







1 - Optimization Objective 优化目标
1.1 从logistic regression来看
首先来看Logistic regression的hypothesis函数: hθ(x)=11+e−θTx ,可以知道:
- 当y=1时,我们希望 hθ(x)≈1 ,那么此时必须有: θTx≥0
- 当y=0时,我们希望 hθ(x)≈0 ,那么此时必须有: θTx≤0
- 误差公式:
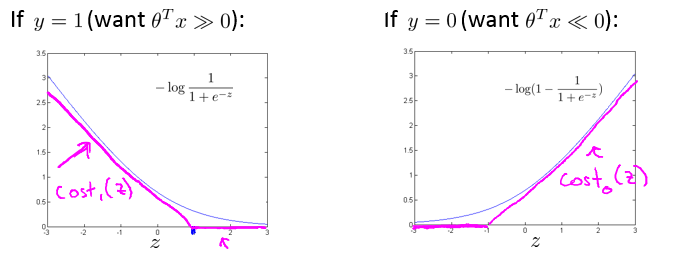
=−yloghθ(x)−(1−y)log(1−hθ(x))−ylog11+e−θTx−(1−y)log(1−11+e−θTx) - 用图来表示
−log11+e−z
和
−log(1−11+e−z)
:
- 令图中品红色的曲线分别为 Cost1(z) 和 Cost0(z) ,我们将在SVM中使用这两个函数衡量误差。
1.2 优化目标
Logistc regression:
minθ1m[∑i=1my(i)(−loghθ(x(i)))+(1−y(i))((−log(1−hθ(x(i)))))]+λ2m∑j=1nθ2jSVM:
minθC∑i=1m[y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))]+12∑j=1nθ2jSVM hypothesis:
hθ(x)={1ifθTx≥00otherwise
2 - Large Margin Intuition
首先来看我们之前定义的优化目标:
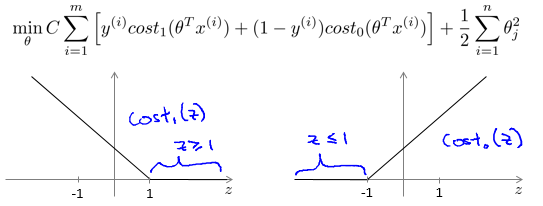
可以看到,我们的cost function与logistic regression相比已经发生了明显的改变:
- 要预测 y=1,我们要求 θTx≥1 ,而不再是 θTx≥0
- 要预测 y=0,我们要求 θTx≤−1 ,而不再是 θTx<0
那么 SVM 的 Decision Boundary 必然与 logistic regression 不同。SVM的 Decision Boundary 主要特点是 Large Margin,这也是 SVM 被称为 Large margin classifier 的原因。用图来表述:
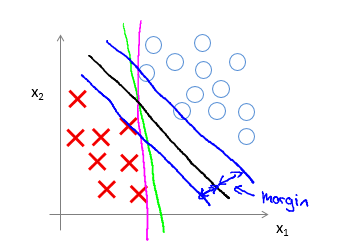
特殊的cost function 让 SVM 会选择一个 margin 最大的 Decision Boundary 。
3 - Kernels 核函数
3.1 what is Kernels
我们来看如下的分类问题:
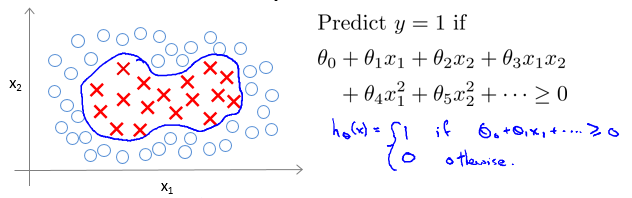
在选择features的时候,我们在logistic regression时选取的是 x1,x2,x1x2,x21,x22 ,并用 θTx 作为 hθ 的判断条件。
在 SVM 中,我们采取了另外的选择 feature 的方法,称为核函数。
Kernels and Similarity:

- 我们选取n个点,作为 landmarks(地标),用
similarity(x,l(i))
表示样本 x 与
l(i)
的相似程度,将它作为一个 feature ,用
fi
来表示,这就是核函数。
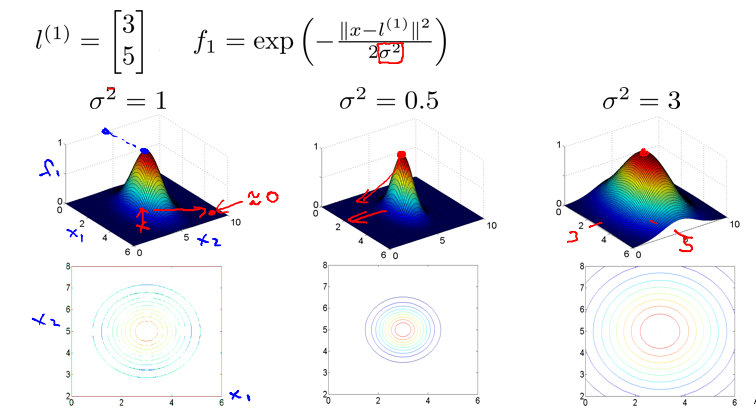
fi=similarity(x,l(i))=exp(−∥x−l(i)∥22σ2)(GuassianKernel) - Hypothesis:
- Predict “1” when θ0+θ1f1+θ2f2+θ3f3≥0
- 关于 Guassian Kernel:
- 若 x≈l(i) , 那么 fi=exp(−022σ2)≈1
- 若 x 与 l(i) 相差很大,那么 fi=exp(−(largenumber)22σ2)≈0
- 关于
σ2
的取值问题:
3.2 Kernel的应用
Given(x(1),y(1)),(x(2),y(2)),…,(x(m),y(m)),
- Choosel(1)=x(1),l(2)=x(2),…,l(m)=x(m).
-
Giventrainingexample(x(i),y(i)):
f(i)1=similarity(x(i),l(1))f(i)2=similarity(x(i),l(2))⋮f(i)m=similarity(x(i),l(m))
值得注意的是,其中 f(i)i=similarity((x(i),l(i))=1 - Hypothesis:
Predicty=1ifθTf≥0 ,其中 f∈Rm+1,f=⎡⎣⎢⎢⎢⎢⎢f0f1⋮fm⎤⎦⎥⎥⎥⎥⎥ Optimization Objective:
minθC∑i=1m[y(i)cost1(θTf(i))+(1−y(i))cost0(θTf(i))]+12∑j=1mθ2j关于 SVM 参数的选择:
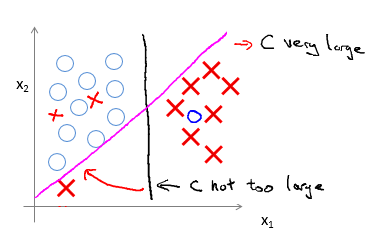
C的选择
- Large C:Lower bias,high variance.
- Small C:Higher bias,low variance.
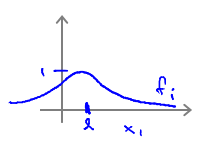
σ2 的选择
- Large
σ2
:属性
fi
的曲线比较平缓,Higher bias,low variance.
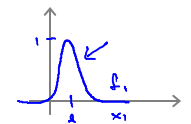
- Small
σ2
:属性
fi
的曲线比较陡峭,Lower bias,high variance.
4 - Using An SVM
4.1 基本用法
使用软件包(如liblinear,libsvm,…)来求解参数 θ 。
需要指定的参数:
- 参数 C 的选择
- Kernel的选择
- No kernel(“linear kernel”):Predict “y=1” if θTx≥0 ,选择条件:n 很大,m较小
- Guassian Kernel:需要选择 σ2 ,选择条件:n较小,m很大
- 其他:polynomial kernel,String kernel,chi-square kernel,histogram intersection kernel
特别提醒: 在处理数据时不要忘了 feature scaling
4.2 Multi-class classification:

4.3 Logistic regression 与 SVM 相对比
- 如果 n 很大,m 较小:
用 logistic regression 或者 SVM without kernel(“linear kernel”) - 如果 n 较小,m中等大小:
用 SVM with Guassian kernel - 如果 n 较小,m 很大:
先添加一些features,再使用logistic regression 或者 SVM without kernel - Neural network 在以上情况下都可以用,但是可能训练起来比较慢















 6163
6163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









