







1 - Learning With Large Datasets
由前面章节的知识可知,在模型属于 low bias & high variance 的时候,增大数据集是对结果大有好处的。
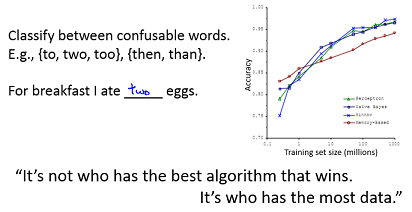
Andrew NG 给的示例:
2 - Stochastic [sto’kæstɪk] Gradient Descent 随机梯度下降
常见的 Linear Regression 的梯度下降算法:
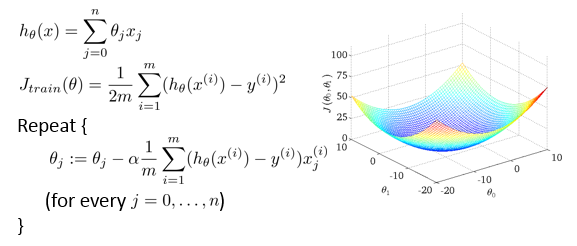
它的特征是每次迭代都需要对所有的训练数据进行一次遍历,在数据集非常大的时候算法运行会比较慢。
改进后的 Stochastic gredient descent 算法:
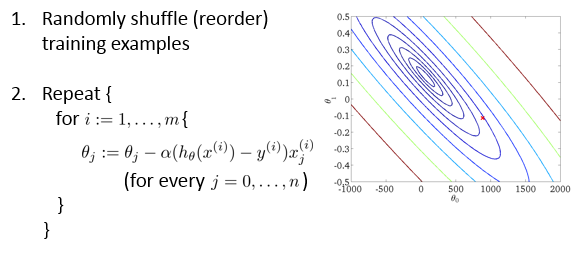
每次迭代只使用一个训练数据,每个训练数据都对参数θ的改进有一些影响。这样在数据量较大的时候运行速度能明显提升。缺点是收敛过程可能是波动的。
3 - Mini-Batch Gradient Descent
Batch gradient descent 与 stochastic gradeint descent 的折中:
- Batch gradient descent: Use **all m **examples in each iteration
- Stochastic gradient descent: Use 1 example in each iteration
- Mini-batch gradient descent: Use b examples in each iteration
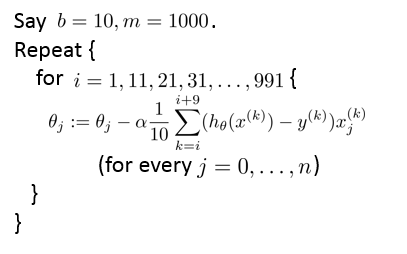
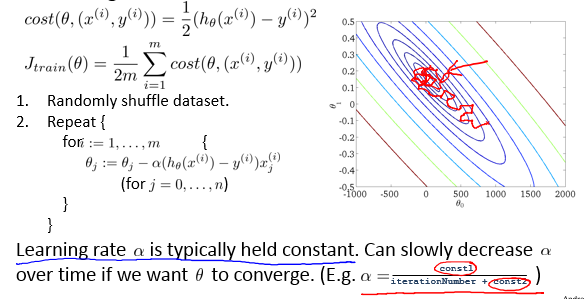
4 - Stochastic Gradient Descent Convergence 随机梯度下降算法的收敛性
Checking for convergence:
Batch gradient descent:每迭代一次计算一次 J(θ) ,绘制出 J(θ) 随迭代次数的变化情况。
Stochastic gradient descent:每1000次迭代绘制一次 cost(θ,(x(i),y(i))) 。
5- Online Learning 在线学习
训练数据不是一开始就有的,而是在不断地动态生成。
假设样例到来的先后顺序为
(x(1),y(1)),(x(2),y(2)),…,(x(n),y(n))
,X为样本特征,y为类别标签。我们的任务是到来一个样例x,给出其类别结果y的预测值,之后我们会看到y的真实值,然后根据真实值来重新调整模型参数,整个过程是重复迭代的过程,直到所有的样例完成.

6 - Map Reduce and Data Parallelism
算法思想:发挥计算机的硬件性能,在多核计算机或计算集群上进行大数据量的学习。
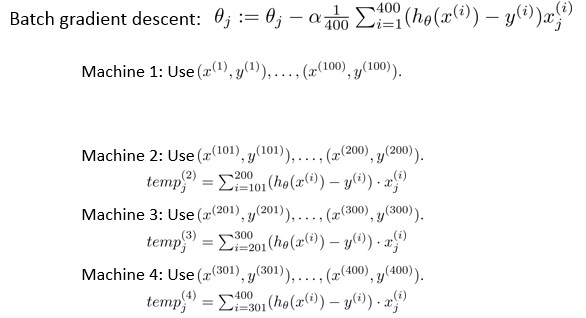
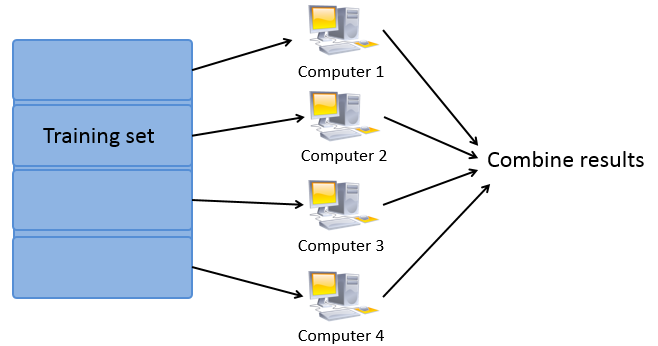
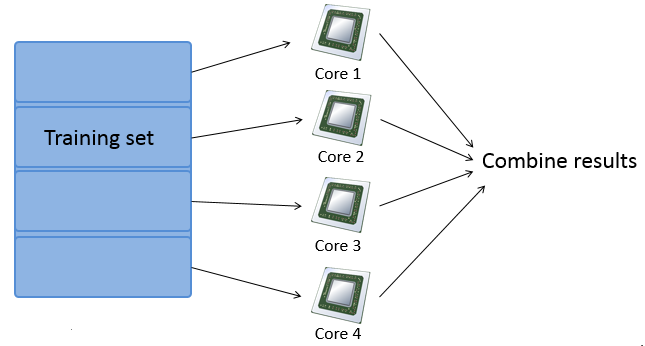
哪些情况下可以使用 Map reduce 算法:
Many learning algorithms can be expressed as computing sums of functions over the training set.
算法步骤中出现了对训练数据的求和的情况,那么就可以将任务划分到堕胎计算机上进行处理。
例如:
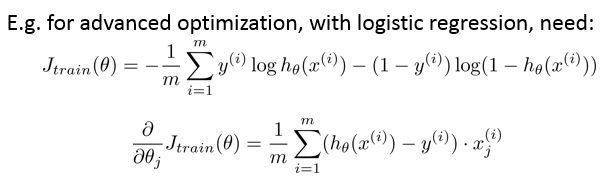















 4863
4863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









