







Doc2X | PDF 到 Markdown 一步搞定
只需几秒,Doc2X 即可将 PDF 转换为 Markdown,支持批量处理和深度翻译功能。
Doc2X | One-Step PDF to Markdown Conversion
In just seconds, Doc2X converts PDFs to Markdown, with support for batch processing and advanced translation features.
👉 立即试用 Doc2X | Try Doc2X Now
原文链接:https://arxiv.org/pdf/2411.05619
WHALE: TOWARDS GENERALIZABLE AND SCALABLE WORLD Models for Embodied Decision-making
WHALE: 面向可泛化和可扩展的具身决策世界模型
Zhilong Zhang 1 , 2 , 3 {}^{1,2,3} 1,2,3 ,Kuifeng Chen 1 , 2 , 3 {}^{1,2,3} 1,2,3 ,* Junyin Ye 1 , 2 , 3 {}^{1,2,3} 1,2,3 ,Yihao Sun 1 , 2 {}^{1,2} 1,2 ,Pengyuan Wang 1 , 2 , 3 {}^{1,2,3} 1,2,3 ,
Zhilong Zhang 1 , 2 , 3 {}^{1,2,3} 1,2,3 ,Kuifeng Chen 1 , 2 , 3 {}^{1,2,3} 1,2,3 ,* Junyin Ye 1 , 2 , 3 {}^{1,2,3} 1,2,3 ,Yihao Sun 1 , 2 {}^{1,2} 1,2 ,Pengyuan Wang 1 , 2 , 3 {}^{1,2,3} 1,2,3 ,
Jingcheng Pang 1 , 2 , 3 {}^{1,2,3} 1,2,3 , Kaiyuan Li 1 , 2 , 3 {}^{1,2,3} 1,2,3 , Tianshuo Liu 1 , 2 , 3 {}^{1,2,3} 1,2,3 , Haoxin Lin 1 , 2 , 3 {}^{1,2,3} 1,2,3 ,
Jingcheng Pang 1 , 2 , 3 {}^{1,2,3} 1,2,3 , Kaiyuan Li 1 , 2 , 3 {}^{1,2,3} 1,2,3 , Tianshuo Liu 1 , 2 , 3 {}^{1,2,3} 1,2,3 , Haoxin Lin 1 , 2 , 3 {}^{1,2,3} 1,2,3 ,
Yang Yu 1 , 2 , 3 {}^{1,2,3} 1,2,3 ; Zhi-Hua Zhou 1 , 2 {}^{1,2} 1,2
Yang Yu 1 , 2 , 3 {}^{1,2,3} 1,2,3 ; Zhi-Hua Zhou 1 , 2 {}^{1,2} 1,2
1 {}^{1} 1 National Key Laboratory for Novel Software Technology,Nanjing University,Nanjing,China
1 {}^{1} 1 国家新软件技术重点实验室,南京大学,中国南京
2 {}^{2} 2 School of Artificial Intelligence,Nanjing University,Nanjing,China
2 {}^{2} 2 人工智能学院,南京大学,中国南京
3 {}^{3} 3 Polixir Technologies,Nanjing,China
3 {}^{3} 3 Polixir Technologies,中国南京
{zhangzl, chenrf, yejy, sunyh, wangpy, pangjc, liky, liuts, linhx}@lamda.nju.edu.cn,
{zhangzl, chenrf, yejy, sunyh, wangpy, pangjc, liky, liuts, linhx}@lamda.nju.edu.cn,
{yuy, zhouzh}@nju.edu.cn
{yuy, zhouzh}@nju.edu.cn
ABSTRACT
摘要
World models play a crucial role in decision-making within embodied environments, enabling cost-free explorations that would otherwise be expensive in the real world. To facilitate effective decision-making, world models must be equipped with strong generalizability to support faithful imagination in out-of-distribution (OOD) regions and provide reliable uncertainty estimation to assess the credibility of the simulated experiences, both of which present significant challenges for prior scalable approaches. This paper introduces WHALE, a framework for learning generalizable world models, consisting of two key techniques: behavior-conditioning and retracing-rollout. Behavior-conditioning addresses the policy distribution shift, one of the primary sources of the world model generalization error, while retracing-rollout enables efficient uncertainty estimation without the necessity of model ensembles. These techniques are universal and can be combined with any neural network architecture for world model learning. Incorporating these two techniques, we present Whale-ST, a scalable spatial-temporal transformer-based world model with enhanced generalizability. We demonstrate the superiority of Whale-ST in simulation tasks by evaluating both value estimation accuracy and video generation fidelity. Additionally, we examine the effectiveness of our uncertainty estimation technique, which enhances model-based policy optimization in fully offline scenarios. Furthermore,we propose Whale-X,a 414M parameter world model trained on 970K trajectories from Open X-Embodiment datasets. We show that Whale-X exhibits promising scalability and strong generalizability in real-world manipulation scenarios using minimal demonstrations.
世界模型在具身环境中的决策制定中发挥着至关重要的作用,使得成本高昂的探索变得无成本。为了促进有效的决策制定,世界模型必须具备强大的泛化能力,以支持在分布外(OOD)区域的真实想象,并提供可靠的不确定性估计,以评估模拟体验的可信度,这两者都对之前的可扩展方法提出了重大挑战。本文介绍了WHALE,一个用于学习可泛化世界模型的框架,包含两个关键技术:行为条件化和回溯展开。行为条件化解决了策略分布的变化,这是世界模型泛化误差的主要来源之一,而回溯展开则在不需要模型集成的情况下实现高效的不确定性估计。这些技术是通用的,可以与任何神经网络架构结合用于世界模型学习。结合这两种技术,我们提出了Whale-ST,一个基于空间-时间变换器的可扩展世界模型,具有增强的泛化能力。我们通过评估价值估计准确性和视频生成保真度,展示了Whale-ST在模拟任务中的优越性。此外,我们还考察了我们不确定性估计技术的有效性,该技术增强了完全离线场景中的基于模型的策略优化。此外,我们提出了Whale-X,一个在来自Open X-Embodiment数据集的970K轨迹上训练的414M参数世界模型。我们展示了Whale-X在真实世界操作场景中展现出良好的可扩展性和强大的泛化能力,且仅需最少的演示。
1 Introduction
1 引言
Human beings can envision an imagined world in their minds, predicting how different actions might lead to different outcomes [1, 2]. Inspired by this aspect of human intelligence, world models [3] are designed to abstract real-world dynamics and provide such “what if” prediction. As a result, embodied agents can interact with world models instead of real-world environments to generate simulation data, which can be used for various downstream tasks, including counterfactual prediction [4], off-policy evaluation [5], and offline reinforcement learning [6]. The requirement to facilitate more effective decision-making presents substantial challenges to the generalizability of world models, an issue that previous approaches have not adequately addressed [7]. Additionally, achieving reliable uncertainty estimation for imagined visual experiences remains a significant challenge, impacting the trustworthy utilization of synthetic data in offline policy optimization [8]. These two unresolved issues impede the further success of world models in supporting decision-making.
人类能够在脑海中构想一个想象的世界,预测不同的行动可能导致不同的结果 [1, 2]。受到人类智能这一方面的启发,世界模型 [3] 被设计用来抽象现实世界的动态,并提供这种“如果……会怎样”的预测。因此,具身代理可以与世界模型进行交互,而不是与现实世界环境进行交互,以生成模拟数据,这些数据可以用于各种下游任务,包括反事实预测 [4]、离策略评估 [5] 和离线强化学习 [6]。促进更有效决策的需求对世界模型的可推广性提出了重大挑战,这是以往方法未能充分解决的问题 [7]。此外,实现对想象视觉体验的可靠不确定性估计仍然是一个重大挑战,影响了在离线策略优化中对合成数据的可信利用 [8]。这两个未解决的问题阻碍了世界模型在支持决策方面的进一步成功。
*Equal Contribution
*平等贡献
† {}^{ \dagger } † Corresponding Author
† {}^{ \dagger } † 通讯作者
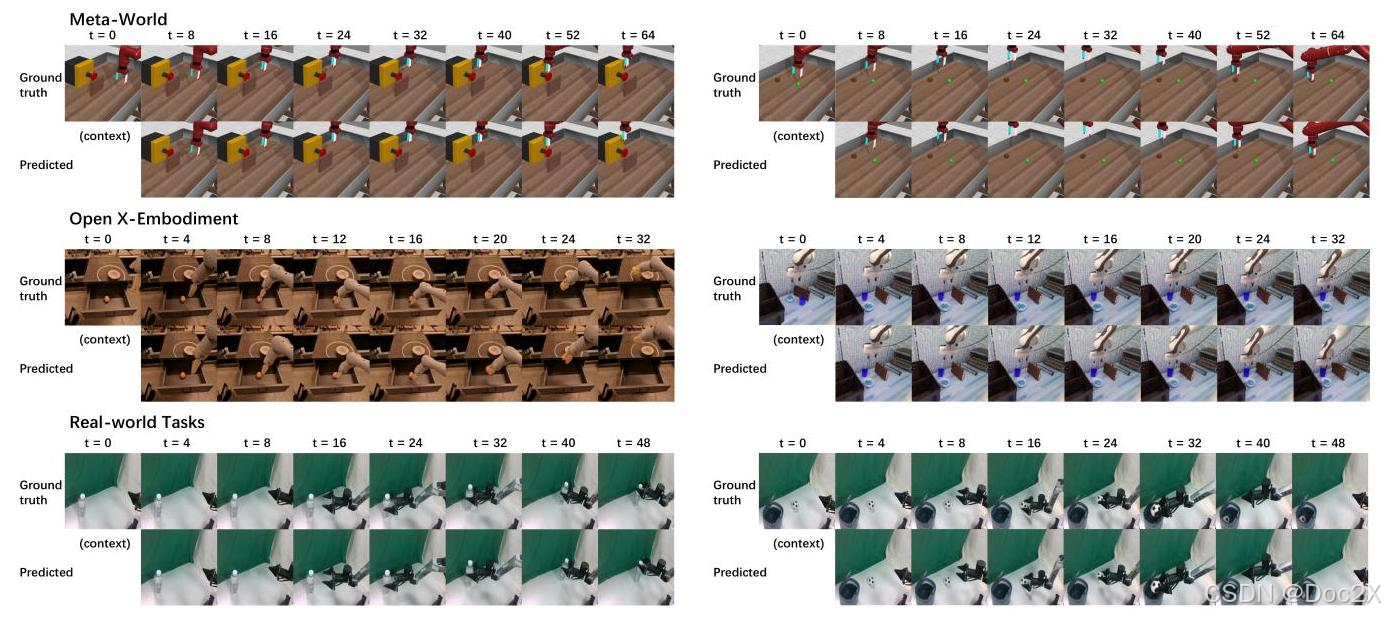
Figure 1: Qualitative evaluation on Meta-World, Open X-Embodiment, and our real-world tasks.
图 1:在 Meta-World、Open X-Embodiment 和我们的现实任务上的定性评估。
In this work, we introduce WHALE (World models with beHavior-conditioning and retrAcing-rollout LEarning), a framework for learning generalizable world models, consisting of two key techniques that can be universally combined with any neural network architecture. First, based on the identification of policy distribution divergence as a primary source of the generalization error, we introduce a behavior-conditioning technique to enhance the generalizability of world models, which builds upon the concept of policy-conditioned model learning [9] aiming to enable the model to adapt to different behaviors actively to mitigate the extrapolation error caused by distribution shift. Furthermore, we propose a simple yet effective technique called retracing-rollout, to enable efficient uncertainty estimation for the model imagination. This approach avoids the necessity of computation-expensive ensembles of the visual world models while providing a reliable uncertainty estimation to facilitate policy optimization in fully offline scenarios. As a plug-and-play solution, the retracing rollout can be efficiently applied to end-effector pose control in various embodiment tasks without necessitating any changes to the training process.
在本研究中,我们介绍了 WHALE(具有行为条件和回溯滚动学习的世界模型),这是一个用于学习可泛化世界模型的框架,包含两种关键技术,可以与任何神经网络架构普遍结合。首先,基于将策略分布偏差识别为泛化误差的主要来源,我们引入了一种行为条件技术,以增强世界模型的泛化能力,该技术建立在策略条件模型学习的概念之上 [9],旨在使模型能够主动适应不同的行为,以减轻由分布变化引起的外推误差。此外,我们提出了一种简单而有效的技术,称为回溯滚动,以实现模型想象的高效不确定性估计。这种方法避免了计算开销大的视觉世界模型集成的必要性,同时提供可靠的不确定性估计,以促进完全离线场景中的策略优化。作为一种即插即用的解决方案,回溯滚动可以高效地应用于各种具身任务中的末端执行器姿态控制,而无需对训练过程进行任何更改。
To implement the WHALE framework, we present Whale-ST, a scalable embodied world model based on the spatial-temporal transformer [10, 11], designed to enable faithful long-horizon imagination for real-world visual control tasks. To substantiate the effectiveness of Whale-ST, we conduct extensive experiments on both simulated Meta-World [12] benchmark and a physical robot platform, encompassing a variety of pixel-based manipulation tasks. Experimental results on the simulated tasks show that Whale-ST outperforms existing world model learning methods in both value estimation accuracy and video generation fidelity. Moreover, we demonstrate that Whale-ST, based on the retracing-rollout technique, effectively captures model prediction error and enhances offline policy optimization using imagined experiences. As a further step, we introduce Whale-X, a 414M-parameter world model trained on 970k real-world demonstrations from Open X-Embodiment datasets [13]. Whale-X serves as a foundational embodied world model for evaluating real-world behaviors. With fine-tuning on a few demonstrations in completely unseen environments and robots, Whale-X demonstrates strong OOD generalizability across visual, motion, and task perspectives. Furthermore, by scaling up the pre-training dataset or model parameters, Whale-X shows impressive scalability during both the pre-training and fine-tuning phases.
为了实现WHALE框架,我们提出了Whale-ST,这是一个基于时空变换器的可扩展体现世界模型 [10, 11],旨在实现对现实世界视觉控制任务的真实长远想象。为了验证Whale-ST的有效性,我们在模拟的Meta-World [12] 基准和一个物理机器人平台上进行了广泛的实验,涵盖了各种基于像素的操作任务。模拟任务的实验结果表明,Whale-ST在价值估计准确性和视频生成保真度方面均优于现有的世界模型学习方法。此外,我们展示了基于回溯展开技术的Whale-ST有效捕捉模型预测误差,并利用想象的经验增强离线策略优化。作为进一步的步骤,我们引入了Whale-X,这是一个在来自Open X-Embodiment数据集的970k真实世界示例上训练的414M参数世界模型 [13]。Whale-X作为评估真实世界行为的基础体现世界模型。通过在完全未见过的环境和机器人上对少量示例进行微调,Whale-X在视觉、运动和任务方面展示了强大的OOD泛化能力。此外,通过扩大预训练数据集或模型参数,Whale-X在预训练和微调阶段均显示出令人印象深刻的可扩展性。
The primary contributions of this work are outlined as follows:
本工作的主要贡献概述如下:
-
We introduce WHALE, a framework for learning generalizable world models, consisting of two key techniques: behavior-conditioning and retracing-rollout, to address two major challenges in the application of world models to decision-making: generalization and uncertainty estimation;
-
我们介绍了WHALE,一个用于学习可泛化世界模型的框架,包含两个关键技术:行为条件化和回溯展开,以解决将世界模型应用于决策中的两个主要挑战:泛化和不确定性估计;
-
By integrating these two techniques from WHALE, we propose Whale-ST, a scalable spatial-temporal transformer-based world model designed for more effective decision-making, and further present Whale-X, a 414M-parameter world model pre-trained on 970K robot demonstrations;
-
通过整合WHALE中的这两项技术,我们提出了Whale-ST,这是一个基于时空变换器的可扩展世界模型,旨在实现更有效的决策,并进一步提出Whale-X,这是一个在970K机器人示例上预训练的414M参数世界模型;
-
We conduct extensive experiments to demonstrate the remarkable scalability and generalizability of Whale-ST and Whale-X across both simulated and real-world tasks, highlighting their efficacy in enhancing decision-making.
-
我们进行广泛的实验,以展示 Whale-ST 和 Whale-X 在模拟和现实任务中的显著可扩展性和普适性,强调它们在增强决策能力方面的有效性。
2 Related Works
2 相关工作
World models have a long research history and recently started to attract significant attention. World models were initially introduced under the name “action models” in simple tasks as components of the decision-making systems [14, 15] and were also referred to as “environment models” [16], “dynamics models” [17, 18], or simply “models” [19] in literature. Since the advent of the neural network era, dynamics models have been more widely applied in deep reinforcement learning algorithms to boost learning efficiency, resulting in a series of model-based reinforcement algorithms [19, 20] 8, 21, 18], while they focused primarily on environment modeling in lower-dimensional proprioceptive state spaces. [3] was the first to propose a general framework for modern world models with high-dimensional visual observations, where a vision module encodes the observed image into a compact latent vector to extract visual information at the current time step and a memory sequence model integrates the historical codes to create a representation that can predict future states. This generic architecture of world models soon achieved a series of notable successes in complex decision-making tasks [22, 23, 24, 25, 26].
世界模型有着悠久的研究历史,最近开始引起广泛关注。世界模型最初以“行动模型”的名称引入,作为决策系统的组成部分,用于简单任务 [14, 15],在文献中也被称为“环境模型” [16]、“动态模型” [17, 18],或简单地称为“模型” [19]。自神经网络时代以来,动态模型在深度强化学习算法中得到了更广泛的应用,以提高学习效率,导致了一系列基于模型的强化算法 [19, 20] 8, 21, 18],而它们主要集中在低维本体状态空间中的环境建模。[3] 首次提出了现代世界模型的通用框架,该框架能够处理高维视觉观测,其中视觉模块将观察到的图像编码为紧凑的潜在向量,以提取当前时间步的视觉信息,而记忆序列模型则整合历史编码以创建能够预测未来状态的表示。这种世界模型的通用架构很快在复杂决策任务中取得了一系列显著成功 [22, 23, 24, 25, 26]。
Despite these successes achieved in world model learning, out-of-distribution generalization remains a fundamental challenge for world models, which has yet to be adequately addressed. In contrast to conventional supervised learning settings with no or mild OOD assumption where the target distribution is similar to the training data distribution, world models answer “what-if” questions: “What will happen in the environment if the agent makes any possible decisions?”, which must be highly out-of-distribution. A potential solution to this generalization issue is collecting a larger amount of data to train large world models. Recently, advanced methods have leveraged modern action-conditioned video prediction models [27,28] to model the visual dynamics and pre-train from large-scale video experience data [11, 29, 30]. Various sophisticated model architectures have been adopted in these methods, including RNNs [31, 22, 32], diffusion models [33, 34], and transformers [35, 36, 11]. Nevertheless, the available training data for model learning are usually collected by expert or near-expert policies, leading to low data coverage in state-action spaces, which poses challenges to reasoning decision outcomes for suboptimal policies in the learned world models [7].
尽管在世界模型学习中取得了这些成功,但分布外泛化仍然是世界模型面临的一个基本挑战,尚未得到充分解决。与没有或轻微分布外假设的传统监督学习设置不同,目标分布与训练数据分布相似,世界模型回答的是“如果”问题:“如果代理做出任何可能的决策,环境将会发生什么?”,这必须是高度分布外的。解决这一泛化问题的一个潜在方案是收集更多的数据来训练大型世界模型。最近,先进的方法利用现代的基于动作的条件视频预测模型 [27,28] 来建模视觉动态,并从大规模视频经验数据 [11, 29, 30] 中进行预训练。这些方法采用了各种复杂的模型架构,包括递归神经网络 [31, 22, 32]、扩散模型 [33, 34] 和变压器 [35, 36, 11]。然而,用于模型学习的可用训练数据通常是由专家或近专家策略收集的,这导致状态-动作空间的数据覆盖率低,这对在学习到的世界模型中推理次优策略的决策结果构成了挑战 [7]。
Another line of work investigates the impact of learning methods on the generalizability of world models. For standard maximum likelihood objectives of single-step transitions, the autoregressive rollout errors or value gaps are linked to in-distribution error and policy divergence and are quadratically amplified by the rollout horizon, a phenomenon known as compounding errors [19, 37, 38]. To overcome the limitations in the standard MLE learning, a series of improvements have been made, including training multi-step models to reduce rollout errors [39, 40], using control objectives to train transition models [41, 42], adversarially training models for counterfactual target policies [4], learning dynamics reward to improve model generalization [43], contrastively learning energy transitions function [44], and incorporating policy information into model inputs to enable test-time model adaptation to target policies [9]. Despite the successes in lower-dimensional proprioceptive observation tasks, scaling these methods to large amounts of high-dimensional visual data remains absent. Introducing advanced learning methods suitable for training large world models with large-scale data to improve model generalizability is of unprecedented importance.
另一项研究工作调查了学习方法对世界模型可泛化性的影响。对于单步转移的标准最大似然目标,自回归展开误差或价值差距与分布内误差和策略发散相关,并且随着展开时间的增加而呈二次放大,这一现象被称为复合误差 [19, 37, 38]。为了克服标准最大似然学习中的局限性,已经进行了一系列改进,包括训练多步模型以减少展开误差 [39, 40],使用控制目标来训练转移模型 [41, 42],对抗性训练模型以应对反事实目标策略 [4],学习动态奖励以提高模型的泛化能力 [43],对比学习能量转移函数 [44],以及将策略信息纳入模型输入,以便在测试时对目标策略进行模型适应 [9]。尽管在低维自我感知观察任务中取得了成功,但将这些方法扩展到大量高维视觉数据仍然缺乏相关研究。引入适合于使用大规模数据训练大型世界模型的先进学习方法,以提高模型的可泛化性,具有前所未有的重要性。
In addition to generalization, another key topic in world models for control is uncertainty estimation. It has been shown that offline decision-making within world models learned from partial-coverage data is vulnerable to the exploitation of model prediction errors [8, 45], which requires quantifying the prediction uncertainty of world models and reminding the agent to keep pessimistic about the model uncertainty [8, 46, 47, 18]. These typical algorithms estimate the model uncertainty via the ensemble of multiple models learned in parallel [48], which is quite computation-consuming, especially for large-scale tasks and models. Recent works [49, 50] adopt the entropy of the categorical token prediction distribution as an uncertainty indicator for large language models (LLMs), though there is limited support for its efficacy in offline model-based control.
除了泛化,控制中世界模型的另一个关键主题是不确定性估计。研究表明,从部分覆盖数据中学习的世界模型中的离线决策容易受到模型预测误差的利用 [8, 45],这需要量化世界模型的预测不确定性,并提醒代理对模型的不确定性保持悲观态度 [8, 46, 47, 18]。这些典型算法通过并行学习的多个模型的集成来估计模型的不确定性 [48],这在计算上相当消耗资源,尤其是在大规模任务和模型中。最近的研究 [49, 50] 将分类标记预测分布的熵作为大型语言模型(LLMs)的不确定性指标,尽管对其在离线基于模型的控制中的有效性支持有限。
3 Foundations of World Model Learning
3 世界模型学习的基础
3.1 Problem Formulation
3.1 问题表述
A typical formulation of sequential decision tasks is the Markov decision process (MDP) [51, 52] specified by the tuple M = ( S , A , r , T ∗ , γ , H , ρ 0 ) \mathcal{M} = \left( {\mathcal{S},\mathcal{A},r,{T}^{ * },\gamma ,H,{\rho }_{0}}\right) M=(S,A,r,T∗,γ,H,ρ0) ,where S \mathcal{S} S is the state space, A \mathcal{A} A is the action space, r ( s , a ) r\left( {s,a}\right) r(s,a) is the reward function, T ∗ ( s ′ ∣ s , a ) {T}^{ * }\left( {{s}^{\prime } \mid s,a}\right) T∗(s′∣s,a) is the real transition probability, γ ∈ ( 0 , 1 ] \gamma \in (0,1\rbrack γ∈(0,1] is the discount factor, H H H is the decision horizon,and ρ 0 ( s ) {\rho }_{0}\left( s\right) ρ0(s) is the initial state distribution. In this work,we simply consider the case where γ = 1 \gamma = 1 γ=1 and H < ∞ H < \infty H<∞ .
顺序决策任务的典型表述是马尔可夫决策过程(MDP)[51, 52],由元组 M = ( S , A , r , T ∗ , γ , H , ρ 0 ) \mathcal{M} = \left( {\mathcal{S},\mathcal{A},r,{T}^{ * },\gamma ,H,{\rho }_{0}}\right) M=(S,A,r,T∗,γ,H,ρ0) 指定,其中 S \mathcal{S} S 是状态空间, A \mathcal{A} A 是动作空间, r ( s , a ) r\left( {s,a}\right) r(s,a) 是奖励函数, T ∗ ( s ′ ∣ s , a ) {T}^{ * }\left( {{s}^{\prime } \mid s,a}\right) T∗(s′∣s,a) 是实际转移概率, γ ∈ ( 0 , 1 ] \gamma \in (0,1\rbrack γ∈(0,1] 是折扣因子, H H H 是决策视野,而 ρ 0 ( s ) {\rho }_{0}\left( s\right) ρ0(s) 是初始状态分布。在本研究中,我们简单地考虑 γ = 1 \gamma = 1 γ=1 和 H < ∞ H < \infty H<∞ 的情况。
In reinforcement learning [53], the objective is to learn a policy that maximizes the expected return in the MDP, which involves estimating the value of different policies. Specifically,the value of policy π \pi π is defined as: where the state-action trajectory τ H = ( s 1 , a 1 , … , s H , a H ) {\tau }_{H} = \left( {{s}_{1},{a}_{1},\ldots ,{s}_{H},{a}_{H}}\right) τH=(s1,a1,…,sH,aH) and rewards are generated by the rollouts of policy π \pi π within the dynamics T ∗ {T}^{ * } T∗ . A common scenario involves abundant pre-collected experience data,but direct interaction with the environment is either prohibited or costly, necessitating value estimation to be performed offline.
在强化学习 [53] 中,目标是学习一个策略,以最大化 MDP 中的期望回报,这涉及到对不同策略的价值进行估计。具体而言,策略 π \pi π 的价值定义为:其中状态-动作轨迹 τ H = ( s 1 , a 1 , … , s H , a H ) {\tau }_{H} = \left( {{s}_{1},{a}_{1},\ldots ,{s}_{H},{a}_{H}}\right) τH=(s1,a1,…,sH,aH) 和奖励是通过策略 π \pi π 在动态 T ∗ {T}^{ * } T∗ 中的展开生成的。一个常见的场景是拥有大量预先收集的经验数据,但与环境的直接交互要么被禁止,要么成本高昂,因此需要离线进行价值估计。
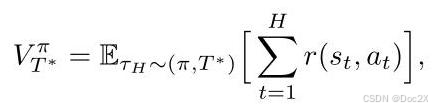
An environment model T T T can be explicitly learned from the offline data to imitate the real state transition T ∗ {T}^{ * } T∗ , synthesizing imaginary experiences to simulate real environment interactions. For visual observation tasks, the agent cannot directly observe the states; instead,it receives high-dimensional images within the observation space O \mathcal{O} O ,which normally introduces redundant information and partial observability. The visual world models [3] usually learn a vision module E θ : O → S {E}_{\theta } : \mathcal{O} \rightarrow \mathcal{S} Eθ:O→S to extract a compressed representation z t = E θ ( o t ) {z}_{t} = {E}_{\theta }\left( {o}_{t}\right) zt=Eθ(ot) from the current frame observation o t {o}_{t} ot ,and use a sequence model to integrate the latent representations z 1 : t {z}_{1 : t} z1:t from past frames as well as actions a 1 : t {a}_{1 : t} a1:t to overcome the partial observability for future prediction. This architecture of world models empowers autoregressive imagination for any given policy, which enables policy evaluation and improvement without real-world interactions.
环境模型 T T T 可以从离线数据中明确学习,以模仿真实状态转移 T ∗ {T}^{ * } T∗,合成虚拟经验以模拟真实环境交互。对于视觉观察任务,代理无法直接观察状态;相反,它在观察空间 O \mathcal{O} O 中接收高维图像,这通常引入冗余信息和部分可观察性。视觉世界模型 [3] 通常学习一个视觉模块 E θ : O → S {E}_{\theta } : \mathcal{O} \rightarrow \mathcal{S} Eθ:O→S,从当前帧观察 o t {o}_{t} ot 中提取压缩表示 z t = E θ ( o t ) {z}_{t} = {E}_{\theta }\left( {o}_{t}\right) zt=Eθ(ot),并使用序列模型整合来自过去帧及其动作 a 1 : t {a}_{1 : t} a1:t 的潜在表示 z 1 : t {z}_{1 : t} z1:t,以克服部分可观察性进行未来预测。这种世界模型的架构赋予了自回归想象能力,适用于任何给定策略,使得在没有真实世界交互的情况下进行策略评估和改进成为可能。
Assume that V T π {V}_{T}^{\pi } VTπ is the value estimated within the model T T T ,the environment model error induces a value gap ∣ V T ∗ π − V T π ∣ \left| {{V}_{{T}^{ * }}^{\pi } - {V}_{T}^{\pi }}\right| ∣VT∗π−VTπ∣ for the policy π \pi π . If the model is globally accurate,the value gap will diminish for any policy. However,offline experiences are often collected by a narrow range of policies (e.g., near-expert policies). Therefore, the learned environment models are likely unfamiliar with the outcomes of novel decision patterns and are expected to generalize beyond the training experiences for counterfactual reasoning to evaluate diverse policies.
假设 V T π {V}_{T}^{\pi } VTπ 是模型中估计的值 T T T,环境模型误差会导致策略 π \pi π 的值差距 ∣ V T ∗ π − V T π ∣ \left| {{V}_{{T}^{ * }}^{\pi } - {V}_{T}^{\pi }}\right| ∣VT∗π−VTπ∣。如果模型是全局准确的,则对于任何策略,值差距将会减小。然而,离线经验通常是通过狭窄范围的策略(例如,接近专家的策略)收集的。因此,学习到的环境模型可能对新决策模式的结果不熟悉,并且预计会超出训练经验进行推广,以进行反事实推理以评估多样化的策略。
3.2 Generalizability of World Models
3.2 世界模型的可推广性
The common learning methods for world models regard the transition learning as a standard supervised learning problem, minimizing the negative log-likelihood (NLL) of the single-step transition probabilities over the pre-collected trajectories in a teacher-forcing manner, i.e.,
世界模型的常见学习方法将转移学习视为标准的监督学习问题,通过教师强制方式最小化在预收集轨迹上的单步转移概率的负对数似然(NLL),即,
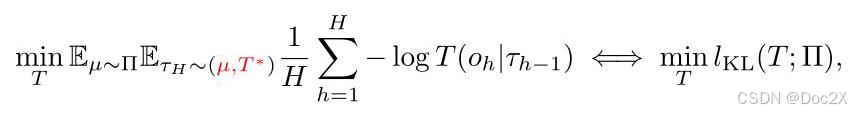
where (sub-)trajectory τ h = ( o 1 , a 1 , o 2 , … , o h , a h ) , 1 ≤ h ≤ H {\tau }_{h} = \left( {{o}_{1},{a}_{1},{o}_{2},\ldots ,{o}_{h},{a}_{h}}\right) ,1 \leq h \leq H τh=(o1,a1,o2,…,oh,ah),1≤h≤H is generated by interaction of a behavior policy μ \mu μ with the real dynamics T ∗ {T}^{ * } T∗ ,and behavior μ \mu μ is assumed to be sampled from a behavior policy distribution Π \Pi Π . Minimizing the NLL equals minimizing the KL divergence loss l K L ( T ; Π ) = E μ ∼ Π E τ H ∼ ( μ , T ∗ ) 1 H ∑ h = 1 H D K L ( T ∗ ( ⋅ ∣ τ h − 1 ) , T ( ⋅ ∣ τ h − 1 ) ) {l}_{\mathrm{{KL}}}\left( {T;\Pi }\right) = {\mathbb{E}}_{\mu \sim \Pi }{\mathbb{E}}_{{\tau }_{H} \sim \left( {\mu ,{T}^{ * }}\right) }\frac{1}{H}\mathop{\sum }\limits_{{h = 1}}^{H}{D}_{\mathrm{{KL}}}\left( {{T}^{ * }\left( {\cdot \mid {\tau }_{h - 1}}\right) ,T\left( {\cdot \mid {\tau }_{h - 1}}\right) }\right) lKL(T;Π)=Eμ∼ΠEτH∼(μ,T∗)H1h=1∑HDKL(T∗(⋅∣τh−1),T(⋅∣τh−1)) . The learned world models are usually utilized to evaluate any target policy π \pi π by simulating trajectories in an autoregressive manner:
其中(子)轨迹 τ h = ( o 1 , a 1 , o 2 , … , o h , a h ) , 1 ≤ h ≤ H {\tau }_{h} = \left( {{o}_{1},{a}_{1},{o}_{2},\ldots ,{o}_{h},{a}_{h}}\right) ,1 \leq h \leq H τh=(o1,a1,o2,…,oh,ah),1≤h≤H 是通过行为策略 μ \mu μ 与真实动态 T ∗ {T}^{ * } T∗ 的交互生成的,并且假设行为 μ \mu μ 是从行为策略分布 Π \Pi Π 中采样的。最小化 NLL 等同于最小化 KL 散度损失 l K L ( T ; Π ) = E μ ∼ Π E τ H ∼ ( μ , T ∗ ) 1 H ∑ h = 1 H D K L ( T ∗ ( ⋅ ∣ τ h − 1 ) , T ( ⋅ ∣ τ h − 1 ) ) {l}_{\mathrm{{KL}}}\left( {T;\Pi }\right) = {\mathbb{E}}_{\mu \sim \Pi }{\mathbb{E}}_{{\tau }_{H} \sim \left( {\mu ,{T}^{ * }}\right) }\frac{1}{H}\mathop{\sum }\limits_{{h = 1}}^{H}{D}_{\mathrm{{KL}}}\left( {{T}^{ * }\left( {\cdot \mid {\tau }_{h - 1}}\right) ,T\left( {\cdot \mid {\tau }_{h - 1}}\right) }\right) lKL(T;Π)=Eμ∼ΠEτH∼(μ,T∗)H1h=1∑HDKL(T∗(⋅∣τh−1),T(⋅∣τh−1))。学习到的世界模型通常用于通过自回归方式模拟轨迹来评估任何目标策略 π \pi π:
where the trajectory simulation distribution deviates from the training distribution.
其中轨迹模拟分布偏离训练分布。
In classical sequential modeling tasks like sentence generation and translation, the distribution shift from teacher-forcing training to autoregressive generation diminishes as the model accuracy improves, which therefore does not lead to significant negative impacts. For world model learning, however, the distribution shift results from both the model prediction inaccuracy and the divergence between the target policy and behavior policies, exacerbating the evaluation inaccuracy:
在经典的顺序建模任务中,如句子生成和翻译,从教师强制训练到自回归生成的分布转变随着模型准确性的提高而减小,因此不会导致显著的负面影响。然而,对于世界模型学习而言,分布转变既源于模型预测的不准确性,也源于目标策略与行为策略之间的差异,从而加剧了评估的不准确性:
where a distribution shift term induced by the policy divergence 3 {}^{3} 3 occurs in addition to the KL training loss,further amplified by an H 2 {H}^{2} H2 factor caused by the supervised teacher-forcing learning. Even if the world model perfectly models the training distribution,i.e. l K L ( T ; Π ) = 0 {l}_{\mathrm{{KL}}}\left( {T;\Pi }\right) = 0 lKL(T;Π)=0 ,the variation of the target policies could also significantly shift the trajectory simulation distribution to those large error areas, resulting in degenerative generalizability.
其中,由策略差异引起的分布转变项 3 {}^{3} 3 除了 KL 训练损失外,还受到由监督教师强制学习引起的 H 2 {H}^{2} H2 因子的进一步放大。即使世界模型完美地建模了训练分布,即 l K L ( T ; Π ) = 0 {l}_{\mathrm{{KL}}}\left( {T;\Pi }\right) = 0 lKL(T;Π)=0,目标策略的变化也可能显著地将轨迹模拟分布转移到那些大误差区域,导致退化的泛化能力。
The generalization issue of world model learning has been noticed as a severe challenge even when large expert training data is available [7]. Previously, solutions have been proposed.
世界模型学习的泛化问题已被认为是一个严重的挑战,即使在有大量专家训练数据的情况下 [7]。之前已经提出了解决方案。
-
Replacing the teacher-forcing objective by the distribution matching solves the compounding error [37], which reduces the term H 2 {H}^{2} H2 to H H H .
-
通过分布匹配替代教师强制目标解决了复合误差 [37],这将项 H 2 {H}^{2} H2 减少为 H H H。
3 {}^{3} 3 Here W 1 ( d π , d Π ) {W}_{1}\left( {{d}^{\pi },{d}^{\Pi }}\right) W1(dπ,dΠ) is the Wasserstein-1 distance between the π \pi π -induced trajectory distribution d π ( τ ) {d}^{\pi }\left( \tau \right) dπ(τ) and the behavior trajectory distribution d Π ( τ ) = E μ ∼ Π [ d μ ( τ ) ] {d}^{\Pi }\left( \tau \right) = {\mathbb{E}}_{\mu \sim \Pi }\left\lbrack {{d}^{\mu }\left( \tau \right) }\right\rbrack dΠ(τ)=Eμ∼Π[dμ(τ)] ,and L L L is the Lipschitz constant of model loss w.r.t. the trajectory,adapted from [9].
3 {}^{3} 3 这里 W 1 ( d π , d Π ) {W}_{1}\left( {{d}^{\pi },{d}^{\Pi }}\right) W1(dπ,dΠ) 是由 π \pi π 诱导的轨迹分布 d π ( τ ) {d}^{\pi }\left( \tau \right) dπ(τ) 和行为轨迹分布 d Π ( τ ) = E μ ∼ Π [ d μ ( τ ) ] {d}^{\Pi }\left( \tau \right) = {\mathbb{E}}_{\mu \sim \Pi }\left\lbrack {{d}^{\mu }\left( \tau \right) }\right\rbrack dΠ(τ)=Eμ∼Π[dμ(τ)] 之间的 Wasserstein-1 距离,而 L L L 是相对于轨迹的模型损失的 Lipschitz 常数,改编自 [9]。
—— 更多内容请到Doc2X翻译查看——
—— For more content, please visit Doc2X for translations ——


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









