






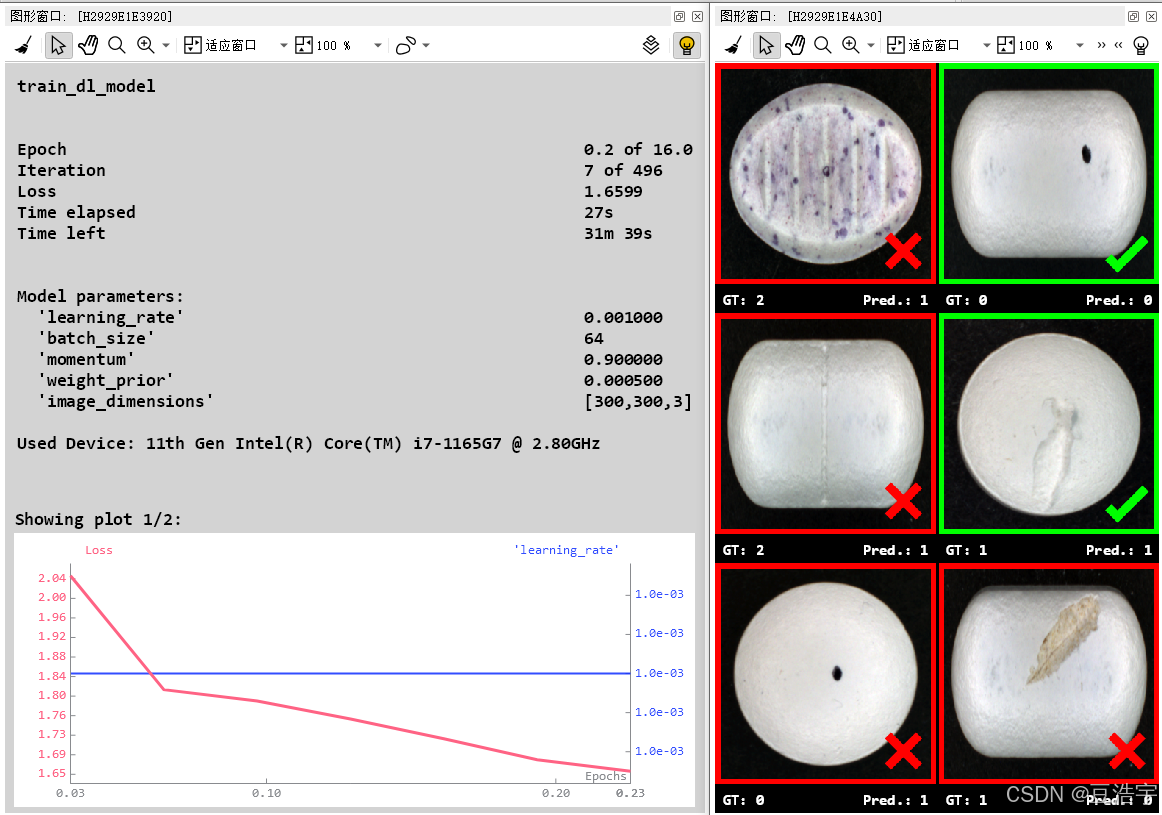
1.Halcon20之后深度学习支持CPU训练模型,没有money买显卡的小伙伴有福了。但是缺点也很明显,就是训练速度超级慢,推理效果也没有GPU好,不过学习用足够。
2.分类模型是Halcon深度学习最简单的模型,可以用在物品分类,缺陷检测等项目。
3.图像预处理和训练代码
*分类网络
dev_update_off ()
dev_close_window ()
WindowWidth := 800
WindowHeight := 600
dev_open_window_fit_size (0, 0, WindowWidth, WindowHeight, -1, -1, WindowHandle)
set_display_font (WindowHandle, 16, ‘mono’, ‘true’, ‘false’)
*训练原图路径
RawImageBaseFolder :=‘D:/训练图/’+ [‘U’,‘SR’,‘MR’,‘BR’,‘C’,‘D’,‘NG’]
*预处理数据存储路径
ExampleDataDir := ‘D:/classify_pill_defects_data’
-
Dataset directory basename for any outputs written by preprocess_dl_dataset.
DataDirectoryBaseName := ExampleDataDir + ‘/dldataset_pill’
- ** Set parameters ***
- LabelSource for reading in the dataset.
LabelSource := ‘last_folder’ - Percentages for splitting the dataset.
TrainingPercent := 70
ValidationPercent := 15 - Image dimensions the images are rescaled to during preprocessing.
ImageWidth := 300
ImageHeight := 300
ImageNumChannels := 3 - Further parameters for image preprocessing.
NormalizationType := ‘none’
DomainHandling := ‘full_domain’ - In order to get a reproducible split we set a random seed.
- This means that re-running the script results in the same split of DLDataset.
SeedRand := 42
- ** Read the labeled data and split it into train, validation and test ***
- Set the random seed.
set_system (‘seed_rand’, SeedRand) - Read the dataset with the procedure read_dl_dataset_classification.
- Alternatively, you can read a DLDataset dictionary
- as created by e.g., the MVTec Deep Learning Tool using read_dict().
read_dl_dataset_classification (RawImageBaseFolder, LabelSource, DLDataset) - Generate the split.
split_dl_dataset (DLDataset, TrainingPercent, ValidationPercent, [])
- ** Preprocess the dataset ***
- Create the output directory if it does not exist yet.
file_exists (ExampleDataDir, FileExists)
if (not FileExists)
make_dir (ExampleDataDir)
endif - Create preprocess parameters.
create_dl_preprocess_param (‘classification’, ImageWidth, ImageHeight, ImageNumChannels, -127, 128, NormalizationType, DomainHandling, [], [], [], [], DLPreprocessParam) - Dataset directory for any outputs written by preprocess_dl_dataset.
DataDirectory := DataDirectoryBaseName + ‘_’ + ImageWidth + ‘x’ + ImageHeight - Preprocess the dataset. This might take a few seconds.
create_dict (GenParam)
set_dict_tuple (GenParam, ‘overwrite_files’, true)
preprocess_dl_dataset (DLDataset, DataDirectory, DLPreprocessParam, GenParam, DLDatasetFileName) - Store preprocess params separately in order to use it e.g. during inference.
PreprocessParamFileBaseName := DataDirectory + ‘/dl_preprocess_param.hdict’
write_dict (DLPreprocessParam, PreprocessParamFileBaseName, [], [])
- ** Preview the preprocessed dataset ***
- Before moving on to training, it is recommended to check the preprocessed dataset.
- Display the DLSamples for 10 randomly selected train images.
get_dict_tuple (DLDataset, ‘samples’, DatasetSamples)
find_dl_samples (DatasetSamples, ‘split’, ‘train’, ‘match’, SampleIndices)
tuple_shuffle (SampleIndices, ShuffledIndices)
read_dl_samples (DLDataset, ShuffledIndices[0:9], DLSampleBatchDisplay)
create_dict (WindowHandleDict)
for Index := 0 to |DLSampleBatchDisplay| - 1 by 1
* Loop over samples in DLSampleBatchDisplay.
dev_display_dl_data (DLSampleBatchDisplay[Index], [], DLDataset, ‘classification_ground_truth’, [], WindowHandleDict)
Text := ‘Press Run (F5) to continue’
dev_disp_text (Text, ‘window’, ‘bottom’, ‘right’, ‘black’, [], [])
stop ()
endfor
*
- Close windows that have been used for visualization.
dev_close_window_dict (WindowHandleDict)
*检测电脑是否有GPU,如果无GPU则使用CPU训练
query_available_dl_devices ([‘runtime’,‘runtime’], [‘gpu’,‘cpu’], DLDeviceHandles)
if (|DLDeviceHandles| == 0)
throw (‘No supported device found to continue this example.’)
endif
- Due to the filter used in query_available_dl_devices, the first device is a GPU, if available.
DLDevice := DLDeviceHandles[0]
get_dl_device_param (DLDevice, ‘type’, DLDeviceType)
if (DLDeviceType == ‘cpu’)- The number of used threads may have an impact
- on the training duration.
NumThreadsTraining := 4
set_system (‘thread_num’, NumThreadsTraining)
endif
- ** Set input and output paths ***
-
File path of the initialized model.
ModelFileName := ‘pretrained_dl_classifier_compact.hdl’ -
File path of the preprocessed DLDataset.
-
Note: Adapt DataDirectory after preprocessing with another image size.
DataDirectory := ExampleDataDir + ‘/dldataset_pill_300x300’
DLDatasetFileName := DataDirectory + ‘/dl_dataset.hdict’
DLPreprocessParamFileName := DataDirectory + ‘/dl_preprocess_param.hdict’ -
Output path of the best evaluated model.
BestModelBaseName := ExampleDataDir + ‘/best_dl_model_classification’ -
Output path for the final trained model.
FinalModelBaseName := ExampleDataDir + ‘/final_dl_model_classification’
- ** Set basic parameters ***
- The following parameters need to be adapted frequently.
- Model parameters.
- Batch size. In case this example is run on a GPU,
- you can set BatchSize to ‘maximum’ and it will be
- determined automatically.
BatchSize := 64 - Initial learning rate.
InitialLearningRate := 0.001 - Momentum should be high if batch size is small.
Momentum := 0.9 - Parameters used by train_dl_model.
- Number of epochs to train the model.
NumEpochs := 16 - Evaluation interval (in epochs) to calculate evaluation measures on the validation split.
EvaluationIntervalEpochs := 1 - Change the learning rate in the following epochs, e.g. [4, 8, 12].
- Set it to [] if the learning rate should not be changed.
ChangeLearningRateEpochs := [4,8,12] - Change the learning rate to the following values, e.g. InitialLearningRate * [0.1, 0.01, 0.001].
- The tuple has to be of the same length as ChangeLearningRateEpochs.
ChangeLearningRateValues := InitialLearningRate * [0.1,0.01,0.001]
- ** Set advanced parameters ***
- The following parameters might need to be changed in rare cases.
- Model parameter.
- Set the weight prior.
WeightPrior := 0.0005 - Parameters used by train_dl_model.
- Control whether training progress is displayed (true/false).
EnableDisplay := true - Set a random seed for training.
RandomSeed := 42
set_system (‘seed_rand’, RandomSeed) - In order to obtain nearly deterministic training results on the same GPU
- (system, driver, cuda-version) you could specify “cudnn_deterministic” as
- “true”. Note, that this could slow down training a bit.
- set_system (‘cudnn_deterministic’, ‘true’)
- Set generic parameters of create_dl_train_param.
- Please see the documentation of create_dl_train_param for an overview on all available parameters.
GenParamName := []
GenParamValue := [] - Augmentation parameters.
- If samples should be augmented during training, create the dict required by augment_dl_samples.
- Here, we set the augmentation percentage and method.
create_dict (AugmentationParam) - Percentage of samples to be augmented.
set_dict_tuple (AugmentationParam, ‘augmentation_percentage’, 50) - Mirror images along row and column.
set_dict_tuple (AugmentationParam, ‘mirror’, ‘rc’)
GenParamName := [GenParamName,‘augment’]
GenParamValue := [GenParamValue,AugmentationParam] - Change strategies.
- It is possible to change model parameters during training.
- Here, we change the learning rate if specified above.
if (|ChangeLearningRateEpochs| > 0)
create_dict (ChangeStrategy)- Specify the model parameter to be changed, here the learning rate.
set_dict_tuple (ChangeStrategy, ‘model_param’, ‘learning_rate’) - Start the parameter value at ‘initial_value’.
set_dict_tuple (ChangeStrategy, ‘initial_value’, InitialLearningRate) - Reduce the learning rate in the following epochs.
set_dict_tuple (ChangeStrategy, ‘epochs’, ChangeLearningRateEpochs) - Reduce the learning rate to the following values.
set_dict_tuple (ChangeStrategy, ‘values’, ChangeLearningRateValues) - Collect all change strategies as input.
GenParamName := [GenParamName,‘change’]
GenParamValue := [GenParamValue,ChangeStrategy]
endif
- Specify the model parameter to be changed, here the learning rate.
- Serialization strategies.
- There are several options for saving intermediate models to disk (see create_dl_train_param).
- Here, we save the best and the final model to the paths set above.
create_dict (SerializationStrategy)
set_dict_tuple (SerializationStrategy, ‘type’, ‘best’)
set_dict_tuple (SerializationStrategy, ‘basename’, BestModelBaseName)
GenParamName := [GenParamName,‘serialize’]
GenParamValue := [GenParamValue,SerializationStrategy]
create_dict (SerializationStrategy)
set_dict_tuple (SerializationStrategy, ‘type’, ‘final’)
set_dict_tuple (SerializationStrategy, ‘basename’, FinalModelBaseName)
GenParamName := [GenParamName,‘serialize’]
GenParamValue := [GenParamValue,SerializationStrategy] - Display parameters.
- In this example, 20% of the training split are selected to display the
- evaluation measure for the reduced training split during the training. A lower percentage
- helps to speed up the evaluation/training. If the evaluation measure for the training split
- shall not be displayed, set this value to 0 (default).
SelectedPercentageTrainSamples := 20 - Set the x-axis argument of the training plots.
XAxisLabel := ‘epochs’
create_dict (DisplayParam)
set_dict_tuple (DisplayParam, ‘selected_percentage_train_samples’, SelectedPercentageTrainSamples)
set_dict_tuple (DisplayParam, ‘x_axis_label’, XAxisLabel)
GenParamName := [GenParamName,‘display’]
GenParamValue := [GenParamValue,DisplayParam]
- ** Read initial model and dataset ***
- Check if all necessary files exist.
check_data_availability (ExampleDataDir, DLDatasetFileName, DLPreprocessParamFileName) - Read in the model that was initialized during preprocessing.
read_dl_model (ModelFileName, DLModelHandle) - Read in the preprocessed DLDataset file.
read_dict (DLDatasetFileName, [], [], DLDataset)
- ** Set model parameters ***
- Set model hyper-parameters as specified in the settings above.
set_dl_model_param (DLModelHandle, ‘learning_rate’, InitialLearningRate)
set_dl_model_param (DLModelHandle, ‘momentum’, Momentum) - Set the class names for the model.
get_dict_tuple (DLDataset, ‘class_names’, ClassNames)
set_dl_model_param (DLModelHandle, ‘class_names’, ClassNames) - Get image dimensions from preprocess parameters and set them for the model.
read_dict (DLPreprocessParamFileName, [], [], DLPreprocessParam)
get_dict_tuple (DLPreprocessParam, ‘image_width’, ImageWidth)
get_dict_tuple (DLPreprocessParam, ‘image_height’, ImageHeight)
get_dict_tuple (DLPreprocessParam, ‘image_num_channels’, ImageNumChannels)
set_dl_model_param (DLModelHandle, ‘image_dimensions’, [ImageWidth,ImageHeight,ImageNumChannels])
if (BatchSize == ‘maximum’ and DLDeviceType == ‘gpu’)
set_dl_model_param_max_gpu_batch_size (DLModelHandle, 100)
else
set_dl_model_param (DLModelHandle, ‘batch_size’, BatchSize)
endif - When the batch size is determined, set the device.
set_dl_model_param (DLModelHandle, ‘device’, DLDevice)
if (|WeightPrior| > 0)
set_dl_model_param (DLModelHandle, ‘weight_prior’, WeightPrior)
endif - Set class weights to counteract unbalanced training data. In this example
- we choose the default values, since the classes are evenly distributed in the dataset.
tuple_gen_const (|ClassNames|, 1.0, ClassWeights)
set_dl_model_param (DLModelHandle, ‘class_weights’, ClassWeights)
- ** Train the model ***
- Create training parameters.
create_dl_train_param (DLModelHandle, NumEpochs, EvaluationIntervalEpochs, EnableDisplay, RandomSeed, GenParamName, GenParamValue, TrainParam) - Start the training by calling the training operator
- train_dl_model_batch () within the following procedure.
train_dl_model (DLDataset, DLModelHandle, TrainParam, 0, TrainResults, TrainInfos, EvaluationInfos) - Stop after the training has finished, before closing the windows.
dev_disp_text (‘Press Run (F5) to continue’, ‘window’, ‘bottom’, ‘right’, ‘black’, [], [])
stop () - Close training windows.
dev_close_window ()
4.推理代码
dev_update_off ()
dev_close_window ()
WindowWidth := 800
WindowHeight := 600
dev_open_window_fit_size (0, 0, WindowWidth, WindowHeight, -1, -1, WindowHandle)
set_display_font (WindowHandle, 16, ‘mono’, ‘true’, ‘false’) - ** INFERENCE **
*检测电脑是否有GPU,如果无GPU则使用CPU推理
query_available_dl_devices ([‘runtime’,‘runtime’], [‘gpu’,‘cpu’], DLDeviceHandles)
if (|DLDeviceHandles| == 0)
throw (‘No supported device found to continue this example.’)
endif
- Due to the filter used in query_available_dl_devices, the first device is a GPU, if available.
DLDevice := DLDeviceHandles[0]
*总路径
ExampleDataDir := ‘D:/classify_pill_defects_data’
-
Dataset directory basename for any outputs written by preprocess_dl_dataset.
DataDirectoryBaseName := ExampleDataDir + ‘/dldataset_pill’ -
File name of the dict containing parameters used for preprocessing.
-
Note: Adapt DataDirectory after preprocessing with another image size.
DataDirectory := ExampleDataDir + ‘/dldataset_pill_300x300’
PreprocessParamFileName := DataDirectory + ‘/dl_preprocess_param.hdict’ -
File name of the finetuned object detection model.
RetrainedModelFileName := ExampleDataDir + ‘/best_dl_model_classification.hdl’ -
Batch Size used during inference.
BatchSizeInference := 1
- ** Inference ***
- Check if all necessary files exist.
check_data_availability (ExampleDataDir, PreprocessParamFileName, RetrainedModelFileName, false) - Read in the retrained model.
read_dl_model (RetrainedModelFileName, DLModelHandle) - Set the batch size.
set_dl_model_param (DLModelHandle, ‘batch_size’, BatchSizeInference) - Initialize the model for inference.
set_dl_model_param (DLModelHandle, ‘device’, DLDevice) - Get the class names and IDs from the model.
get_dl_model_param (DLModelHandle, ‘class_names’, ClassNames)
get_dl_model_param (DLModelHandle, ‘class_ids’, ClassIDs) - Get the parameters used for preprocessing.
read_dict (PreprocessParamFileName, [], [], DLPreprocessParam) - Create window dictionary for displaying results.
create_dict (WindowHandleDict) - Create dictionary with dataset parameters necessary for displaying.
create_dict (DLDataInfo)
set_dict_tuple (DLDataInfo, ‘class_names’, ClassNames)
set_dict_tuple (DLDataInfo, ‘class_ids’, ClassIDs) - Set generic parameters for visualization.
create_dict (GenParam)
set_dict_tuple (GenParam, ‘scale_windows’, 1.1)
list_files (‘E:/NG’, [‘files’,‘follow_links’], ImageFiles)
tuple_regexp_select (ImageFiles, [‘\.(tif|tiff|gif|bmp|jpg|jpeg|jp2|png|pcx|pgm|ppm|pbm|xwd|ima|hobj)$’,‘ignore_case’], ImageFiles)
for Index := 0 to |ImageFiles| - 1 by 1
read_image (ImageBatch, ImageFiles[Index])
gen_dl_samples_from_images (ImageBatch, DLSampleBatch)
preprocess_dl_samples (DLSampleBatch, DLPreprocessParam)
apply_dl_model (DLModelHandle, DLSampleBatch, [], DLResultBatch)
DLSample := DLSampleBatch[0]
DLResult := DLResultBatch[0]
*获取识别结果 参数:分类的结果,批处理中图像的索引,通用参数的名称,通用参数的值
get_dict_tuple (DLResult, ‘classification_class_ids’, ClassificationClassID)
get_dict_tuple (DLResult, ‘classification_class_names’, ClassificationClassName)
get_dict_tuple (DLResult, ‘classification_confidences’, ClassificationClassConfidence)
dev_display (ImageBatch)
Text := ‘预测类为: ’ + ClassificationClassName[0] + ’ 置信度:’+ClassificationClassConfidence[0]
dev_disp_text (Text, ‘window’, ‘top’, ‘left’, ‘red’, ‘box’, ‘false’)
stop ()
endfor
dev_close_window_dict (WindowHandleDict)


















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









