







幸存者偏差(英语:survivorship bias),另译为“生存者偏差”,是一种认知偏差。其逻辑谬误表现为过分关注于目前人或物“幸存了某些经历”然而往往忽略了不在视界内或无法幸存这些事件的人或物。
在第二次世界大战期间,英国几乎每天派遣轰炸机飞越英吉利海峡,许多飞行员在这个冒险行动中不幸牺牲。为了提高飞行员的生存机会,统计学沃德教授应军方要求,利用其在统计方面的专业知识来提供关于《飞机应该如何加强防护,才能降低被炮火击落的几率》的相关建议。沃德教授提出的建议非常奇怪:装甲位置不该是弹孔最密集的机翼,而是未中弹的机尾部位。
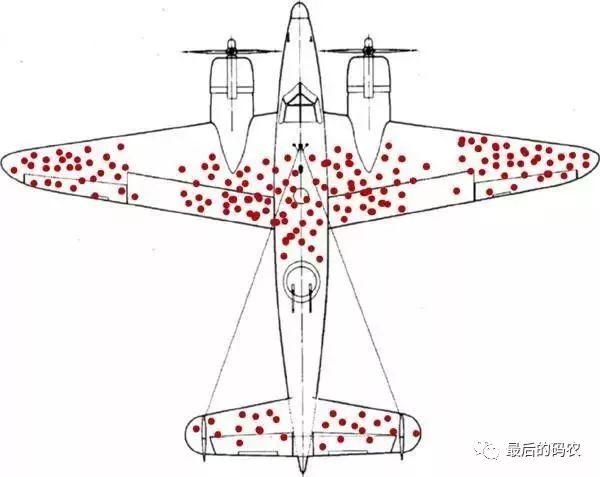
他的想法是:有着千疮百孔的机翼的飞机既然能安然返航,显然这些弹孔几乎不会损害飞机。而中弹位置与返回飞机不同的战机,均未能安全返航。也就是说,平安归来的飞机遭受弹孔攻击的部位,都是最不致命的地方,所以不会导致飞机坠落。统计学家给工程师犯的这种致命错误取了个名字──“幸存者偏差”。简单地说,就是我们只会考虑到幸存者,直接忽略那些死亡的人,这就是为什么会出现存活率假象的主因。
再举一个非常简单的例子:
一名记者来到火车站台上,随机询问:“请问你买到火车票了吗?”
一位大妈微微一愣,回答:“买到了”
记者又转向一位精瘦精瘦的年轻人,问:“请问你买到火车票了吗?”
年轻人回答:“买到了”
随后记者又问了5个人,大家都回答:“买到了”
最后记者对着镜头说:“今年虽然火车票难买,但是通过采访我们发现,大家都买到了火车票,现在正满怀希望地赶回家乡,过个团圆年!”
幸存者偏差,就是忽略了筛选条件,把经过筛选的结果当成随机结果。
生活中我们大多数人所认为的事情,其实都是错的,举两个例子。
随着参加高考的人数越来越多,高考的录取率也越来越高,2018年的参加高考的人数是975万,前六年的录取率都在74%以上,也就意味着每年100个人参加高考就会有74个同学可以考上大学,如果算上一些民营或者专科类高校,可以说只要参加高考了就可以上大学。
大家现在身边经常会流行这么一句:现在满大街都是大学生了。但其实根据统计本科生占据总人口的比例是3.69%,换句话说,
只要你是本科生,你的学历就碾压了97%的中国人!
好多程序员都称自嘲为IT民工,身边朋友也普遍认为一线月入一万都是门槛级别的收入。
但其实2018年,国家统计局公布了中国人可支配收入的中位数:2028元/月。这个数据是不是超出大多数人的预期?
可支配收入的定义,可以理解为在缴纳税/险/金之后的到手收入;
中位数的定义,可以理解为一半的人在此收入之上,一半的人在此收入之下,在统计学里被认为比平均数要更加客观。
如果我说中国有些地方的年轻人,竟然听不懂普通话,一辈子没有走出过他们县城,大家是不是觉得很夸张。
2018年我国农村还有5000万贫困人口。如何定义为贫困人口呢?2016年的标准是年收入少于3026元,请注意这里是年收入而不是月收入。
我们常常都喜欢把自己身边人的情况,当成了世界的普世情况.

不要认为马云成功了就去模仿马云,可能淘宝也是幸存者偏差的一种现象。存活下来的企业往往被视为“传奇”,它们的做法被争相效仿,而其实有些也许只是因为偶然原因幸存下来了而已。
我们在看我们不熟悉的行业时,往往被这种存活者偏差所蒙蔽,报纸杂志更是时常针对那些所谓成功的企业案例,赋予一些戏剧化的故事,让我们以为成功唾手可得。实际上,这些结果论的成功故事只是锦上添花,他们所归纳出的成功要诀往往只是整幅画里面的其中一小块拼图,这些1%的存活者得以大声说话,让我们以为前景一片看好,我们却没有看到其他99%的竞争者早就默默地战死沙场了!创业如是,投资亦如是,那些靠炒股票炒房地产一夜致富而声名大噪的“专家”们,终究只是幸存下来的相对少数(更不用说有些人只是报喜不报忧,赚钱的时候大吹大擂,赔钱的时候就闷不吭声),如果我们这些小小散户盲目的跟着他们跳进去瞎搅和,最后往往只能落得尸骨无存而已。
比如,有人说,祈祷可以治疗绝症。身患绝症的患者,为了求生往往什么都会尝试,这时候有人告诉他,曾经有个某某祈祷后获得了神的救赎,最终变得活蹦乱跳。所以,祈祷可以治疗绝症,因为这个活下来的人,就经常祈祷。

普通人都喜欢基于自己所熟悉的情况做出判断,那么这个判断难免会具有很大的误差,有时候明明有科学的数据放在那里,大家不去参考借鉴,偏偏却喜欢问身边一个半拉子不懂的人。
这也是为什么某些中药、阿胶、保健品等产物,可以在中国这片神奇的土地上大肆流行的原因之一。中国其实还需要更多的大学生,更多具有理性、独立思考的人,只有这样随着时间推移这些产物才会慢慢淘汰掉。

一旦洞悉“幸存者偏差”的陷阱,就能避免做出错误的决定:不要只看成功的榜样,也要同时观察输家的经验,才能更切合实际地评价成功机会。即便是失败者还是有值得学习之处,例如哪些策略没有效用。想要成功,必须向失败者取经。

















 631
631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









