







1 - The Problem of Overfitting 过拟合问题
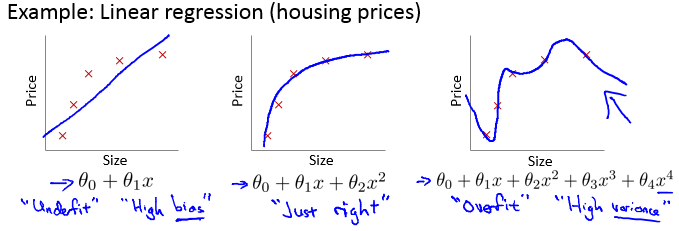
- Overfitting:太多features,Hypothesis函数能非常好的拟合训练集,使得J(θ)≈0。但是不能适应一般情况,对测试集预测效果较差。
- 解决方法:
- 减少属性数目:人工选择应该保留的属性,使用模型选择算法(后续章节会讲到)
- Regularization:
- 保留所有的features,但是减小参数 θ 的值
- 即使在features很多的情况下效果也很好,每个feature对y的预测都有贡献。
2 - Cost Function 代价函数
J(θ)=12m[∑i=1m(hθ(x(i))−y(i))+λ∑j=1nθ2j]
- 更小的 θ 值:hypothesis函数更简单、过拟合可能性更小。
- 如果此时 λ 选取了一个非常大的值呢?
- 算法运行正常(许多属性将被舍弃)
- 无法消除过拟合问题
- 算法出现欠学习现象
- 梯度下降法无法收敛
- 注意:
只要是用到 regularization 的地方,都要记住:只考虑对输入x有权值的参数 θ 的影响。不如,这里不能加上 θ0^2,而只能计算从 θ1~θn 的情况!!!!
3 - Regularized Linear Regression 线性回归的规范化
Gradient Descent
}Repeat{θ0:=θ0−α1m∑i=1m(hθ(x(i))−y(i))x(i)0θj:=θj(1−αλm)−α1m∑i=1m(hθ(x(i))−y(i))x(i)jNormal equation
X=⎡⎣⎢⎢⎢(x(1))T⋮(x(m))T⎤⎦⎥⎥⎥,y=⎡⎣⎢⎢y(1)⋮y(m)⎤⎦⎥⎥θ=(XTX+λ⎡⎣⎢⎢⎢⎢⎢01⋱1⎤⎦⎥⎥⎥⎥⎥)−1XTyNon-invertibility 矩阵不可逆问题在这里得到了解决
- 另外,可以证明,当λ>0时,上面的 θ 表达式一定是可逆的。
- m<=n(样本数量比属性还少):
4 - Regularized Logistic Regression 逻辑回归的规范化
Hypothesis公式和Cost function:
hθ(x)=g(θTx)
J(θ)=[−1m∑i=1my(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]+λ2m∑j=1nθ2j
J(θ)=12m[∑i=1m(hθ(x(i))−y(i))+λ∑j=1nθ2j]
下面是具体的算法:
Gradient Descent
}Repeat{θ0:=θ0−α1m∑i=1m(hθ(x(i))−y(i))x(i)0ifj=0θj:=θj−α[1m∑i=1m(hθ(x(i))−y(i))x(i)j−λmθj]ifj=1,2,3,…,n其实也就是Linear Regression中的公式:
}Repeat{θ0:=θ0−α1m∑i=1m(hθ(x(i))−y(i))x(i)0θj:=θj(1−αλm)−α1m∑i=1m(hθ(x(i))−y(i))x(i)j- Advanced optimization
















 3803
3803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









