







本文从贝叶斯定理、朴素贝叶斯概念、应用场景、原理、实现思路、python实现情感倾向预测、模型调优来快速学会朴素贝叶斯,完整版代码见文末。
贝叶斯定理
是概率论中的一个重要定理,描述了在已知某些其他条件的情况下,某一事件发生的概率。这个定理以托马斯.贝叶斯命名
P ( A ∣ B ) = P ( B ∣ A ) ⋅ P ( A ) P ( B ) P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)⋅P(A)
- P ( A ∣ B ) P(A|B) P(A∣B) 是在事件B已经发生的条件下,事件A发生的概率,成为后验概率
- P ( B ∣ A ) P(B|A) P(B∣A) 是在事件 A 已经发生的条件下,事件 B 发生的概率,称为似然概率。
- P(A) 是事件 A 发生的概率,称为先验概率。
- P ( B ) P(B) P(B) 是事件 B 发生的概率。
举例
假设有一种疾病,发病率是1%:P(病) = 0.01
有一个检测这种疾病的测试,如果一个人确实患有这种疾病,测试为阳性的概率是90%:P(阳性|病) = 0.9
如果一个人没有患这种疾病,测试为阳性的概率是10%:P(阳性|非病) = 0.1
现在,如果一个人测试为阳性,我们想知道这个人实际上患有这种疾病的概率是多少。也就是说,我们要计算P(病|阳性)。
根据贝叶斯定理,我们有:
P(病|阳性) = P(阳性|病) * P(病) / P(阳性)
其中,P(阳性)是测试为阳性的总概率,可以通过全概率公式计算得到:
P(阳性) = P(阳性|病) * P(病) + P(阳性|非病) * P(非病)
将已知的概率值代入公式中,我们得到:
P(病|阳性) = 0.9 * 0.01 / (0.9 * 0.01 + 0.1 * 0.99)
≈ 0.083
所以,如果一个人测试为阳性,那么这个人实际上患有这种疾病的概率是约8.3%。
*
朴素贝叶斯分类
朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的简单概率分类算法,其中对于给定的类别,每一对特征之间都是相互独立的。这种独立性假设使得算法在计算上非常高效,特别是在处理具有大量特征的数据集时。
举例
在朴素贝叶斯分类中,我们通常将 A 看作类别标签,B 看作特征。也就是说,我们希望计算在观察到特征 B 的情况下,样本属于类别 A 的概率,即 P(A|B)。我们的目标是找到使这个概率最大的类别 A。
根据朴素贝叶斯的假设,我们认为特征之间是相互独立的,所以 P(B|A) 可以分解为各个特征概率的乘积:
P(B|A) = P(B1|A) * P(B2|A) * … * P(Bn|A)
其中,B1, B2, …, Bn 是输入特征的各个维度。
将这个分解代入贝叶斯定理的公式中,我们得到:
P(A|B) = P(B1|A) * P(B2|A) * … * P(Bn|A) * P(A) / P(B)
由于对于所有的类别 A,分母 P(B) 都是相同的,所以在分类时,我们可以忽略它,只需要计算分子部分。也就是说,我们可以通过计算 P(B1|A) * P(B2|A) * … * P(Bn|A) * P(A) 并选择使这个值最大的类别 A 作为预测结果。
应用场景
-
文本分类: 在处理文本数据时,朴素贝叶斯分类器能够准确识别出垃圾邮件、情感倾向、主题分类等。
-
推荐系统: 通过分析用户过去的行为,如浏览记录和购买历史,朴素贝叶斯分类器能够预测用户可能喜欢的商品或内容。
-
医学诊断: 根据患者的症状和体征,朴素贝叶斯分类器能够预测患者可能患有的疾病。
-
面部识别: 通过分析人脸的特征,朴素贝叶斯分类器能够识别出给定面部图像的个体。
-
入侵检测: 通过分析网络流量的特征,朴素贝叶斯分类器能够检测出异常行为或网络攻击。
实现思路
-
数据准备:首先需要收集数据并进行预处理,将数据转换为适合朴素贝叶斯分类器处理的格式。对于文本数据,通常需要进行分词、去停用词等预处理操作。
-
特征选择:选择合适的特征对于分类器的性能至关重要。特征选择方法包括卡方检验、信息增益、互信息等,我们选择卡方检验
-
模型训练:利用训练数据计算先验概率 P(A) 和条件概率 P(A|B)。对于连续特征,可以假设特征服从高斯分布,并计算其均值和方差。对于离散特征,可以计算各个特征值出现的频率。
-
分类预测:对于待分类的样本,计算在该样本特征下属于各个类别的概率 P(B|A),选择概率最大的类别作为预测结果。
-
模型评估:使用测试数据集评估模型的性能,常用的评估指标包括准确率、召回率、F1分数等。
-
模型调优:使用训练数据、测试数据集来来优化模型参数,常用的模型调优方法有网格搜索、随机搜索、贝叶斯优化、模拟退火、遗传算法,我们选用贝叶斯优化。
分类实现
数据加载
# 加载数据
data = pd.read_csv('../datasets/ChnSentiCorp_htl_all.csv')
# 加载停用词
stopwords = [line.strip() for line in open('../datasets/baidu_stopwords.txt', 'r', encoding='utf-8').readlines()]
文本预处理
# 将浮点数转换为保留两位小数的字符串
data['text'] = data['text'].astype(str)
# 定义一个函数来进行文本预处理
def preprocess(text):
# 去除标点符号和特殊字符
text = re.sub(r'[^\w\s]', '', text)
# 分词
words = jieba.cut(text)
# 去除停用词
words = [word for word in words if word not in stopwords]
return ' '.join(words)
# 对文本进行预处理
data['text'] = data['text'].apply(preprocess)
数据探索和可视化
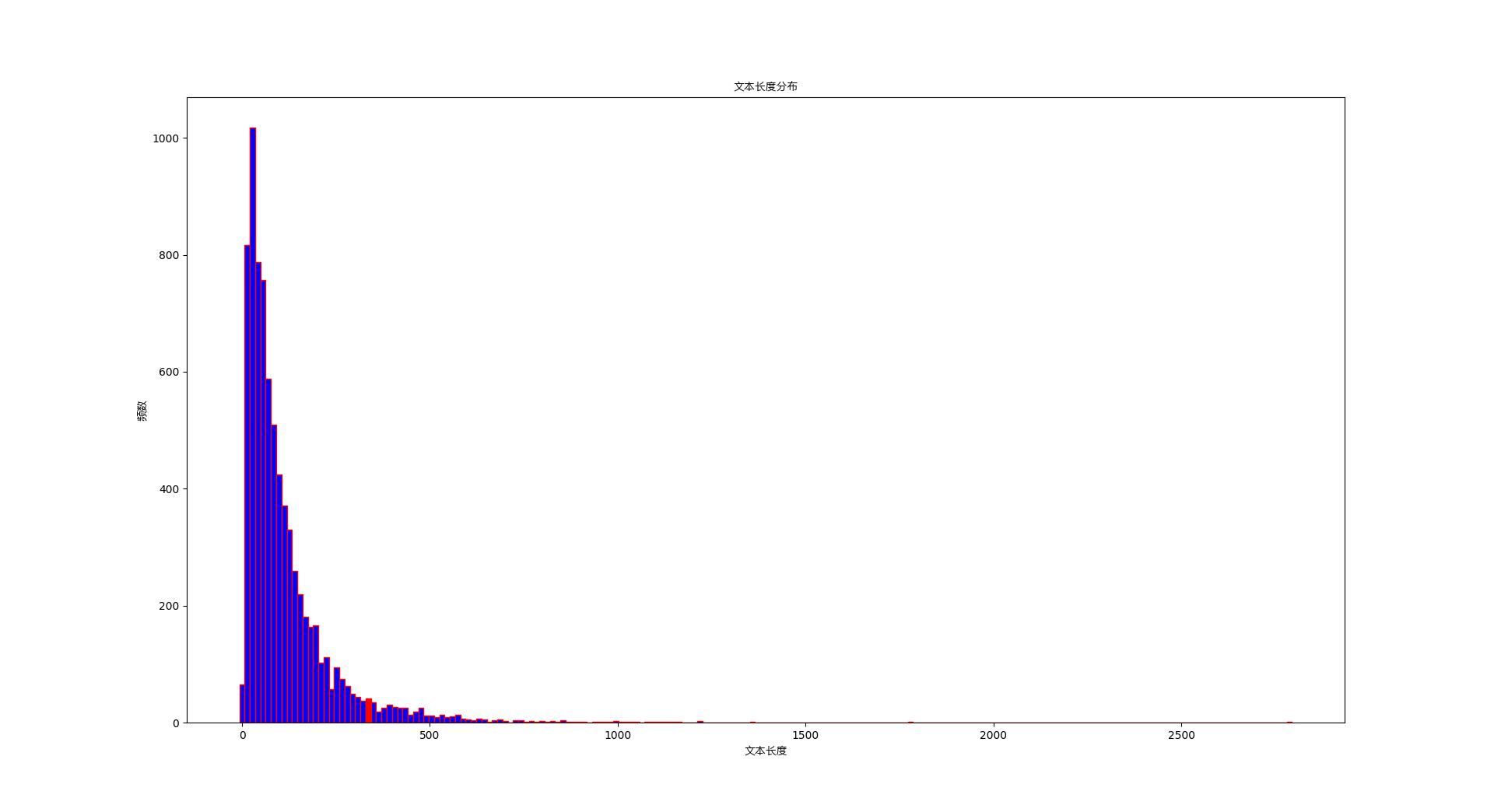
文本长度分布
# 计算文本长度分布
data['text_length'] = data['text'].apply(len)
# 设置文本长度阈值
threshold = 500
# 生成颜色数组
colors = np.where(data['text_length'] < threshold, 'blue', 'red')
# 计算文本长度的分布
counts, bins = np.histogram(data['text_length'], bins=200)
# 绘制文本长度分布直方图
plt.figure(figsize=(20, 10))
plt.bar(bins[:-1], counts, width=np.diff(bins), color=colors[:len(bins) - 1], edgecolor='red')
plt.xlabel('文本长度')
plt.ylabel('频数')
plt.title('文本长度分布')
plt.show()
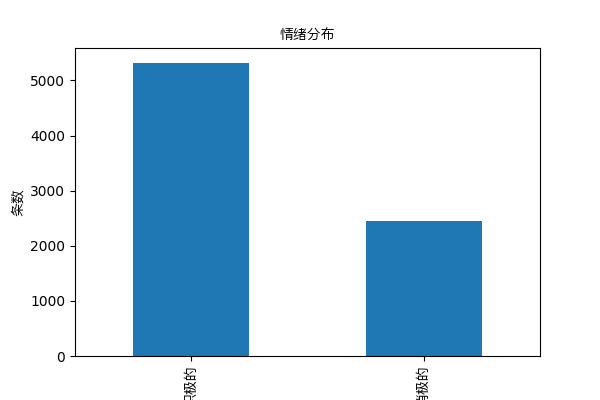
标签分布
# 绘制标签分布柱状图
plt.figure(figsize=(6, 4))
data['label'].value_counts().plot(kind='bar')
plt.xlabel('标签')
plt.ylabel('条数')
plt.title('情绪分布')
plt.xticks([0, 1], ['积极的', '消极的'])
plt.show()
词云
# 生成词云
text = ' '.join(data['text'])
wordcloud = WordCloud(width=800, height=400, background_color='white', font_path=fontPath).generate(text)
# 绘制词云
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()

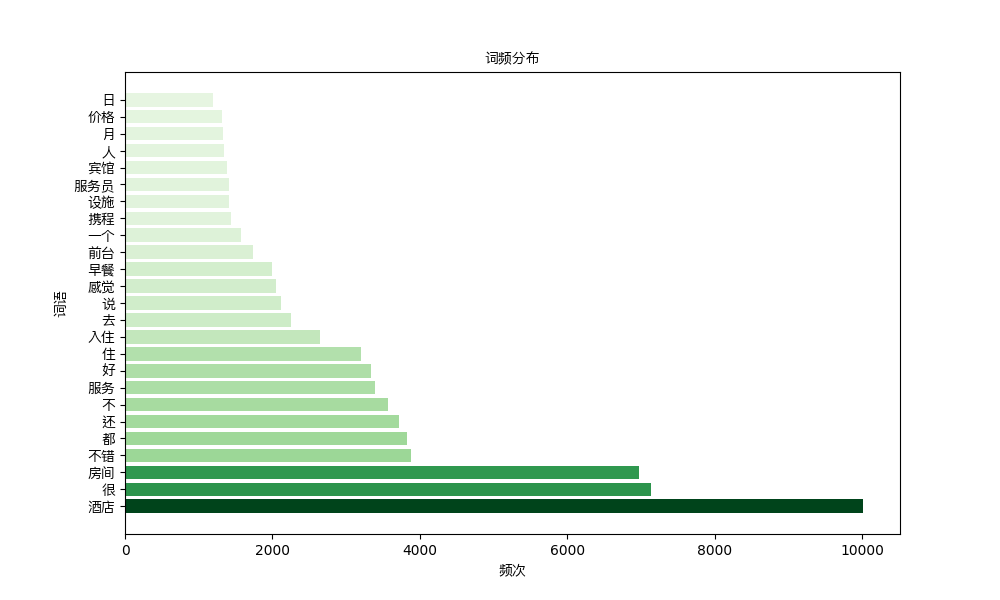
词频分析
# 计算词频
word_counts = Counter(' '.join(data['text']).split())
# 绘制词频分布图
top_words = word_counts.most_common(25)
words, counts = zip(*top_words)
# 绘制横向条形图
relative_counts = counts / np.max(counts)
# 绘制横向条形图
plt.figure(figsize=(10, 6))
plt.barh(words, counts, color=plt.cm.Greens(relative_counts))
plt.ylabel('词语', fontproperties=myFont)
plt.xlabel('频次', fontproperties=myFont)
plt.title('词频分布', fontproperties=myFont)
plt.yticks(range(len(words)), words, fontproperties=myFont)
plt.show()
特征表示
tfidf_vectorizer = TfidfVectorizer()
创建模型和管道
# 创建朴素贝叶斯分类器
classifier = MultinomialNB()
# 创建卡方特征选择器
kbest = SelectKBest(chi2, k=30)
# 创建管道
pipeline = Pipeline([
('tfidf', tfidf_vectorizer),
('kbest', kbest),
('clf', classifier)
])
数据划分
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data['text'], data['label'], test_size=0.2, random_state=42)
模型训练
# 训练模型
pipeline.fit(X_train, y_train)
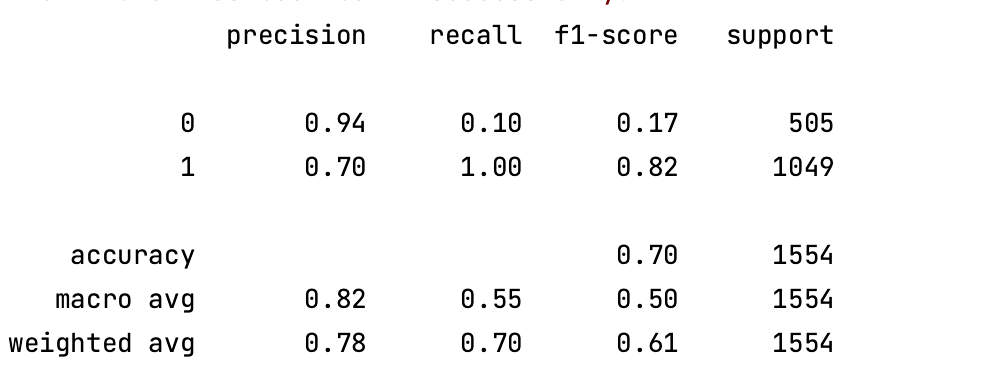
模型评估
# 对测试集进行预测
y_pred = pipeline.predict(X_test)
# 打印分类报告
print(classification_report(y_test, y_pred))
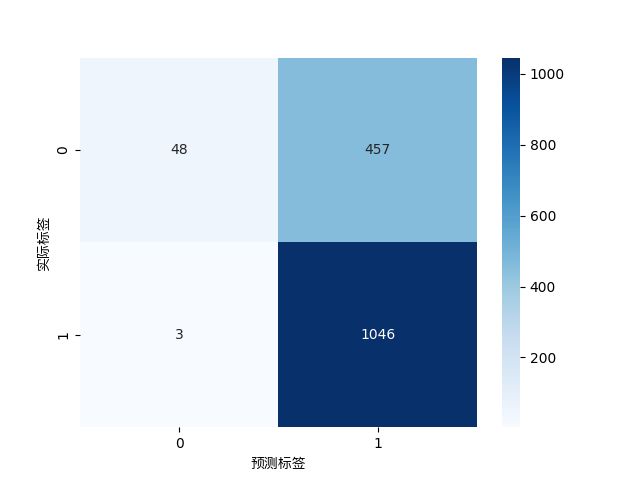
**优化前结果**
# 绘制混淆矩阵
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, cmap='Blues', fmt='g')
plt.xlabel('预测标签')
plt.ylabel('实际标签')
plt.show()
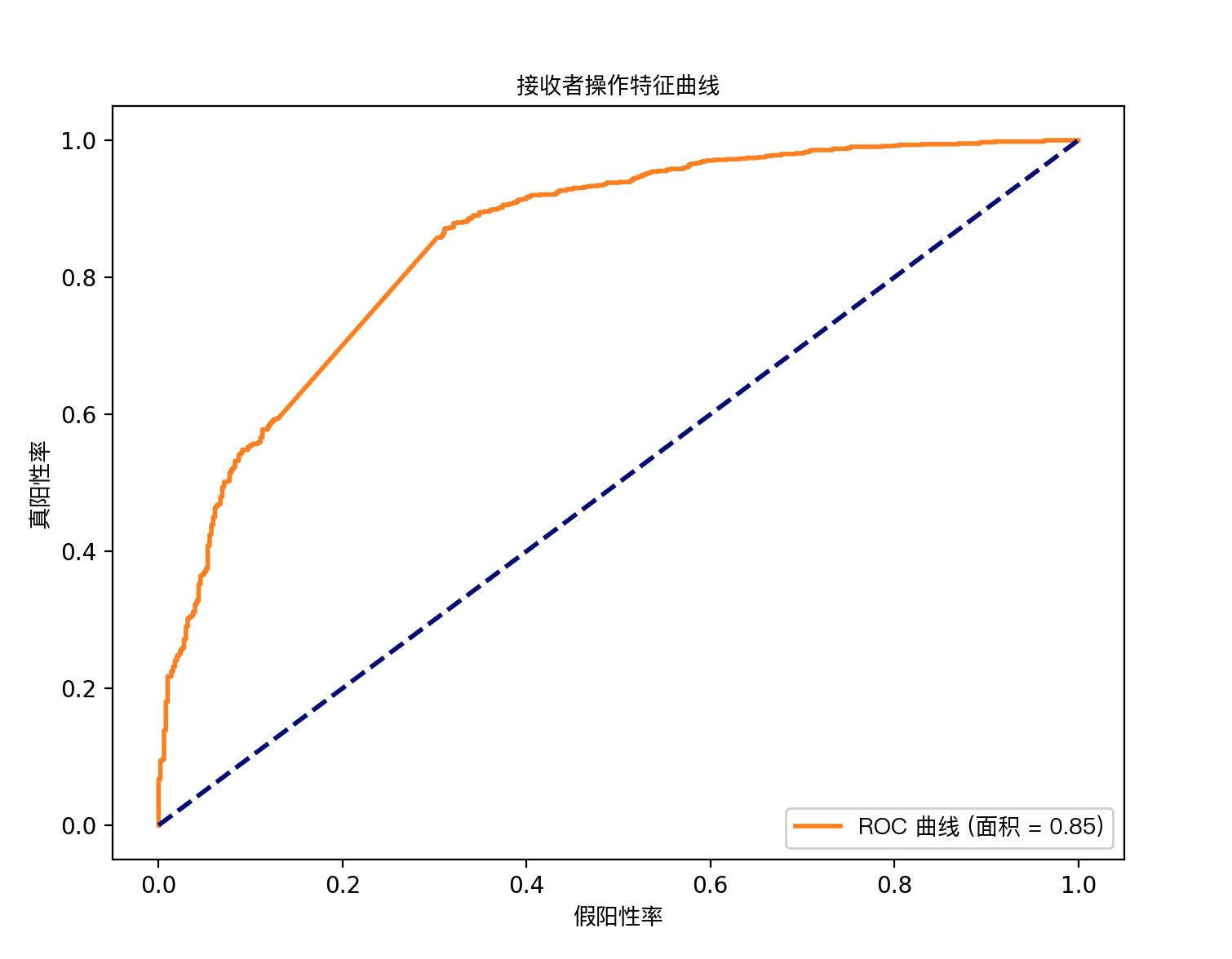
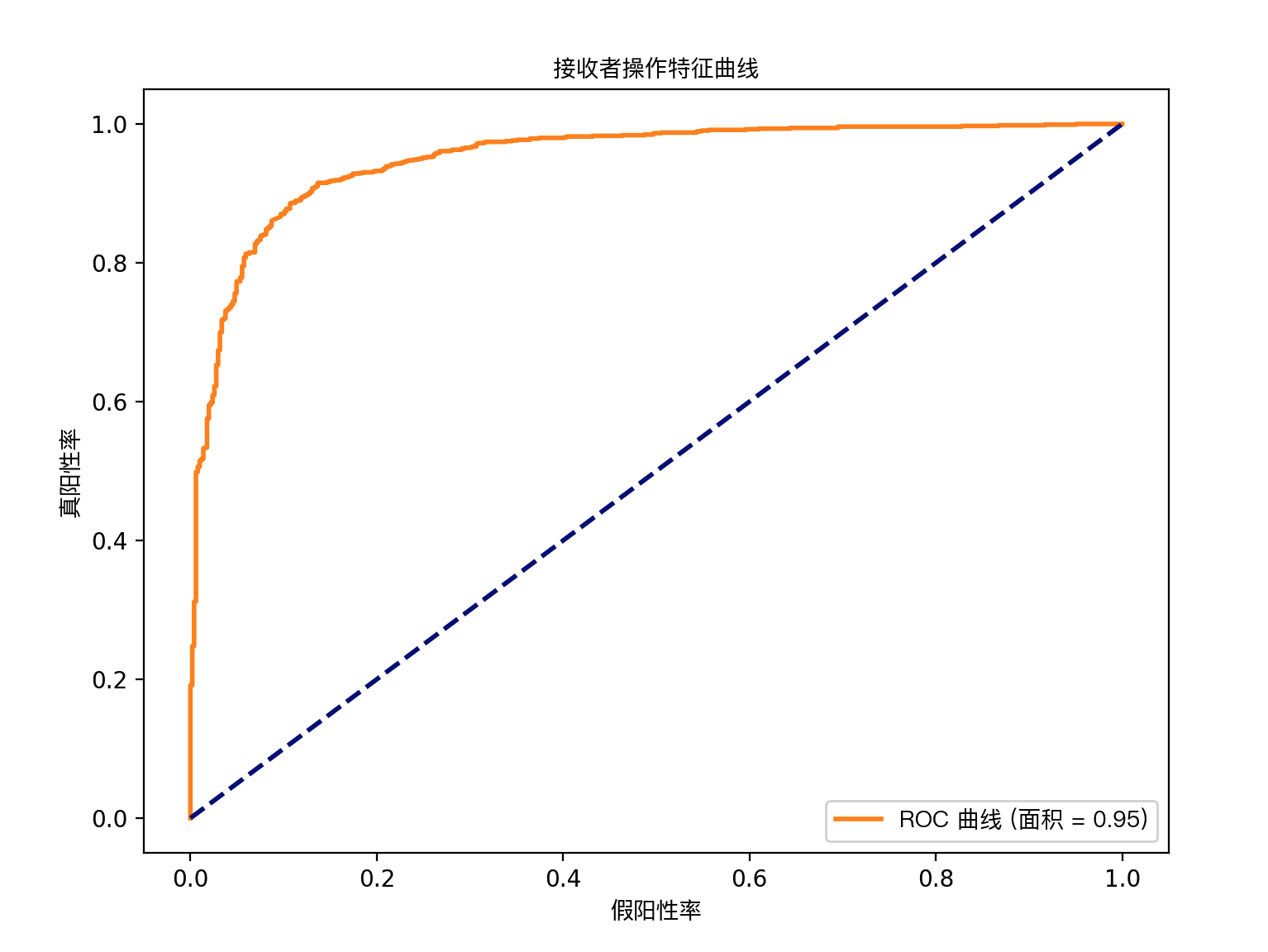
# 计算 ROC 曲线和 AUC 分数
fpr, tpr, _ = roc_curve(y_test, pipeline.predict_proba(X_test)[:, 1])
roc_auc = auc(fpr, tpr)
# 绘制 ROC 曲线
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC 曲线 (面积 = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('假阳性率')
plt.ylabel('真阳性率')
plt.title('接收者操作特征曲线')
plt.legend(loc='lower right')
plt.show()
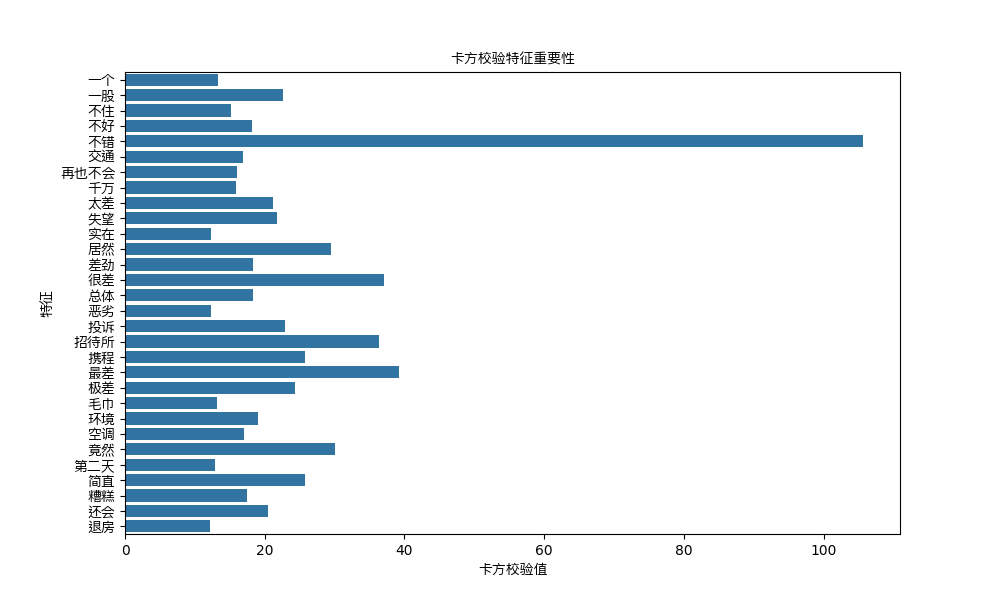
卡方校验特征选择
# 使用卡方校验选择特征
kbest_instance = pipeline.named_steps['kbest']
# 获取选定的特征
selected_features = kbest_instance.get_support(indices=True)
# 获取特征分数
feature_scores = kbest_instance.scores_
# 获取选定的特征的名字
selected_feature_names = np.array(tfidf_vectorizer.get_feature_names_out())[selected_features]
# 获取选定特征的分数
selected_feature_scores = feature_scores[selected_features]
# 绘制条形图
plt.figure(figsize=(10, 6))
sns.barplot(x=selected_feature_scores, y=selected_feature_names)
plt.xlabel('卡方校验值')
plt.ylabel('特征')
plt.title('卡方校验特征重要性')
plt.yticks()
plt.show()
模型调优
基于贝叶斯优化
# 定义搜索空间
space = {
'tfidf__min_df': scope.int(hp.quniform('tfidf__min_df', 1, 10, 1)),
'tfidf__max_df': hp.uniform('tfidf__max_df', 0.5, 1.0),
'tfidf__max_features': scope.int(hp.quniform('tfidf__max_features', 1000, 3000, 50)),
'tfidf__ngram_range': hp.choice('tfidf__ngram_range', [(1, 1), (1, 2)]),
'clf__alpha': hp.uniform('clf__alpha', 0.01, 1),
'kbest__k': scope.int(hp.quniform('kbest__k', 10, 1000, 10))
}
# 定义目标函数
def objective(params):
pipeline.set_params(**params)
score = -np.mean(cross_val_score(pipeline, data['text'], data['label'], cv=5))
return score
# 进行贝叶斯优化
trials = Trials()
best = fmin(fn=objective, space=space, algo=tpe.suggest, max_evals=100, trials=trials)
# 打印最佳参数
print('最佳参数:', best)
优化参数及分类报告

优化后混淆矩阵
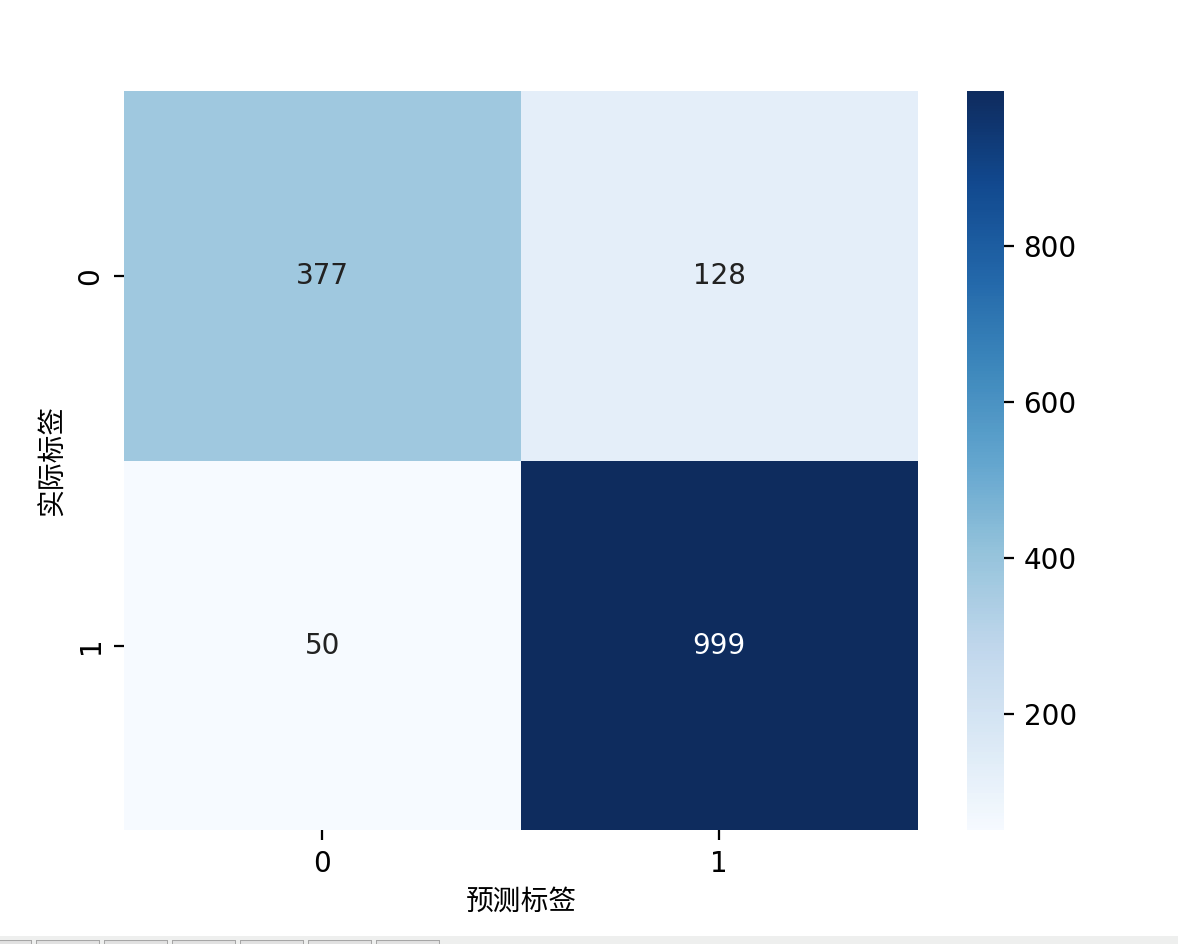
优化后ROC曲线
关注公众号每日思行发送:NBC代码 获取完整版源码


















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









