







Flink checkpoint操作流程详解与报错调试方法汇总,增量checkpoint原理及版本更新变化,作业恢复和扩缩容原理与优化
本文主要参考官方社区给出的checkpoint出错类型和种类,以及查找报错的方法。
flink checkpint出错类型
主要分为两种
Checkpoint Decline 与 Checkpint Expire 两种类型 下面分开讨论
从业务上来讲,Checkpoint 失败可能有较多的影响。
-
Flink 恢复时间长,会导致服务可用率降低。
-
非幂等或非事务场景,导致大量业务数据重复。
-
Flink 任务如果持续反压严重,可能会进入死循环,永远追不上 lag。因为反压严重会导致 Flink Checkpoint 失败,Job 不能无限容忍 Checkpoint 失败,所以 Checkpoint 连续失败会导致 Job 失败。Job 失败后任务又会从很久之前的 Checkpoint 恢复开始追 lag,追 lag 时反压又很严重,Checkpoint 又会失败。从而进入死循环,任务永远追不上 Lag。
-
在一些大流量场景中,SSD 成本很高,所以 Kafka 只会保留最近三小时的数据。如果 Checkpoint 持续三小时内失败,任务一旦重启,数据将无法恢复。
flink 重启策略
- 固定延迟(失败重试次数)重启策略(Fixed Delay Restart Strategy)
- 故障率重启策略(Failure Rate Restart Strategy)
- 没有重启策略(No Restart Strategy)
- Fallback 重启策略(Fallback Restart Strategy):使用群集定义的重新启动策略。这对于启用检查点的流式传输程序很有帮助。
- 默认情况下,如果没有定义其他重启策略,则选择固定延迟重启策略。
Checkpint 流程简介
- 第一步,Checkpoint Coordinator 向所有 source 节点 trigger Checkpoint;。
- 第二步,source 节点向下游广播 barrier,这个 barrier 就是实现 Chandy-Lamport 分布式快照算法的核心,下游的 task 只有收到所有 input 的 barrier 才会执行相应的 Checkpoint。
- 第三步,当 task 完成 state 备份后,会将备份数据的地址(state handle)通知给 Checkpoint coordinator。
- 第四步,下游的 sink 节点收集齐上游两个 input 的 barrier 之后,会执行本地快照,这里特地展示了 RocksDB incremental Checkpoint 的流程,首先 RocksDB 会全量刷数据到磁盘上,然后 Flink 框架会从中选择没有上传的文件进行持久化备份。
- 同样的,sink 节点在完成自己的 Checkpoint 之后,会将 state handle 返回通知 Coordinator。
- task收到上游全部的barrier后,会把barrier向下继续传递,并异步将自己的状态写如到持久化存储中,完成后给jm中的 Checkpoint coordinator 通知已经完成,并将备份数据的地址(state handle)也给过去。Checkpoint coordinator收集全后,会将Checkpoint Meta写入到持久化存储中,完。
总结一下 checkpoint分为一下几个操作:
-
JM trigger checkpoint
-
Source 收到 trigger checkpoint 的 PRC,自己开始做 snapshot,并往下游发送 barrier
-
下游task接收 barrier(需要 barrier 都到齐才会开始做 checkpoint)
-
Task 开始同步阶段 snapshot
1 task处理数据,对齐barrier,取最大的barrier 发送到下游task
2 发起备份,以及,增量checkpoint 将内存数据刷到磁盘的操作
3 调用 Task 的 SnapshotState 方法。
4 State backend 同步快照。 -
Task 开始异步阶段 snapshot
具体操作备份 将数据写入hdfs 数据包括
1 同步阶段引用的算子内部的 State。
2 同步阶段引用的所有 input 和 output Buffe -
Task snapshot 完成,汇报给 JM
以上任何一个操作失败都会导致checkpoint失败
增量Checkpoint实现原理
目前三种状态管理器

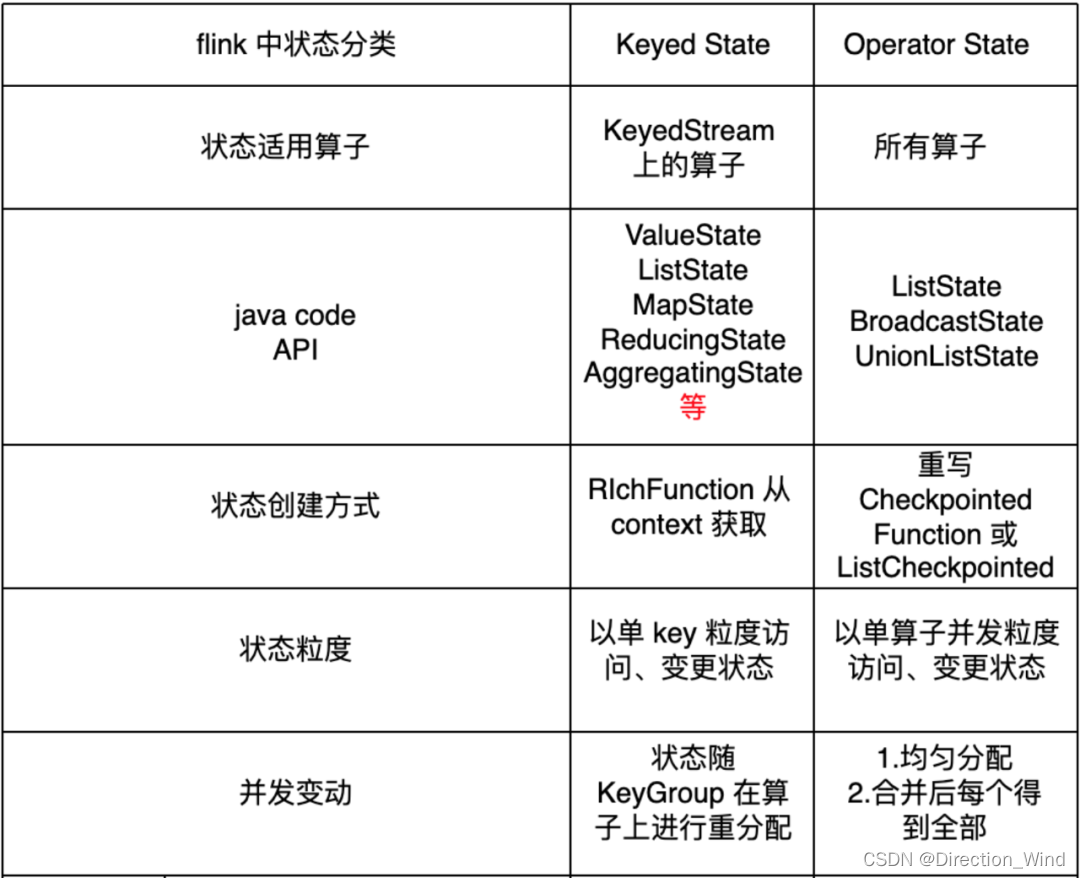
MemoryStateBackend 原理
运行时所需的 State 数据全部保存在 TaskManager JVM 堆上内存中,执行 Checkpoint 的时候,会把 State 的快照数据保存到 JobManager 进程 的内存中。执行 Savepoint 时,可以把 State 存储到文件系统中。
-
1 基于内存的状态管理器,聚合类算子的状态会存储在JobManager的内存中
-
2 单次状态大小默认最大被限制为5MB,可以通过构造函数来指定状态初始化内存大小。无论单次状态大小最大被限制为多少,都不可大于akka的frame大小(1.5MB,JobManager和TaskManager之间传输数据的最大消息容量)。状态的总大小不能超过 JobManager 的内存。
-
3 是Flink默认的后端状态管理器,默认是异步的
-
4 主机内存中的数据可能会丢失,任务可能无法恢复
-
5 将工作state保存在TaskManager的内存中,并将checkpoint数据存储在JobManager的内存中
-
适用:本地开发和调试 状态比较少的作业
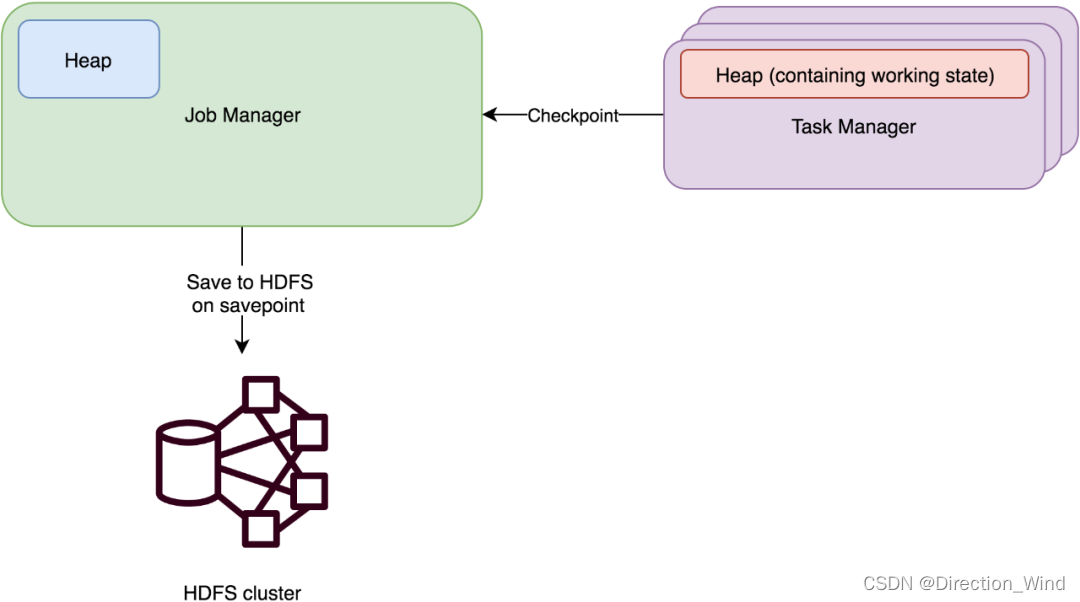
FsStateBackend原理
运行时所需的 State 数据全部保存在 TaskManager 的内存中,执行 Checkpoint 的时候,会把 State 的快照数据保存到配置的文件系统中。TM 是异步将 State 数据写入外部存储。
- 1 基于文件系统的状态管理器
- 2 如果使用,默认是异步
- 3 比较稳定,3个副本,比较安全。不会出现任务无法恢复等问题
- 4 状态大小受磁盘容量限制
- 5 将工作state保存在TaskManager的内存中,并将checkpoint数据存储在文件系统中
- 适用:状态比较大,窗口比较长,大的KV状态
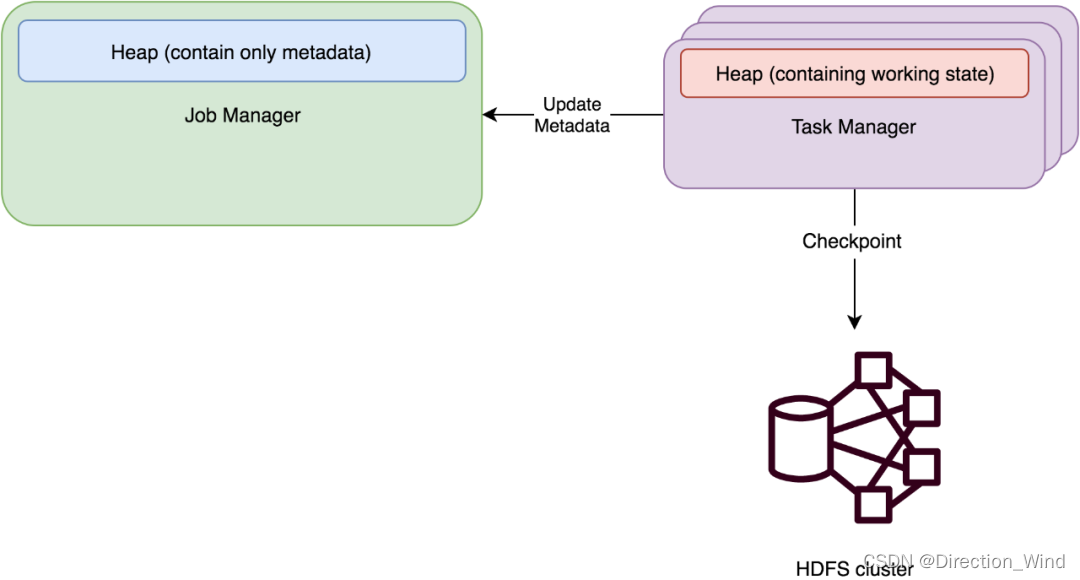
RocksDBStateBackend 原理
使用嵌入式的本地数据库 RocksDB 将流计算数据状态存储在本地磁盘中。在执行 Checkpoint 的时候,会将整个 RocksDB 中保存的 State 数据全量或者增量持久化到配置的文件系统中。
- 1 状态数据先写入RocksDB,然后异步的将状态数据写入文件系统。
- 2 正在进行计算的热数据存储在RocksDB,长时间才更新的数据写入磁盘中(文件系统)存储,体量比较小的元数据状态写入JobManager内存中(将工作state保存在RocksDB中,并且默认将checkpoint数据存在文件系统中)
- 3 支持的单 key 和单 value 的大小最大为每个 2^31 字节(2GB)
- 4 RocksDBStateBackend是目前唯一支持incremental的checkpoints的策略
- 5 默认使用是异步
RocksDBStateBackend增量更新
原理详解
目前只有RocksDBStateBackend支持checkpoint增量更新,
Flink 的增量 checkpoint 以 RocksDB 的 checkpoint 为基础。RocksDB 是一个 LSM 结构的 KV 数据库,把所有的修改保存在内存的可变缓存中(称为 memtable),所有对 memtable 中 key 的修改,会覆盖之前的 value,当前 memtable 满了之后,RocksDB 会将所有数据以有序的写到磁盘。当 RocksDB 将 memtable 写到磁盘后,整个文件就不再可变,称为有序字符串表(sstable)。
这种数据的更新方法再hologres里被称为 WAL+memtable 的数据刷新方式,主要是为了保证数据一致性,预写日志+memtable 实现方式几乎相同。
RocksDB 的后台压缩线程会将 sstable 进行合并,就重复的键进行合并,合并后的 sstable 包含所有的键值对,RocksDB 会删除合并前的 sstable。
在这个基础上,Flink 会记录上次 checkpoint 之后所有新生成和删除的 sstable,另外因为 sstable 是不可变的,Flink 用 sstable 来记录状态的变化。为此,Flink 调用 RocksDB 的 flush,强制将 memtable 的数据全部写到 sstable,并硬链到一个临时目录中。这个步骤是在同步阶段完成,其他剩下的部分都在异步阶段完成,不会阻塞正常的数据处理。
Flink 将所有新生成的 sstable 备份到持久化存储(比如 HDFS,S3),并在新的 checkpoint 中引用。Flink 并不备份前一个 checkpoint 中已经存在的 sstable,而是引用他们。Flink 还能够保证所有的 checkpoint 都不会引用已经删除的文件,因为 RocksDB 中文件删除是由压缩完成的,压缩后会将原来的内容合并写成一个新的 sstable。因此,Flink 增量 checkpoint 能够切断 checkpoint 历史。
为了追踪 checkpoint 间的差距,备份合并后的 sstable 是一个相对冗余的操作。但是 Flink 会增量的处理,增加的开销通常很小,并且可以保持一个更短的 checkpoint 历史,恢复时从更少的 checkpoint 进行读取文件。
举例

上图以一个有状态的算子为例,checkpoint 最多保留 2 个,上图从左到右分别记录每次 checkpoint 时本地的 RocksDB 状态文件,引用的持久化存储上的文件,以及当前 checkpoint 完成后文件的引用计数情况。
-
Checkpoint 1 的时候,本地 RocksDB 包含两个 sstable 文件,该 checkpoint 会把这两个文件备份到持久化存储,当 checkpoint 完成后,对这两个文件的引用计数进行加 1,引用计数使用键值对的方式保存,其中键由算子的当前并发以及文件名所组成。我们同时会维护一个引用计数中键到对应文件的隐射关系。
-
Checkpoint 2 的时候,RocksDB 生成两个新的 sstable 文件,并且两个旧的文件还存在。Flink 会把两个新的文件进行备份,然后引用两个旧的文件,当 checkpoint 完成时,Flink 对这 4 个文件都进行引用计数 +1 操作。
-
Checkpoint 3 的时候,RocksDB 将 sstable-(1),sstable-(2) 以及 sstable-(3) 合并成 sstable-(1,2,3),并且删除了三个旧文件,新生成的文件包含了三个删除文件的所有键值对。sstable-(4) 还继续存在,生成一个新的 sstable-(5) 文件。Flink 会将 sstable-(1,2,3) 和 sstable-(5) 备份到持久化存储,然后增加 sstable-4 的引用计数。由于保存的 checkpoint 数达到上限(2 个),因此会删除 checkpoint 1,然后对 checkpoint 1 中引用的所有文件(sstable-(1) 和 sstable-(2))的引用计数进行 -1 操作。
-
Checkpoint 4 的时候,RocksDB 将 sstable-(4),sstable-(5) 以及新生成的 sstable-(6) 合并成一个新的 sstable-(4,5,6)。Flink 将 sstable-(4,5,6) 备份到持久化存储,并对 sstabe-(1,2,3) 和 sstable-(4,5,6) 进行引用计数 +1 操作,然后删除 checkpoint 2,并对 checkpoint 引用的文件进行引用计数 -1 操作。这个时候 sstable-(1),sstable-(2) 以及 sstable-(3) 的引用计数变为 0,Flink 会从持久化存储删除这三个文件。
Checkpoint 异常情况排查
check失败可以使用flink自带的工具进行查看
| 工具 | 用途 | 使用方式 |
|---|---|---|
| read Dump | 查看当前时刻的 Operator 线程是否主要在访问 State | 在 Thread Dump 页面,按 Operator 名字搜索,观察线程栈是否在访问 State (线程栈持续在 Gemini 或 RocksDB 的访问链路上),操作示例见 “Thread Dump 使用方式” |
| 线程动态 | 抽样查看一段时间内的线程动态是否主要在访问 State | 在线程动态页面,按 Operator 名字搜索,采样一段时间,并观察线程栈是否在访问 State (线程栈持续在 Gemini 或 RocksDB 的访问链路上),操作示例见 “线程动态使用方式” |
| CPU 火焰图 | 查看一段时间内的 CPU 时间占比大头是否在访问 State | 在 CPU 火焰图页面,采样一段时间,并观察最长几条 CPU 链路上,方法是否在访问 State (方法在 Gemini 或 RocksDB 的访问链路上),操作示例见 “火焰图使用方式” |
| 查看运行监控指标 | 通过查看 State Size 相关指标判断 状态大小和 IO 情况 | 在指标页面,重点观察以下指标:State Size (Gemini Only): 运行时单并发的状态大小;lastCheckpointFullSize: 最近一个 Checkpoint 的全量大小,可以用来大致估算整体作业的状态大小;State Access Latency (需要额外开启):当单个 State 访问达到毫秒级,需要重点关注下状态访问的性能操作示例见 “指标使用方式”。 |
(1)Thread Dump 使用方式
■ 点击瓶颈算子进入TaskManager 性能查看页面,同时记录在 Detail 页面中的算子名
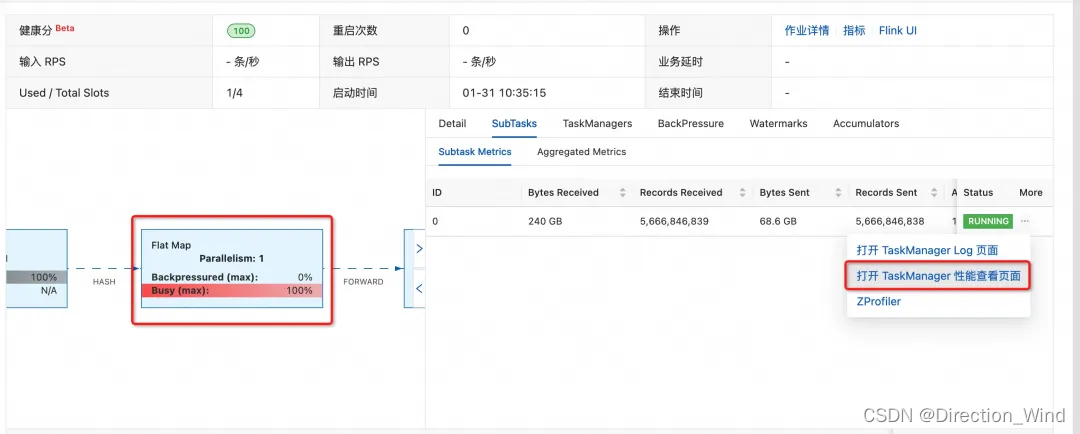
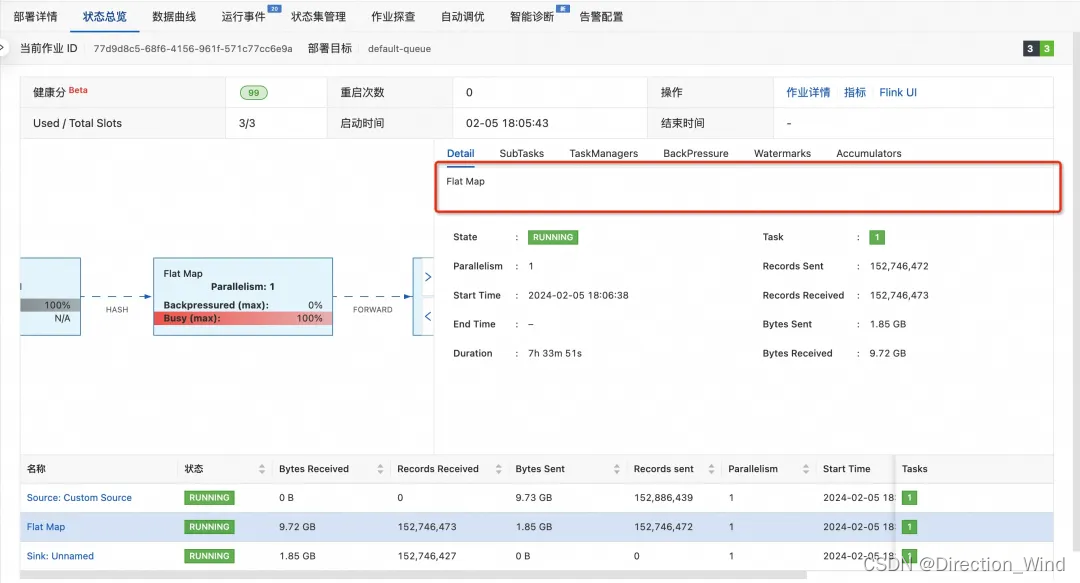
■ 进入 Thread Dump 页面 并按 1 中的瓶颈算子名搜索其线程栈,如下即是 Gemini State 访问的线程栈
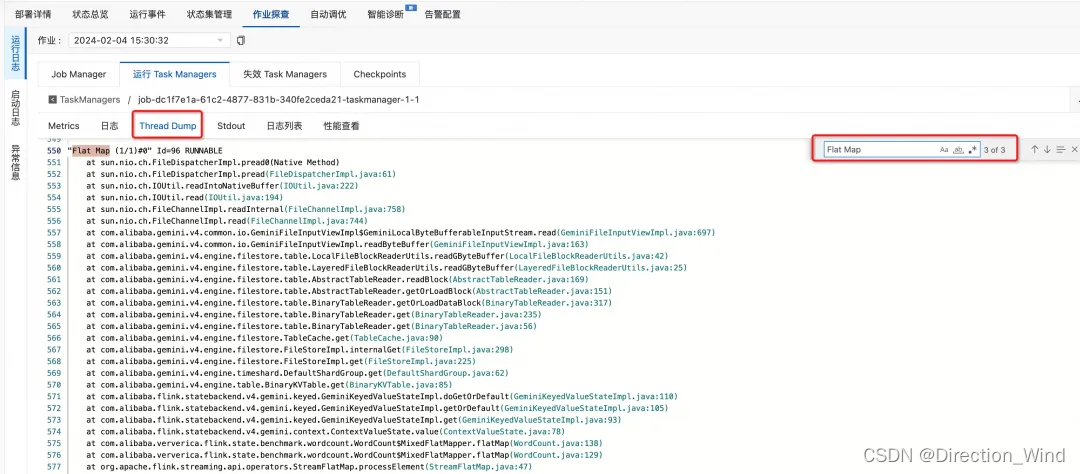
(2)线程动态使用方式
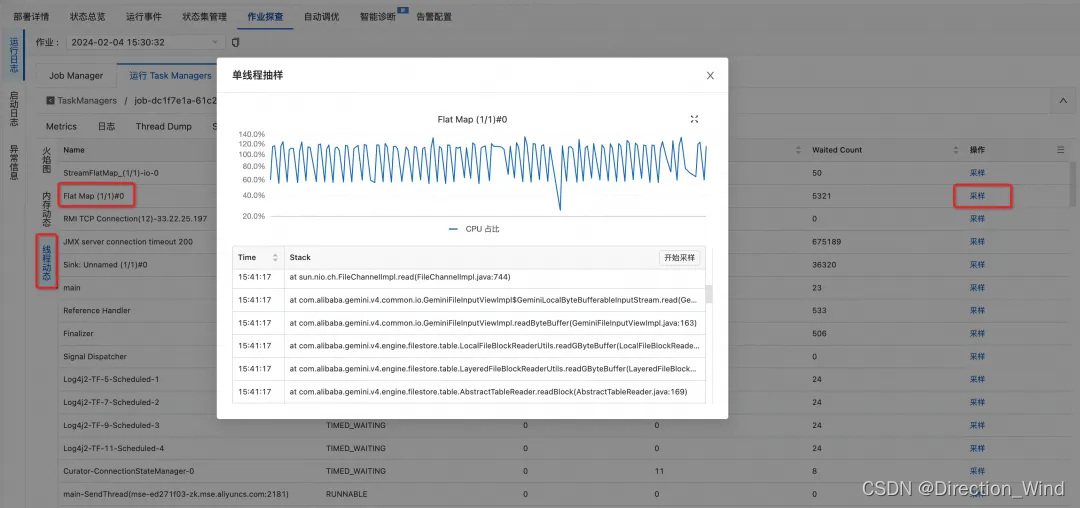
■ 类似上一节,点击瓶颈算子进入TaskManager 性能查看页面,同时记录在 Detail 页面中的算子名
■ 进入线程动态页面并按 1 中的瓶颈算子名搜索其线程栈并采样一段时间,观察其线程栈,如下即可观察到 Gemini State 访问的线程栈
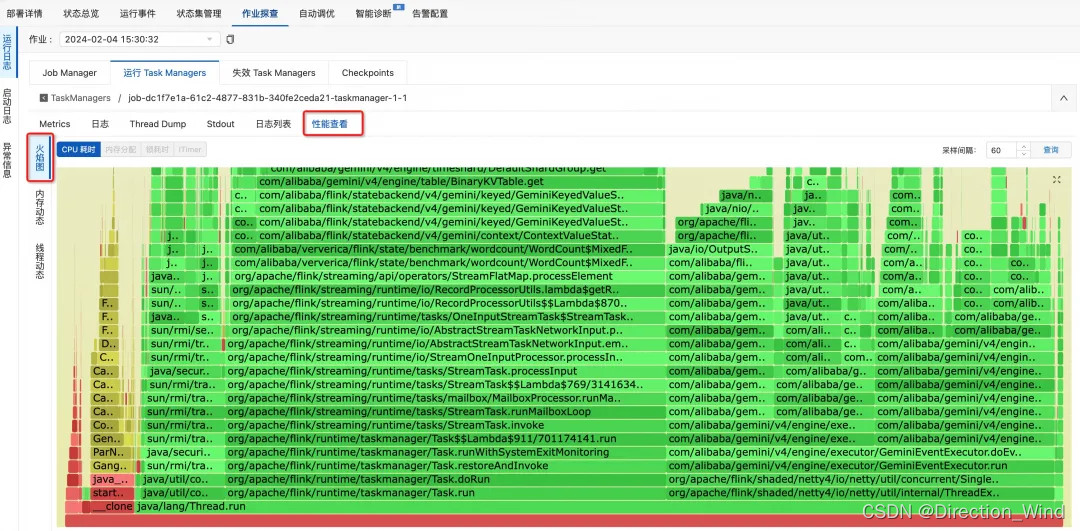
(3)火焰图使用方式
■ 类似上一节,点击瓶颈算子进入TaskManager 性能查看页面,同时记录在 Detail 页面中的算子名
■ 进入火焰图页面并观察占据 CPU 时间最长的方法,如下可以观察到有较多 Gemini State 访问的方法
(4) 指标使用方式
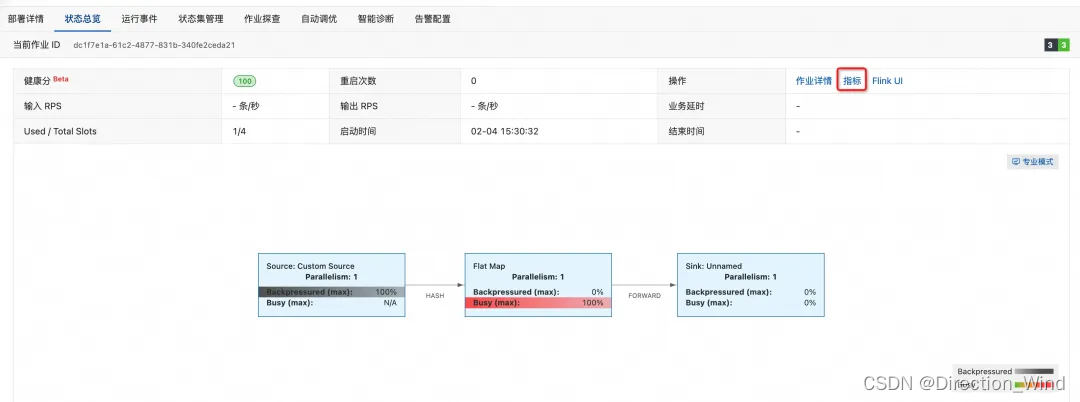
■可以在 State 和 Checkpoint 两部分观察上述的一些指标


以上几个参数分别是:
- 一列表示有多少个 subtask 对这个 Checkpoint 进行了 ack
- 表示该 operator 的所有 subtask 最后 ack 的时间
- 表 示 整 个 operator 的 所 有 subtask 中 完 成 snapshot 的最长时间
- 表示当前 Checkpoint 的 state 大小,增量就是增量的大小
从上图可以知道第4个task操作导致整体的checkpoint非常慢,可以根据UI给出物理执行图来有根据的检查任务,但是大部分情况当发现checkpoint报错时,任务已经down掉,那么就需要根据yarn上的日志来具体分析
Checkpoint Decline:
从jm的日志中可以看到
Decline checkpoint 10000 by task ********* container_e119_1640332468237_165586_01_000002 @ hostname01 with allocation id 2872ccdf76d6af3baf9064be9d46fcaa
可以去 container_e119_1640332468237_165586_01_000002 所在的 tm 也就是hostname01 ,可以查看具体的tm日志查看具体的报错信息
Checkpoint Decline 中有一种情况 Checkpoint Cancel,这是由于 较小的 barrier还没有对齐,就已经收到了更大的 barrier,这种情况下就会把小的 checkpoint给取消的掉
在jm.log中会有 当前chk-11还在对齐阶段,但收到了 chk-12的barrier ,所以取消了 chk-11
Received checkpoint barrier for checkpoint ****** before completing current checkpoint ** Skipping current checkpoint
下游task收到被取消的barrier时会打印
$taskNameWithSubTaskAndID: Checkpoint chk-11 canceled, aborting alignment.
或
$taskNameWithSubTaskAndID: Received cancellation barrier for checkpoint chk-12 before completing current checkpoint chk-11. Skipping current checkpoint
Checkpoint Expire:
上面的Decline 比较少见,更常见的是 Expire 的情况。其中最主要的原因就是因为 checkpoint 做的非常慢,导致超时等各种情况。
出现expire时,jm.log中会有
Checkpoint 157 of job ba02728367ae85bca4d43ab7445251f5 expired before completing.
以及
Received late message for now expired checkpoint attempt 158 from task d11aac4d0b6f4fd9bde0fa4e76240c71 of job ba02728367ae85bca4d43ab7445251f5 at container_e119_1640332468237_165586_01_000002 @ cp-hadoop-hdp-node07 (dataPort=11460).
其中tm具体日志可以参考上述的办法来找到对应的报错日志。
chk很慢的情况主要有一下几种:
Source Trigger 慢
这个一般发生较少,但是也有可能,因为 source 做 snapshot 并往下游发送 barrier 的时候,需要抢锁(这个现在社区正在进行用 mailBox 的方式替代当前抢锁的方式,详情参考[1])。如果一直抢不到锁的话,则可能导致 Checkpoint 一直得不到机会进行。如果在 Source 所在的 taskmanager.log 中找不到开始做 Checkpoint 的 log,则可以考虑是否属于这种情况,可以通过 jstack 进行进一步确认锁的持有情况
State 非常大
这种情况使用增量checkpoint,现在增量checkpoint只支持RocksDBStateBackend 并需要设置开启
数据倾斜或有反压的情况
数据倾斜可以重新设计主键以及数据处理流程来改善,反压可以参考flink UI来查看哪里反压 ,并使用Metrics 来获取关键指标
反压问题处理:
定位节点,加Metrics
我们在监控反压时会用到的 Metrics 主要和 Channel 接受端的 Buffer 使用率有关,最为有用的是以下几个:
Metrics: Metris描述
outPoolUsage发送端 Buffer 的使用率
inPoolUsage接收端 Buffer 的使用率
floatingBuffersUsage(1.9 以上)接收端 Floating Buffer 的使用率
exclusiveBuffersUsage (1.9 以上)接收端 Exclusive Buffer 的使用率
barrier对齐的慢
Checkpoint 在 task 端分为 barrier 对齐(收齐所有上游发送过来的 barrier),然后开始同步阶段,再做异步阶段。如果 barrier 一直对不齐的话,就不会开始做 snapshot
这种情况也会导致 State非常大,当先到的barrier到达后,晚的barrier来之前,这之间的数据也会放入到State中一起保存起来。
在Debug日志下,barrier对齐后会有
Starting checkpoint (6751) CHECKPOINT on task taskNameWithSubtasks (4/4)
如果一直没有,注意! 是Debug日志,可以使用 at least once,来观察哪个barrier没有到达,多说一嘴,at least once 与 exectly once 最主要的语义区别就是 ,先到的barrier,是否等后到的barrier对齐才做checkpoint
Received barrier for checkpoint 96508 from channel 5
线程太忙
在 task 端,所有的处理都是单线程的,数据处理和 barrier 处理都由主线程处理,如果主线程在处理太慢(比如使用 RocksDBBackend,state 操作慢导致整体处理慢),导致 barrier 处理的慢,也会影响整体 Checkpoint 的进度,可能会出现barrier一直对不齐的情况
可以用AsyncProfile生成一份火焰图,查看占用cpu最多的栈,大数据集群中,如果实时离线使用一套集群,凌晨时,离线任务集体调度,就有可能导致node节点上线程不够,无法完成checkpoint导致报错
同步阶段慢
非 RocksDBBackend 我们可以考虑查看是否开启了异步 snapshot,如果开启了异步 snapshot 还是慢,需要看整个 JVM 在干嘛,也可以使用前一节中的工具。
对于 RocksDBBackend 来说,我们可以用 iostate 查看磁盘的压力如何,另外可以查看 tm 端 RocksDB 的 log 的日志如何,查看其中 SNAPSHOT 的时间总共开销多少
异步阶段慢
这一步主要是,jm将Checkpoint Meta写入到持久化存储,
非 RocksDB-Backend ,主要是网络流量的问题,可以使用metirc来监控检查问题
RocksDB 来说,则需要从本地读取文件,写入到远程的持久化存储上,会涉及磁盘IO的瓶颈,如果感觉IO足够,网络也没问题,可以开启多线程上传的功能
flink状态调优
(1)反复确认业务逻辑,合理设计状态
在使用Flink进行状态管理时,首先需要审视业务逻辑,确保只存储必要的数据,避免产生不必要的状态信息。合理设计状态结构和存储内容是控制状态增长的关键所在。仅存储业务所需的最小化状态信息,有利于避免状态的无限增长。
设置合理状态生命周期减小状态大小
Flink 提供了丰富的状态时间特性,如 ValueStateDescriptor 的 setTTL 方法,可以设置状态的生命周期,确保状态在一定时间后自动过期并被清除。同时,开发者也可以直接调用 clear() 或 remove() 方法,显式删除不再需要的状态条目。合理利用这些特性,可以有效控制状态规模。
(2)使用定时器进行状态清理
除了依赖状态的时间特性,开发者还可以利用 Flink 的定时器机制,定期触发状态的清理操作。通过设置合理的定时器触发时间,可以确保过期状态及时被清理,避免状态无限增长。这种主动清理状态的方法,可以更精细地控制状态的生命周期。
(3)进行必要的监控与日志输出,同时定期分析状态文件
在状态管理过程中,需要持续监控状态大小和状态后端的性能指标,及时发现异常情况。同时,记录详细的日志信息,有助于在出现问题时快速定位和解决。除此之外,定期分析状态文件,也能够提供系统运行的历史数据,有助于识别作业模式和预测可能的风险点,为进一步优化状态管理提供依据。
(4)尽可能减少读盘
为了提升系统性能,我们可以通过减少磁盘读取次数并优化内存使用来实现。以下是针对不同情况的具体策略:
■优化内存分配:在保证系统总资源不受影响的前提下,我们可以重新分配内存资源,将更多的内存分配给托管内存(Managed Memory)。这样做可以有效提升内存的命中率,从而减少对磁盘的依赖。具体操作时,应确保其他内存资源充足,以免影响系统的其他部分。
■细粒度资源配置:在进行资源配置时,应优先考虑增加内存资源。通过为存储引擎分配更多的托管内存,我们可以进一步提高内存命中率,减少对磁盘的读取需求。这种方法在细粒度的资源管理中尤为重要,因为它允许我们更精确地控制资源分配,以达到最佳的性能表现。
■提高并发处理能力:通过增加并发处理的数量,我们可以降低单个并发任务的状态量,从而减少需要写入磁盘的数据量。这种方法可以有效地减少磁盘 I/O 操作,提高整体的数据处理效率。
| 使用场景 | 方案 | 实践方式 | 注意事项 |
|---|---|---|---|
| 当 Heap 等其他内存资源余量较多时 | 调整内存资源比例,提供更多内存资源给 Managed Memory | 运行参数中配置参数:taskmanager.memory.managed.fraction[6]该参数默认值是 0.4,适当增加该参数可以将更多内存资源用于实际状态数据存储 | 需要确保其他内存资源够用,否则会导致 Full GC 频繁从而性能下降 |
| 所有场景 | 增加内存 | 在资源配置或细粒度资源配置中增加内存[7] | |
| 增加并发 | 在资源配置或细粒度资源配置中增加并发[7] |
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
Unaligned Checkpoint (不对齐checkpoint 详解 )
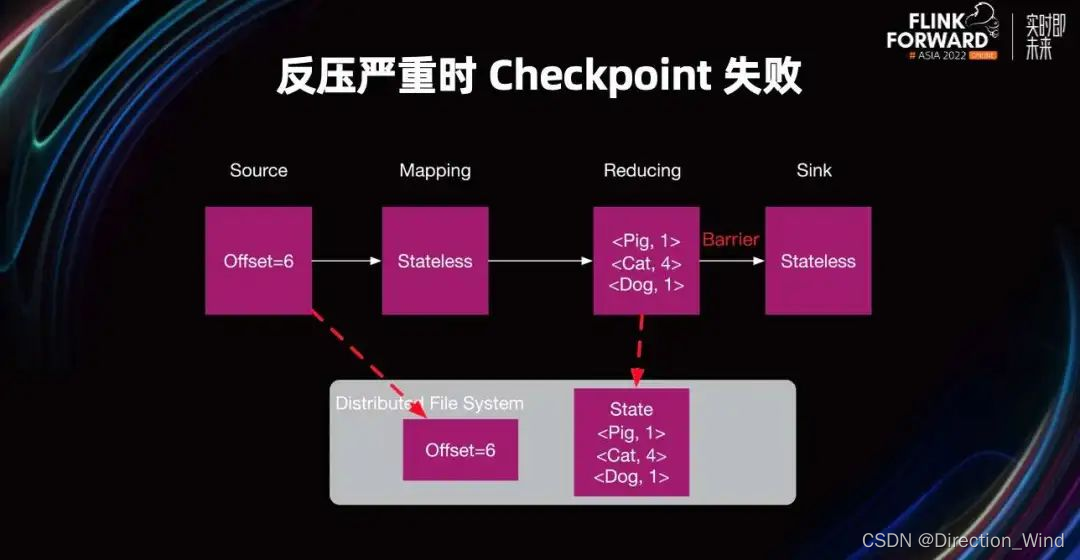
为什么 Checkpoint 会失败呢?Checkpoint Barrier 从 Source 生成,并且 Barrier 从 Source 发送到 Sink Task。当 Barrier 到达 Task 时,该 Task 开始 Checkpoint。当这个 Job 的所有 Task 完成 Checkpoint 时,这个 Job 的 Checkpoint 就完成了。
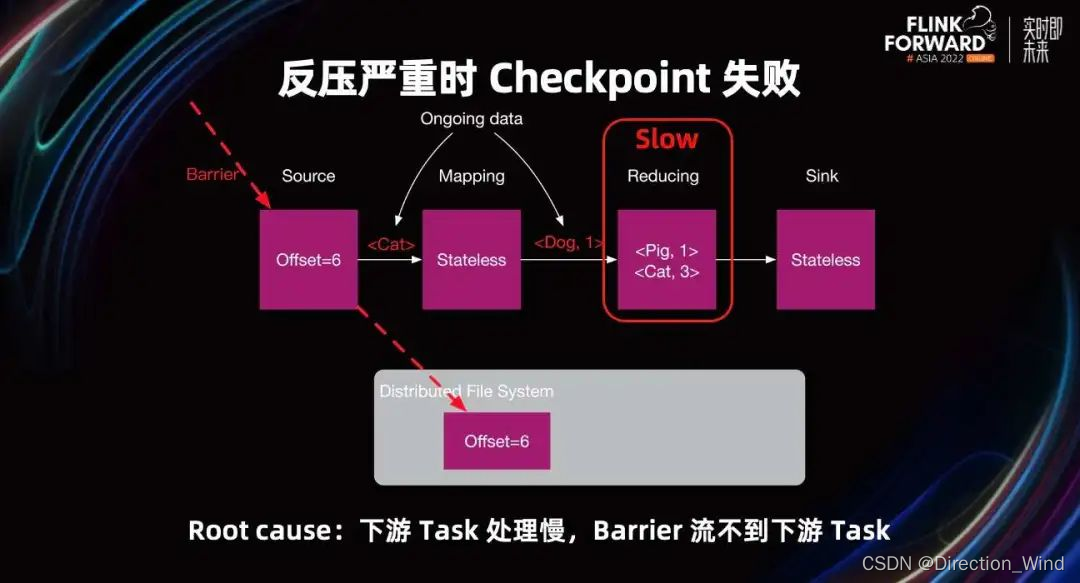
Task 必须处理完 Barrier 之前的所有数据,才能接收到 Barrier。例如 Reducing Task 处理数据慢,Task 不能快速消费完 Barrier 前的所有数据,所以不能接收到 Barrier。最终 Reducing Task 的 Checkpoint 就会失败,从而导致 Job 的 Checkpoint 失败。
Unaligned Checkpoint 核心思路:
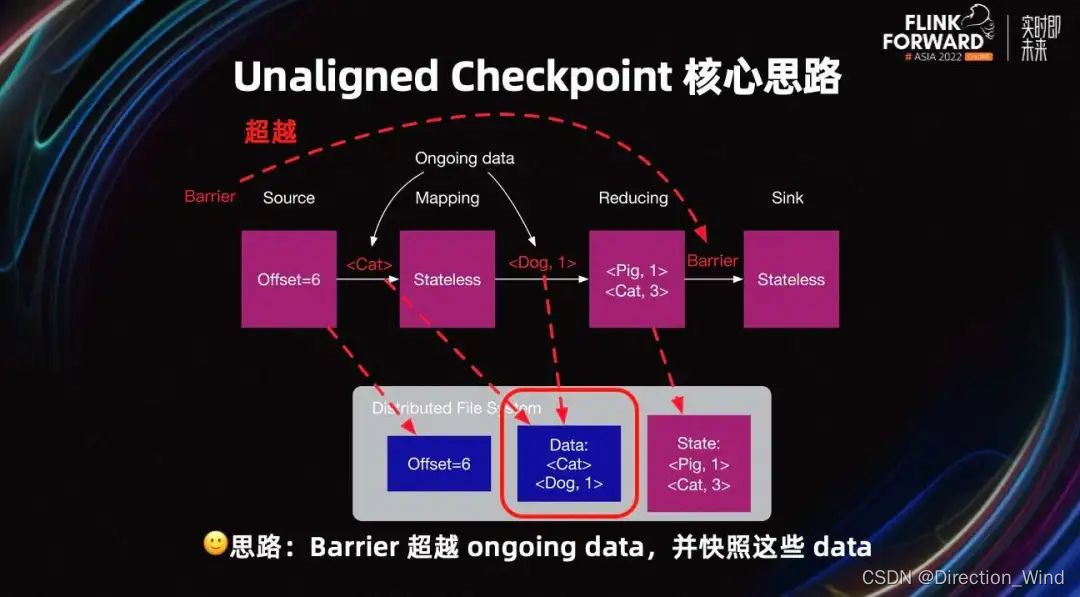
UC 的核心思路是 Barrier 超越这些 ongoing data,即 Buffer 中的数据,并快照这些数据。由此可见,当 Barrier 超越 ongoing data 后,快速到达了 Sink Task。与此同时,这些数据需要被快照,防止数据丢失。
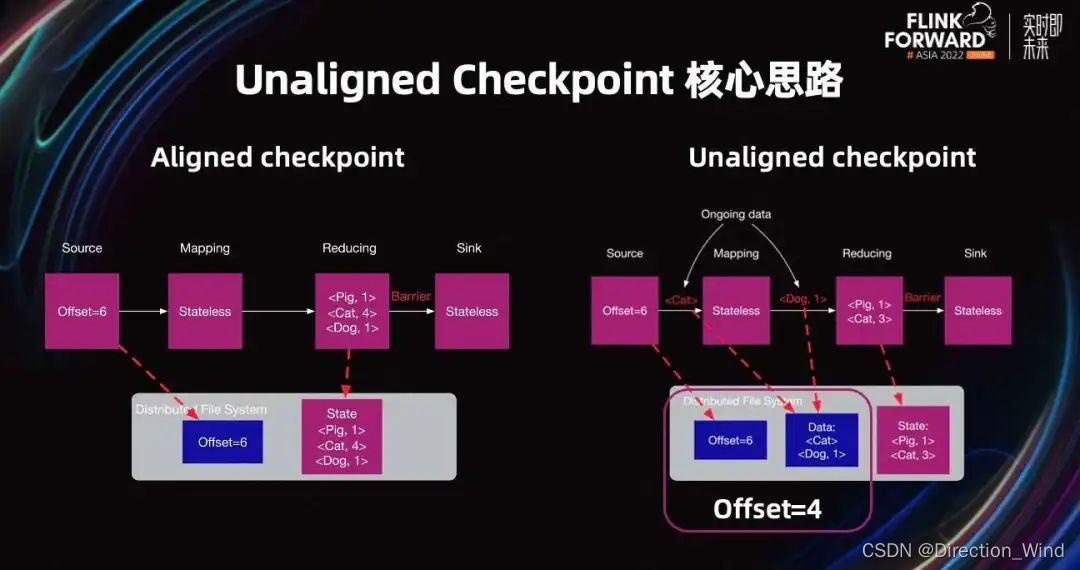
上图是 UC 和 AC 的简单对比,对于 AC,Offset 与数据库 Change log 类似。对于 UC,Offset 和 data 与数据库的 Change log 类似。Offset6 和 data 的组合,可以认为是 Offset4。其中,Offset4 和 Offset5 的数据从 State 中恢复,Offset6 以及以后的数据从 Kafka 中恢复。
Unaligned Checkpoint 的实现原理
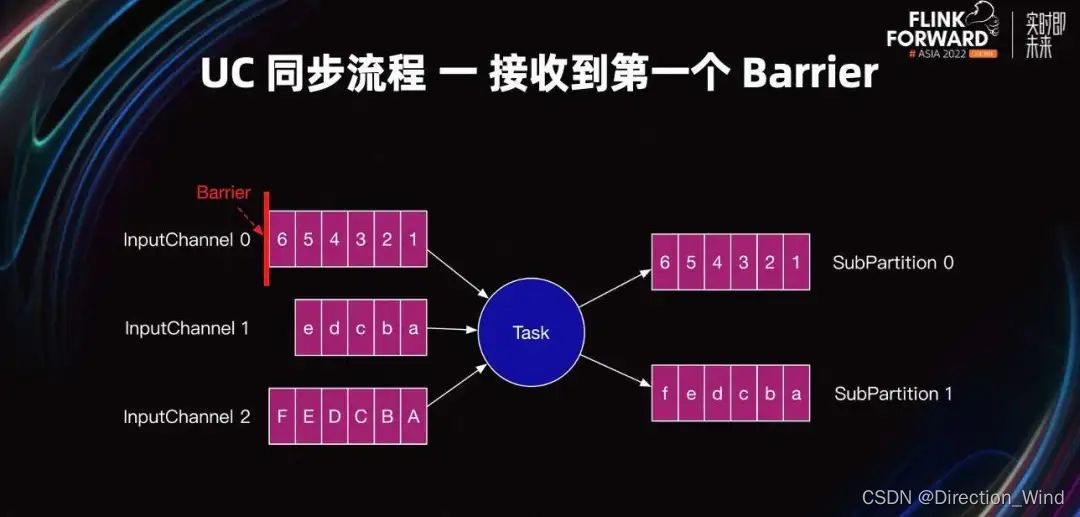
了解完 Checkpoint 存在的问题以及 UC 的核心思路后。接下来主要介绍 UC 的实现原理。
假设当前 Task 的上游 Task 并行度为 3,下游 Task 并行度为 2。如图所示,Task 会有三个 InputChannel 和两个 SubPartition。紫红色框表示 Buffer 中的一条条数据。
UC 开始后,Task 的三个 InputChannel 会陆续收到上游发送的 Barrier。如图所示,InputChannel 0 先收到了 Barrier,其他 Inputchannel 还没有收到 Barrier。当某一个 InputChannel 接收到 Barrier 时,Task 会直接开始 UC 的第一阶段,即:UC 同步阶段。
这里只要有任意一个 Barrier 进入 Task 网络层的输入缓冲区,Task 就会直接开始 UC,不用等其他 InputChannel 接收到 Barrier,也不需要处理完 InputChannel 内 Barrier 之前的数据。
AC UC 区别是 at last once 和 exactily once ?
UC 同步阶段
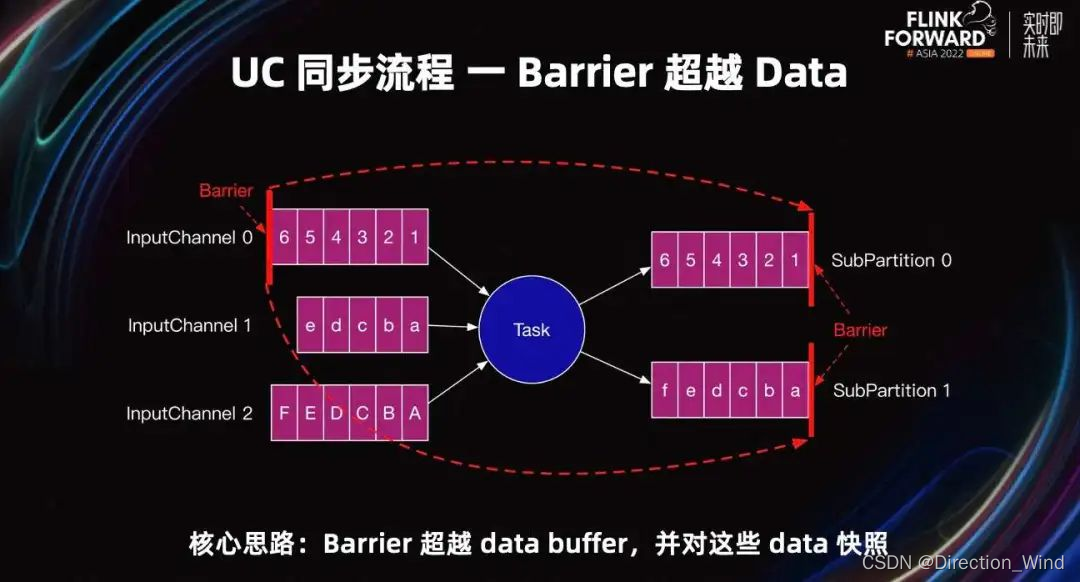
UC 同步阶段的核心思路是:Barrier 超越所有的 data Buffer,并对这些超越的 data Buffer 快照。我们可以看到 Barrier 被直接发送到所有 SubPartition 的头部,超越了所有的 input 和 output Buffer,从而 Barrier 可以被快速发送到下游 Task。这也解释了为什么反压时 UC 可以成功:
-
从 Task 视角来看,Barrier 可以在 Task 内部快速超车。
-
从 Job 视角来看,如果每个 Task 都可以快速超车,那么 Barrier 就可以从 Source Task 快速超车到 Sink Task。
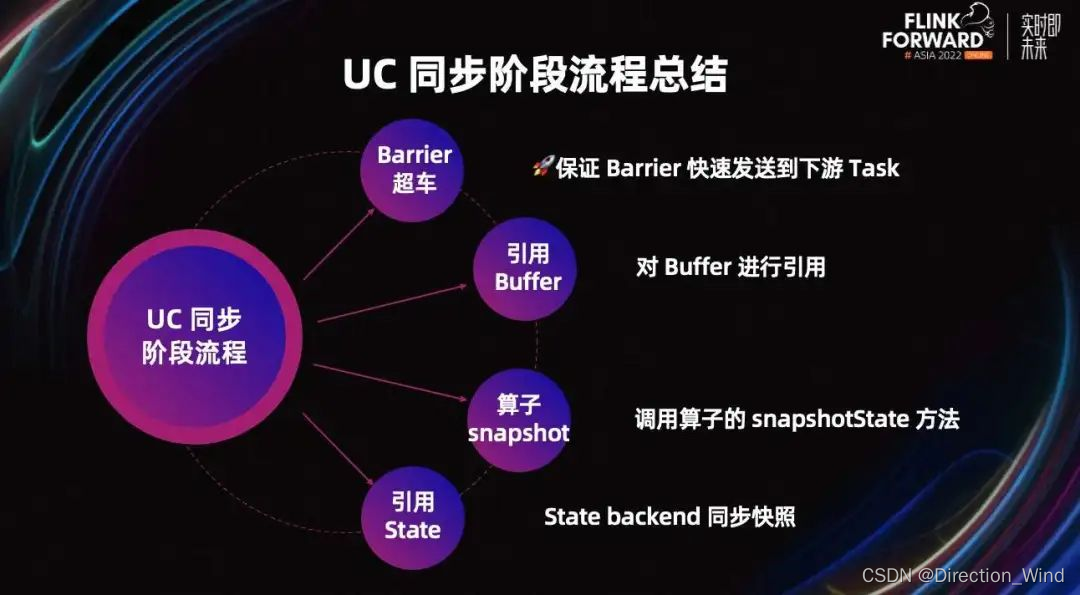
为了保证数据一致性,在 UC 同步阶段 Task 不能处理数据。同步阶段主要有上图中的流程。
-
Barrier 超车:保证 Barrier 快速发送到下游 Task。
-
对 Buffer 进行引用:这里只是引用,真正的快照会在异步阶段完成。
-
调用 Task 的 SnapshotState 方法。
-
State backend 同步快照。
UC 同步阶段的最后两步与 AC 完全一致,对算子内部的 State 进行快照。
个人总结 AC的同步阶段应该是:
1 task处理数据,对齐barrier,取最大的barrier 发送到下游task
2 发起备份,以及,增量checkpoint 将内存数据刷到磁盘的操作
3 调用 Task 的 SnapshotState 方法。
4 State backend 同步快照。
UC 异步流程
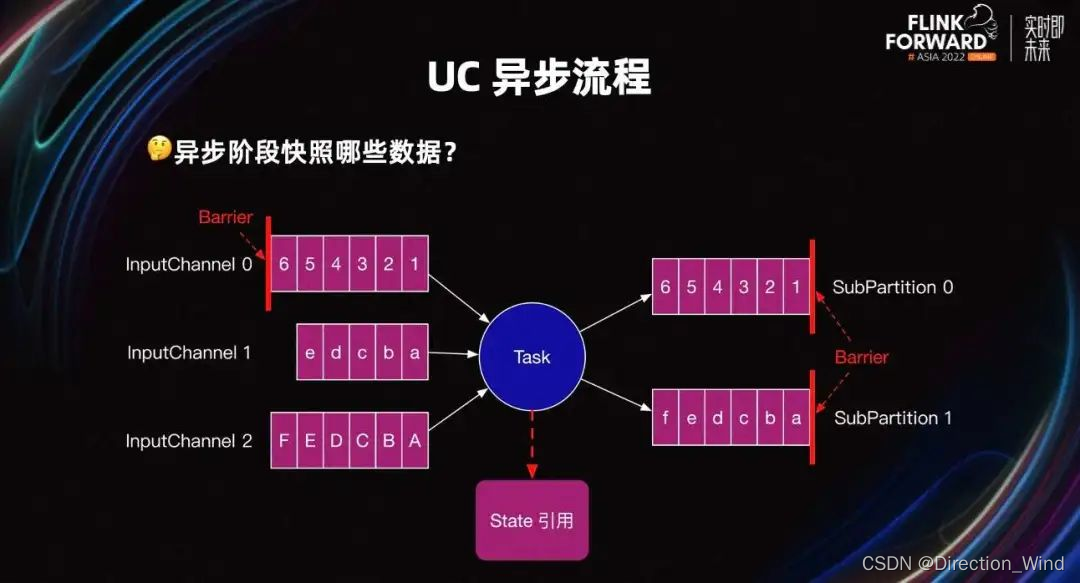
当 UC 同步阶段完成后,会继续处理数据。与此同时,开启 UC 的第二阶段:Barrier 对齐和 UC 异步阶段。
异步阶段要快照同步阶段引用的所有 input 和 output Buffer,以及同步阶段引用的算子内部的 State。
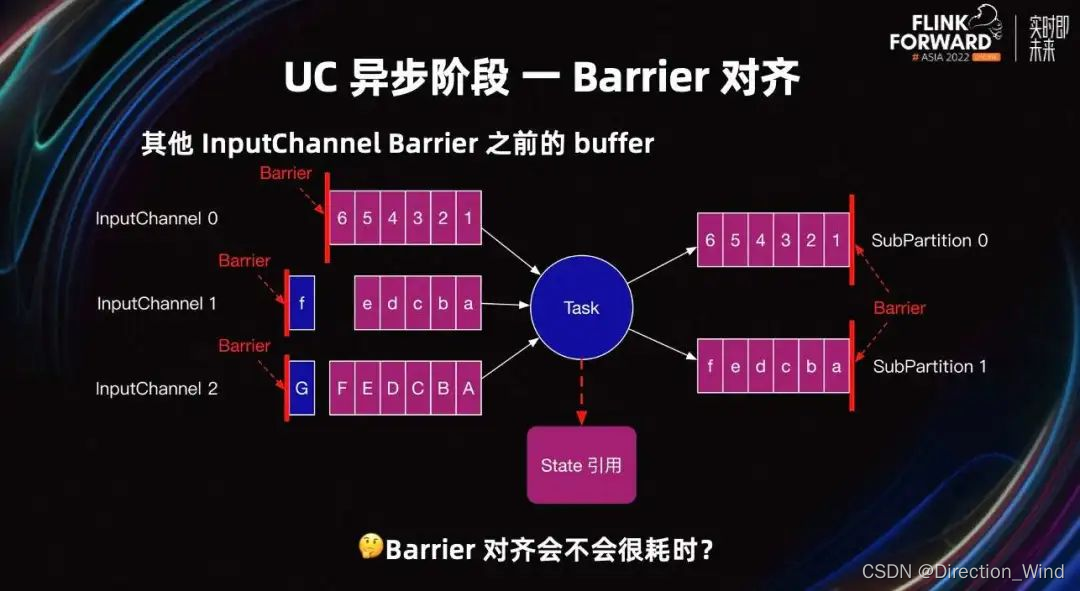
除此之外,UC 也有 Barrier 对齐。当 Task 开始 UC 时,有很多 Inputchannel 没接收到 Barrier。这些 InputChannel Barrier 之前的 Buffer,可能还有一些 Buffer 需要快照。例如上图中 InputChannel1 的 f 和 InputChannel2 的 g。
所以 UC 的第二阶段需要等所有 InputChannel 的 Barrier 到达,且 Barrier 之前的 Buffer 都需要快照,这就是所谓的 UC Barrier 对齐。(对于ac就没有这 F 和 G 的数据了,因为ac是对齐后才下发的barrier,相当于 先对其 后下发barrier)
那 UC 的 Barrier 对齐会不会很耗时呢?理论上 UC 的 Barrier 对齐会很快,像之前的 Task 一样,Barrier 可以快速超越所有的 input 和 output Buffer,优先发送 Barrier 给下游 Task。所以上游 Task 也类似,Barrier 超越上游所有的 Buffer 快速发送给当前 Task。
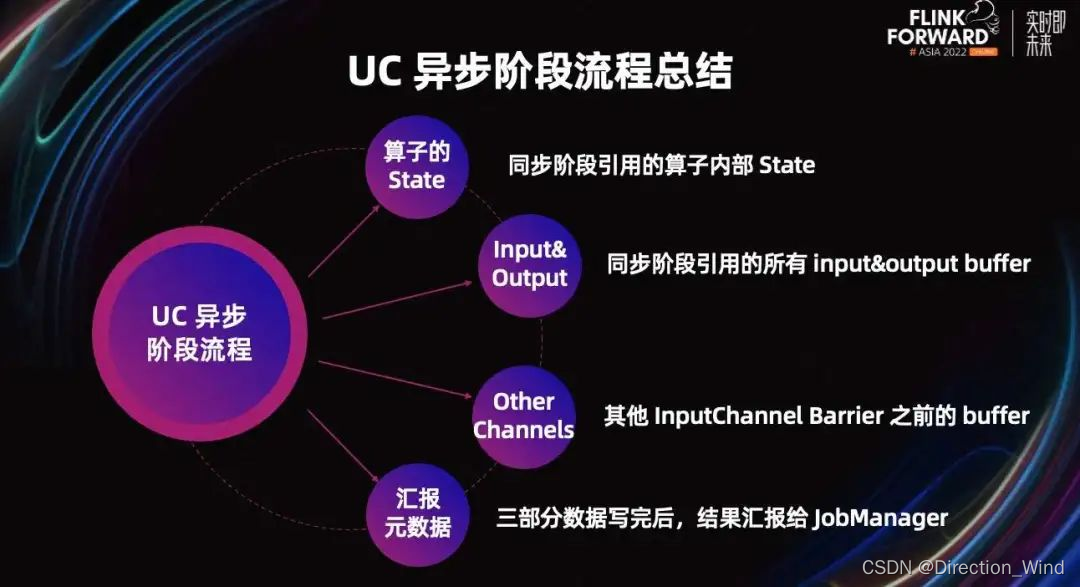
接下来,总结一下 UC 异步阶段流程。异步阶段需要写三部分数据到 HDFS,分别是:
- 同步阶段引用的算子内部的 State。
- 同步阶段引用的所有 input 和 output Buffer。
- 以及其他 input channel Barrier 之前的 Buffer。
对于ac异步阶段的话 写入hdfs的应该就是:
- 同步阶段引用的算子内部的 State。
- 同步阶段引用的所有 input 和 output Buffer。
当这三部分数据写完后,Task 会将结果汇报给 JobManager,Task 的异步阶段结束。其中算子 State 和汇报元数据流程与 Aligned Checkpoint 一致。

理论上,反压时 Barrier 可以一路超车,快速从 Source Task 超车到 Sink,保证 UC 可以快速完成。
但现实却是 UC 效果不佳,很多反压场景 UC 仍然不能完成。而且 UC 相比 AC 有大量的额外风险和 bug。
大幅提升 UC 收益
Task 处理数据流程
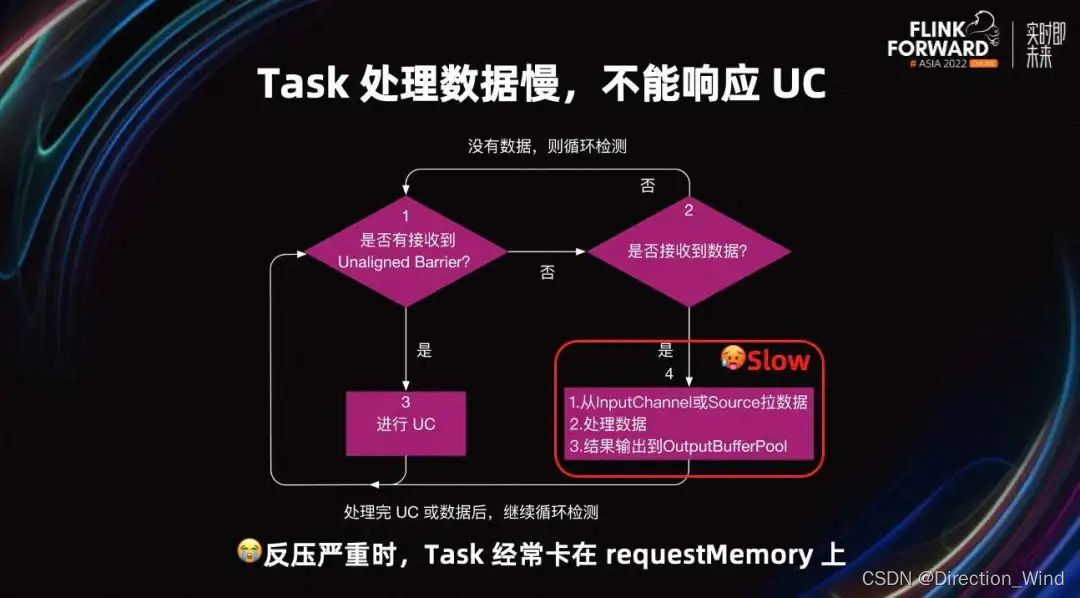
接下来介绍哪些场景 UC 不能完成以及通过一些优化项大幅提升 UC 的适用场景和收益。
首先看一下 Task 处理数据流程。Task 会检查是否有接收到 UC Barrier。如果接收到,直接进行 UC。如果没有接收到 Barrier,则检查是否有接收到数据。如果也没有接收到数据,则循环检测。如果接收到数据,就开始处理。处理数据分三步:
- 如果是 Source Task,则从 Source 读取数据。如果是非 Source Task,则从 input channel 读取数据。
- 读取到数据后,执行业务逻辑开始处理。
- 处理完以后,将结果写入到 output Buffer 中。
当处理结束后,再次循环检测。
如果 Task 处理一条数据并写入到 output Buffer 需要十分钟。那么在这 10 分钟期间,就算 UC Barrier 来了,Task 也不能进行 Checkpoint,所以 UC 还是会超时。
通常处理一条数据不会很慢,但写入到 output Buffer 里,可能会比较耗时。因为反压严重时,Task 的 output Buffer 经常没有可用的 Buffer,导致 Task 输出数据时经常卡在 request memory 上。这就是我们熟知的 Flink 反压机制。
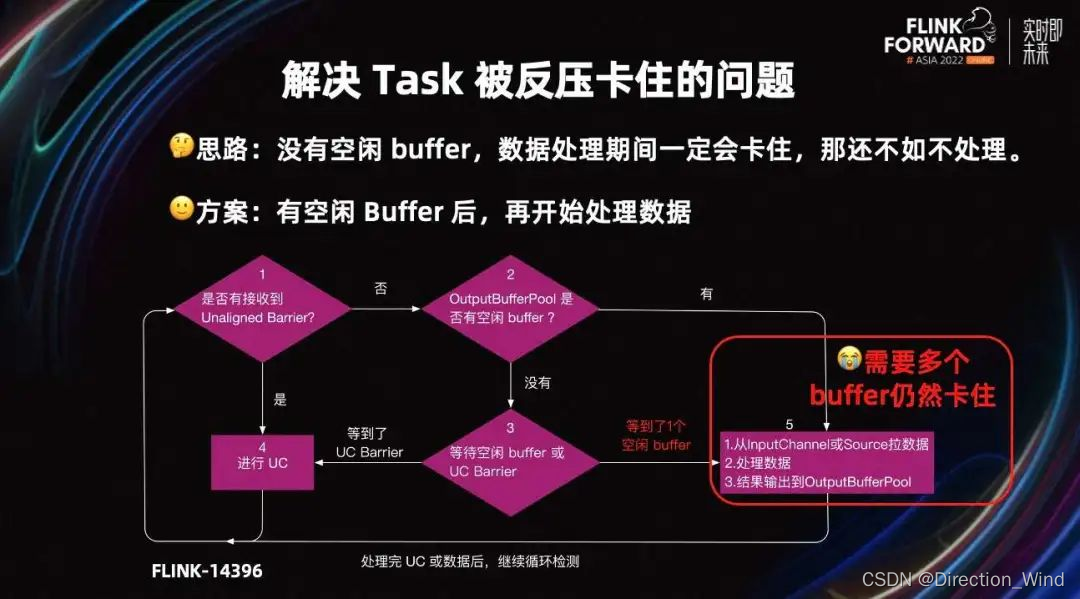
如果没有空闲 Buffer,数据处理完也一定会卡住,还不如不处理。所以 Flink 社区在 Flink-14396 中引入了检查空闲 Buffer 的机制。解决方案是 Task 在处理数据前,检查 output Buffer Pool 是否有空闲的 Buffer,等有空闲 Buffer 分后再处理数据。
详细处理流程如图所示,首先会检查是否接收到 Barrier。如果有,则进行 UC;如果没有,则先判断 output Buffer Pool 是不是有空闲的 Buffer,如果有则处理数据,如果没有则进入第三步,等待空闲 Buffer 或 UC Barrier。如果等到 Barrier,则开始 Checkpoint;如果等到了一个空闲 Buffer,则开始处理数据。
优化前,Task 会卡在第五步的数据处理环节,不能及时响应 UC。优化后,Task 会卡在第三步,在这个环节接收到 UC Barrier 时,也可以快速开始 UC。
第三步,只检查是否有一个空闲 Buffer。所以当处理一条数据需要多个 Buffer 的场景,Task 处理完数据输出结果时,可能仍然会卡在第五步,导致 Task 不能处理 UC。
例如单条数据较大,flatmap 算子、window 触发以及广播 watermark,都是处理一条数据,需要多个 Buffer 的场景。这些场景 Task 仍然会卡在 request memory 上。
Overdraft Buffer
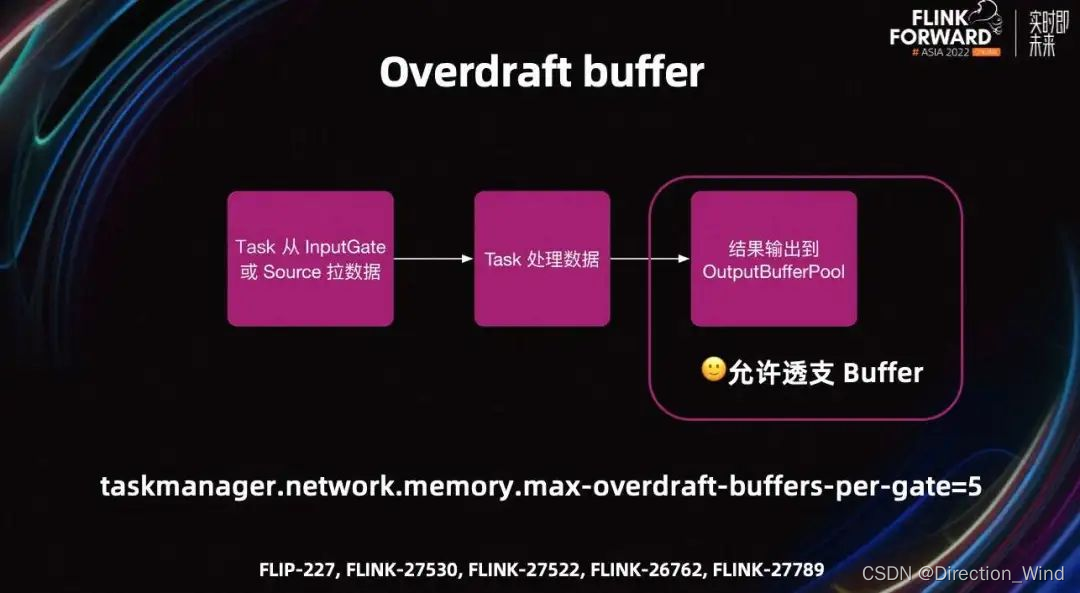
基于上述问题,FLIP-227 提出了 overdraft Buffer(透支 Buffer)的提议。
Task 处理数据时有三步,即拉数据、处理数据以及输出结果。透支 Buffer 的思路是,在输出结果时,如果 output Buffer pool 中的 Buffer 不足,且 Task 有足够的 network Buffer。则当前 Task 会向 TM 透支一些 Buffer,从而完成数据处理环节,防止 Task 阻塞。
优化后处理一条数据需要多个 Buffer 的场景,UC 也可以较好的工作。默认每个 gate 可以透支五个 Buffer,可以调节 max-overdraft-Buffer 参数来控制可以透支的 Buffer 量。
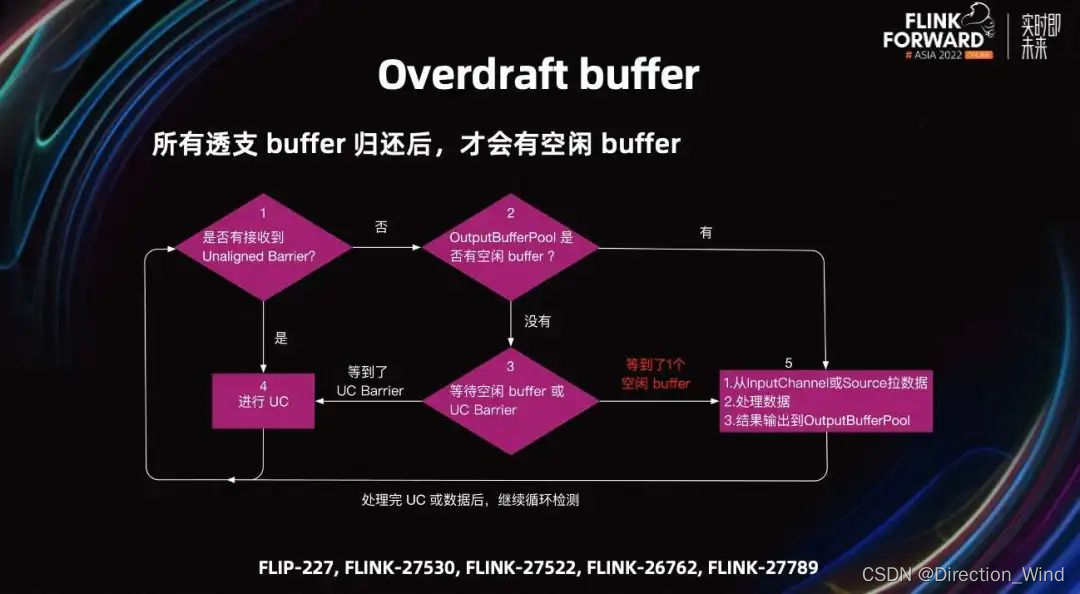
Task 一定会在没有空闲 Buffer 时,才会使用透支 Buffer。一旦透支 Buffer 被使用,Task 在等待 Barrier 和空闲 Buffer 时,会认为没有空闲 Buffer。直到所有透支 Buffer 都被下游 Task 消费,且 output Buffer pool 至少有一个空闲 Buffer 时,Task 才能继续处理数据。Flink 1.16 已经支持了透支 Buffer 功能。
Legacy Source

接下来,介绍一下 Legacy Source 的提升。从数据的来源划分,Flink 有两种 Task,分别是 Source Task 和非 Source Task。Source Task 从外部组件读取数据到 Flink Job。非 Source Task 从 input channel 中读取数据,数据来源于上游 Task。
非 Source Task 会检查有空闲 Buffer 后,再从 input channel 里拿数据。Source Task 从外部组件读取数据前,如果不检查是否有空闲 Buffer,则 UC 会表现不佳。
Flink 有两种 Source,分别是 Legacy Source 和新的 Source。新 Source 与 Task 的工作模式属于拉的模式。工作模式与 input channel 类似,Task 会检查有空闲 Buffer 后,再从 Source 中拿数据。
如图所示,Legacy Source 是推的模式。Legacy Source 从外部系统读数据后,直接往下游发送。当没有空闲 Buffer 时,就会卡住,不能正常处理 UC。
Legacy Source 属于社区废弃的 Source,遗憾的是我们生产环境大部分 Flink 1.13 的任务仍在使用 Legacy Source,所以我们对常用的 Legacy Source 做了改进。
改进思路与上述思路类似:Legacy Source 检查有空闲 Buffer 后,再开始处理数据。Flink 中最常用的 FlinkKafkaConsumer 就是 Legacy Source,所以业界的 Flink 很多用户仍在使用。我们将内部的改进版 Legacy Source 分享到了 Flink-26759 中,有需要的同学可以参考(来自虾皮)。
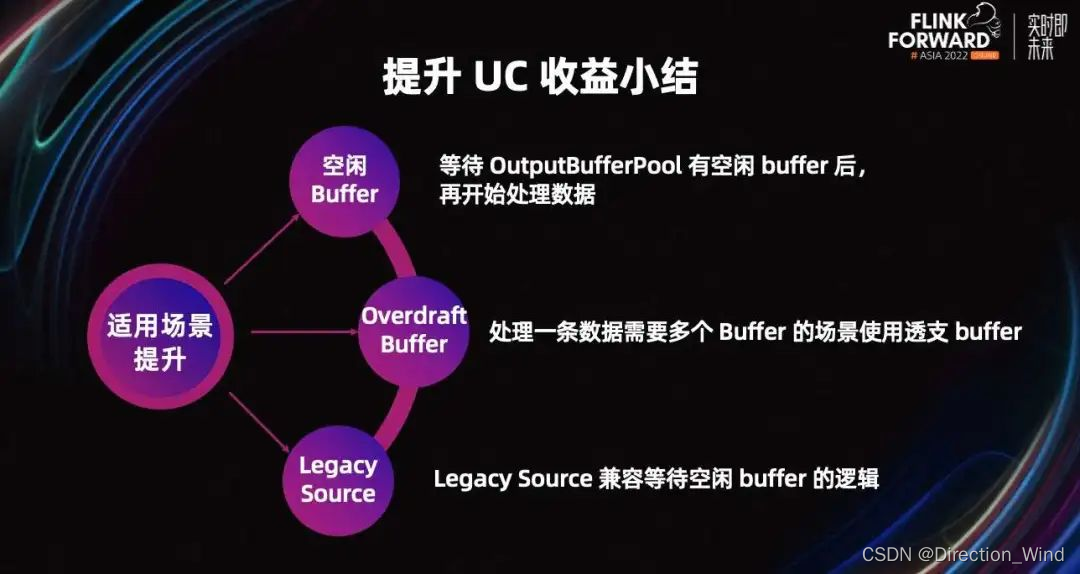
最后,对提升 UC 收益做一个小结。为了防止 Task 在处理数据期间卡住,Flink 会等待有空闲 Buffer 后再处理数据。处理一条数据需要多个 Buffer 的场景,为了防止 Task 卡住,引入了 Overdraft Buffer 来解决。除此之外,Legacy Source 也支持了等待空闲 Buffer 的逻辑。
大幅降低 UC 风险
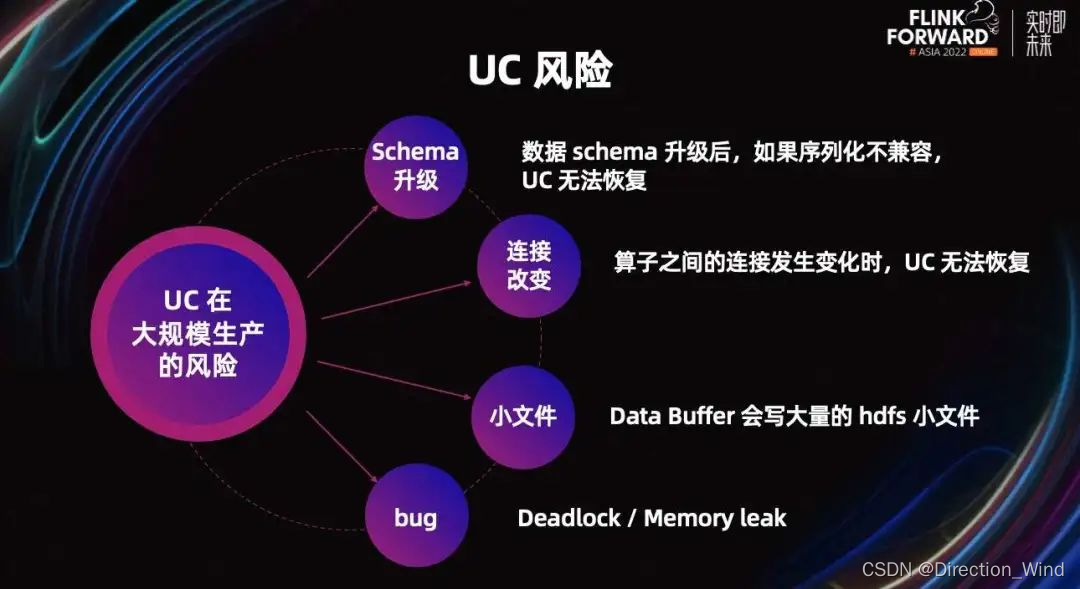
接下来我会介绍 UC 带来的额外风险以及如何规避风险。
首先,介绍一下 UC 在大规模生产下有哪些风险。由于 UC 比 AC 写入了额外的数据,这些数据会带来一些问题。
例如,作业重启前后,如果数据序列化不兼容,则 UC 无法恢复。其次,如果算子之间的连接发生改变,UC 也无法恢复。除此之外,这些数据会写大量的小文件到 DFS,可能会给系统带来压力。
与此同时,我们在调研和使用过程中发现了一些 UC 的 bug。例如死锁和内存泄露。

如上图所示,简单对比一下 AC 和 UC。当反压正常时,AC 和 UC 都能成功,但 AC 无风险,UC 有风险,所以 AC 更好。当反压严重时,AC 会失败,但 UC 能成功,所以 UC 更好。所以我们的目标是,反压正常时使用 AC,反压严重时使用 UC。
如何实现这个目标呢?我们的思路就是混合使用 AC 和 UC。即默认使用 AC,当 AC 不能完成时切换成 UC。

Flink 社区在 1.13 提出了 AC timeout 机制,即默认使用 AC。当 AC 在 AC timeout 内不能完成时,从 AC 切换为 UC。
但在我们调研时发现,AC timeout 机制效果不佳。假设 AC timeout 是一分钟,且 Checkpoint timeout 是五分钟,即默认使用 AC。如果 AC 1 分钟内不能成功,则切换为 UC。如果 Checkpoint 总时长超过五分钟,就会超时失败。
效果不佳主要体现在,当一分钟时间到了,Job 仍然不能从 AC 切换为 UC,甚至五分钟都不能切换成为 UC,最终导致 Checkpoint 超时失败。
AC timeout 机制
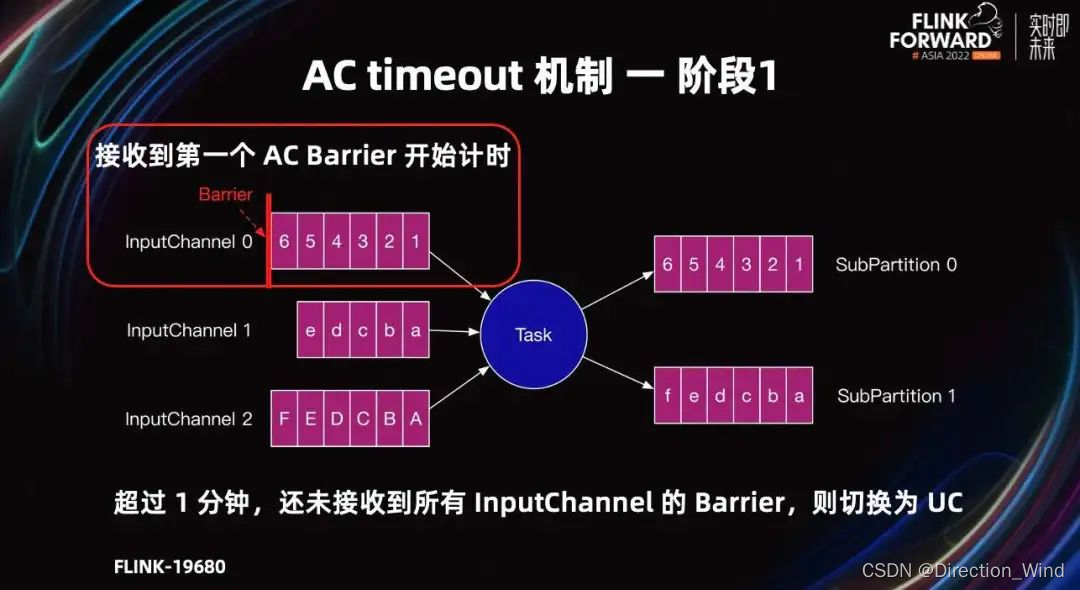
接下来,详细介绍一下 AC timeout 机制。AC timeout 在社区的发展主要有三个阶段,Flink-19680 首次支持了 AC timeout 机制。
第一阶段的原理是,Task 从接收到第一个 Barrier 开始计时,超过一分钟还未接收到所有 input channel 的 Barrier,则切换为 UC,或者说 Barrier 对齐时间超过一分钟,则切换为 UC。

第一阶段存在的问题是,每个 Task 接收到第一个 Barrier 后,59 秒接收到所有 Barrier,则不会切换为 UC,但多个 Task 的时间会累计。
我们期望 Job 的 AC 一分钟未完成,再切换为 UC。但图中除了 Source Task 以外的 7 个 Task,每个 Task 都用了 59 秒,所以 Task 都不会切换为 UC。但 7*59 秒,总时间已经超过了五分钟,所以最终会超时失败。
相应解决思路是,AC timeout 应该全局累积。
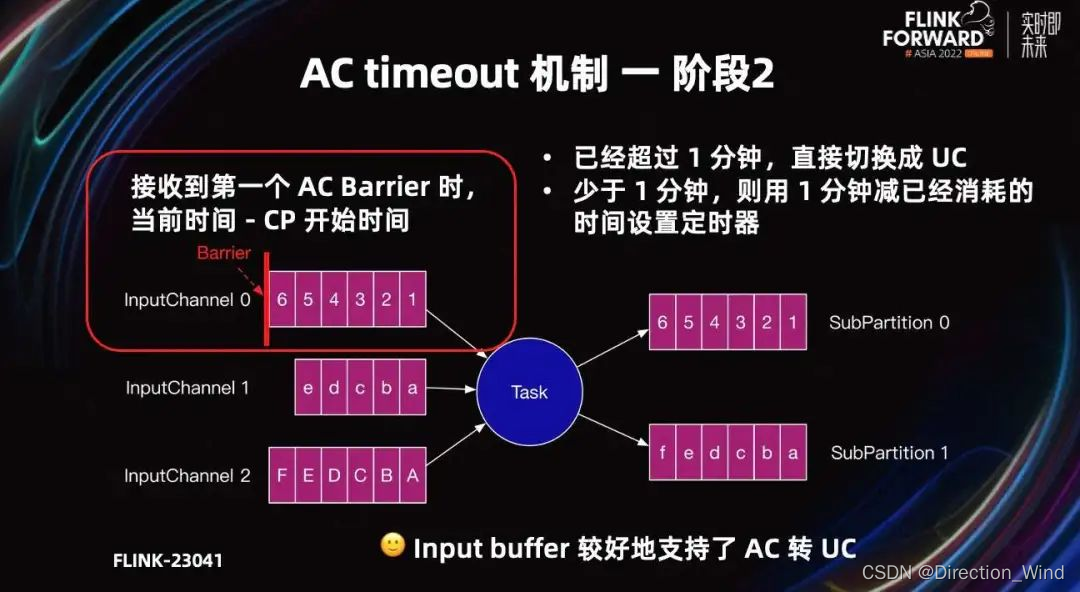
基于阶段一的问题,Flink-23041 进行了改进。第二阶段的原理是,当 input channel 收到 Barrier 后,用当前系统时间减去 Checkpoint 的开始时间,表示 Checkpoint 已经过了多久。
如果超过了一分钟,直接切换为 UC。如果少于一分钟,则用一分钟减 AC 已经消耗的时间,表示希望多久以后切换成 UC。通过设定一个定时器,当 cp 全局时间到达一分钟时触发,时间到了就会切换为 UC。
阶段二相比阶段一,解决了多个 Task 时间累积的问题。只要 input channel 接收到 Barrier,且在指定时间内 AC 没有完成,就可以定时将 AC 切换为 UC。所以阶段二完成后,input Buffer 已经可以较好的支持从 AC 转化为 UC。
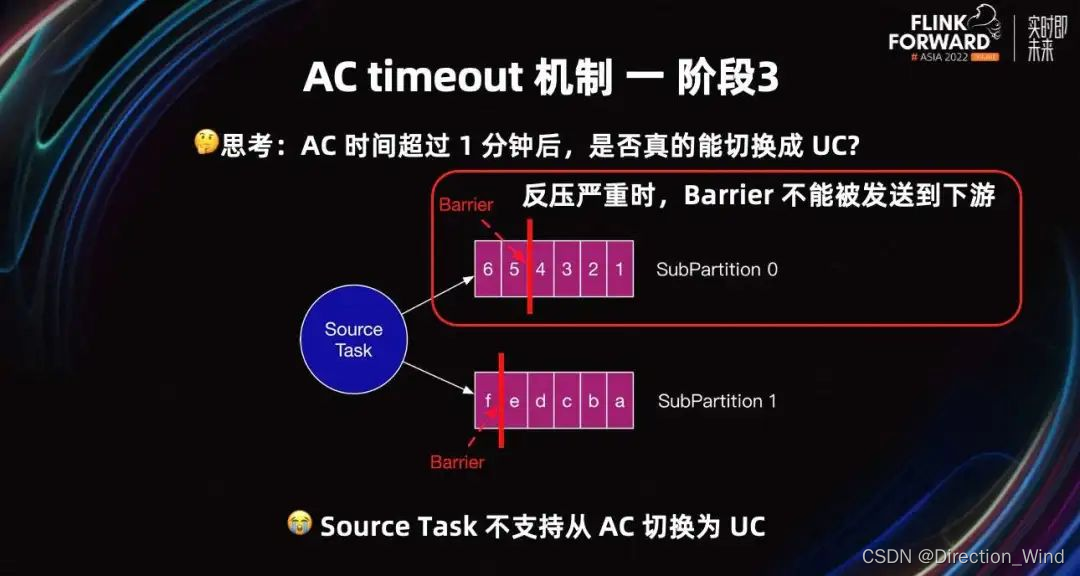
当时间超过一分钟后,所有 Task 真的能从 AC 转化为 UC 吗?例如 Source Task 反压严重时,Barrier 不能被发送到下游。下游 Task 接收不到 Barrier,所以无法从 AC 转化为 UC。当前 Source Task 也不支持从 AC 切换为 UC。
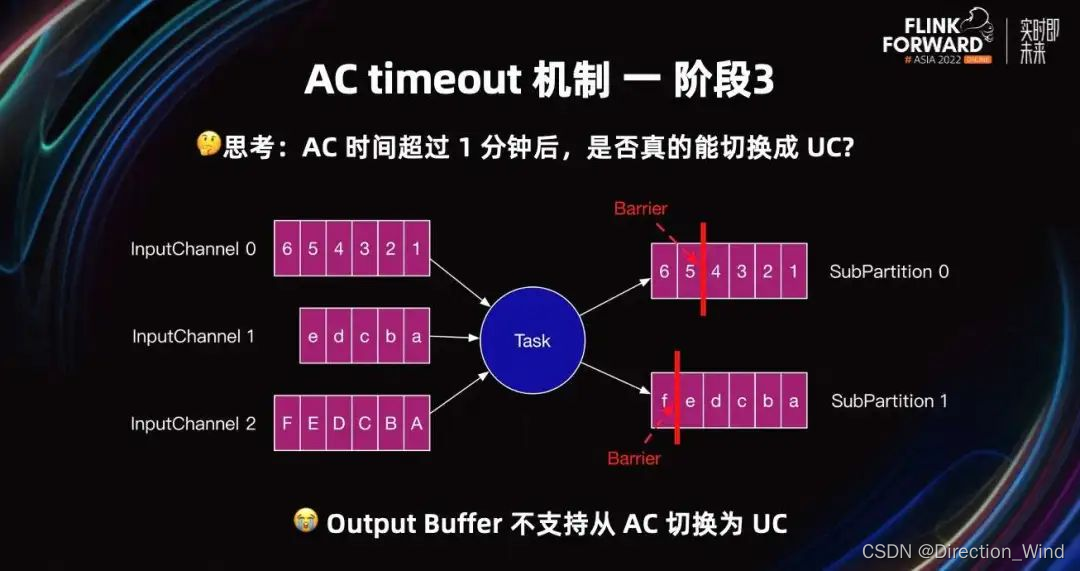
非 Source Task 亦是如此,如果一分钟内接收到了所有 Barrier,则当前 Task 不会切换为 UC。但可能由于反压严重,Barrier 长时间不能发送到下游。所以根本问题是,只有 input Buffer 支持从 AC 切换为 UC,但 output Buffer 不支持从 AC 切换成 UC。
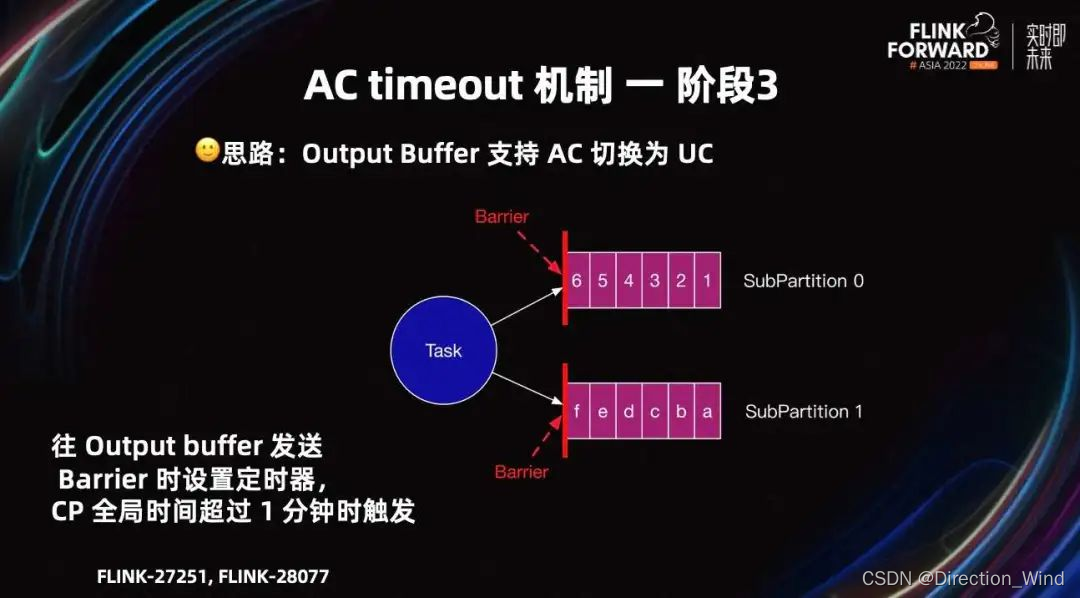
基于这个问题,我们在 Flink-27251 中提出了支持 Output Buffer 从 AC 切换为 UC 的改进。设计思路是 Task 往 output Buffer 发送 Barrier 时,设置定时器,CP 全局时间超过一分钟时触发。
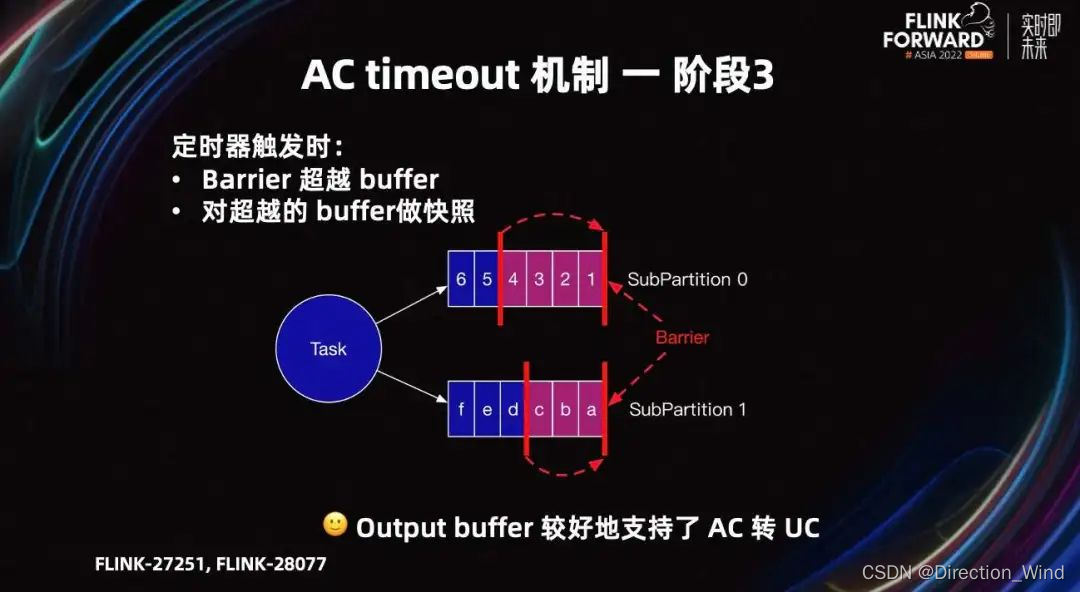
当定时器触发时,output Buffer 切换为 UC,需要进行两个操作。
-
Barrier 超越 Buffer,到 SubPartition 头部。保证 Barrier 快速超车到下游 Task。
-
对图中超越的紫红色 Buffer 做快照。
阶段三完成后,input 和 output Buffer 都可以较好地支持 AC 转 UC 了。
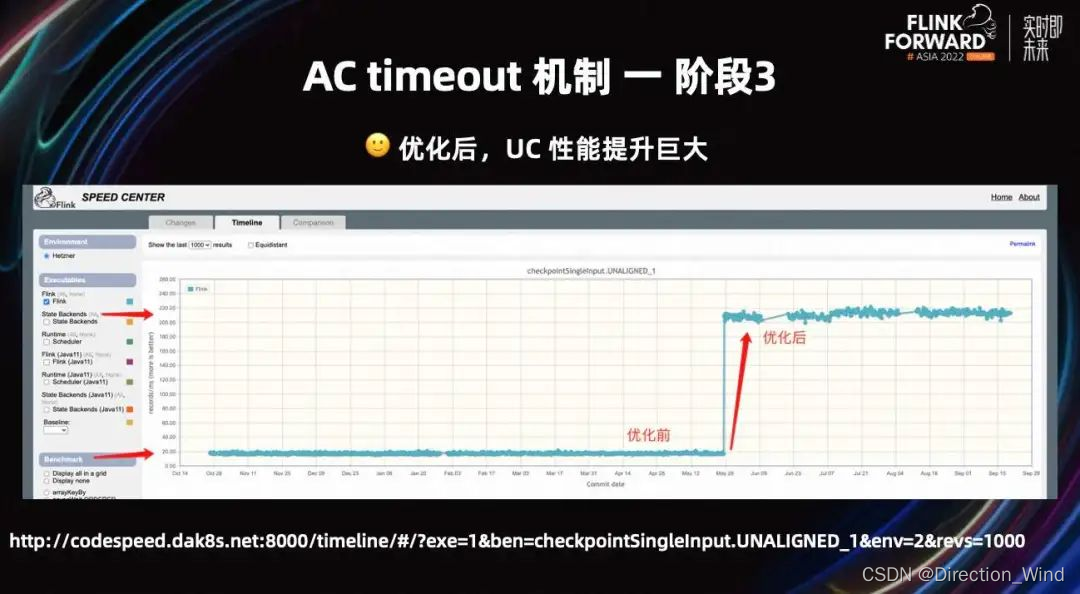
Flink 社区早期为 Checkpoint 设计了 Benchmark,用来评估 Checkpoint 的性能。如上图所示,该优化 merge 到 Flink master 分支后,UC 的性能提升非常明显。这里有链接可以查看 Flink benchmark 的结果,相关地址:
http://codespeed.dak8s.net:8000/timeline/#/?exe=1&ben=checkpointSinglelnput.UNALIGNED_1&env=2&revs=1000

最后,对 AC timeout 机制、AC 和 UC 混合使用场景进行总结。经过上述优化后可以达到的效果是,反压严重时,使用 UC 反压;反压正常时,使用 AC。
对业务侧的收益是,反压严重时,Checkpoint 可以成功。反压正常时,无任何额外的风险和开销。
启用非对齐 checkpoint 后,你也可以通过 CheckpointConfig.setAlignmentTimeout(Duration) 或 execution.checkpointing.alignment-timeout 在配置文件中指定对齐超时时间。指定超时时间之后,每个 checkpoint 刚开始任然是对齐的 checkpoint,但是如果某些子任务的对齐时间超过了该超时时间,就会变成非对齐 checkpoint。
checkpointConfig.setAlignmentTimeout(Duration.ofMillis(param.getLong(UNALIGNED_CHECKPOINTS_TIMEOUT, 5000L)));
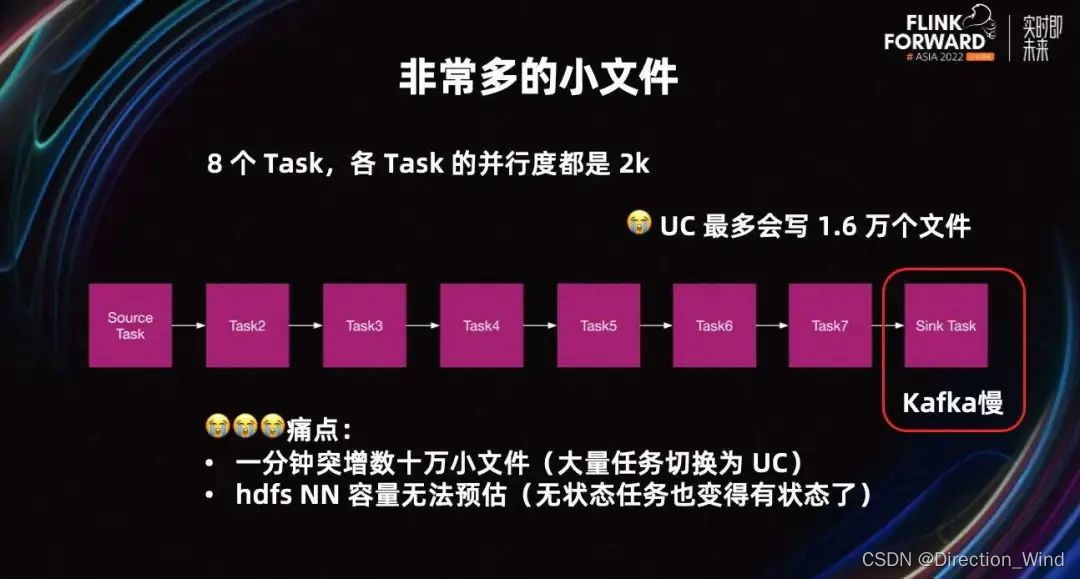
如果整个集群大量作业同时反压严重,大量作业同时切换为 UC,仍然有其他风险。
假设一个作业有 8 个 Task,各个 Task 的并行度都是 2000。UC 默认每个 Task 写一个文件,所以该 Job 最多会写 1.6 万个文件。
当生产环境有大量 Flink Job 在写 Kafka 时,假设 Kafka 集群出现网络瓶颈或磁盘瓶颈,大量 Flink 任务会反压。此时,大量 Flink 任务会同时从 AC 切换为 UC,瞬间整个集群会突增数上百万个小文件,导致 UC 对 DFS 的压力很难评估。
因为很多任务平时是无状态的,平时对 HDFS 的访问很少。但 UC 会让所有任务都变得有状态,且文件数较多,所以这也算是一个隐患。如果大量任务同时切换为 UC,HDFS 可能会血崩。

为了解决小文件的问题,我们在 Flink-26803 中提出了合并 UC 小文件的改进。优化思路是,同一个 TM 的多个 Task,不再单独创建文件,而是共享一个文件。
默认 execution.checkpointing.unaligned.max-subTasks-per-channel-state-file 是 5,即五个 Task 共享一个 UC 文件。UC 文件个数就会减少为原来的 1/5。五个 Task 只能串行写文件,来保证数据正确性,所以耗时会增加。
从生产经验来看,大量的 UC 小文件都会在 1M 以内,所以 20 个 Task 共享一个文件也是可以接受的。如果系统压力较小,且 Flink Job 更追求写效率,可以设置该参数为 1,表示 Task 不共享 UC 文件。
Flink 1.17 已经支持了 UC 小文件合并的 feature。
作业恢复和扩缩容原理与优化
接下来讲一讲 Flink 社区在作业恢复和扩缩容部分的优化,主要包括优化本地状态重建,云原生背景下的分层状态存储架构升级,以及简化调度过程。

作业扩缩容和作业容错恢复有很多共性,比如都需要依据上一次快照来做恢复,都需要重新调度,但他们在细微之处又是有些区别的。
本地状态重建
以状态恢复本地重建来讲,对于容错恢复,将状态文件原样加载进本地数据库就可以了,但是如果是扩缩容恢复就会更复杂一些。举例来说上图中的作业并发从 3 扩容到 4,新作业 task 2 的状态有一部分来自原先作业的 task 1,还有一部分来自原先作业的 task 2,分别是橙色和黄色部分。
Flink 作业算子的状态在 Rescaling 做状态重新分配时,新分配的状态来自原先作业相邻的并发,不可能出现跳跃的有间隔的状态分配。在缩容时,有可能有多个状态合成一个新状态;在扩容的时候,因为状态一定是变小的,所以新的变小的状态一定最多来自相邻的两个原先的并发。
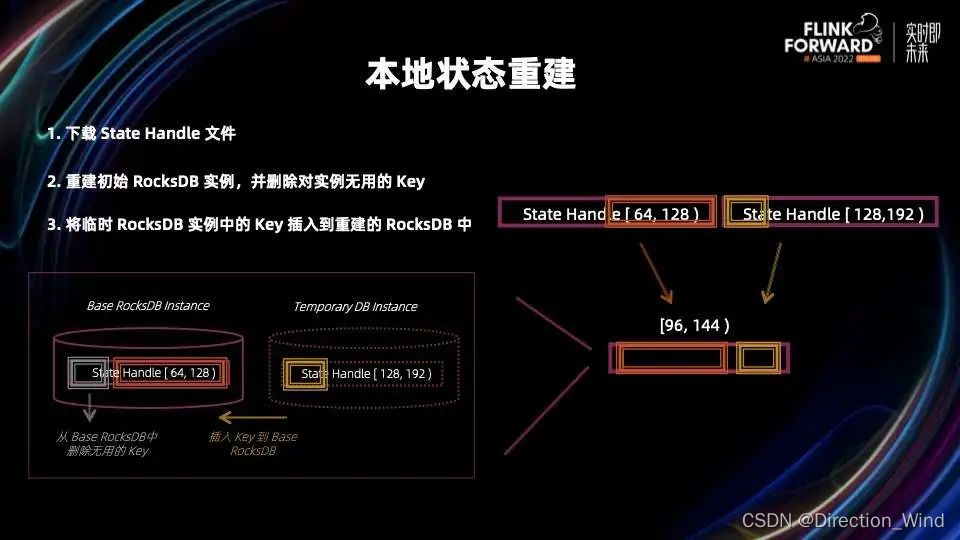
接下来具体讲一讲状态是如何做本地重建的,以 RocksDB 为例。
-
第一步,需要下载相关的状态文件。
-
第二步,重建初始的 RocksDB 实例,并删除对实例无用的 Key,即删除上图中灰色的部分,留下橙色部分。
-
第三步,将临时 RocksDB 实例中的 Key 插入到第二步重建的 RocksDB 中,也就是黄色的部分插入到橙色的 DB 中。
快照管理
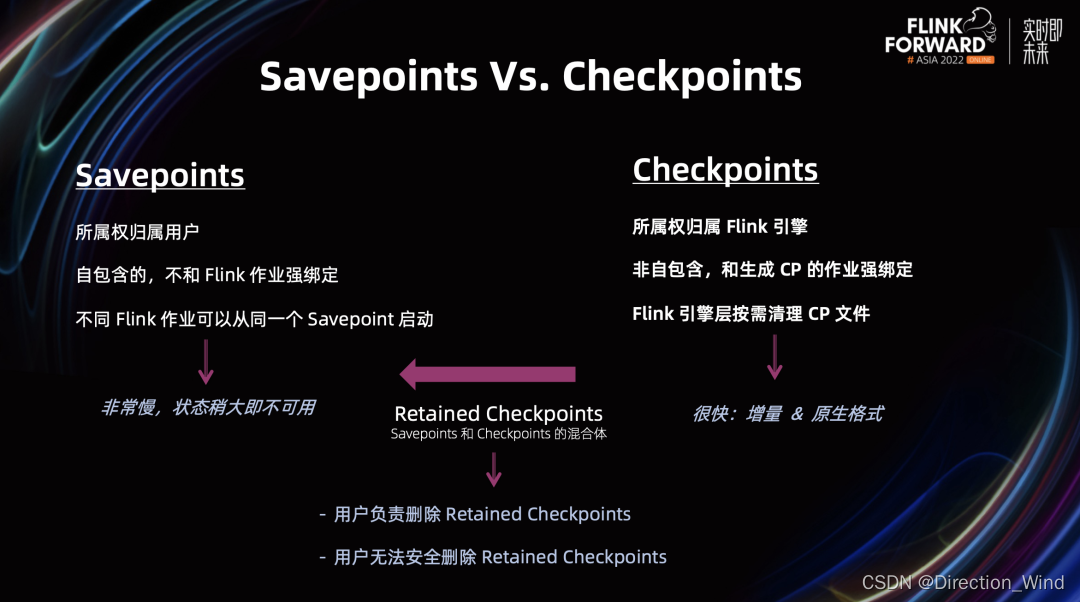
Flink 的快照 Snapshot 分为两种:Savepoint 和 Checkpoint。
Savepoint 一般由用户触发,所以它归属用户所有,因此由用户负责创建和删除。正因此,Flink 系统引擎层是不能够去删除 Savepoint 相关文件的。所以 Savepoint 不和 Flink 作业强绑定,不同的 Flink 作业可以从同一个 Savepoint 启动。Savepoint 是自包含的:自己包含所需要的一切。
Checkpoint 正好相反,它的主要作用是系统容错自愈,所以它由 Flink 引擎周期性触发,并且所属权归属 Flink 引擎。Checkpoint 文件的组织结构都由 Flink 引擎决定和管理,所以引擎负责按需清理 Checkpoint 文件。正因此,Checkpoint 和生成该 Checkpoint 的作业强绑定,并且是非自包含的,比如说 Incremental Checkpoint 之间会有依赖关系。
那有什么问题呢?因为 Savepoint 主要目标服务对象是用户,为了对用户友好,Savepoint 使用用户可读的标准格式,也正因此 Savepoints 做得非常慢,经常情况下状态稍微大一点就会超时,同样恢复也很慢。另一方面,Checkpoint 使用的是增量系统原生格式,所以做得很快。
这种情况下,用户会把 Retained Checkpoint 当成 Savepoint 来使用。Retained Checkpoint 是在作业停掉后保留的 Checkpoint,这样Retained Checkpoint 就变成了 Savepoint 和 Checkpoint 的混合体。造成的问题是用户负责删除 Retained Checkpoint,但是用户并不知道如何安全的删除 Retained Checkpoint。
为了解决上述问题,Flink 1.15 引入了两种状态恢复模式,即 Claim 模式和 No-Claim 模式。
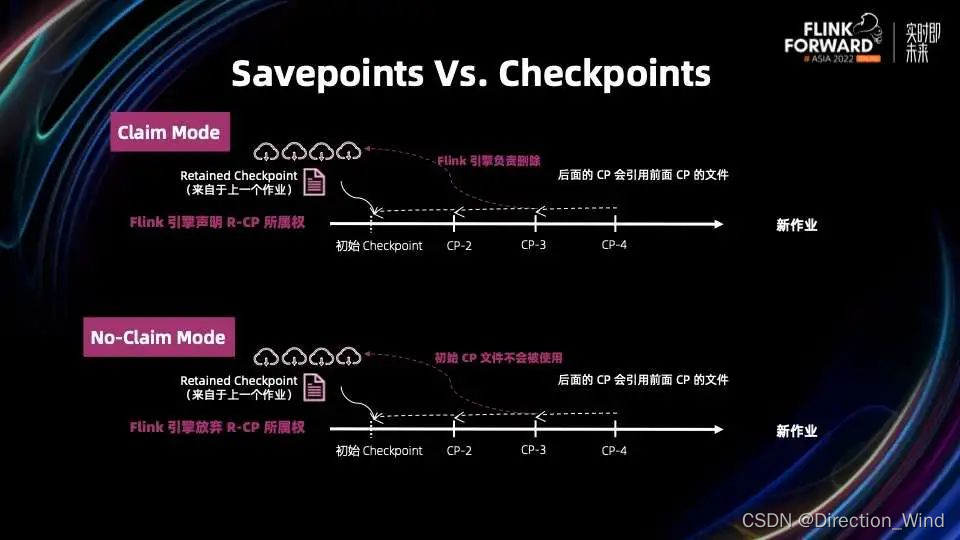
在 Claim 恢复模式下,引擎声明 Retained Checkpoint 的所属权,Retained Checkpoint 归引擎所有,引擎负责删除。
在 No-Claim 恢复模式下,引擎放弃 Retained Checkpoint 的所属权。Retained Checkpoint 中所有的文件都不会被 Flink 引擎使用,用户可以很安全的删除 Retained Checkpoint。
在 No-Claim 的基础上,我们引入了 Native Savepoint,来加速 Savepoint 的创建和恢复。Native Savepoints 使用和 Checkpoint 一样的存储格式,其实现原理和 No-Claim 类似。Savepoint 不会使用之前的 Checkpoint 文件,相当于做一个全量的 Checkpoint。我们的企业版本通过进一步优化,让 Native Savepoint 也真正能做到增量 Savepoint。
总结一下checkpoint 1.0版本(社区在202301正在搞2.0版本)的问题
问题 1:对齐时间长,反压时被完全阻塞
Flink 的 Checkpoint 机制是通过从 Source 插入 Barrier,然后在 Barrier 流过每个算子的时候给每个算子做快照来完成的。为了保证全局一致性,如果算子有多个输入管道的时候,需要对齐多个输入的 Barrier。这就产生了问题 1,因为每条链路的处理速度不一样,因此 Barrier 对齐是需要时间的。如果某一条链路有反压,会因为等待对齐而使得整条链路完全被阻塞,Checkpoint 也会因为阻塞而无法完成。
问题 2:Buffer 数目固定,管道中有多余的处理数据
由于算子间的上下游 Buffer 数目是固定的,它们会缓存比实际所需更多的数据。这些多余的数据不仅会在反压时进一步阻塞链路,而且会使得 Unaligned Checkpoint 存储更多的上下游管道数据。
问题 3:快照异步上传时间较长且不可控
快照的过程包括两部分:同步状态刷盘和异步上传状态文件,其中异步文件上传的过程和状态文件大小相关,时间较长且不可控。
Flink 1.11、 Flink 1.12 引入了 Unaligned Checkpoint, 使得 Checkpoint Barrier 不被缓慢的中间数据阻塞。Flink 1.13、Flink 1.14 引入了 Buffer Debloating,让算子与算子间的管道数据变得更少。Flink 1.15、Flink 1.16 引入了通用增量 Checkpoints,让异步上传的过程更快、更稳定。
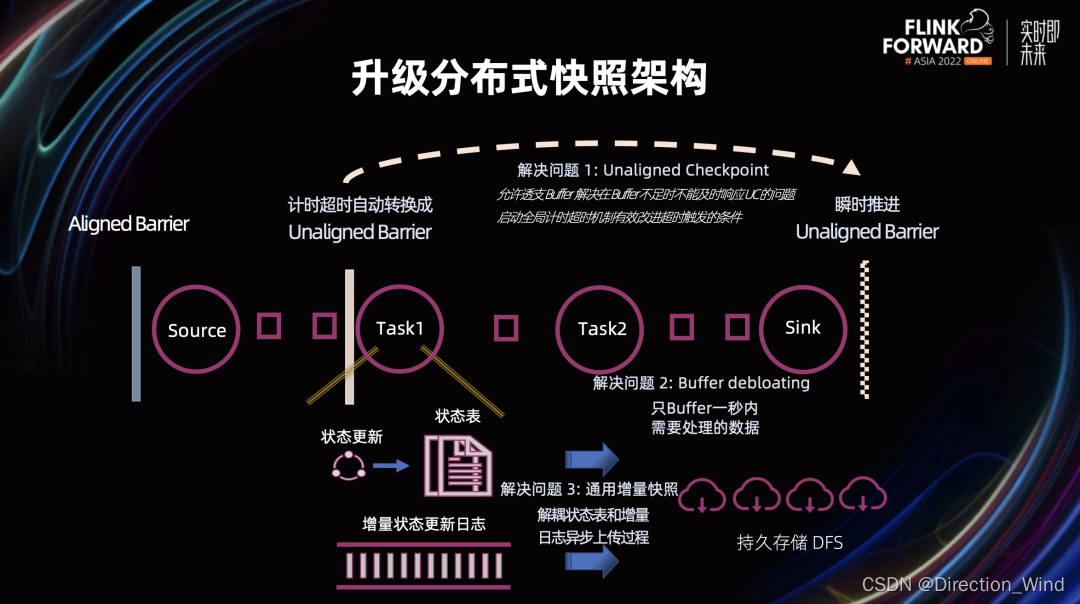
对于问题 1,在 Flink 1.16 版本中,Unaligned Checkpoint 允许透支 Buffer,解决了在 Buffer 不足时,不能及时响应 Unaligned Checkpoint 的问题。此外,全局计时超时机制的引入能够有效改进 Unaligned 和 Aligned Checkpoint 之间自动转换的触发条件。
对于问题 2,Buffer debloating 的引入可以动态调整缓存的数据量,动态缓存 1 秒内需要处理的数据。
下面我们来重点看一看第 3 个问题是如何用通用增量 Checkpoint 来解决的
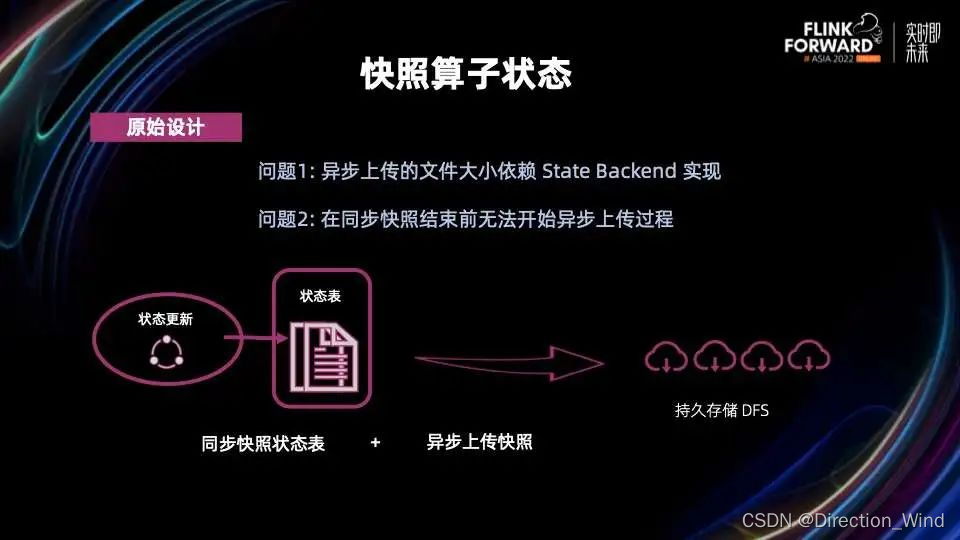
Flink 的算子状态更新会反映在状态表中。在之前的设计当中,Flink 算子做快照的过程分为两步:第一步是同步的对状态表进行快照,内存中的数据刷盘,准备好上传到持久存储的文件;第二步是异步的上传这些文件。
异步上传文件这个部分有两个问题:
问题 1:异步上传的文件大小依赖 State Backend 的实现
问题 2:异步过程需要等到同步过程结束才能开始,因为同步快照结束前是没法准备好需要上传的文件的
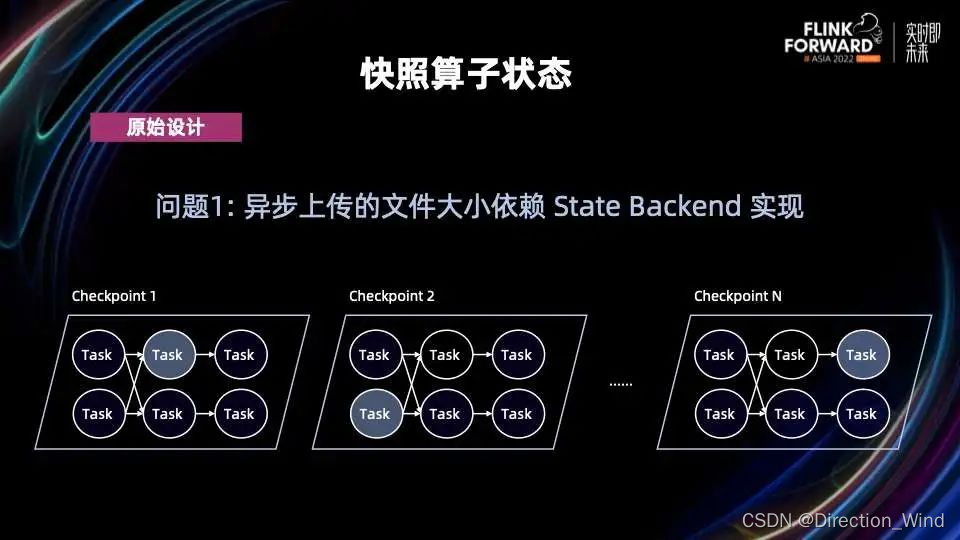
我们来分别看一下这两个问题。对于第一个问题,以 RocksDB 为例,虽然 Flink 对 RocksDB 也支持增量 Checpoint,但是 RocksDB 出于自身实现考虑,它需要对文件做 Compaction。每次 Compaction 会产生新的比较大的文件,那这个时候即使是增量 Checkpoint,需要上传的文件也会因此时不时变大。在 Flink 作业并发比较大的情况下,上传文件时不时变大的问题就会变得很频繁,因为只有等所有并发的文件上传完毕,一个完整的算子状态才算快照完成。
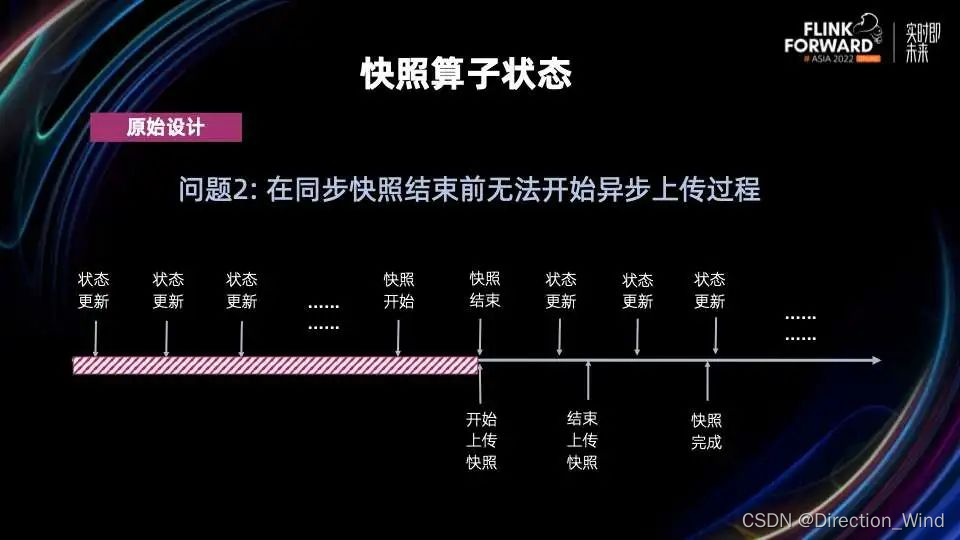
对于第二个问题,在同步快照结束前,Flink 无法准备好需要上传的文件,所以必须要等快照结束时才能开始上传。也就是说,上图中的红色斜条纹这个时间段完全被浪费了。如果需要上传的状态比较大,会在很短时间内对 CPU 和网络产生较大的压力。
解决:Flink 社区实现了通用增量快照。在新架构下,状态更新不仅会更新状态表,而且会记录状态的更新日志。上图中状态表会和架构升级前一样周期性的刷到持久存储,但是这个周期可以比较大(比如 10 分钟)在后台慢慢上传,该过程称为物化过程。同时状态更新日志也会持续上传到远端持久存储,并且在做 Checkpoint 时 Flush 剩余全部日志。
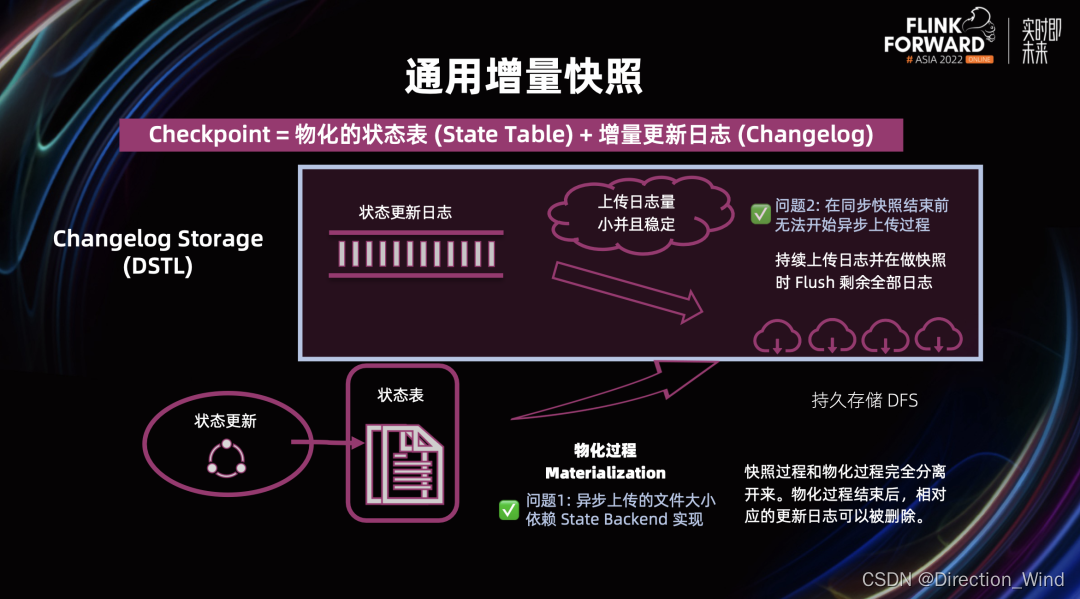
这样的设计就比较好的解决了前面提到的两个问题:通过将快照过程和物化过程完全独立开来,可以让异步上传的文件大小变得很稳定;同时因为状态更新是持续的,所以我们可以在快照之前就一直持续的上传更新日志,所以在 Flush 以后我们实际需要上传的数据量就变得很小。
架构升级后的一个 Checkpoint 由物化的状态表以及增量更新的日志组成。物化过程结束后,相对应的更新日志就可以被删除了。上图中的蓝色方框部分,是通用增量快照和之前架构的区别,这个部分被称为 Changelog Storage(DSTL)。

DSTL 是 Durable Short-term Log 的缩写。我们从这个英文名就能看出来 DSTL 是有针对性需求的
-
需要短期持久化增量日志,物化后即可删除
-
需要支持高频写,是一个纯 append 写操作,仅在恢复时需要读取
-
需要 99.9% 的写请求在1秒内完成
-
需要和现有的 Checkpoint 机制提供同一级别的一致性保证
社区现在的版本是用 DFS 来实现的,综合考量下来基本可以满足需求。同时 DSTL 提供了标准的接口也可以对接其他的存储。
这里是通用增量快照,不是增量checkpoint!

这个部分的最后我们来看一下使用通用增量快照的 Trade-off
-
通用增量快照带来的好处显而易见:
可以让 Checkpoint 做的更稳定,平滑 CPU 曲线,平稳网络流量使用(因为快照上传的时间被拉长了,并且单次上传量更小更可控) -
可以更快速的完成 Checkpoint(因为减少了做快照 Flush 的那个部分需要上传的数据)
-
也因此,我们也可以获得更小的端到端的数据延迟,减小 Transactional Sink 的延迟
-
因为可以把 Checkpoint 做快,所以每次 Checkpoint 恢复时需要回滚的数据量也会变少。这对于对数据回滚量有要求的应用是非常关键的
通用增量快照也会带来一些额外的 Cost,主要来自两个方面:Checkpoint 放大和状态双写:
-
Checkpoint 放大的影响主要有两点。第一,远端的存储空间变大。但远端存储空间很便宜,10G 一个月大约 1 块钱。第二,会有额外的网络流量。但一般做 Checkpoint 使用的流量也是内网流量,费用几乎可以忽略不计。
-
对于状态双写,双写会对极限性能有一些影响,但在我们的实验中发现在网络不是瓶颈的情况下,极限性能的损失在 2-3% 左右(Flink 1.17 中优化了双写部分 FLINK-30345 [2] ,也会 backport 到 Flink 1.16),因此性能损失几乎可以忽略不计。
容错恢复2022进展:
最后我们小结回顾一下 Flink 容错恢复在 2022 年的主要进展
在分布式快照架构方面,Unaligned Checkpoint 引入全局计时器,可以通过超时机制自动从 Aligned Checkpoint 切换成 Unaligned Checkpoint,这个对于 Unaligned Checkpoint 生产可用是非常重要的一步
通用增量 Checkpoint 生产可用,这对于 Checkpoint 稳定性和完成速度有很大的提升,同时可以平滑 CPU 和网络带宽的使用
这里值得一提的是,不仅仅是阿里巴巴在 Checkpoint 这个部分贡献了大量的代码,很多其他的公司也积极的投入到社区当中,比如 Shopee 和美团。他们在社区中贡献代码同时,也积极推动这些功能在公司内部的落地和延展,取得了不错的效果
在状态存储方面,我们进行了分层状态存储的初步探索,扩缩容速度有 2 – 10 倍的提升
阿里云实时计算平台推出了扩缩容无断流的组合功能:延迟状态加载和作业热更新,分别从状态加载和作业调度这两个方面来实现扩缩容无断流
引入增量 Native Savepoint,全面提升 Savepoint 的可用性和性能
分层状态存储架构
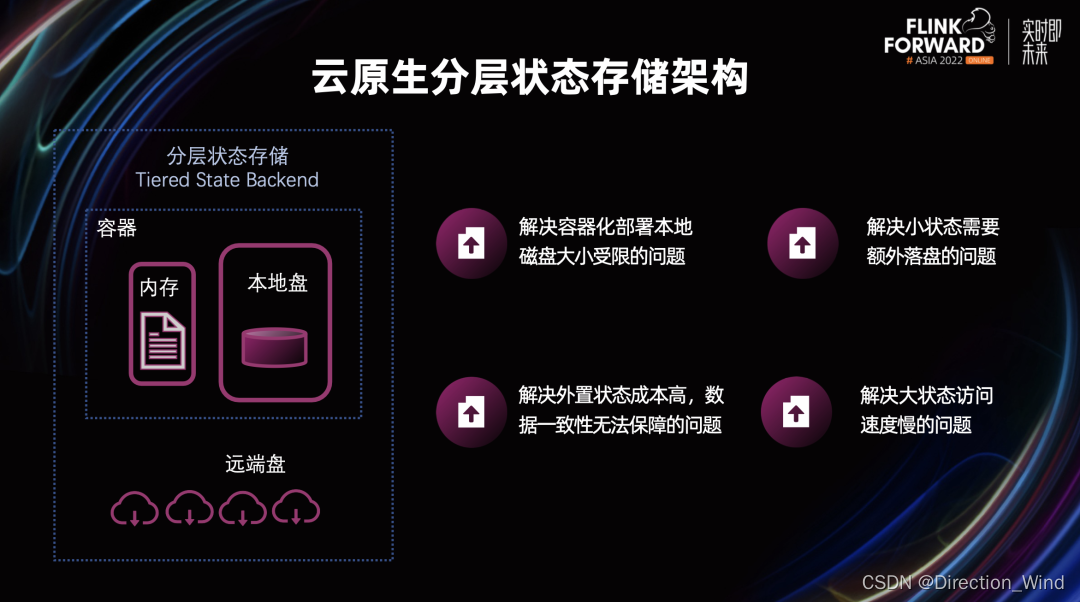
为了更好的适应云原生的大背景,我们对分层状态存储架构也进行了初步探索,也就是说我们把远端盘也作为 State Backend 的一部分。这种分层架构可以解决 Flink 状态存储在云原生背景下面临的大部分问题:
-
解决容器化部署本地磁盘大小受限的问题
-
解决外置状态成本高,数据一致性难以保障的问题
-
解决小状态需要额外落盘的问题
-
解决大状态访问速度慢的问题

















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











