







一、Intel RealSense D435(使用了yolov8)
Intel RealSense D435是一款具备距离感知功能的摄像头,它采用了yolov8算法来实现物体种类识别和距离定位。
环境配置
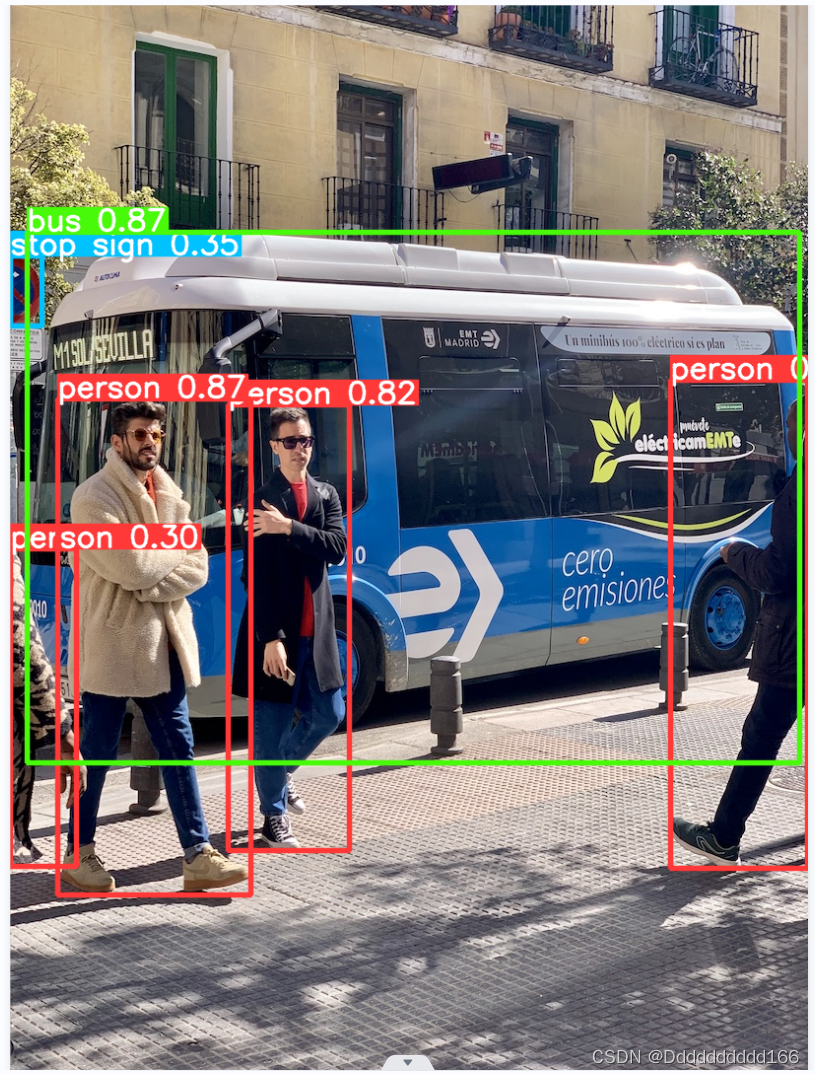
分析图片(需要将图片放在与代码同一个文件夹)
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # pretrained YOLOv8n model
# Run batched inference on a list of images
results = model(['zidane.jpg'], stream=True) # return a generator of Results objects
# Process results generator
for result in results:
boxes = result.boxes # Boxes object for bounding box outputs
masks = result.masks # Masks object for segmentation masks outputs
keypoints = result.keypoints # Keypoints object for pose outputs
probs = result.probs # Probs object for classification outputs
result.show() # display to screen
result.save(filename='result.jpg') # save to disk例

分析视频(同一文件夹)
import cv2
from ultralytics import YOLO
# Load the YOLOv8 model
model = YOLO('yolov8n.pt')
# Open the video file
video_path = "12.mp4"
cap = cv2.VideoCapture(video_path)
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLOv8 inference on the frame
results = model(frame)
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Display the annotated frame
cv2.imshow("YOLOv8 Inference", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()
分析实时摄像头
import cv2
from ultralytics import YOLO
# 加载YOLOv8模型
model = YOLO('runs/yolov8n.pt')
# 打开摄像头
cap = cv2.VideoCapture(0) # 0表示默认摄像头,如果有多个摄像头,可以尝试不同的索引
# 循环读取摄像头帧
while True:
# 从摄像头读取一帧
success, frame = cap.read()
if success:
# 在帧上运行YOLOv8推理
results = model(frame)
# 在帧上可视化结果
annotated_frame = results[0].plot()
# 显示带注释的帧
cv2.imshow("YOLOv8目标检测", annotated_frame)
# 检测按键输入
key = cv2.waitKey(1) & 0xFF
# 如果按下'q'键则退出循环
if key == ord("q"):
break
else:
break
# 释放摄像头捕获对象
cap.release()
# 关闭显示窗口
cv2.destroyAllWindows()
调用了本机摄像头

还可调用外接摄像头,如Intel RealSense D435,只需更改id
cap = cv2.VideoCapture(700) # 0表示默认摄像头,如果有多个摄像头,可以尝试不同的索引

二、飞桨PaddlePaddle基础学习
前往官网配置环境
快速了解深度学习模型开发的大致流程,并初步掌握飞桨框架 API 的使用方法。
深度学习任务一般分为以下几个核心步骤:
-
数据集定义与加载
-
模型组网
-
模型训练与评估
-
模型推理
可以实现读取训练集中的代码进行识别图片数字与输出训练集的图片
import paddle
import numpy as np
from paddle.vision.transforms import Normalize
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# 下载数据集并初始化 DataSet
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
# 模型组网并初始化网络
lenet = paddle.vision.models.LeNet(num_classes=10)
model = paddle.Model(lenet)
# 模型训练的配置准备,准备损失函数,优化器和评价指标
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 模型训练
model.fit(train_dataset, epochs=5, batch_size=64, verbose=1)
# 模型评估
model.evaluate(test_dataset, batch_size=64, verbose=1)
# 保存模型
model.save('./output/mnist')
# 加载模型
model.load('output/mnist')
# 从测试集中取出一张图片
img, label = test_dataset[0]
# 将图片shape从1*28*28变为1*1*28*28,增加一个batch维度,以匹配模型输入格式要求
img_batch = np.expand_dims(img.astype('float32'), axis=0)
# 执行推理并打印结果,此处predict_batch返回的是一个list,取出其中数据获得预测结果
out = model.predict_batch(img_batch)[0]
pred_label = out.argmax()
print('true label: {}, pred label: {}'.format(label[0], pred_label))
# 可视化图片
from matplotlib import pyplot as plt
plt.imshow(img[0])
plt.show()

尝试是否可以实现识别其他。jpg图片
import paddle
import numpy as np
from paddle.vision.transforms import Normalize
import matplotlib.pyplot as plt
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# 下载数据集并初始化 DataSet
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
# 模型组网并初始化网络
lenet = paddle.vision.models.LeNet(num_classes=10)
model = paddle.Model(lenet)
# 模型训练的配置准备,准备损失函数,优化器和评价指标
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 模型训练
model.fit(train_dataset, epochs=5, batch_size=64, verbose=1)
# 模型评估
model.evaluate(test_dataset, batch_size=64, verbose=1)
# 保存模型
model.save('./output/mnist')
model.load('output/mnist')
from PIL import Image
# 加载新的jpg图片,并进行必要的预处理
new_img_path = '1.jpg' # 替换为您想要使用的jpg图片路径
new_img = Image.open(new_img_path).convert('L') # 转为灰度图像
new_img = new_img.resize((28, 28)) # 缩放为MNIST数据集的大小
new_img = np.array(new_img) # 转为numpy数组
new_img = (new_img - 127.5) / 127.5 # 归一化处理
new_img_batch = np.expand_dims(new_img, axis=0) # 添加一个批处理维度
new_img_batch = np.expand_dims(new_img_batch.astype('float32'), axis=0) # 将图片shape从1*28*28转换为1*1*28*28
# 执行推理并打印结果
# 执行推理并打印结果
out = model.predict_batch(new_img_batch)[0]
pred_label = np.argmax(out)
print('Predicted label: {}'.format(pred_label))
if len(out) > pred_label:
print('Confidence: {}'.format(out[pred_label]))
else:
print('Invalid confidence index')
# 可视化新的jpg图片
plt.imshow(new_img, cmap='gray')
plt.show()
结果是不太准确比较模糊
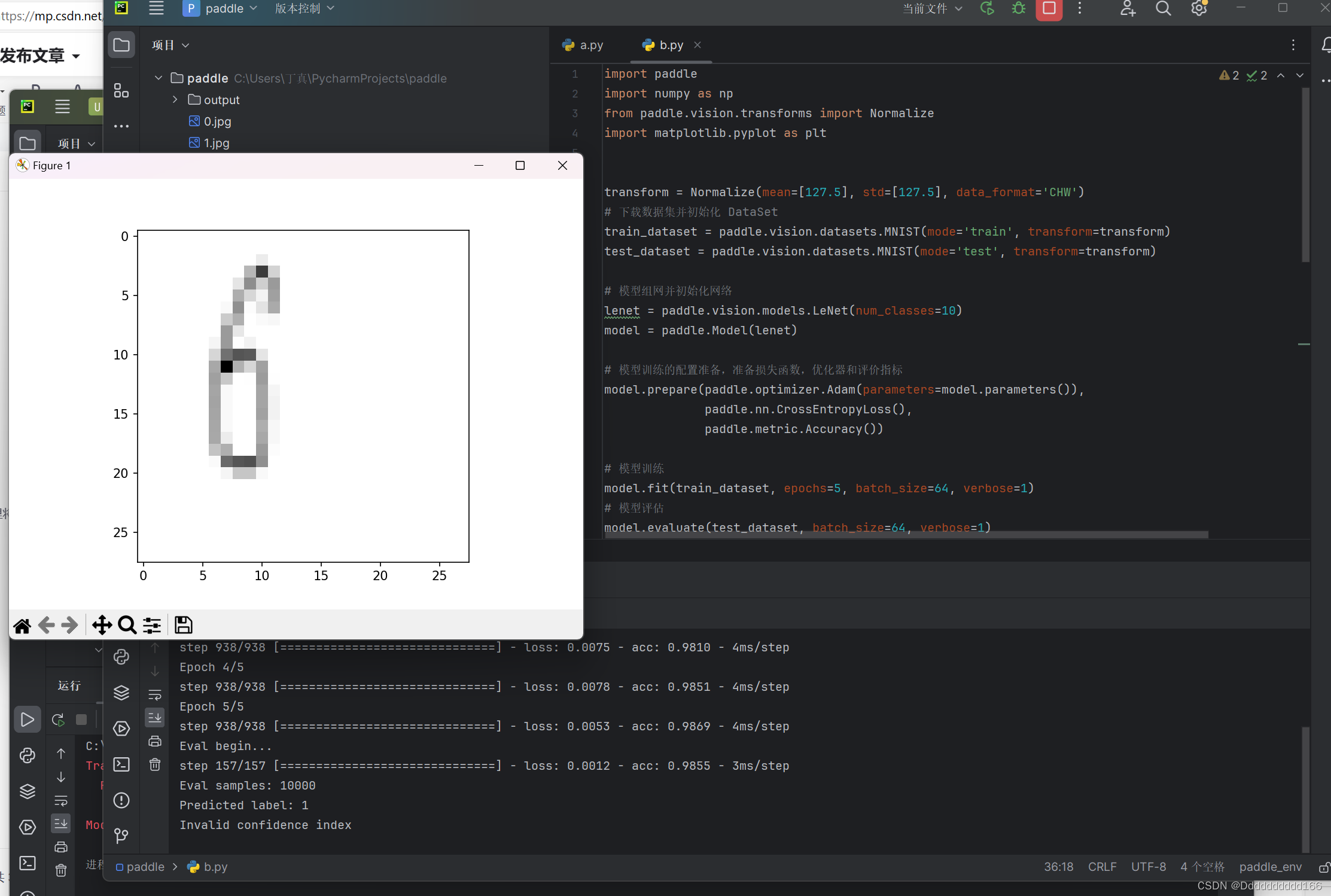
Predicted label: 1
三、了解物体在空间中三维坐标的表示,并实现视觉坐标系和大地坐标系的变换。
在三维空间中,物体的三维坐标表示通常采用笛卡尔坐标系,即通过三个坐标轴(X、Y、Z)来确定一个点的位置。这种表示方法在计算机图形学、机器人学和许多其他领域中非常常见为了实现视觉坐标系和大地坐标系之间的变换,首先需要理解这两种坐标系的基本概念和特点。
视觉坐标系通常指的是与相机或观察者相关的坐标系,它描述的是从相机中心到物体表面点的向量。在双目立体视觉中,世界坐标系可以被用来描述相机的位置,而相机坐标系则直接关联到相机本身图像坐标系则是基于像素的二维坐标系,用于描述图像中的点
大地坐标系则是一种基于地球表面或其参考椭球体的坐标系统,常用于地理信息系统(GIS)中。它包括经度、纬度和高程三个维度,能够精确地表示地球表面上某一点的位置。大地直角坐标系是根据参考椭球面建立的笛卡尔直角坐标系,原点为参考椭球面的中心点
要实现从视觉坐标系到大地坐标系的变换,首先需要将视觉坐标系中的点转换到世界坐标系中,这通常涉及到旋转和平移的操作。然后,如果需要,可以从世界坐标系转换到大地坐标系,这可能涉及到复杂的地理信息和数学模型。在这个过程中,旋转矩阵和平移向量是常用的工具,它们可以通过矩阵乘法来实现对坐标系中点的旋转和平移。此外,齐次坐标技术也是处理三维空间变换的重要方法,它允许在进行平移、旋转、缩放等操作时使用统一的矩阵表示法。在实际应用中,如SLAM(Simultaneous Localization and Mapping,即同时定位与地图构建)技术,就需要频繁地进行坐标系之间的转换,以实现对环境的准确理解和映射
总之,了解物体在空间中的三维坐标表示,并实现视觉坐标系和大地坐标系之间的变换,需要掌握三维坐标变换的基本原理和方法,包括但不限于旋转矩阵、齐次坐标以及地理信息的应用。这些知识和技术在计算机视觉、机器人学、GIS等多个领域都有广泛的应用。


















 4140
4140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









