







Doc2X:高效代码提取工具
从 PDF 中快速提取代码块,并转换为 Markdown 或 HTML,便于开发与交流。
Doc2X: Efficient Code Extraction Tool
Quickly extract code blocks from PDFs and convert them into Markdown or HTML for seamless development and sharing.
👉 了解更多 Doc2X | Learn More About Doc2X
原文链接:https://arxiv.org/pdf/2410.08593
VERIFIED: A Video Corpus Moment Retrieval Benchmark for Fine-Grained Video Understanding
验证:用于细粒度视频理解的帧检索基准
Houlun Chen 1 {}^{1} 1 , Xin Wang 1 , 2 ∗ {}^{1,2 * } 1,2∗ , Hong Chen 1 {}^{1} 1 , Zeyang Zhang 1 {}^{1} 1 Wei Feng 1 {}^{1} 1 , Bin Huang 1 {}^{1} 1 , Jia Jia 1 , 2 ∗ {}^{1,2 * } 1,2∗ , Wenwu Zhu 1 , 2 ∗ {}^{1,2 * } 1,2∗
陈厚伦 1 {}^{1} 1、王鑫 1 , 2 ∗ {}^{1,2 * } 1,2∗、陈宏 1 {}^{1} 1、张泽宇 1 {}^{1} 1、冯伟 1 {}^{1} 1、黄斌 1 {}^{1} 1、贾佳 1 , 2 ∗ {}^{1,2 * } 1,2∗、朱文武 1 , 2 ∗ {}^{1,2 * } 1,2∗
1 {}^{1} 1 Department of Computer Science and Technology,Tsinghua University,Beijing,China 2 {}^{2} 2 BNRIST,Tsinghua University,Beijing,China
1 {}^{1} 1 清华大学计算机科学与技术系,北京,中国 2 {}^{2} 2 清华大学BNRIST,北京,中国
{chenh123,h-chen20,zy-zhang20,fw22,huangb23}@mails.tsinghua.edu.cn {xin_wang,jjia,wwzhu}@tsinghua.edu.cn
{chenh123,h-chen20,zy-zhang20,fw22,huangb23}@mails.tsinghua.edu.cn {xin_wang,jjia,wwzhu}@tsinghua.edu.cn
Abstract
摘要
Existing Video Corpus Moment Retrieval (VCMR) is limited to coarse-grained understanding, which hinders precise video moment localization when given fine-grained queries. In this paper, we propose a more challenging fine-grained VCMR benchmark requiring methods to localize the best-matched moment from the corpus with other partially matched candidates. To improve the dataset construction efficiency and guarantee high-quality data annotations, we propose VERIFIED, an automatic VidEo-text annotation pipeline to generate captions with RelIable FInE-grained statics and Dynamics. Specifically, we resort to large language models (LLM) and large multimodal models (LMM) with our proposed Statics and Dynamics Enhanced Captioning modules to generate diverse fine-grained captions for each video. To filter out the inaccurate annotations caused by the LLM hallucination, we propose a Fine-Granularity Aware Noise Evaluator where we fine-tune a video foundation model with disturbed hard-negatives augmented contrastive and matching losses. With VERIFIED, we construct a more challenging fine-grained VCMR benchmark containing Charades-FIG, DiDeMo-FIG, and ActivityNet-FIG which demonstrate a high level of annotation quality. We evaluate several state-of-the-art VCMR models on the proposed dataset, revealing that there is still significant scope for fine-grained video understanding in VCMR. Code and Datasets are in https://github.com/hlchen23/VERIFIED
现有的视频语料库时刻检索(VCMR)局限于粗粒度的理解,这阻碍了在给定细粒度查询时进行精确的视频时刻定位。在本文中,我们提出了一个更具挑战性的细粒度VCMR基准,要求方法从语料库中定位最佳匹配的时刻,同时排除其他部分匹配的候选者。为了提高数据集构建效率并保证高质量的数据标注,我们提出了VERIFIED,一种自动化的视频-文本标注流水线,用于生成具有可靠细粒度静态和动态统计的标注。具体而言,我们借助大型语言模型(LLM)和大型多模态模型(LMM),结合我们提出的静态和动态增强标注模块,为每个视频生成多样化的细粒度标注。为了过滤掉由LLM幻觉引起的不准确标注,我们提出了一个细粒度感知噪声评估器,通过使用增强的对比和匹配损失对视频基础模型进行微调,并引入扰动的硬负样本。通过VERIFIED,我们构建了一个更具挑战性的细粒度VCMR基准,包含Charades-FIG、DiDeMo-FIG和ActivityNet-FIG,这些基准展示了高水平的标注质量。我们在提出的数据集上评估了几种最先进的VCMR模型,揭示了在VCMR中细粒度视频理解仍有显著的提升空间。代码和数据集可在https://github.com/hlchen23/VERIFIED获取。
1 Introduction
1 引言
Video Corpus Moment Retrieval (VCMR) [1] aims to retrieve a video moment from a large untrimmed video corpus given a text query. It requires handling two subtasks: Video Retrieval (VR) [2] from a corpus and Single Video Moment Retreival (SVMR) [3, 4] within a video, which involves grasping multi-level semantic granularities across video-text and moment-text alignment. However, as shown in Figure 1(a), in the previous VCMR setting, the queries are usually coarse-grained and thus struggle to localize a video moment discriminatively, where there exists potentially relevant positive pairs [5]- [7] besides the ground truth, which hinders cross-modal retrieval and makes it hard for models to learn distinctive video features.
视频语料库时刻检索 (VCMR) [1] 旨在根据文本查询从大型未修剪视频语料库中检索视频时刻。它需要处理两个子任务:从语料库中进行视频检索 (VR) [2] 和在单个视频中进行视频时刻检索 (SVMR) [3, 4],这涉及在视频-文本和时刻-文本对齐中掌握多层次的语义粒度。然而,如图 1(a) 所示,在之前的 VCMR 设置中,查询通常是粗粒度的,因此难以区分性地定位视频时刻,其中除了真实标注外,还存在潜在的相关正样本对 [5]- [7],这阻碍了跨模态检索,并使得模型难以学习到独特的视频特征。
To address the problem, we propose a more challenging VCMR scenario in this paper. As shown in Fig 1(b), a fine-grained distinctive query is provided to retrieve the best-matched moment, requiring models to precisely understand the details in text descriptions and distinguish the target moments from
为了解决这个问题,我们在本文中提出了一个更具挑战性的 VCMR 场景。如图 1(b) 所示,提供了一个细粒度的独特查询来检索最佳匹配的时刻,要求模型精确理解文本描述中的细节,并从
*Corresponding authors.
*通讯作者。

© Our VERIFIED annotations
© 我们的 VERIFIED 标注
Figure 1: (a) Previous VCMR, where a query may be coarse and there are many potential positive moments (green) that are not annotated, making the ground truth annotations unreasonable. (b) Our Challenging Fine-Grained VCMR, where a more fine-grained query is given and the method needs to retrieve the best matched one from partially matched candidates (pink). © Our VERIFIED pipeline generates fine-grained annotations with reliable static (green) and dynamic (blue) details.
图 1:(a) 之前的 VCMR,其中查询可能是粗粒度的,并且存在许多未标注的潜在正样本时刻(绿色),使得真实标注不合理。(b) 我们的挑战性细粒度 VCMR,其中给出了更细粒度的查询,方法需要从部分匹配的候选者(粉色)中检索最佳匹配的时刻。© 我们的 VERIFIED 流程生成了具有可靠静态(绿色)和动态(蓝色)细节的细粒度标注。
partially matched candidates. However, annotating such fine-grained video-text datasets [8-11] relies on intensive manual work and domain knowledge, limiting its productivity and scalability. Therefore, we resort to the power of recent large language model (LLM) and large multimodal model (LMM) [12]- 16 for automatic detailed video-clip annotation. Simply relying on the LLMs/LMMs for annotation faces the following two challenges: 1) how to extract as much fine-grained information from videos as possible remains unexplored, especially dynamic video details; 2) LLM or LMM are known to struggle with the hallucination problem, how to avoid the impact of the generated inaccurate content is also challenging.
然而,注释这种细粒度的视频-文本数据集 [8-11] 依赖于大量的手动工作和领域知识,限制了其生产力和可扩展性。因此,我们求助于最近的大型语言模型(LLM)和大型多模态模型(LMM)[12]-16 来自动进行详细的视频片段注释。仅仅依赖 LLM/LMM 进行注释面临以下两个挑战:1)如何从视频中提取尽可能多的细粒度信息仍然未被探索,尤其是动态视频细节;2)LLM 或 LMM 已知存在幻觉问题,如何避免生成的不准确内容的影响也是一个挑战。
To tackle these challenges, we propose VERIFIED, an automatic VidEo-text annotation pipeline to generate captions with RelIable FInE-grained statics and Dynamics. To fully utilize fine-grained visual content, we design the Statics and Dynamics Enhanced Captioning modules. Specifically, for statics, we extract foreground and background attributes with image LMM and form several statics enhanced caption candidates via LLM rewriting. For dynamics, we propose a VQA-guided dynamic detail discovering method, which guides the video LMM to focus more on dynamic changes in the video, before having LLM rewrite dynamics enhanced captions. To alleviate the impact of the inaccurate annotations caused by LLM/LMM hallucinations, we propose a Fine-Granularity Aware Noise Evaluator where we fine-tune a video foundation model [17] with disturbed hard-negative data through contrastive and matching losses, so that it can better discriminate the unreasonable annotations. We apply it to evaluate each generated video-text pair, which helps to filter out inaccurate annotations.
为了应对这些挑战,我们提出了 VERIFIED,这是一个自动的视频-文本注释管道,用于生成具有可靠细粒度静态和动态描述的标题。为了充分利用细粒度的视觉内容,我们设计了静态和动态增强的标题生成模块。具体来说,对于静态部分,我们使用图像 LMM 提取前景和背景属性,并通过 LLM 重写形成多个静态增强的标题候选。对于动态部分,我们提出了一种 VQA 引导的动态细节发现方法,该方法引导视频 LMM 更多地关注视频中的动态变化,然后在 LLM 重写动态增强的标题之前。为了缓解由 LLM/LMM 幻觉引起的不准确注释的影响,我们提出了一个细粒度感知噪声评估器,其中我们通过对比和匹配损失对视频基础模型 [17] 进行微调,使用扰动的硬负数据,使其能够更好地辨别不合理的注释。我们将其应用于评估每个生成的视频-文本对,以帮助过滤出不准确的注释。
We construct our benchmark based on the widely adopted VCMR datasets with our VERIFIED pipeline, including Charades-STA [3], DiDeMo [4], and ActivityNet Captions [18]. As shown in Fig 1©, we obtain fine-grained Charades-FIG, DiDeMo-FIG, and ActivityNet-FIG to better support fine-grained VCMR, which demonstrate a high level of annotation quality. Compared to previous ones, our benchmark significantly reduces the many-to-many situations, offering more precise ground truth annotations. We evaluate several state-of-the-art VCMR models on our benchmark, and the results show that models trained on previous datasets show poor performance on the fine-grained VCMR task, while our proposed training dataset significantly improves its performance. We believe this benchmark will inspire a lot of future work for fine-grained video understanding in VCMR.
我们基于广泛采用的VCMR数据集构建了我们的基准,包括Charades-STA [3]、DiDeMo [4]和ActivityNet Captions [18],并通过我们的VERIFIED管道进行处理。如图1©所示,我们获得了细粒度的Charades-FIG、DiDeMo-FIG和ActivityNet-FIG,以更好地支持细粒度的VCMR,这些数据集展示了高水平的注释质量。与之前的基准相比,我们的基准显著减少了多对多情况,提供了更精确的地面真值注释。我们在我们的基准上评估了几种最先进的VCMR模型,结果显示,在之前的训练数据集上训练的模型在细粒度VCMR任务上的表现较差,而我们提出的训练数据集显著提高了其性能。我们相信这个基准将激发未来在VCMR中进行细粒度视频理解的大量工作。
Our contributions can be summarized as follows:
我们的贡献可以总结如下:
-
We first define a more challenging fine-grained VCMR setting, which requires models to understand video fine-grained information precisely and learn distinctive video features.
-
我们首先定义了一个更具挑战性的细粒度VCMR设置,这要求模型精确理解视频的细粒度信息并学习独特的视频特征。
-
We propose an automatic fine-grained video clip annotation pipeline, VERIFIED, aided by LLMs/LMMs, which fully captions fine-grained statics and dynamics in visual content, demonstrating high annotation quality.
-
我们提出了一种自动细粒度视频片段注释管道VERIFIED,该管道由LLMs/LMMs辅助,能够全面描述视觉内容中的细粒度静态和动态信息,展示了高注释质量。
-
We evaluate several state-of-the-art VCMR models on our benchmarks to analyze their ability to localize fine-grained queries among large video corpus, indicating several important challenges and future directions.
-
我们在我们的基准上评估了几种最先进的VCMR模型,以分析它们在大规模视频语料库中定位细粒度查询的能力,指出了几个重要的挑战和未来方向。
2 Related Works
2 相关工作
Video Annotation through Multimodal Models. Most video-text datasets heavily rely on manual work and domain knowledge, especially for fine-grained details [8-11], limiting their scalability, particularly in video moment datasets [3, 18, 4]. Others construct large-scale datasets via web crawling [19] or ASR [20], but suffer from noisy cross-modal alignment. With the rapid advancement of multimodal foundation models and LLM, automatically annotating large-scale video-text datasets is becoming feasible [21]. InternVid [22] integrates image captioning models to caption video clips at multiple scales, while Panda-70M [23] uses multimodal teacher models to caption 70M text-annotated videos. MVid [24] automatically captions visual, audio, and speech with LLM refinement. However, they often lack fine-grained annotations, especially for dynamic details such as motions and interactions, or rely mainly on subtitles or auxiliary text labels [25]. To address this, we propose VERIFIED to automatically capture fine-grained static and dynamic details from the vision modality with quality management.
通过多模态模型进行视频标注。大多数视频-文本数据集严重依赖人工工作和领域知识,尤其是对于细粒度细节 [8-11],这限制了它们的可扩展性,特别是在视频时刻数据集 [3, 18, 4] 中。其他数据集通过网络爬取 [19] 或自动语音识别(ASR)[20] 构建大规模数据集,但存在跨模态对齐噪声的问题。随着多模态基础模型和大型语言模型(LLM)的快速发展,自动标注大规模视频-文本数据集正变得可行 [21]。InternVid [22] 集成了图像字幕模型,以在多个尺度上为视频片段生成字幕,而 Panda-70M [23] 使用多模态教师模型为 70M 个带有文本标注的视频生成字幕。MVid [24] 自动为视觉、音频和语音生成字幕,并通过 LLM 进行细化。然而,它们通常缺乏细粒度的标注,尤其是对于动态细节,如运动和交互,或者主要依赖于字幕或辅助文本标签 [25]。为了解决这一问题,我们提出了 VERIFIED,以自动捕捉视觉模态中的细粒度静态和动态细节,并进行质量管理。
Video Corpus Moment Retrieval. Video moment retrieval (VMR) [3, 4, 26-37] requires localizing a matched moment within an untrimmed video for a text query and video corpus moment retrieval (VCMR) [1] extends VMR to search the target moment from a large untrimmed video corpus, requiring appropriate integration of video retrieval and moment localization. Among VCMR methods, XML [25] introduces a convolutional start-end detector with its late fusion design. CONQUER [38] integrates query context into video representation learning for enhanced moment retrieval by two stages. ReLoCLNet [39] leverages video and frame contrastive learning through separate encoder alignment. As video corpora expand, many video moments share similar semantics with subtle differences in fine-grained statics and dynamics. While some VCMR works [5-7] have explored relevance within non-ground-truth moments and texts by pseudo-positive labels or relevance-based margin, they fail to learn distinctive differences among semantically analogous clips. To address this, we propose a fine-grained VCMR scenario that requires localizing the best-matched moment among partially matched candidates for a fine-grained text query and we introduce new datasets to benchmark state-of-the-art VCMR methods.
视频语料库时刻检索。视频时刻检索(VMR)[3, 4, 26-37] 需要在一个未修剪的视频中定位与文本查询匹配的时刻,而视频语料库时刻检索(VCMR)[1] 则扩展了 VMR,使其能够从大型未修剪视频语料库中搜索目标时刻,这需要适当整合视频检索和时刻定位。在 VCMR 方法中,XML [25] 引入了一种卷积起止检测器及其后期融合设计。CONQUER [38] 通过两个阶段将查询上下文整合到视频表示学习中,以增强时刻检索。ReLoCLNet [39] 通过单独的编码器对齐来利用视频和帧的对比学习。随着视频语料库的扩展,许多视频时刻在细粒度的静态和动态上存在细微差异,但具有相似的语义。尽管一些 VCMR 工作 [5-7] 通过伪正标签或基于相关性的边际探索了非真实时刻和文本之间的相关性,但它们未能学习到语义相似片段之间的显著差异。为此,我们提出了一种细粒度 VCMR 场景,该场景要求在细粒度文本查询的部分匹配候选中定位最佳匹配时刻,并引入了新的数据集来基准测试最先进的 VCMR 方法。
3 Dataset Construction Methodology: VERIFIED
3 数据集构建方法:已验证
In this section, we introduce our VERIFIED pipeline to annotate fine-grained captions for video moments with reliable static and dynamic details. The annotations in the previous video moment datasets are in the form of ( V , t s , t e , q ) \left( {V,{t}_{s},{t}_{e},q}\right) (V,ts,te,q) for a moment V [ t s : t e ] V\left\lbrack {{t}_{s} : {t}_{e}}\right\rbrack V[ts:te] (designated as v v v ) from t s {t}_{s} ts to t e {t}_{e} te seconds in the video V V V ,where q q q is a moment-level text caption for moment v v v . In this paper, our VERIFIED pipeline constructs novel fine-grained video moment datasets in the form of ( V , t s , t e , { q i ( s ) } i = 1 N s , { c i ( s ) } i = 1 N s , { q i ( d ) } i = 1 N d , { c i ( d ) } i = 1 N d ) \left( {V,{t}_{s},{t}_{e},{\left\{ {q}_{i}^{\left( s\right) }\right\} }_{i = 1}^{{N}_{s}},{\left\{ {c}_{i}^{\left( s\right) }\right\} }_{i = 1}^{{N}_{s}},{\left\{ {q}_{i}^{\left( d\right) }\right\} }_{i = 1}^{{N}_{d}},{\left\{ {c}_{i}^{\left( d\right) }\right\} }_{i = 1}^{{N}_{d}}}\right) (V,ts,te,{qi(s)}i=1Ns,{ci(s)}i=1Ns,{qi(d)}i=1Nd,{ci(d)}i=1Nd) . We annotate the same video moment in the previous dataset with multiple diverse captions containing rich static and dynamic fine-grained information. { q i ( s ) } i = 1 N s {\left\{ {q}_{i}^{\left( s\right) }\right\} }_{i = 1}^{{N}_{s}} {qi(s)}i=1Ns and { q i ( d ) } i = 1 N d {\left\{ {q}_{i}^{\left( d\right) }\right\} }_{i = 1}^{{N}_{d}} {qi(d)}i=1Nd are for fine-grained static and dynamic captions,respectively, with confidence scores { c i ( s ) } i = 1 N s {\left\{ {c}_{i}^{\left( s\right) }\right\} }_{i = 1}^{{N}_{s}} {ci(s)}i=1Ns and { c i ( d ) } i = 1 N d {\left\{ {c}_{i}^{\left( d\right) }\right\} }_{i = 1}^{{N}_{d}} {ci(d)}i=1Nd . Captions within { q i ( s ) } i = 1 N s {\left\{ {q}_{i}^{\left( s\right) }\right\} }_{i = 1}^{{N}_{s}} {qi(s)}i=1Ns or { q i ( d ) } i = 1 N d {\left\{ {q}_{i}^{\left( d\right) }\right\} }_{i = 1}^{{N}_{d}} {qi(d)}i=1Nd share nearly identical coarse semantics yet they may exhibit distinct fine-grained static or dynamic details.
在本节中,我们介绍了我们的 VERIFIED 流水线,用于为视频片段注释具有可靠静态和动态细节的细粒度字幕。先前视频片段数据集中的注释形式为 ( V , t s , t e , q ) \left( {V,{t}_{s},{t}_{e},q}\right) (V,ts,te,q),用于视频中从 t s {t}_{s} ts 到 t e {t}_{e} te 秒的片段 V [ t s : t e ] V\left\lbrack {{t}_{s} : {t}_{e}}\right\rbrack V[ts:te](指定为 v v v),其中 q q q 是片段 v v v 的片段级文本字幕。在本文中,我们的 VERIFIED 流水线构建了形式为 ( V , t s , t e , { q i ( s ) } i = 1 N s , { c i ( s ) } i = 1 N s , { q i ( d ) } i = 1 N d , { c i ( d ) } i = 1 N d ) \left( {V,{t}_{s},{t}_{e},{\left\{ {q}_{i}^{\left( s\right) }\right\} }_{i = 1}^{{N}_{s}},{\left\{ {c}_{i}^{\left( s\right) }\right\} }_{i = 1}^{{N}_{s}},{\left\{ {q}_{i}^{\left( d\right) }\right\} }_{i = 1}^{{N}_{d}},{\left\{ {c}_{i}^{\left( d\right) }\right\} }_{i = 1}^{{N}_{d}}}\right) (V,ts,te,{qi(s)}i=1Ns,{ci(s)}i=1Ns,{qi(d)}i=1Nd,{ci(d)}i=1Nd) 的新型细粒度视频片段数据集。我们对先前数据集中的同一视频片段进行多次多样化的字幕注释,包含丰富的静态和动态细粒度信息。 { q i ( s ) } i = 1 N s {\left\{ {q}_{i}^{\left( s\right) }\right\} }_{i = 1}^{{N}_{s}} {qi(s)}i=1Ns 和 { q i ( d ) } i = 1 N d {\left\{ {q}_{i}^{\left( d\right) }\right\} }_{i = 1}^{{N}_{d}} {qi(d)}i=1Nd 分别用于细粒度静态和动态字幕,具有置信度分数 { c i ( s ) } i = 1 N s {\left\{ {c}_{i}^{\left( s\right) }\right\} }_{i = 1}^{{N}_{s}} {ci(s)}i=1Ns 和 { c i ( d ) } i = 1 N d {\left\{ {c}_{i}^{\left( d\right) }\right\} }_{i = 1}^{{N}_{d}} {ci(d)}i=1Nd。 { q i ( s ) } i = 1 N s {\left\{ {q}_{i}^{\left( s\right) }\right\} }_{i = 1}^{{N}_{s}} {qi(s)}i=1Ns 或 { q i ( d ) } i = 1 N d {\left\{ {q}_{i}^{\left( d\right) }\right\} }_{i = 1}^{{N}_{d}} {qi(d)}i=1Nd 中的字幕共享几乎相同的粗略语义,但它们可能表现出不同的细粒度静态或动态细节。
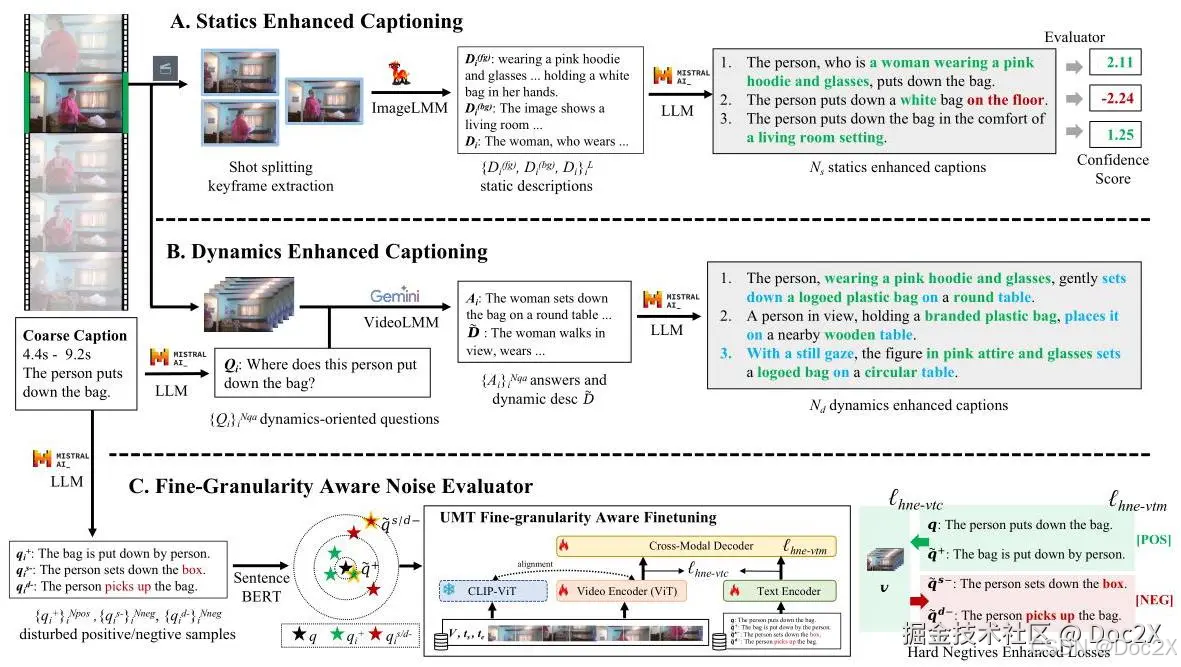
Figure 2: Our VERIFIED annotation pipeline includes two independent modules: Statics Enhanced Captioning (A) and Dynamics Enhanced Captioning (B), which generate multiple fine-grained caption candidates with static and dynamic details. Additionally, we develop a Fine-Granularity Aware Noise Evaluator © that generates and selects the best disturbed positive and negative samples to fine-tune UMT using hard-negative augmented contrastive and matching losses. This evaluator grades captions, assigning low confidence scores to inaccurate ones.
图2:我们的 VERIFIED 注释流水线包括两个独立模块:静态增强字幕(A)和动态增强字幕(B),它们生成具有静态和动态细节的多个细粒度字幕候选。此外,我们开发了一个细粒度感知噪声评估器(C),用于生成和选择最佳的扰动正负样本,以使用硬负样本增强的对比和匹配损失来微调 UMT。该评估器对字幕进行评分,为不准确的字幕分配低置信度分数。
3.1 Statics Enhanced Captioning
3.1 静态增强字幕
Given the moment ( t s , t e ) \left( {{t}_{s},{t}_{e}}\right) (ts,te) in the video V V V with its original coarse caption annotation q q q ,we first extract key frames from the moment ( t s , t e ) \left( {{t}_{s},{t}_{e}}\right) (ts,te) . Concretely,we adaptively adjust the threshold in PySceneDetect 2 {}^{2} 2 to split the moment up to L L L segments and we select the mid-time frames of these segments as key frames { f i } i = 1 L {\left\{ {f}_{i}\right\} }_{i = 1}^{L} {fi}i=1L . For each keyframe f i {f}_{i} fi ,we prompt a strong image LMM with the inputs of the previous coarse caption q q q as guidance and the key frame f i {f}_{i} fi to describe fine-grained details of the foreground D i ( f g ) {\mathcal{D}}_{i}^{\left( fg\right) } Di(fg) and background D i ( b g ) {\mathcal{D}}_{i}^{\left( bg\right) } Di(bg) before generating a complete fine-grained description D i {\mathcal{D}}_{i} Di of this frame.
给定视频中的时刻 ( t s , t e ) \left( {{t}_{s},{t}_{e}}\right) (ts,te) 及其原始的粗略字幕注释 q q q,我们首先从该时刻 ( t s , t e ) \left( {{t}_{s},{t}_{e}}\right) (ts,te) 中提取关键帧。具体来说,我们自适应地调整 PySceneDetect 2 {}^{2} 2 中的阈值,将该时刻分割成 L L L 个片段,并选择这些片段的中间时间帧作为关键帧 { f i } i = 1 L {\left\{ {f}_{i}\right\} }_{i = 1}^{L} {fi}i=1L。对于每个关键帧 f i {f}_{i} fi,我们使用之前的粗略字幕 q q q 作为指导,并结合关键帧 f i {f}_{i} fi 提示一个强大的图像大模型(LMM),以描述前景 D i ( f g ) {\mathcal{D}}_{i}^{\left( fg\right) } Di(fg) 和背景 D i ( b g ) {\mathcal{D}}_{i}^{\left( bg\right) } Di(bg) 的细粒度细节,然后再生成该帧的完整细粒度描述 D i {\mathcal{D}}_{i} Di。
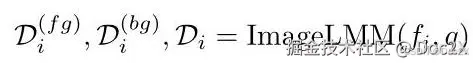
Afterward,we prompt an LLM to extract important static attributes to rephrase it to N s {N}_{s} Ns diverse fine-grained caption candidates { q i ( s ) } i = 1 N s {\left\{ {q}_{i}^{\left( s\right) }\right\} }_{i = 1}^{{N}_{s}} {qi(s)}i=1Ns as follows,
随后,我们提示一个大型语言模型(LLM)提取重要的静态属性,并将其重新表述为 N s {N}_{s} Ns 多样化的细粒度字幕候选 { q i ( s ) } i = 1 N s {\left\{ {q}_{i}^{\left( s\right) }\right\} }_{i = 1}^{{N}_{s}} {qi(s)}i=1Ns,如下所示:
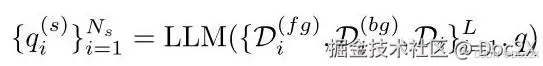
These new captions now contain rich static visual details about the video moment.
这些新字幕现在包含了关于视频时刻的丰富静态视觉细节。
3.2 Dynamics Enhanced Captioning
3.2 动态增强字幕
Since it’s hard for even existing strong video captioning models to capture rich enough dynamic information, we introduce video question answering (VQA) to enhance the dynamic information extraction process. We prompt an LLM to generate N q a {N}_{qa} Nqa relevant dynamics-oriented questions
由于即使是现有的强大视频字幕模型也难以捕捉足够丰富的动态信息,我们引入了视频问答(VQA)来增强动态信息提取过程。我们提示一个大型语言模型(LLM)生成 N q a {N}_{qa} Nqa 相关的面向动态的问题。
2 {}^{2} 2 https://www.scenedetect.com/
2 {}^{2} 2 https://www.scenedetect.com/
—— 更多内容请到Doc2X翻译查看——
—— For more content, please visit Doc2X for translations ——


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









