







代码来源:https://github.com/ZhugeKongan/Attention-mechanism-implementation
转载的文章地址:https://zhuanlan.zhihu.com/p/388122250
本文目录
pytorch for Self-attention、Non-local、SE、SK、CBAM、DANet
根据注意机制的不同应用领域,即注意权重的不同应用方式和位置,将注意机制分为空间域、通道域和混合域,并介绍了这些不同注意的一些先进方面。注意模型,仔细分析了它们的设计方法和应用领域,最后用实验方法证明了这些注意机制的有效性和对CV任务结果的改善。
1. Spatial attention method / 空间注意力
1.1 Self-Attention
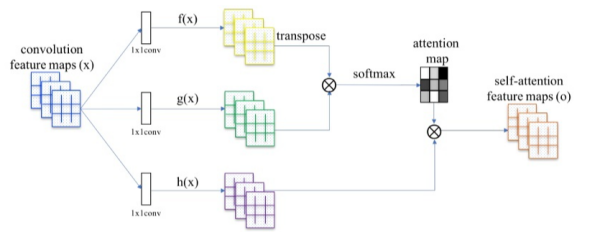
1.2 Non-local Attention
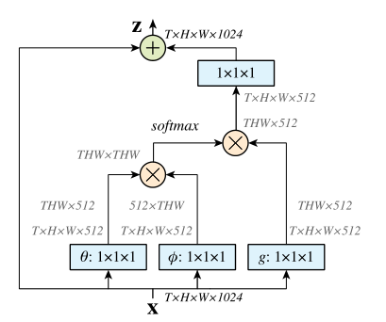
non_local_concatenation代码:
import torch
from torch import nn
from torch.nn import functional as F
class _NonLocalBlockND(nn.Module):
def __init__(self, in_channels, inter_channels=None, dimension=3, sub_sample=True, bn_layer=True):
super(_NonLocalBlockND, self).__init__()
assert dimension in [1, 2, 3]
self.dimension = dimension
self.sub_sample = sub_sample
self.in_channels = in_channels
self.inter_channels = inter_channels
if self.inter_channels is None:
self.inter_channels = in_channels // 2
if self.inter_channels == 0:
self.inter_channels = 1
if dimension == 3:
conv_nd = nn.Conv3d
max_pool_layer = nn.MaxPool3d(kernel_size=(1, 2, 2))
bn = nn.BatchNorm3d
elif dimension == 2:
conv_nd = nn.Conv2d
max_pool_layer = nn.MaxPool2d(kernel_size=(2, 2))
bn = nn.BatchNorm2d
else:
conv_nd = nn.Conv1d
max_pool_layer = nn.MaxPool1d(kernel_size=(2))
bn = nn.BatchNorm1d
self.g = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
if bn_layer:
self.W = nn.Sequential(
conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0),
bn(self.in_channels)
)
nn.init.constant_(self.W[1].weight, 0)
nn.init.constant_(self.W[1].bias, 0)
else:
self.W = conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0)
nn.init.constant_(self.W.weight, 0)
nn.init.constant_(self.W.bias, 0)
self.theta = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
self.phi = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
self.concat_project = nn.Sequential(
nn.Conv2d(self.inter_channels * 2, 1, 1, 1, 0, bias=False),
nn.ReLU()
)
if sub_sample:
self.g = nn.Sequential(self.g, max_pool_layer)
self.phi = nn.Sequential(self.phi, max_pool_layer)
def forward(self, x, return_nl_map=False):
'''
:param x: (b, c, t, h, w)
:param return_nl_map: if True return z, nl_map, else only return z.
:return:
'''
batch_size = x.size(0)
g_x = self.g(x).view(batch_size, self.inter_channels, -1)
g_x = g_x.permute(0, 2, 1)
# (b, c, N, 1)
theta_x = self.theta(x).view(batch_size, self.inter_channels, -1, 1)
# (b, c, 1, N)
phi_x = self.phi(x).view(batch_size, self.inter_channels, 1, -1)
h = theta_x.size(2)
w = phi_x.size(3)
theta_x = theta_x.repeat(1, 1, 1, w)
phi_x = phi_x.repeat(1, 1, h, 1)
concat_feature = torch.cat([theta_x, phi_x], dim=1)
f = self.concat_project(concat_feature)
b, _, h, w = f.size()
f = f.view(b, h, w)
N = f.size(-1)
f_div_C = f / N
y = torch.matmul(f_div_C, g_x)
y = y.permute(0, 2, 1).contiguous()
y = y.view(batch_size, self.inter_channels, *x.size()[2:])
W_y = self.W(y)
z = W_y + x
if return_nl_map:
return z, f_div_C
return z
class NONLocalBlock1D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock1D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=1, sub_sample=sub_sample,
bn_layer=bn_layer)
class NONLocalBlock2D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock2D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=2, sub_sample=sub_sample,
bn_layer=bn_layer)
class NONLocalBlock3D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True,):
super(NONLocalBlock3D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=3, sub_sample=sub_sample,
bn_layer=bn_layer)
if __name__ == '__main__':
import torch
for (sub_sample_, bn_layer_) in [(True, True), (False, False), (True, False), (False, True)]:
img = torch.zeros(2, 3, 20)
net = NONLocalBlock1D(3, sub_sample=sub_sample_, bn_layer=bn_layer_)
out = net(img)
print(out.size())
img = torch.zeros(2, 3, 20, 20)
net = NONLocalBlock2D(3, sub_sample=sub_sample_, bn_layer=bn_layer_)
out = net(img)
print(out.size())
img = torch.randn(2, 3, 8, 20, 20)
net = NONLocalBlock3D(3, sub_sample=sub_sample_, bn_layer=bn_layer_)
out = net(img)
print(out.size())
non_local_dot_product代码:
import torch
from torch import nn
from torch.nn import functional as F
class _NonLocalBlockND(nn.Module):
def __init__(self, in_channels, inter_channels=None, dimension=3, sub_sample=True, bn_layer=True):
super(_NonLocalBlockND, self).__init__()
assert dimension in [1, 2, 3]
self.dimension = dimension
self.sub_sample = sub_sample
self.in_channels = in_channels
self.inter_channels = inter_channels
if self.inter_channels is None:
self.inter_channels = in_channels // 2
if self.inter_channels == 0:
self.inter_channels = 1
if dimension == 3:
conv_nd = nn.Conv3d
max_pool_layer = nn.MaxPool3d(kernel_size=(1, 2, 2))
bn = nn.BatchNorm3d
elif dimension == 2:
conv_nd = nn.Conv2d
max_pool_layer = nn.MaxPool2d(kernel_size=(2, 2))
bn = nn.BatchNorm2d
else:
conv_nd = nn.Conv1d
max_pool_layer = nn.MaxPool1d(kernel_size=(2))
bn = nn.BatchNorm1d
self.g = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
if bn_layer:
self.W = nn.Sequential(
conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0),
bn(self.in_channels)
)
nn.init.constant_(self.W[1].weight, 0)
nn.init.constant_(self.W[1].bias, 0)
else:
self.W = conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0)
nn.init.constant_(self.W.weight, 0)
nn.init.constant_(self.W.bias, 0)
self.theta = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
self.phi = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
if sub_sample:
self.g = nn.Sequential(self.g, max_pool_layer)
self.phi = nn.Sequential(self.phi, max_pool_layer)
def forward(self, x, return_nl_map=False):
"""
:param x: (b, c, t, h, w)
:param return_nl_map: if True return z, nl_map, else only return z.
:return:
"""
batch_size = x.size(0)
g_x = self.g(x).view(batch_size, self.inter_channels, -1)
g_x = g_x.permute(0, 2, 1)
theta_x = self.theta(x).view(batch_size, self.inter_channels, -1)
theta_x = theta_x.permute(0, 2, 1)
phi_x = self.phi(x).view(batch_size, self.inter_channels, -1)
f = torch.matmul(theta_x, phi_x)
N = f.size(-1)
f_div_C = f / N
y = torch.matmul(f_div_C, g_x)
y = y.permute(0, 2, 1).contiguous()
y = y.view(batch_size, self.inter_channels, *x.size()[2:])
W_y = self.W(y)
z = W_y + x
if return_nl_map:
return z, f_div_C
return z
class NONLocalBlock1D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock1D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=1, sub_sample=sub_sample,
bn_layer=bn_layer)
class NONLocalBlock2D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock2D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=2, sub_sample=sub_sample,
bn_layer=bn_layer)
class NONLocalBlock3D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock3D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=3, sub_sample=sub_sample,
bn_layer=bn_layer)
if __name__ == '__main__':
import torch
for (sub_sample_, bn_layer_) in [(True, True), (False, False), (True, False), (False, True)]:
img = torch.zeros(2, 3, 20)
net = NONLocalBlock1D(3, sub_sample=sub_sample_, bn_layer=bn_layer_)
out = net(img)
print(out.size())
img = torch.zeros(2, 3, 20, 20)
net = NONLocalBlock2D(3, sub_sample=sub_sample_, bn_layer=bn_layer_)
out = net(img)
print(out.size())
img = torch.randn(2, 3, 8, 20, 20)
net = NONLocalBlock3D(3, sub_sample=sub_sample_, bn_layer=bn_layer_)
out = net(img)
print(out.size())
non_local_embedded_gaussian代码:
import torch
from torch import nn
from torch.nn import functional as F
class _NonLocalBlockND(nn.Module):
def __init__(self, in_channels, inter_channels=None, dimension=3, sub_sample=True, bn_layer=True):
"""
:param in_channels:
:param inter_channels:
:param dimension:
:param sub_sample:
:param bn_layer:
"""
super(_NonLocalBlockND, self).__init__()
assert dimension in [1, 2, 3]
self.dimension = dimension
self.sub_sample = sub_sample
self.in_channels = in_channels
self.inter_channels = inter_channels
if self.inter_channels is None:
self.inter_channels = in_channels // 2
if self.inter_channels == 0:
self.inter_channels = 1
if dimension == 3:
conv_nd = nn.Conv3d
max_pool_layer = nn.MaxPool3d(kernel_size=(1, 2, 2))
bn = nn.BatchNorm3d
elif dimension == 2:
conv_nd = nn.Conv2d
max_pool_layer = nn.MaxPool2d(kernel_size=(2, 2))
bn = nn.BatchNorm2d
else:
conv_nd = nn.Conv1d
max_pool_layer = nn.MaxPool1d(kernel_size=(2))
bn = nn.BatchNorm1d
self.g = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
if bn_layer:
self.W = nn.Sequential(
conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0),
bn(self.in_channels)
)
nn.init.constant_(self.W[1].weight, 0)
nn.init.constant_(self.W[1].bias, 0)
else:
self.W = conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0)
nn.init.constant_(self.W.weight, 0)
nn.init.constant_(self.W.bias, 0)
self.theta = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
self.phi = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
if sub_sample:
self.g = nn.Sequential(self.g, max_pool_layer)
self.phi = nn.Sequential(self.phi, max_pool_layer)
def forward(self, x, return_nl_map=False):
"""
:param x: (b, c, t, h, w)
:param return_nl_map: if True return z, nl_map, else only return z.
:return:
"""
batch_size = x.size(0)
g_x = self.g(x).view(batch_size, self.inter_channels, -1)
g_x = g_x.permute(0, 2, 1)
theta_x = self.theta(x).view(batch_size, self.inter_channels, -1)
theta_x = theta_x.permute(0, 2, 1)
phi_x = self.phi(x).view(batch_size, self.inter_channels, -1)
f = torch.matmul(theta_x, phi_x)
f_div_C = F.softmax(f, dim=-1)
y = torch.matmul(f_div_C, g_x)
y = y.permute(0, 2, 1).contiguous()
y = y.view(batch_size, self.inter_channels, *x.size()[2:])
W_y = self.W(y)
z = W_y + x
if return_nl_map:
return z, f_div_C
return z
class NONLocalBlock1D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock1D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=1, sub_sample=sub_sample,
bn_layer=bn_layer)
class NONLocalBlock2D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock2D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=2, sub_sample=sub_sample,
bn_layer=bn_layer,)
class NONLocalBlock3D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock3D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=3, sub_sample=sub_sample,
bn_layer=bn_layer,)
if __name__ == '__main__':
import torch
for (sub_sample_, bn_layer_) in [(True, True), (False, False), (True, False), (False, True)]:
img = torch.zeros(2, 3, 20)
net = NONLocalBlock1D(3, sub_sample=sub_sample_, bn_layer=bn_layer_)
out = net(img)
print(out.size())
img = torch.zeros(2, 3, 20, 20)
net = NONLocalBlock2D(3, sub_sample=sub_sample_, bn_layer=bn_layer_)
out = net(img)
print(out.size())
img = torch.randn(2, 3, 8, 20, 20)
net = NONLocalBlock3D(3, sub_sample=sub_sample_, bn_layer=bn_layer_)
out = net(img)
print(out.size())
non_local_gaussian代码:
import torch
from torch import nn
from torch.nn import functional as F
class _NonLocalBlockND(nn.Module):
def __init__(self, in_channels, inter_channels=None, dimension=3, sub_sample=True, bn_layer=True):
super(_NonLocalBlockND, self).__init__()
assert dimension in [1, 2, 3]
self.dimension = dimension
self.sub_sample = sub_sample
self.in_channels = in_channels
self.inter_channels = inter_channels
if self.inter_channels is None:
self.inter_channels = in_channels // 2
if self.inter_channels == 0:
self.inter_channels = 1
if dimension == 3:
conv_nd = nn.Conv3d
max_pool_layer = nn.MaxPool3d(kernel_size=(1, 2, 2))
bn = nn.BatchNorm3d
elif dimension == 2:
conv_nd = nn.Conv2d
max_pool_layer = nn.MaxPool2d(kernel_size=(2, 2))
bn = nn.BatchNorm2d
else:
conv_nd = nn.Conv1d
max_pool_layer = nn.MaxPool1d(kernel_size=(2))
bn = nn.BatchNorm1d
self.g = conv_nd(in_channels=self.in_channels, out_channels=self.inter_channels,
kernel_size=1, stride=1, padding=0)
if bn_layer:
self.W = nn.Sequential(
conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0),
bn(self.in_channels)
)
nn.init.constant_(self.W[1].weight, 0)
nn.init.constant_(self.W[1].bias, 0)
else:
self.W = conv_nd(in_channels=self.inter_channels, out_channels=self.in_channels,
kernel_size=1, stride=1, padding=0)
nn.init.constant_(self.W.weight, 0)
nn.init.constant_(self.W.bias, 0)
if sub_sample:
self.g = nn.Sequential(self.g, max_pool_layer)
self.phi = max_pool_layer
def forward(self, x, return_nl_map=False):
"""
:param x: (b, c, t, h, w)
:param return_nl_map: if True return z, nl_map, else only return z.
:return:
"""
batch_size = x.size(0)
g_x = self.g(x).view(batch_size, self.inter_channels, -1)
g_x = g_x.permute(0, 2, 1)
theta_x = x.view(batch_size, self.in_channels, -1)
theta_x = theta_x.permute(0, 2, 1)
if self.sub_sample:
phi_x = self.phi(x).view(batch_size, self.in_channels, -1)
else:
phi_x = x.view(batch_size, self.in_channels, -1)
f = torch.matmul(theta_x, phi_x)
f_div_C = F.softmax(f, dim=-1)
# if self.store_last_batch_nl_map:
# self.nl_map = f_div_C
y = torch.matmul(f_div_C, g_x)
y = y.permute(0, 2, 1).contiguous()
y = y.view(batch_size, self.inter_channels, *x.size()[2:])
W_y = self.W(y)
z = W_y + x
if return_nl_map:
return z, f_div_C
return z
class NONLocalBlock1D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock1D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=1, sub_sample=sub_sample,
bn_layer=bn_layer)
class NONLocalBlock2D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock2D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=2, sub_sample=sub_sample,
bn_layer=bn_layer)
class NONLocalBlock3D(_NonLocalBlockND):
def __init__(self, in_channels, inter_channels=None, sub_sample=True, bn_layer=True):
super(NONLocalBlock3D, self).__init__(in_channels,
inter_channels=inter_channels,
dimension=3, sub_sample=sub_sample,
bn_layer=bn_layer)
if __name__ == '__main__':
import torch
for (sub_sample_, bn_layer_) in [(True, True), (False, False), (True, False), (False, True)]:
img = torch.zeros(2, 3, 20)
net = NONLocalBlock1D(3, sub_sample=sub_sample_, bn_layer=bn_layer_)
out = net(img)
print(out.size())
img = torch.zeros(2, 3, 20, 20)
net = NONLocalBlock2D(3, sub_sample=sub_sample_, bn_layer=bn_layer_)
out = net(img)
print(out.size())
img = torch.randn(2, 3, 8, 20, 20)
net = NONLocalBlock3D(3, sub_sample=sub_sample_, bn_layer=bn_layer_)
out = net(img)
print(out.size())
NonLocalBlock代码:
import torch
import torch.nn as nn
import torchvision
class NonLocalBlock(nn.Module):
def __init__(self, channel):
super(NonLocalBlock, self).__init__()
self.inter_channel = channel // 2
self.conv_phi = nn.Conv2d(in_channels=channel, out_channels=self.inter_channel, kernel_size=1, stride=1,padding=0, bias=False)
self.conv_theta = nn.Conv2d(in_channels=channel, out_channels=self.inter_channel, kernel_size=1, stride=1, padding=0, bias=False)
self.conv_g = nn.Conv2d(in_channels=channel, out_channels=self.inter_channel, kernel_size=1, stride=1, padding=0, bias=False)
self.softmax = nn.Softmax(dim=1)
self.conv_mask = nn.Conv2d(in_channels=self.inter_channel, out_channels=channel, kernel_size=1, stride=1, padding=0, bias=False)
def forward(self, x):
# [N, C, H , W]
b, c, h, w = x.size()
# [N, C/2, H * W]
x_phi = self.conv_phi(x).view(b, c, -1)
# [N, H * W, C/2]
x_theta = self.conv_theta(x).view(b, c, -1).permute(0, 2, 1).contiguous()
x_g = self.conv_g(x).view(b, c, -1).permute(0, 2, 1).contiguous()
# [N, H * W, H * W]
mul_theta_phi = torch.matmul(x_theta, x_phi)
mul_theta_phi = self.softmax(mul_theta_phi)
# print(mul_theta_phi[0,:,0])
# [N, H * W, C/2]
mul_theta_phi_g = torch.matmul(mul_theta_phi, x_g)
# [N, C/2, H, W]
mul_theta_phi_g = mul_theta_phi_g.permute(0,2,1).contiguous().view(b,self.inter_channel, h, w)
# [N, C, H , W]
mask = self.conv_mask(mul_theta_phi_g)
out = mask + x
return out
if __name__=='__main__':
model = NonLocalBlock(channel=16)
print(model)
input = torch.randn(1, 16, 64, 64)
out = model(input)
print(out.shape)
2. Channel domain attention method / 通道注意力
2.1 SENet
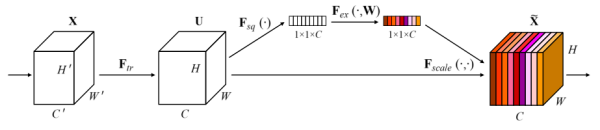
SE_block
# -*- coding: UTF-8 -*-
"""
SE structure
"""
import torch.nn as nn
import torch.nn.functional as F
class SE(nn.Module):
def __init__(self, in_chnls, ratio):
super(SE, self).__init__()
self.squeeze = nn.AdaptiveAvgPool2d((1, 1))
self.compress = nn.Conv2d(in_chnls, in_chnls // ratio, 1, 1, 0)
self.excitation = nn.Conv2d(in_chnls // ratio, in_chnls, 1, 1, 0)
def forward(self, x):
out = self.squeeze(x)
out = self.compress(out)
out = F.relu(out)
out = self.excitation(out)
return x*F.sigmoid(out)
2.2 SKNet
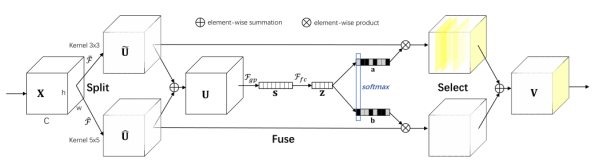
SK_block代码:
import torch.nn as nn
from functools import reduce
class SKConv(nn.Module):
def __init__(self,in_channels,out_channels,stride=1,M=2,r=16,L=32):
super(SKConv,self).__init__()
d=max(in_channels//r,L)
self.M=M
self.out_channels=out_channels
self.conv=nn.ModuleList()
for i in range(M):
self.conv.append(nn.Sequential(nn.Conv2d(in_channels,out_channels,3,stride,padding=1+i,dilation=1+i,groups=32,bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)))
self.global_pool=nn.AdaptiveAvgPool2d(1)
self.fc1=nn.Sequential(nn.Conv2d(out_channels,d,1,bias=False),
nn.BatchNorm2d(d),
nn.ReLU(inplace=True))
self.fc2=nn.Conv2d(d,out_channels*M,1,1,bias=False)
self.softmax=nn.Softmax(dim=1)
def forward(self, input):
batch_size=input.size(0)
output=[]
#the part of split
for i,conv in enumerate(self.conv):
#print(i,conv(input).size())
output.append(conv(input))
#the part of fusion
U=reduce(lambda x,y:x+y,output)
s=self.global_pool(U)
z=self.fc1(s)
a_b=self.fc2(z)
a_b=a_b.reshape(batch_size,self.M,self.out_channels,-1)
a_b=self.softmax(a_b)
#the part of selection
a_b=list(a_b.chunk(self.M,dim=1))#split to a and b
a_b=list(map(lambda x:x.reshape(batch_size,self.out_channels,1,1),a_b))
V=list(map(lambda x,y:x*y,output,a_b))
V=reduce(lambda x,y:x+y,V)
return V
import torch
class SKConv(nn.Module):
def __init__(self, features, M=2, G=32, r=16, stride=1, L=32):
""" Constructor
Args:
features: input channel dimensionality.
M: the number of branchs.
G: num of convolution groups.
r: the ratio for compute d, the length of z.
stride: stride, default 1.
L: the minimum dim of the vector z in paper, default 32.
"""
super(SKConv, self).__init__()
d = max(int(features / r), L)
self.M = M
self.features = features
self.convs = nn.ModuleList([])
for i in range(M):
self.convs.append(nn.Sequential(
nn.Conv2d(features, features, kernel_size=3, stride=stride, padding=1 + i, dilation=1 + i, groups=G,
bias=False),
nn.BatchNorm2d(features),
nn.ReLU(inplace=False)
))
self.gap = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(nn.Conv2d(features, d, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(d),
nn.ReLU(inplace=False))
self.fcs = nn.ModuleList([])
for i in range(M):
self.fcs.append(
nn.Conv2d(d, features, kernel_size=1, stride=1)
)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
batch_size = x.shape[0]
feats = [conv(x) for conv in self.convs]
feats = torch.cat(feats, dim=1)
feats = feats.view(batch_size, self.M, self.features, feats.shape[2], feats.shape[3])
feats_U = torch.sum(feats, dim=1)
feats_S = self.gap(feats_U)
feats_Z = self.fc(feats_S)
attention_vectors = [fc(feats_Z) for fc in self.fcs]
attention_vectors = torch.cat(attention_vectors, dim=1)
attention_vectors = attention_vectors.view(batch_size, self.M, self.features, 1, 1)
attention_vectors = self.softmax(attention_vectors)
feats_V = torch.sum(feats * attention_vectors, dim=1)
return feats_V
class ECA(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(ECA, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# x: input features with shape [b, c, h, w]
b, c, h, w = x.size()
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return y#x * y.expand_as(x)
class SF(nn.Module):
def __init__(self,channels,M=2):
super(SF,self).__init__()
# self.M=M
self.convs=nn.ModuleList()
for i in range(M):
self.convs.append(nn.Sequential(
# nn.Conv2d(channels, channels, kernel_size=3, stride=1, padding=1 + i, dilation=1 + i, groups=32,bias=False),
# nn.Conv2d(channels, channels, kernel_size=3, stride=1, padding=1, dilation=1, groups=32,bias=False),
nn.Conv2d(channels, channels, kernel_size=3 + 2 * i, stride=1, padding=1 + i, dilation=1, groups=32,bias=False),
nn.BatchNorm2d(channels),
nn.ReLU(inplace=False)
))
self.eca=ECA(channels)
def forward(self, input):
batch_size=input.size(0)
#the part of split
output = [conv(input) for conv in self.convs]
#the part of fusion
U=reduce(lambda x,y:x+y,output)
# print(U.size())
return self.eca(U)
SKNet代码:
import torch.nn as nn
import torch
class SKConv(nn.Module):
def __init__(self, features, WH, M, G, r, stride=1, L=32):
super(SKConv, self).__init__()
d = max(int(features / r), L)
self.M = M
self.features = features
self.convs = nn.ModuleList([])
for i in range(M):
# 使用不同kernel size的卷积
self.convs.append(
nn.Sequential(
nn.Conv2d(features,
features,
kernel_size=3 + i * 2,
stride=stride,
padding=1 + i,
groups=G), nn.BatchNorm2d(features),
nn.ReLU(inplace=False)))
self.fc = nn.Linear(features, d)
self.fcs = nn.ModuleList([])
for i in range(M):
self.fcs.append(nn.Linear(d, features))
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
for i, conv in enumerate(self.convs):
fea = conv(x).unsqueeze_(dim=1)
if i == 0:
feas = fea
else:
feas = torch.cat([feas, fea], dim=1)
fea_U = torch.sum(feas, dim=1)
fea_s = fea_U.mean(-1).mean(-1)
fea_z = self.fc(fea_s)
for i, fc in enumerate(self.fcs):
print(i, fea_z.shape)
vector = fc(fea_z).unsqueeze_(dim=1)
print(i, vector.shape)
if i == 0:
attention_vectors = vector
else:
attention_vectors = torch.cat([attention_vectors, vector],
dim=1)
attention_vectors = self.softmax(attention_vectors)
attention_vectors = attention_vectors.unsqueeze(-1).unsqueeze(-1)
fea_v = (feas * attention_vectors).sum(dim=1)
return fea_v
if __name__ == "__main__":
t = torch.ones((32, 256, 24, 24))
sk = SKConv(256, WH=1, M=2, G=1, r=2)
out = sk(t)
print(out.shape)
3. Hybrid domain attention method / 混合注意力
3.1 CBAM
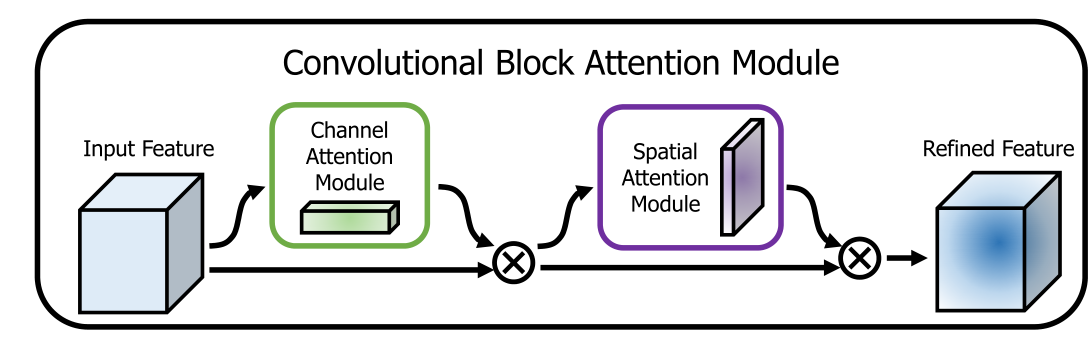
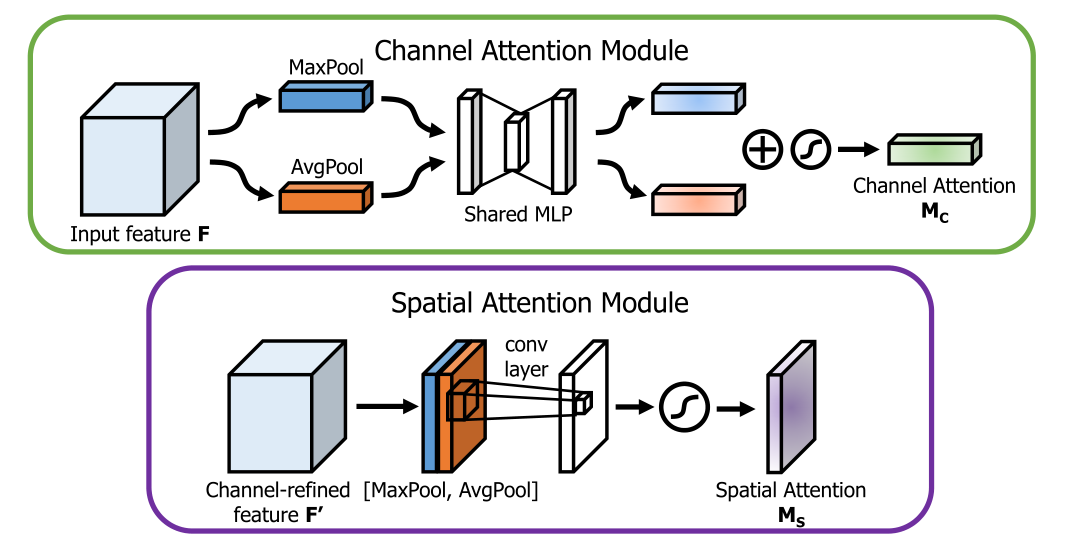
CBAM_blocks代码:
import torch
from torch import nn
from torch.nn import functional as F
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
)
# self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
# self.relu1 = nn.ReLU()
# self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out =self.shared_MLP(self.avg_pool(x))# self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out =self.shared_MLP(self.max_pool(x))# self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, planes):
super(CBAM, self).__init__()
self.ca = ChannelAttention(planes)
self.sa = SpatialAttention()
def forward(self, x):
x = self.ca(x) * x
x = self.sa(x) * x
return x
if __name__ == '__main__':
img = torch.randn(16, 32, 20, 20)
net = CBAM(32)
print(net)
out = net(img)
print(out.size())
3.2 DANet
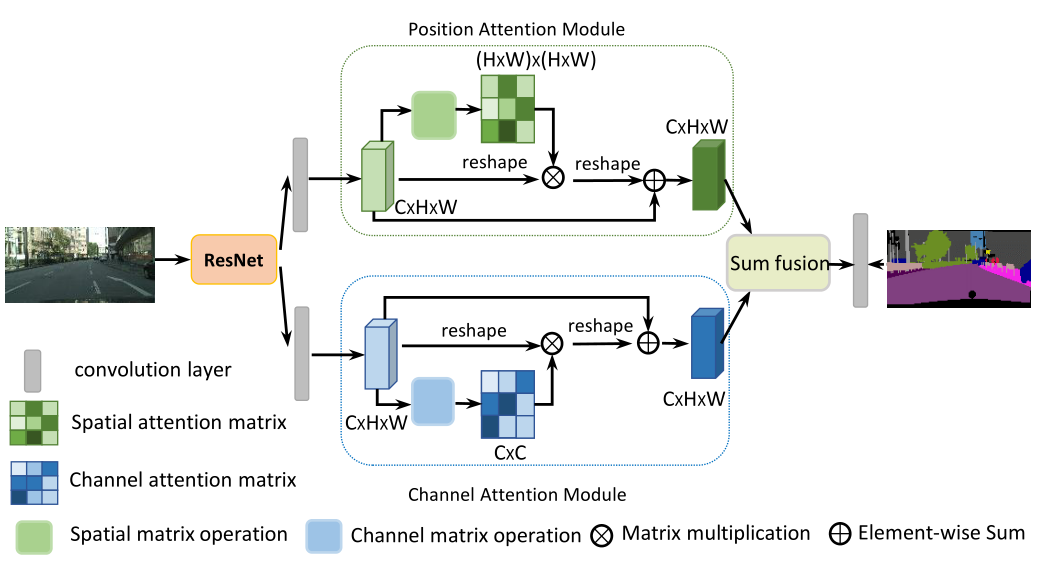
DANet代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class _PositionAttentionModule(nn.Module):
""" Position attention module"""
def __init__(self, in_channels, **kwargs):
super(_PositionAttentionModule, self).__init__()
self.conv_b = nn.Conv2d(in_channels, in_channels // 8, 1)
self.conv_c = nn.Conv2d(in_channels, in_channels // 8, 1)
self.conv_d = nn.Conv2d(in_channels, in_channels, 1)
self.alpha = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
batch_size, _, height, width = x.size()
feat_b = self.conv_b(x).view(batch_size, -1, height * width).permute(0, 2, 1)
feat_c = self.conv_c(x).view(batch_size, -1, height * width)
attention_s = self.softmax(torch.bmm(feat_b, feat_c))
feat_d = self.conv_d(x).view(batch_size, -1, height * width)
feat_e = torch.bmm(feat_d, attention_s.permute(0, 2, 1)).view(batch_size, -1, height, width)
out = self.alpha * feat_e + x
return out
class _ChannelAttentionModule(nn.Module):
"""Channel attention module"""
def __init__(self, **kwargs):
super(_ChannelAttentionModule, self).__init__()
self.beta = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
batch_size, _, height, width = x.size()
feat_a = x.view(batch_size, -1, height * width)
feat_a_transpose = x.view(batch_size, -1, height * width).permute(0, 2, 1)
attention = torch.bmm(feat_a, feat_a_transpose)
attention_new = torch.max(attention, dim=-1, keepdim=True)[0].expand_as(attention) - attention
attention = self.softmax(attention_new)
feat_e = torch.bmm(attention, feat_a).view(batch_size, -1, height, width)
out = self.beta * feat_e + x
return out
class _DAHead(nn.Module):
def __init__(self, in_channels, nclass, aux=True, norm_layer=nn.BatchNorm2d, norm_kwargs=None, **kwargs):
super(_DAHead, self).__init__()
self.aux = aux
inter_channels = in_channels // 4
self.conv_p1 = nn.Sequential(
nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels, **({} if norm_kwargs is None else norm_kwargs)),
nn.ReLU(True)
)
self.conv_c1 = nn.Sequential(
nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels, **({} if norm_kwargs is None else norm_kwargs)),
nn.ReLU(True)
)
self.pam = _PositionAttentionModule(inter_channels, **kwargs)
self.cam = _ChannelAttentionModule(**kwargs)
self.conv_p2 = nn.Sequential(
nn.Conv2d(inter_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels, **({} if norm_kwargs is None else norm_kwargs)),
nn.ReLU(True)
)
self.conv_c2 = nn.Sequential(
nn.Conv2d(inter_channels, inter_channels, 3, padding=1, bias=False),
norm_layer(inter_channels, **({} if norm_kwargs is None else norm_kwargs)),
nn.ReLU(True)
)
self.out = nn.Sequential(
nn.Dropout(0.1),
nn.Conv2d(inter_channels, nclass, 1)
)
if aux:
self.conv_p3 = nn.Sequential(
nn.Dropout(0.1),
nn.Conv2d(inter_channels, nclass, 1)
)
self.conv_c3 = nn.Sequential(
nn.Dropout(0.1),
nn.Conv2d(inter_channels, nclass, 1)
)
def forward(self, x):
feat_p = self.conv_p1(x)
feat_p = self.pam(feat_p)
feat_p = self.conv_p2(feat_p)
feat_c = self.conv_c1(x)
feat_c = self.cam(feat_c)
feat_c = self.conv_c2(feat_c)
feat_fusion = feat_p + feat_c
outputs = []
fusion_out = self.out(feat_fusion)
outputs.append(fusion_out)
if self.aux:
p_out = self.conv_p3(feat_p)
c_out = self.conv_c3(feat_c)
outputs.append(p_out)
outputs.append(c_out)
return tuple(outputs)
4. 实验结果
对于每组实验,我们使用Resnet18作为基线,训练160个历元,初始学习率为0.1,80个历元调整为0.01,160个历元调整为0.001。批量大小设置为128,并对带有动量的SGD优化器进行了实验。读取输入时,首先执行随机裁剪和随机翻转数据增强。特别是,为了最大限度地提高注意力效果,我们在实验开始时都进行了1个阶段的预热操作,并以最佳5个阶段的平均值作为最终结果。
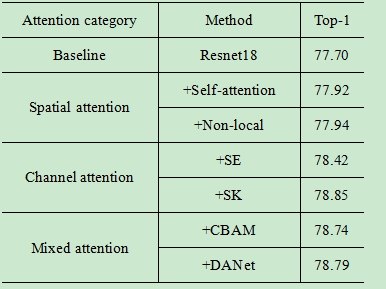
5. Reference–参考文献链接
Self-Attention
Non-local Attention
SENet
SKNet
CBAM
DANet
6. Train代码:
#引入必须的包
import torch
import torchvision
import torchvision.transforms as transforms
data_path='./dataset'#数据保存路径
#数据的预处理操作
training_transform=transforms.Compose([
transforms.RandomCrop(32, padding=4),#数据增广
transforms.RandomHorizontalFlip(),#数据增广
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465],std=[0.2471, 0.2435, 0.2616]),#数据归一化
])
validation_transforms=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465],std=[0.2471, 0.2435, 0.2616]),
])
#训练集
train_dataset = torchvision.datasets.CIFAR100(root=data_path,#数据下载和加载
train=True,
transform=training_transform,
download=True)#若已下载改为False
#测试集
val_dataset = torchvision.datasets.CIFAR100(root=data_path,
train=False,
transform=validation_transforms,
download=True)
x,y= train_dataset[0]
print(x.size(),y)
import torch
import torch.nn as nn
import torch.nn.functional as F
def Conv1(in_planes, places, stride=2):
return nn.Sequential(
nn.Conv2d(in_channels=in_planes, out_channels=places, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
# nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
# 经过处理后的x要与x的维度相同(尺寸和深度)
# 如果不相同,需要添加卷积+BN来变换为同一维度
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes)
)
def forward(self, x):
# print(x.size())
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
#attention block
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = Conv1(in_planes=3, places=64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifer = nn.Linear(512*block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size()[0], -1) # 4, 2048
x = self.classifer(x)
return x
def ResNet18(**kwargs):
return ResNet(BasicBlock, [2, 2, 2, 2],**kwargs)
net = ResNet18(num_classes=10).cuda()
# y = net(torch.randn(1, 3, 32, 32))
# print(y.size())
import os
import sys
import argparse
import time
from datetime import datetime
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import _LRScheduler
class WarmUpLR(_LRScheduler):
"""warmup_training learning rate scheduler
Args:
optimizer: optimzier(e.g. SGD)
total_iters: totoal_iters of warmup phase
"""
def __init__(self, optimizer, total_iters, last_epoch=-1):
self.total_iters = total_iters
super().__init__(optimizer, last_epoch)
def get_lr(self):
"""we will use the first m batches, and set the learning
rate to base_lr * m / total_iters
"""
return [base_lr * self.last_epoch / (self.total_iters + 1e-8) for base_lr in self.base_lrs]
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k""" # [128, 10],128
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True) # [128, 5],indices
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred)) # 5,128
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
wrong_k = batch_size - correct_k
res.append(wrong_k.mul_(100.0 / batch_size))
return res
#超参数
warm=1
epoch=160
batch_size=128
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-4)
train_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[80,120], gamma=0.1) #learning rate decay
from torch.utils.data import DataLoader
trainloader = DataLoader(train_dataset, batch_size, shuffle=True, num_workers=5, pin_memory=True)
valloader = DataLoader(val_dataset, batch_size, shuffle=False, num_workers=5, pin_memory=True)
iter_per_epoch = len(trainloader)
warmup_scheduler = WarmUpLR(optimizer, iter_per_epoch * warm)
def train(trainloader, model, criterion, optimizer, epoch):
losses = AverageMeter()
top1 = AverageMeter()
model.train()
for i, (input, target) in enumerate(trainloader):
# measure data loading time
input, target = input.cuda(), target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
prec = accuracy(output, target)[0]
losses.update(loss.item(), input.size(0))
top1.update(prec.item(), input.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
return top1.avg
def validate(val_loader, model, criterion):
losses = AverageMeter()
top1 = AverageMeter()
model.eval()
with torch.no_grad():
for i, (input, target) in enumerate(val_loader):
input, target = input.cuda(), target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
prec = accuracy(output, target)[0]
losses.update(loss.item(), input.size(0))
top1.update(prec.item(), input.size(0))
print(' * Prec {top1.avg:.3f}% '.format(top1=top1))
return top1.avg
best_prec = 0
for e in range(epoch):
train_scheduler.step( e)
# train for one epoch
train(trainloader, net, loss_function, optimizer, e)
# evaluate on test set
prec = validate(valloader, net, loss_function)
# remember best precision and save checkpoint
is_best = prec > best_prec
best_prec = max(prec,best_prec)
print(best_prec)
附录:
1. 1*1卷积与全连接层的区别:
参考链接:1*1卷积与全连接层的区别
用1*1卷积层代替全连接层的好处:
1、不改变图像空间结构
全连接层会破坏图像的空间结构,而1*1卷积层不会破坏图像的空间结构。
全连通就相当于每个像素点都一样对待,但是卷积是将一个区域单独对待,所以会保留图像局部特征
2、输入可以是任意尺寸
全连接层的输入尺寸是固定的,因为全连接层的参数个数取决于图像大小。而卷积层的输入尺寸是任意的,因为卷积核的参数个数与图像大小无关。

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









