






目录
1 多尺度金字塔网络(Multi-Scale Pyramid Network)
2 自适应图学习模块(Adaptive Graph Learning Module)
3 多尺度时序图神经网络(Multi-Scale Temporal Graph Neural Network)
4 尺度融合模块(Scale-Wise Fusion Module)
5 输出模块与损失函数(Output Module & Loss Function)
摘要
本周深入学习了MAGNN模型内部的结构,主要包括:多尺度金字塔网络、自适应图学习模块、多尺度时序图神经网络、尺度融合模块、输出模块与损失函数六大模块。其中多尺度金字塔网络用于捕获原始时间序列在不同尺度上的特征表示。自适应图学习模块用于捕获样本间的依赖关系,最终输出的是邻接矩阵。多尺度时序图神经网络用于根据输入的不同尺度时间序列和邻接矩阵进行时序卷积操作,得到最终的特定尺度下的特征表示。尺度融合模块加权融合特定尺度表示以捕获整个原始时间序列的时间模式。最终的多尺度特征表示被送入包括两个卷积神经网络的输出模块以获得预测值。模型参数根据损失函数进行更新。
ABSTRACT
This week, We delved into the internal structure of the MAGNN model, which mainly consists of six modules: the Multi-scale Pyramid Network, Adaptive Graph Learning Module, Multi-scale Temporal Graph Neural Network, Scale-Wise Fusion Module, Output Module, and Loss Function. The Multi-scale Pyramid Network is employed to capture feature representations of the original time series at different scales. The Adaptive Graph Learning Module captures dependencies among samples and ultimately outputs an adjacency matrix. The Multi-scale Temporal Graph Neural Network performs temporal convolution operations based on input time series of different scales and the adjacency matrix, producing feature representations specific to the chosen scale. The Scale-Wise Fusion Module combines weighted representations at specific scales to capture temporal patterns of the entire original time series. The resulting multi-scale feature representations are fed into the Output Module, consisting of two convolutional neural networks, to obtain predictions. Model parameters are updated based on the Loss Function.
1 多尺度金字塔网络(Multi-Scale Pyramid Network)
多尺度金字塔网络的主要作用是保存不同时间尺度上的潜在时间依赖。该网络按照金字塔结构,应用多个金字塔层将原始时间序列从小尺度到大尺度分层转换为特征表示。这种多尺度结构使我们有机会在不同的时间尺度上观察原始时间序列。具体而言,较小尺度的特征表示可以保留更细粒度的细节,而较大尺度的特征表示可以捕获时间序列的缓慢变化趋势。
多尺度金字塔网络通过金字塔层生成多尺度特征表示。每个金字塔层都将前一层的输出作为输入,并生成更大规模的特征表示作为输出。具体来说,给定输入,多尺度金字塔网络生成K个尺度的特征表示,第K个尺度的特征表示表示为
,其中N为变量维数,
为第K个尺度的序列长度,
为第K个尺度的通道大小。
金字塔层使用卷积神经网络在时间维度上捕获局部模式。按照图像处理的设计理念,不同的金字塔层使用不同的卷积核大小。初始卷积核具有较大的filter,并且在每一金字塔层的大小缓慢减小,可以控制感受野的大小并保持大尺度时间序列的序列特征。例如,可以将每个金字塔层的卷积核大小设置为1×7、1×6和1×3,并将卷积的步幅设置为2以增加时间尺度。公式表示如下:
,
其中⊗表示卷积操作,和
分别表示第k个金字塔层中的卷积核和偏移向量。然而,不同的金字塔层有望在不同的时间尺度上保留潜在的时间依赖性。仅使用一个卷积神经网络的灵活性是有限的,因为在两个连续的金字塔层的特征表示中捕获的时间依赖关系的粒度对超参数设置(即核大小和步长)高度敏感。为了缓解这个问题,在现有的图像处理工作的基础上,论文引入了另一个卷积神经网络,其卷积核大小为1×1和池化层为1×2,它是与原始卷积神经网络并行的结构。公式表示如下:
,
然后,在每个尺度上对这两个卷积神经网络的输出进行逐点相加:
,
由此,学习到的多尺度特征表示灵活而全面,能够保留各种时序依赖关系。在特征表示学习过程中,为避免MTS变量之间的相互影响,在时间维度上进行卷积操作,变量维度是固定的,即在每个金字塔层的变量维度之间共享卷积核。
2 自适应图学习模块(Adaptive Graph Learning Module)
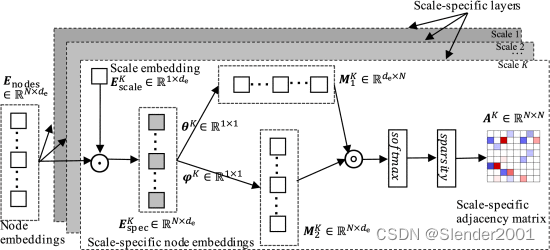
自适应图学习模块自动地生成邻接矩阵来保存MTS中的变量间依赖关系。现有的基于学习的方法只学习一个共享的邻接矩阵,这样的好处在于可以在许多问题中学习MTS中最突出的变量间依赖关系,并且可以显著减少参数数量,避免过拟合问题。然而,变量间的依赖关系在不同的时间尺度下可能是不同的。共享邻接矩阵使模型偏向于学习一类突出的共享时态模式,因此,学习多个尺度特定的邻接矩阵至关重要。
但是,直接为每个尺度学习一个唯一的邻接矩阵会引入过多的参数,使模型难以训练,尤其是当节点数量较大时。为解决该问题,本文提出一种具有K个特定尺度层的自适应图学习模块(AGL)。受矩阵分解的启发,AGL有两类参数:1)节点嵌入在所有尺度之间共享,其中
为嵌入维度,
;2)尺度嵌入
。对于第k个特定尺度层,特定尺度的节点嵌入
通过将第k个尺度嵌入
和节点嵌入
逐点相乘得到。公式表示如下:
,
这样的设计限制了参数的数量,且同时包含了共享的节点信息和特定尺度信息。然后,类似于通过相似度函数计算节点的邻近度,论文计算成对节点的相似度如下:
,
,
,
其中和
为可学习参数,从
分别获得节点的接收端特征和发送端特征,即
和
。激活函数tanh用于将输入值归一化为[−1,1]。然后通过激活函数ReLU将
的值归一化为[0,1],并将其作为节点之间的软边。为了降低图卷积的计算成本,减少噪声的影响,使模型更具鲁棒性,论文引入一种策略使
稀疏化:
,
其中为第k层最终的邻接矩阵,使用Softmax函数实现归一化,稀疏函数定义为:
,
其中是TopK函数的阈值,表示节点的最大邻居数。最后,我们可以得到特定尺度的邻接矩阵
。AGL模块整体架构如下图所示。
3 多尺度时序图神经网络(Multi-Scale Temporal Graph Neural Network)
给定从多尺度金字塔网络生成的多尺度特征表示,和从AGL模块生成的特定尺度邻接矩阵
,提出了多尺度时序图神经网络(MTG),以捕获跨时间步长和变量的特定尺度时序模式。现有的研究集成了GRU和GNN,用GNN代替GRU中的MLP来学习变量间的依赖关系。然而,基于RNN的解决方案往往存在梯度消失和爆炸问题,并且对循环层采用分步策略,使得模型训练效率低下,特别是当时间序列足够长时。时间卷积网络(TCN)在建模时间模式方面表现出优越性。本文提出一种结合GNN和TCN的解决方案,即用时间卷积层代替GRU。具体来说,MTG由K个时序图神经网络组成,每个网络都结合了TCN和GNN来捕获特定尺度的时序模式。对于第k个尺度,首先在时间维度上分割
,得到
。引入
和
的转置(即
),并利用两个GNN来捕获传入信息和传出信息。接着将两个GNN的结果相加,公式表示如下:
,
其中,表示第k个尺度下GNN的可训练参数。然后,我们可以获得所有的输出
,它们会被送入一个时间卷积层,以获得特定尺度的表示
:
,
其中表示第k个时间卷积层中的可训练参数。我们可以看到利用MTG具有如下优势:1)它可以捕获跨时间步长和变量的特定尺度的时间模式;2)图卷积操作使模型能够显式地考虑变量间的依赖关系。
4 尺度融合模块(Scale-Wise Fusion Module)
所有特定尺度的表示都能全面地反映各种时间模式,其中
,
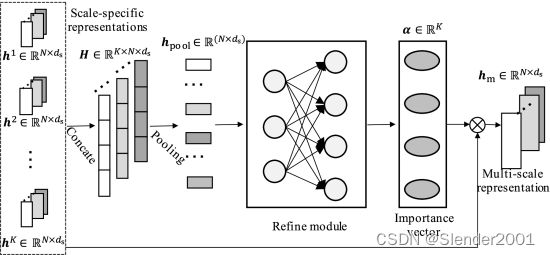
表示TCN的输出维度。为了获得最终的多尺度表示,直观的解决方案是直接连接这些特定尺度的表示,或通过全局池化层聚合这些表示。然而,这种解决方案平等地对待每个尺度特定的表示,忽略了对最终预测结果贡献的差异。例如,小尺度表示对短期预测更重要,而大尺度表示对长期预测更重要。本文提出一个尺度融合模块,从这些特定尺度表示中学习鲁棒的多尺度表示,可以考虑特定尺度时间模式的重要性,并捕获跨尺度的相关性。
下图为尺度融合模块的整体架构。给定特定尺度的表示,首先将这些表示连接起来以获得多尺度矩阵
:
,
其中Concat表示连接操作。然后,在尺度维度上使用平均池化层:
,
其中。然后,将
扁平化,并将其输入到由两个全连接层组成的细化模块中,以压缩不同时间尺度的细粒度信息:
,
,
其中和
是权重矩阵。
和
是偏置向量。第二层使用sigmoid激活函数。定义
为重要性得分向量,表示不同尺度特定表示的重要性。最后,利用加权聚合层来合并特定尺度的表示:
,
其中为最终的多尺度表示。
5 输出模块与损失函数(Output Module & Loss Function)
输出模块包括一个具有卷积核大小的卷积神经网络,以将
转换为所需的输出维度,以及一个具有1×1卷积核大小的后续卷积神经网络,以获得预测值
。
损失函数可表示为:
,
其中是训练样本的数量,N是变量的数量。
和
分别是第i个样本中第j个变量的预测值和真实值。
6 复杂度分析(Complexity Analysis)
MAGNN算法的时间复杂度主要由4个模块组成。对于多尺度金字塔网络,第k个尺度的时间复杂度为,整体时间复杂度为
,其中N为变量维数,T为输入序列长度,
和
分别为输入通道和输出通道的数量。由于
和
被视为常数,因此多尺度金字塔网络的时间复杂度为
。对于AGL模块,时间复杂度为
,其中K是尺度的数量,
是节点或尺度嵌入的维度。前半部分表示节点嵌入和尺度嵌入之间的逐点乘法。后半部分为两两相似度计算。由于
被视为常数,因此AGL模块的时间复杂度为
。对于MTG模块,其时间复杂度为
,其中m为边的数量。
和
分别表示输入维度和输出维度。这个结果来自GNN的信息传递和信息聚合。以
、
、
为常数,MTG模块的时间复杂度为
。对于尺度融合模块,时间复杂度为
,其中
为第一个全连接层的输出维度。由于
和
均为常数,因此该尺度融合模块的时间复杂度为
。
7 相关代码
训练MAGNN模型:
import argparse
import math
import time
import torch
import torch.nn as nn
from net import magnn
import numpy as np
import importlib
from util import *
import os
from torchsummaryX import summary
import nni
os.environ['CUDA_VISIBLE_DEVICE']='1'
def evaluate(data, X, Y, model, evaluateL2, evaluateL1, batch_size, last_test=False):
model.eval()
total_loss = 0
total_loss_l1 = 0
n_samples = 0
predict = None
test = None
for X, Y in data.get_batches(X, Y, batch_size, False):
X = torch.unsqueeze(X,dim=1)
X = X.transpose(2,3)
with torch.no_grad():
output, adj_matrix = model(X)
output = torch.squeeze(output)
if len(output.shape)==1:
output = output.unsqueeze(dim=0)
if predict is None:
predict = output
test = Y
else:
predict = torch.cat((predict, output))
test = torch.cat((test, Y))
scale = data.scale.expand(output.size(0), data.m)
total_loss += evaluateL2(output * scale, Y * scale).item()
total_loss_l1 += evaluateL1(output * scale, Y * scale).item()
n_samples += (output.size(0) * data.m)
rse = math.sqrt(total_loss / n_samples) / data.rse
rae = (total_loss_l1 / n_samples) / data.rae
mae = total_loss_l1 / n_samples
mse = total_loss / n_samples
# mae = mse
rmse = math.sqrt(total_loss * n_samples) / data.rmse
# rmse = 0
predict = predict.data.cpu().numpy()
Ytest = test.data.cpu().numpy()
sigma_p = (predict).std(axis=0)
sigma_g = (Ytest).std(axis=0)
mean_p = predict.mean(axis=0)
mean_g = Ytest.mean(axis=0)
index = (sigma_g != 0)
correlation = ((predict - mean_p) * (Ytest - mean_g)).mean(axis=0) / (sigma_p * sigma_g)
correlation = (correlation[index]).mean()
# if last_test == True:
# np.set_printoptions(precision=4)
# np.savetxt("1.txt", np.array(adj_matrix[0].cpu()), fmt='%.8s')
# np.savetxt("2.txt", np.array(adj_matrix[1].cpu()), fmt='%.8s')
# print(adj_matrix[0])
# print(adj_matrix[1])
return rse, rae, correlation, mae, rmse
def train(data, X, Y, model, criterion, optim, batch_size):
model.train()
total_loss = 0
n_samples = 0
iter = 0
for X, Y in data.get_batches(X, Y, batch_size, True):
model.zero_grad()
X = torch.unsqueeze(X,dim=1)
X = X.transpose(2,3) # shape [4, 1, 137, 168] batch_size * dim * nodes * legnth
# print(X.shape)
if iter % args.step_size == 0:
perm = np.random.permutation(range(args.num_nodes))
num_sub = int(args.num_nodes / args.num_split)
for j in range(args.num_split):
if j != args.num_split - 1:
id = perm[j * num_sub:(j + 1) * num_sub]
else:
id = perm[j * num_sub:]
id = torch.tensor(id).to(device)
tx = X[:, :, id, :]
ty = Y[:, id]
output, adj_matrix = model(tx,id)
output = torch.squeeze(output)
scale = data.scale.expand(output.size(0), data.m)
scale = scale[:,id]
loss = criterion(output * scale, ty * scale)
loss.backward()
total_loss += loss.item()
n_samples += (output.size(0) * data.m)
grad_norm = optim.step()
if iter%100==0:
print('iter:{:3d} | loss: {:.3f}'.format(iter,loss.item()/(output.size(0) * data.m)))
# break
iter += 1
return total_loss / n_samples
parser = argparse.ArgumentParser(description='PyTorch Time series forecasting')
parser.add_argument('--data', type=str, default='solar-energy/solar_AL.txt',
help='location of the data file')
parser.add_argument('--log_interval', type=int, default=2000, metavar='N', help='report interval')
parser.add_argument('--save', type=str, default='model/model.pt',
help='path to save the final model')
parser.add_argument('--optim', type=str, default='adam')
parser.add_argument('--L1Loss', type=bool, default=True)
parser.add_argument('--normalize', type=int, default=2)
parser.add_argument('--device',type=str,default='cuda:0',help='')
parser.add_argument('--gcn_depth',type=int,default=2,help='graph convolution depth')
parser.add_argument('--num_nodes',type=int,default=137,help='number of nodes/variables')
# parser.add_argument('--dropout',type=float,default=0.3,help='dropout rate')
# parser.add_argument('--subgraph_size',type=int,default=20,help='k')
parser.add_argument('--node_dim',type=int,default=40,help='dim of nodes')
# parser.add_argument('--conv_channels',type=int,default=16,help='convolution channels')
parser.add_argument('--scale_channels',type=int,default=32,help='scale channels')
parser.add_argument('--end_channels',type=int,default=64,help='end channels')
parser.add_argument('--in_dim',type=int,default=1,help='inputs dimension')
parser.add_argument('--seq_in_len',type=int,default=24*7,help='input sequence length')
parser.add_argument('--seq_out_len',type=int,default=1,help='output sequence length')
parser.add_argument('--horizon', type=int, default=3)
parser.add_argument('--layers',type=int,default=3,help='number of layers')
parser.add_argument('--batch_size',type=int,default=32,help='batch size')
parser.add_argument('--lr',type=float,default=0.0001,help='learning rate')
parser.add_argument('--weight_decay',type=float,default=0.00001,help='weight decay rate')
parser.add_argument('--clip',type=int,default=5,help='clip')
parser.add_argument('--propalpha',type=float,default=0.05,help='prop alpha')
parser.add_argument('--tanhalpha',type=float,default=3,help='tanh alpha')
parser.add_argument('--epochs',type=int,default=1,help='')
parser.add_argument('--num_split',type=int,default=1,help='number of splits for graphs')
parser.add_argument('--step_size',type=int,default=100,help='step_size')
args = parser.parse_args()
device = torch.device(args.device)
torch.set_num_threads(3)
def main(params):
dropout = params['dropout']
subgraph_size = params['subgraph_size']
conv_channels = params['conv_channels']
scale_channels = conv_channels
gnn_channels = conv_channels
data_dir = "multivariate-time-series-data/" + args.data
Data = DataLoaderS(data_dir, 0.6, 0.2, device, args.horizon, args.seq_in_len, args.normalize)
model = magnn(args.gcn_depth, args.num_nodes,
device, node_dim=args.node_dim, subgraph_size=subgraph_size, dropout=dropout, conv_channels=conv_channels,
scale_channels=scale_channels, end_channels= args.end_channels, gnn_channels = gnn_channels,
seq_length=args.seq_in_len, in_dim=args.in_dim, out_dim=args.seq_out_len,
layers=args.layers, propalpha=args.propalpha, tanhalpha=args.tanhalpha,
single_step=True)
model = model.to(device)
print(args)
nParams = sum([p.nelement() for p in model.parameters()])
print('Number of model parameters is', nParams, flush=True)
# for p in model.parameters():
# if p.requires_grad:
# print(p.nelement())
# summary(model, torch.zeros((4, 1, 137, 168)).to(device))
if args.L1Loss:
criterion = nn.L1Loss(size_average=False).to(device)
else:
criterion = nn.MSELoss(size_average=False).to(device)
evaluateL2 = nn.MSELoss(size_average=False).to(device)
evaluateL1 = nn.L1Loss(size_average=False).to(device)
best_val = 10000000
optim = Optim(model.parameters(), args.optim, args.lr, args.clip, lr_decay=args.weight_decay)
# At any point you can hit Ctrl + C to break out of training early.
try:
print('begin training')
for epoch in range(1, args.epochs + 1):
epoch_start_time = time.time()
train_loss = train(Data, Data.train[0], Data.train[1], model, criterion, optim, args.batch_size)
val_loss, val_rae, val_corr, val_mae, val_rmse = evaluate(Data, Data.valid[0], Data.valid[1], model, evaluateL2, evaluateL1,
args.batch_size)
print(
'| end of epoch {:3d} | time: {:5.2f}s | train_loss {:5.4f} | valid rse {:5.4f} | valid rae {:5.4f} | valid corr {:5.4f} | valid mae {:5.4f} | valid rmse {:5.4f}'.format(
epoch, (time.time() - epoch_start_time), train_loss, val_loss, val_rae, val_corr, val_mae, val_rmse), flush=True)
# Save the model if the validation loss is the best we've seen so far.
if val_loss < best_val:
with open(args.save, 'wb') as f:
torch.save(model, f)
best_val = val_loss
if epoch % 5 == 0:
test_acc, test_rae, test_corr, test_mae, test_rmse = evaluate(Data, Data.test[0], Data.test[1], model, evaluateL2, evaluateL1,
args.batch_size)
print("test rse {:5.4f} | test rae {:5.4f} | test corr {:5.4f} | test mae {:5.4f} | test rmse {:5.4f}".format(test_acc, test_rae, test_corr, test_mae, test_rmse), flush=True)
nni.report_intermediate_result(float(test_acc))
except KeyboardInterrupt:
print('-' * 89)
print('Exiting from training early')
# Load the best saved model.
with open(args.save, 'rb') as f:
model = torch.load(f)
vtest_acc, vtest_rae, vtest_corr, vtest_mae, vtest_rmse = evaluate(Data, Data.valid[0], Data.valid[1], model, evaluateL2, evaluateL1,
args.batch_size)
test_acc, test_rae, test_corr, test_mae, test_rmse = evaluate(Data, Data.test[0], Data.test[1], model, evaluateL2, evaluateL1,
args.batch_size)
print("final test rse {:5.4f} | test rae {:5.4f} | test corr {:5.4f} | test mae {:5.4f} | test mae {:5.4f} | test rmse {:5.4f}".format(test_acc, test_rae, test_corr, test_mae, test_mae, test_rmse))
nni.report_final_result(float(test_acc))
return vtest_acc, vtest_rae, vtest_corr, vtest_mae, vtest_rmse, test_acc, test_rae, test_corr, test_mae, test_rmse
if __name__ == "__main__":
params = nni.get_next_parameter()
main(params)














 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









