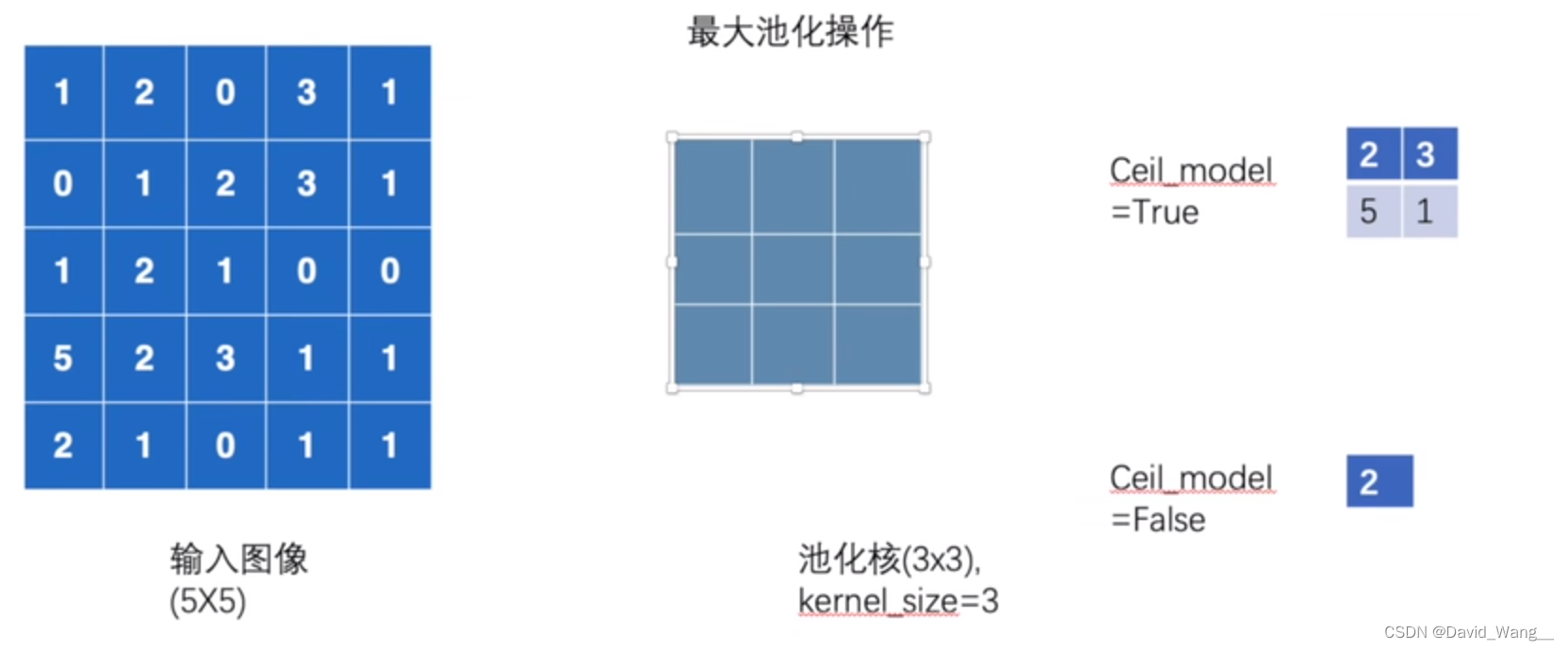
池化层—Pool Layer
最常用最大池化—MaxPool2d
可以保留数据特征,但将其大小缩小
stride 注意与卷积做区分,这里的默认返回值是kernel_size(3x3记为3),而卷积默认是1
ceil_mode 表示是否上取整,ceil为上取整,floor为下取整。取整是对格子而言的,即作下一次
运算时,若格数不够,是否要考虑扩充的情况(即是否考虑比kernel_size小的区域的最大值)。默认值为false
最大池化计算方式
用池化核去选中对应的格子,去其中的最大值
非线性激活—Non-linear Activations
引入非线性特征,便于模型的适应性
最常用的处理方式—ReLU & Sigmoid
inplace 表示是否对于输入值input进行修改,若为False则可以返回值output,且不对input修改
正则化层—Normalization Layer
常用正则化方式—BatchNorm2d
可以加快神经网络的训练速度
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True, device=None, dtype=None)
线性层—Linear Layers
常用线性层—Linear
Linear变换是对一维向量的变换,in_features&out_features都是个数
所以在使用线性变换之前都是采用Flatten()将矩阵展开为一维向量
**torch.nn.Linear(*in_features*, *out_features*, *bias=True*, *device=None*, *dtype=None*)**
>>> m = nn.Linear(20, 30)
>>> input = torch.randn(128, 20)
>>> output = m(input)
>>> print(output.size())
torch.Size([128, 30])
循环层—Recurrent Layer
特定的网络结构,可以用于文字识别等
转换层—Transformer Layer
使用不多
随机失活层—Dropout Layer
防止过拟合
针对训练集与测试集的拟合效果都很棒,但投入实际却发现模型效果一般的现象
Sparse Layer
特定的网络结构,用于自然语言处理
序列—Sequential
将module按顺序进行,读起来更加简洁易懂
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
损失函数—Loss Function
①可以计算实际输出与目标的差距
②可以为我们更新输出提供依据(反向传播)
L1Loss 直接做差之后求和再取平均
# torch.nn.L1Loss(*size_average=None*, *reduce=None*, *reduction='mean'*)
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss(reduction='sum')
result = loss(inputs, targets)
MSELoss 计算方差
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
loss_mse = nn.MSELoss()
result_mse = loss_mse(inputs, targets)
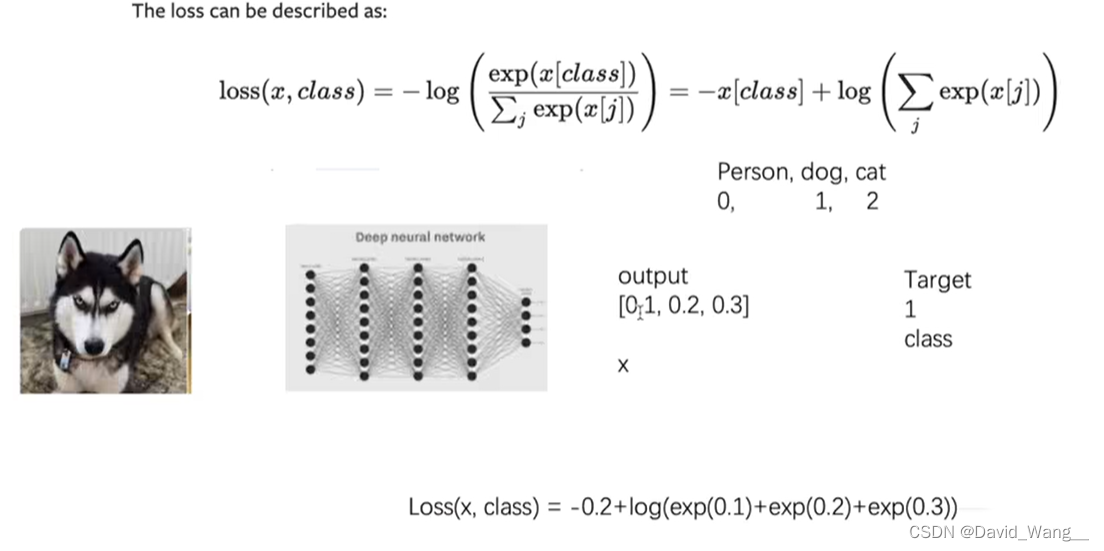
CrossEntropyLoss 计算交叉熵
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
# 1 batch_size;有3类(概率分别为0.1,0.2,0.3)
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
反向传播
根据loss得到grad,再用grad对参数进行优化,达到loss降低的目的
result_cross.backward()
优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
for input, target in dataset:
optimizer.zero_grad() # 清零,以防上一步的梯度造成影响
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
模型的保存与加载
推荐使用以下方式进行操作
**# 保存方式2,模型参数(官方推荐,空间更小)**
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
**# 方式2,对应保存方式2,加载模型**
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
完整的模型训练
开始训练(设置训练轮数epoch → ____.train() → 得到误差 → 放到优化器中优化 → 一轮结束后进行测试 → 计算误差/正确率)
最后验证,结果聚合展示
利用GPU训练
网络模型 & 数据(输入/标注)& 损失函数
以上三者含有.cuda()方法,可以进行GPU训练
注意在每一次cuda使用之前要if torch.cuda.is_available():确保GPU可用再进行cuda操作
# 用GPU训练方法1
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
没有显卡可以采用colab在线进行GPU训练
# 用GPU训练方法2
# 定义训练的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 之后可以如下使用
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
项目整理
此压缩包中含有上述笔记中对应的代码共20个专题,后续附上
再次感谢土堆老师!
涉及的图片如下,侵删







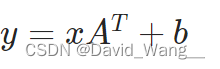

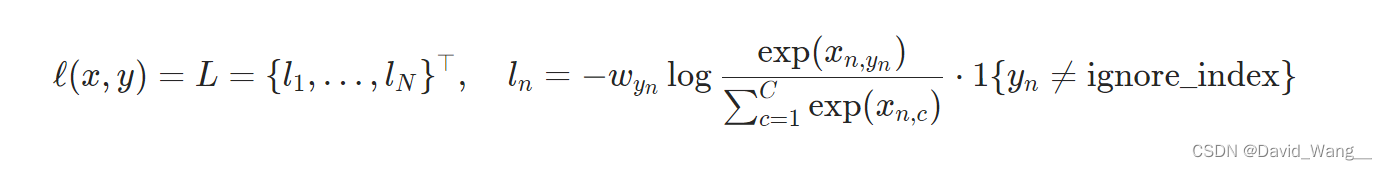















 938
938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









