







今天学习的内容是昇思(MindSpore)平台初学教程里的数据集Dataset
先贴上打卡截图
简介
数据集Dataset类在深度学习中一般用于加载原始数据,将原始数据初始化为易用的格式。在MindSpore中既有一些预加载的数据集,也提供了接口来自定义数据集。
数据集Dataset
导入必要的库
import numpy as np
from mindspore.dataset import vision
from mindspore.dataset import MnistDataset, GeneratorDataset
import matplotlib.pyplot as plt
预定义数据集:Minist
Minist数据集可以直接用包里的MinistDataset来加载
# 下载数据集
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
# 初始化数据集对象,加载数据集
train_dataset = MnistDataset("MNIST_Data/train", shuffle=False)
自定义数据集
可随机访问数据集
顾名思义,就是可以直接通过[i]来访问第i个样本的数据集。主要是要实现两个方法:__getitem__、__len__。
class RandomAccessDataset:
def __init__(self):
self._data = np.ones((5, 2))
self._label = np.zeros((5, 1))
def __getitem__(self, index):
return self._data[index], self._label[index]
def __len__(self):
return len(self._data)
loader = RandomAccessDataset()
dataset = GeneratorDataset(source=loader, column_names=["data", "label"])
直接用List或tuple也是可以的
loader = [np.array(0), np.array(1), np.array(2)]
dataset = GeneratorDataset(source=loader, column_names=["data"])
可迭代数据集
只能按顺序逐个获取样本,适用于随机访问成本太高或不可行的情况。要实现__iter__和__next__方法。
class IterableDataset():
def __init__(self, start, end):
'''init the class object to hold the data'''
self.start = start
self.end = end
def __next__(self):
'''iter one data and return'''
return next(self.data)
def __iter__(self):
'''reset the iter'''
self.data = iter(range(self.start, self.end))
return self
loader = IterableDataset(1, 5)
dataset = GeneratorDataset(source=loader, column_names=["data"])
也可以通过生成器来搞可迭代数据集
# Generator
def my_generator(start, end):
for i in range(start, end):
yield i
dataset = GeneratorDataset(source=lambda: my_generator(3, 6), column_names=["data"])
数据集操作
迭代
调用create_tuple_iterator()。默认output_numpy=False, 输出类型为Tensor,设置output_numpy=True后输出类型为Numpy
for idx, (image, label) in enumerate(train_dataset.create_tuple_iterator(output_numpy=True)):
print(type(image))
break
for idx, (image, label) in enumerate(train_dataset.create_tuple_iterator()):
print(type(image))
break
输出:
<class 'numpy.ndarray'>
<class 'mindspore.common.tensor.Tensor'>`
Shuffle
打乱数据顺序,可以避免数据排列对模型的影响。
train_dataset = train_dataset.shuffle(buffer_size=64)
map
对指定列用函数进行映射,比如做一个缩放并转为默认的浮点数float32类型
train_dataset = train_dataset.map(vision.Rescale(1.0 / 255.0, 0), input_columns='image')
batch
把数据集以batch_size的数量为单位打包到一起,如下图所示(来自MindSpore教程)。
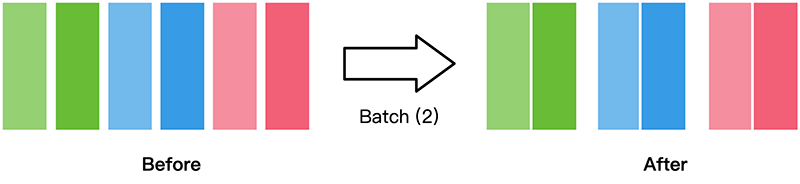
train_dataset = train_dataset.batch(batch_size=32)
image, label = next(train_dataset.create_tuple_iterator())
print(image.shape, image.dtype)
输出:
(32, 28, 28, 1) Float32
总结
今天学习了昇思框架中数据集相关的知识,包括预定义数据集Minist、两种自定义数据集的构造,数据集的几种操作包括迭代访问、Map、Shuffle、Batch,作为data_pipe的开头,理解清楚这一部分的内容还是挺重要的。















 1378
1378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









