






目录
2.Step2:Goodness of a Function
3.Step3:Find the Best Function
4.Cross Entropy v.s. Square Error
5.Discriminative v.s. Generative
2.Limitation of Logistic Regression
Model Bias v.s. Optimization Issue
Large Loss in Testing Data(Based on Small Loss in Training Data)
摘要
本周学习了逻辑回归以及基本的机器学习任务框架,同时还学习了当一个机器学习任务的Model表现不佳时,如何找到问题所在。通过深入研究这些问题,我明白了这些问题产生的原因,掌握了解决这些问题的方法。
ABSTRACT
This week I learned about logistic regression and basic machine learning task frameworks, as well as how to find the problem when the model of a machine learning task is not performing well. By delving into these problems, I understood the causes of these problems and mastered the methods to solve them.
一、逻辑回归
逻辑回归(Logistic Regression)通常用于解决分类问题,例如客户是否会购买某个商品,借款人是否会违约等现实问题,当然也包括上一周学习的pokemon属性分类案例。实际上,“分类”是应用逻辑回归的目的和结果,中间过程依旧是“回归”,因为通过逻辑回归模型,可以得到计算结果是0-1之间的连续数字,并把它称为“可能性”(概率)。然后,给这个可能性加一个阈值,就成了分类。例如,当时,将
分为
类,其他情况则分为
类。
1.Step1:Function Set
利用逻辑回归模型,首先需要定义函数集。使用sigmoid函数将输出的结果限制在0-1之间,函数则定义为,令
,
记为
,即
。

的结构如下所示。

对比Linear Regression,Logistic Regression在函数定义步骤上与其唯一的区别在于使用了激活函数sigmoid,所以其输出在0-1之间,而Linear Regression的输出可以是任何值。

2.Step2:Goodness of a Function
现有一组训练集(
),每一个
都对应了一个真实的分类标签
(
)。假设这组训练集是希望由模型
所产生的预测结果,定义损失函数为
,则当
最大时才能最逼近这组被预期输出的预测结果,因此也就需要穷举所有的
和
来找到这个最大的
,对应的最优参数记为
和
。

对两边同时取自然对数再添负号,即
,则目标就从穷举所有的
和
找到最大的
转变为穷举所有的
和
找到最小的
。若假设标签设置为
表示
,
表示
,则
,即
时取
,
时取
。

Cross Entropy
分类模型中常使用交叉熵(Cross Entropy)来计算损失。例如本例中的就是一个典型的二分类交叉熵,它的大小表示两个概率分布之间的差异,可以通过最小化交叉熵来得到目标概率分布的近似分布,本例中就是让预测分类标签概率的概率分布逼近真实分类标签的概率分布。

Linear Regression和Logistic Regression在Step2上的区别主要在于前者使用的是均方误差,而后者使用的是交叉熵。为什么不在Logistic Regression也简单地使用均方误差呢?后续将解释这个问题。
3.Step3:Find the Best Function
接下来只需要简单地用损失函数计算对每一个参数的微分,利用微分来更新参数,直到找到使得损失最小的最优的参数。

对比Linear Regression和Logistic Regression在Step3上的区别就仅仅只是和
取值范围的不同。

4.Cross Entropy v.s. Square Error
现在来解释为什么逻辑回归要使用Cross Entropy而不是Square Error。如果逻辑回归使用Square Error,通过计算损失函数对参数的微分可以看出,当预测结果和标签差距很大时,微分趋向于零,而当预测结果和标签差距很小时,微分也趋向于零,这就导致计算出微分很小时无法判断此时的参数时最优的还是最差的。虽然使用Square Error最终也能在一定程度上解决问题,但由于预测结果和标签差距很大时微分趋向于零,会使得参数更新的步长变得很小,参数更新的速度也因此会变得很慢,此时也不能通过盲目增大学习率来增大步长,因为这同样会影响在预测结果和标签差距很小时参数更新的过程。所以逻辑回归模型使用Square Error不容易得到好的结果。

下图是Cross Entropy和Square Error在不同参数下Loss值的直观表现。

5.Discriminative v.s. Generative
虽然判别模型(Discriminative Model)和生成模型(Generative Model)都是基于同一个模型所定义的,但是它们优化参数和
的方式不一样,前者直接对
进行建模,将输出Label的过程视为找到函数
,也被看做直接找到属于不同类的
之间的边界,后者则先假设出
,即对每个类的特征进行建模,然后求出
。因此同一个训练集通过Discriminative和Generative最终得到的最优参数
和
可能并不相同。

也正因为得到的参数不同,同一个训练集通过Discriminative和Generative进行训练后,再由同一个测试集得到的准确率也会有所差别。

Discriminative和Generative到底孰优孰劣呢?现在来举个例子进行分析。如下图,假设现在有一组训练集,共包含了13个样本,每个样本有两个特征,即和
。其中只有特征
,
的那个样本标签为Class1,其余的12个样本全是Class2,假设此时有一个测试集样本的特征
和
也都等于1,按照人类的思维很容易的就会将其归为Class1。

然而使用Naïve Bayes计算得到如下结果,表示Naïve Bayes认为测试数据是属于Class2而不是Class1。事实上Naïve Bayes会得出这样的结果是因为它不会考虑不同维度特征之间的关系,而是认为每一个维度的特征都是独立产生的,它会推测Class2中没有出现特征,
的样本是因为训练集的样本不够多,即当样本数量增加时,Class2是有概率会出现特征
和
都为1的样本的,通俗来讲,Naïve Bayes在“脑补”Class2中的样本。

“脑补”在通常情况下并不是一件好事,但如果在训练集数据量很小的情况下,“脑补”反而有利于模型的预测。因此在训练集数据量很小的情况下,Generative会比Discriminative更好,随着数据量的增加,Discriminative又会反过来超越Generative具有更好的预测表现。除了数据量的大小,训练集noise的大小也影响Generative和Discriminative的表现,noise很大时,Generative更好,反之,则Discriminative更好。

二、多分类任务
对于两个以上分类的分类任务可以使用softmax来解决。softmax可以将输入的值限定在一定范围内输出,同时放大不同输入之间的差距。

1.softmax
softmax将线性预测值转换为概率作为模型的输出,通过Cross Entropy来计算输出和标签之间的误差,然后优化参数。softmax可以看作逻辑回归推广到多分类场景的应用。

2.Limitation of Logistic Regression
对于如下所示的四个样本进行分类使用Logistic Regression是无法做到的,因为无法画出一条直线完全将两个不同分类的样本分开。


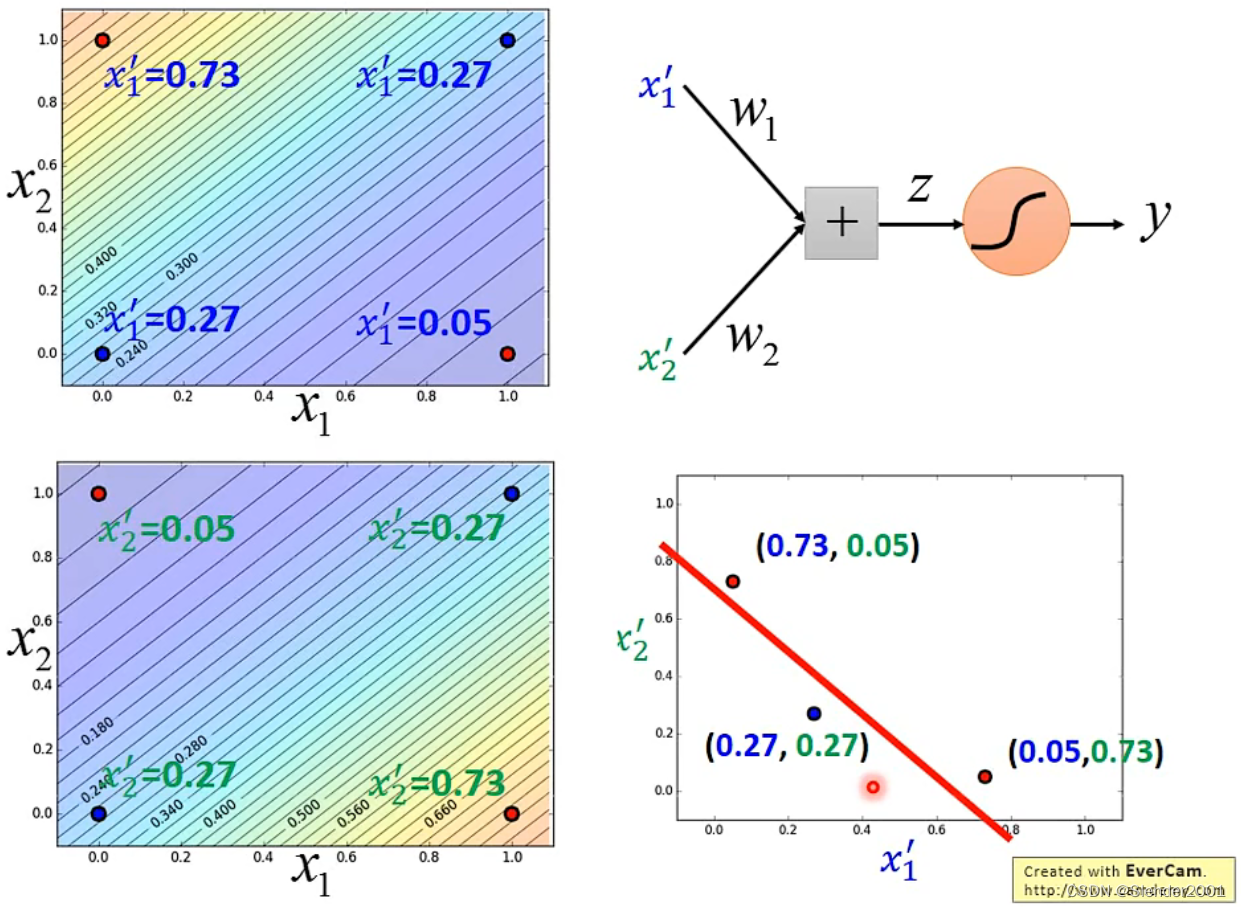
如果这种情况下仍然想要使用Logistic Regression,需要对特征进行转变。例如将上面例子中的转变成
,可以让
等于
到
的距离,
等于
到
的距离,这样就可以用一条直线分开两个分类的样本。但实际应用中想要找到这种变换方式并不容易。

我们可以连接多个Logistic Regression Model来实现上述特征变换的过程,再由一个Logistic Regression Model来实现分类。
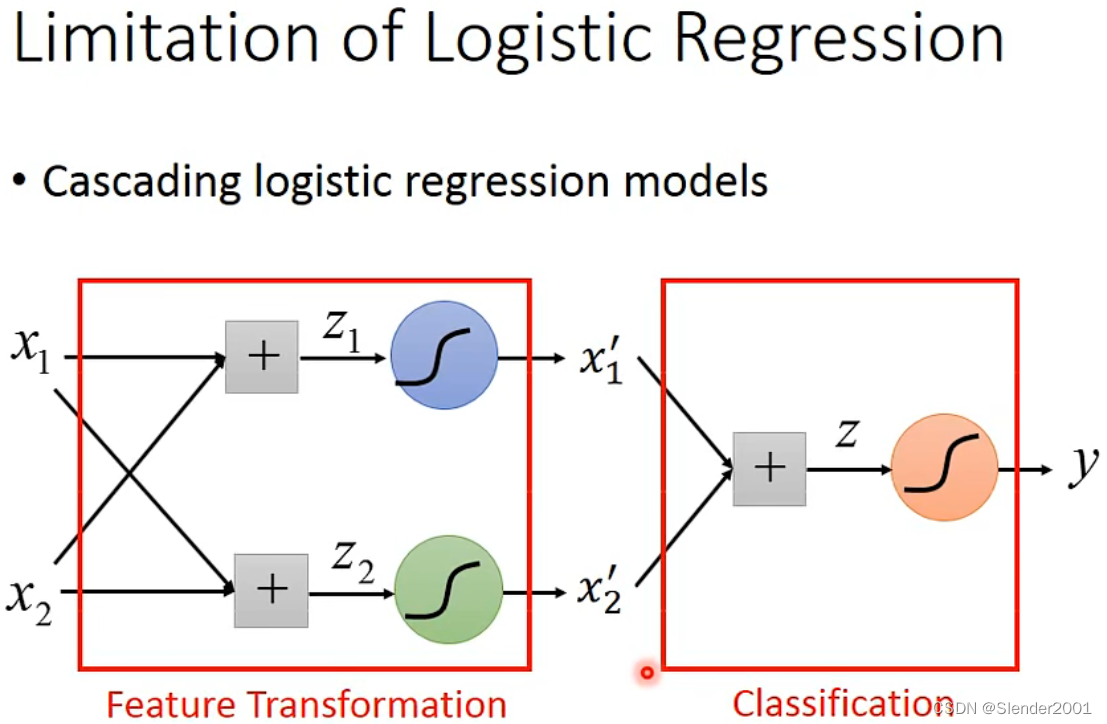

通过连接堆叠这些Logistic Regression Model,也就组成了一个神经网络。

三、机器学习任务框架
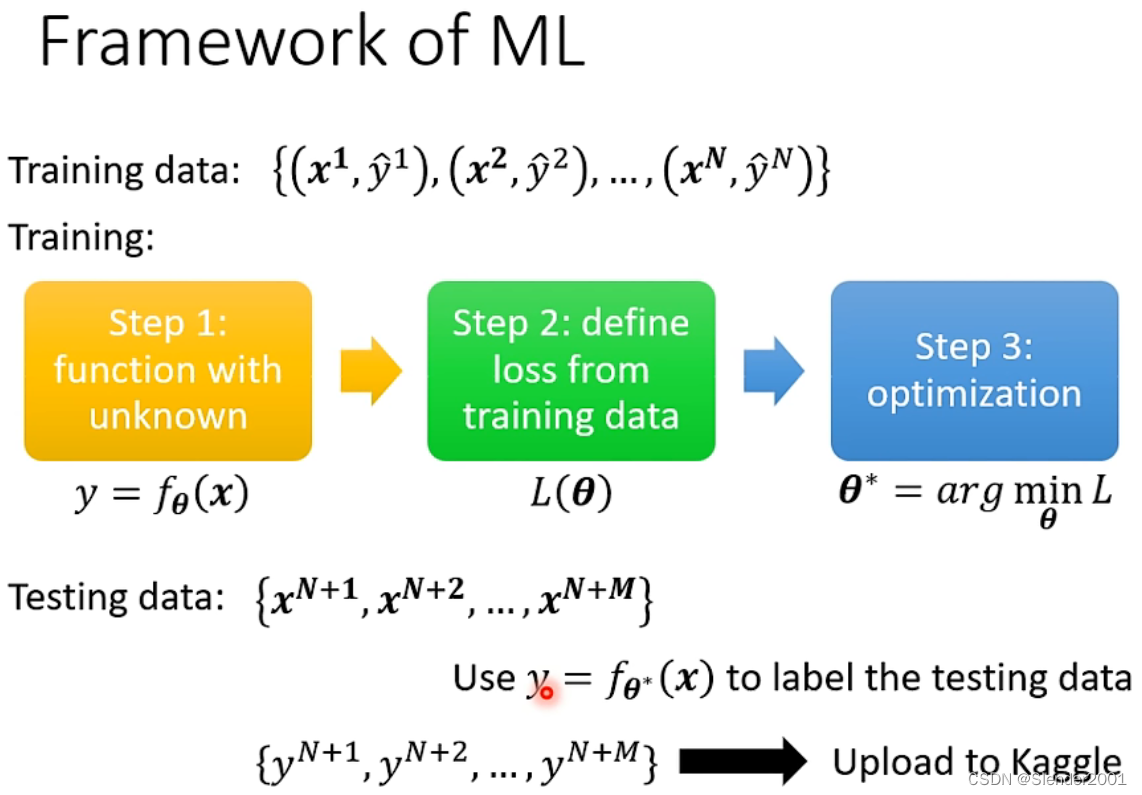
机器学习任务基本框架如下:
step1:定义一个带有参数的函数集,这一个函数集的所有参数统一用
表示。
step2:基于训练集数据定义损失函数。
step3:将参数优化为
使得
的值最小。
step4:使用Best Function 来预测测试集数据的标签。
1.General Guide
如果模型训练出来后仍然达不到理想的状态可以按照如下步骤进行检查,首先检查训练集上的loss值是大还是小。

2.Large Loss in Training Data
如果模型在训练集上的loss值是大的,则说明模型在训练集上没有得到很好的训练,此时主要从两个方向进行考虑来解决问题。第一个考虑的方向是Model Bias,即模型本身太过简单而导致即使得到了Best Function其所达到的效果也非常有限。解决方案是优化模型,例如代入更多的特征加以计算,或者使用深度学习的方法在特征提取的过程中堆叠连接更多的神经元,更多的层数。
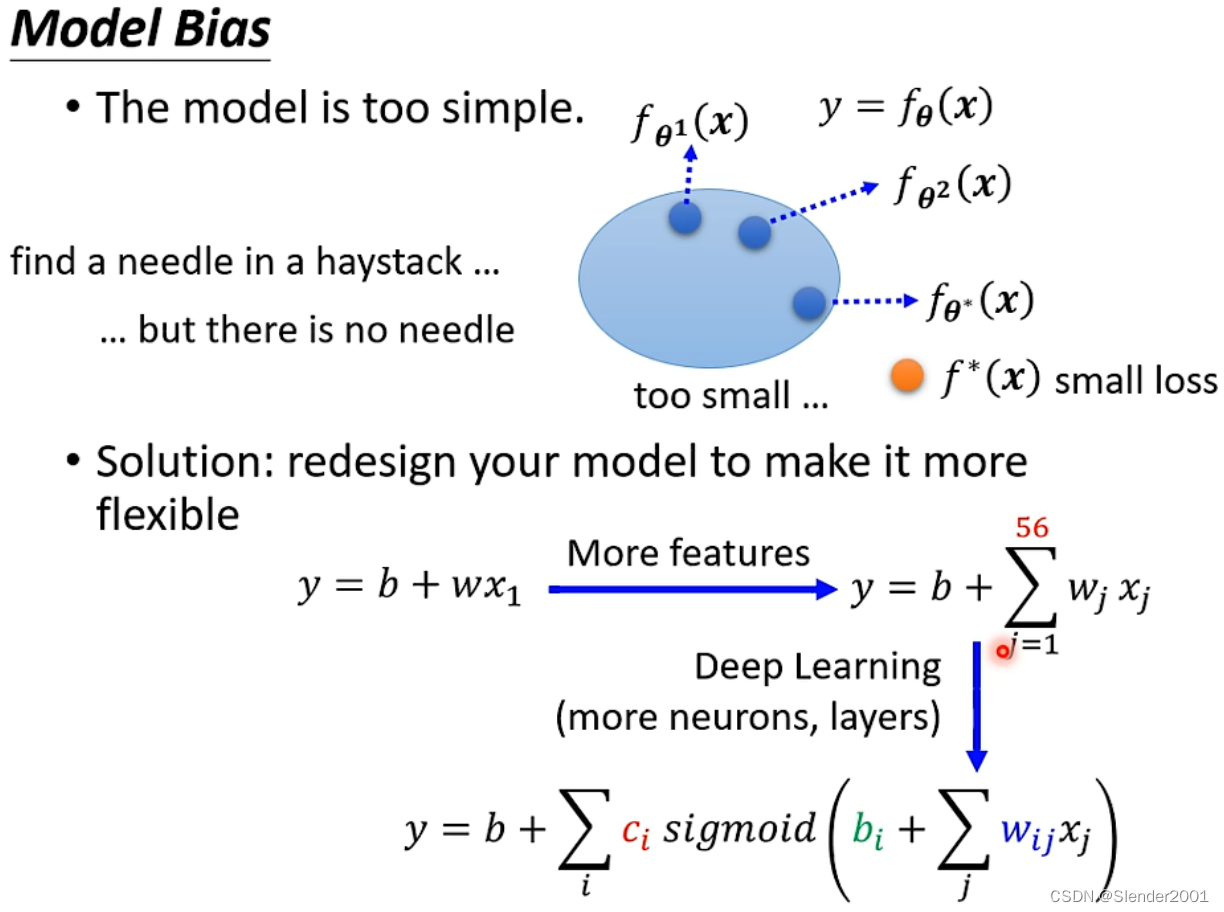
第二个考虑的方向是Optimization Issue,即优化参数的方法存在的问题,例如使用Gradient Decent优化参数时只能找到局部最优的参数而很难找到全局最优的参数。解决方案是使用更加强大的优化方式。
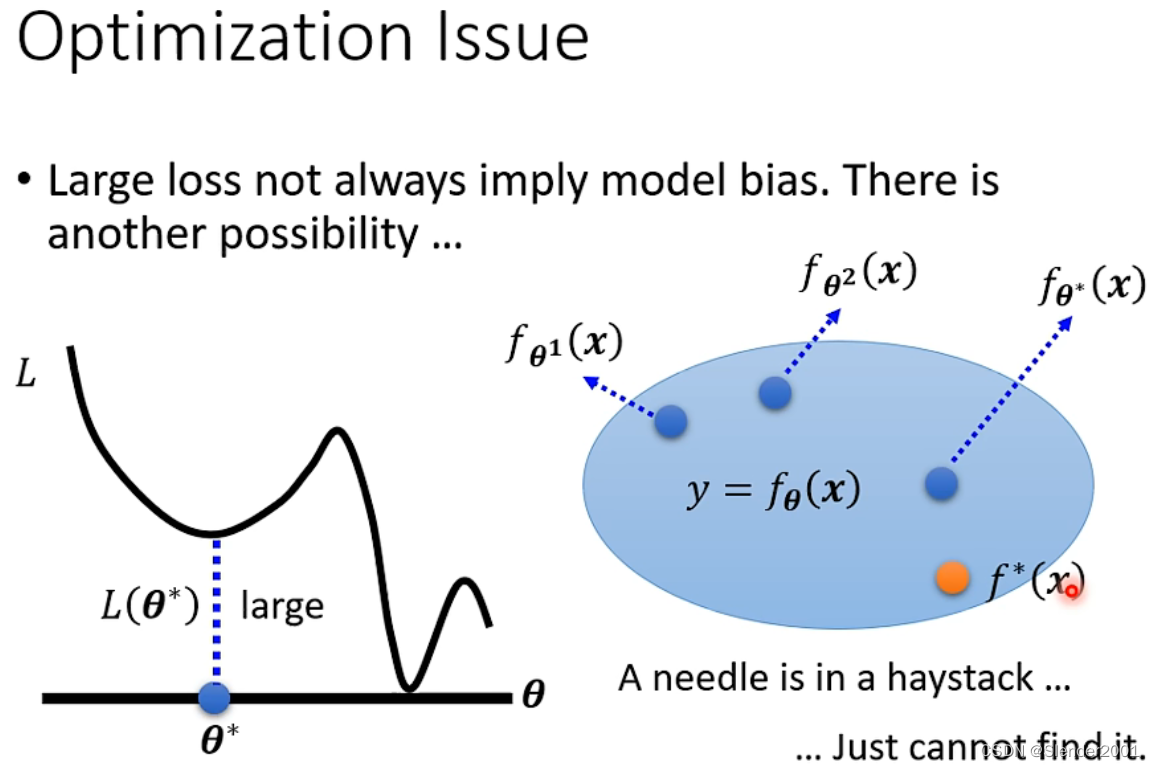
Model Bias v.s. Optimization Issue
怎样判断模型在训练集上得到的loss较大时,出现的问题是Model Bias还是Optimization Issue呢?主要通过比较的方式,例如下图中,56层的模型在测试集上的loss要比20层的大,正常来说都会认为这是Overfitting的结果,但是比较两个模型在训练集上的loss时可以发现,56层模型的loss也比20层模型的要大,这是一个很不正常的结果,此时就主要考虑Optimization Issue。相同的,当使用一个其他的模型进行训练反而能得到好的结果时,就主要考虑Model Bias。

3.Small Loss in Training Data
如果模型在训练集上的loss值是小的则接着看模型在测试集上loss值的大小,如果也是小的,说明模型表现好,能够完成机器学习任务,如果loss值大,说明模型存在问题,仍需继续优化。

Large Loss in Testing Data(Based on Small Loss in Training Data)
出现模型在训练集上表现好而在测试集上表现差,首先考虑到的就是出现了Overfitting现象,模型过于复杂。解决Overfitting的方法有很多种,第一种,增加训练数据量,提高模型的泛化能力,增加的数据可以是全新的数据,也可以是旧数据经过一系列不影响训练的变化而产生的数据(这种变换旧数据扩充训练样本的方法叫做Data Augmentation)。

第二种,限制模型,比如说使用Linear Model时可以限制它的最多是二次式,这样训练出来的模型最多也只能以二次式来调节参数,再比如说在深度学习中使用减小参数量或者干脆共用参数、减少特征的数量、早停止(Early Stopping)、引入正则项(Regularization)以及Dorpout等方法也能有效地解决模型过于复杂而导致的Overfitting的问题。

当然也不能太过于限制模型,比如在近似二次式分布的数据中使用一次式的Linear Model,这样就又回到了之前所碰到的Model Bias的问题。

Mismatch
另一种可能的原因是失配(Mismatch)现象,即训练集和测试集的分布不一样。例如下图这样的情况,就算增加训练集数据或者改变Model都不能解决问题,具体的解决方法之后的内容再进一步说明。

4.Cross Validation
基于前面的结论,选择一个好的Model是非常有必要的,那么该如何选择呢?交叉验证(Cross Validation )是一个比较不错的方案。Cross validation 是一种在机器学习中常用的数据集划分技术,它通过将数据集划分为训练集、验证集和测试集,以便对模型进行训练、评估和调优。首先将原来的训练集划分为两部分,一部分保持为训练集不变,另一部分则为验证集(Validation Set)。然后使用训练集对模型进行训练,使用验证集计算loss,最后挑选出具有最小loss的function,并计算在其public测试集和private测试集上的loss。

N-fold Cross Validation
N折交叉验证(N-fold Cross Validation)是一种常用的交叉验证方法,该方法不再只将训练集划分为训练集和验证集两部分,而是多个小部分,具体数目将根据N的选取决定。比如,如果N=5,此时就是五折交叉验证,即把训练集划分为5个部分。然后不重复地每次取其中一份做为验证集,用其他四份做为训练集训练模型,并计算该模型在验证集上的。最后将5次的
取平均得到最后的
,取拥有最小
的模型进行测试集的预测。

总结
本周学习的主要难点在于学习如何找到机器学习模型表现不佳的原因,然后通过各种方法加以解决这个方面。下一周我将继续深入学习机器学习,了解并掌握其各个概念的知识。















 1002
1002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









