







 本文介绍了使用Halcon进行深度学习目标检测的完整流程,包括数据准备、模型选择、数据集划分、模型训练和推理。重点讨论了预训练模型的选择,如AlexNet、ResNet和MobileNet,并详细阐述了训练过程中的参数配置和数据增强策略。
本文介绍了使用Halcon进行深度学习目标检测的完整流程,包括数据准备、模型选择、数据集划分、模型训练和推理。重点讨论了预训练模型的选择,如AlexNet、ResNet和MobileNet,并详细阐述了训练过程中的参数配置和数据增强策略。
Halcon20.11 深度学习模型训练及预测流程(目标检测为例,持续补充,欢迎提出问题)
😐 😐 😐
Halcon提供了深度学习模型训练的功能,所提供的函数都有明确的解释,以及对输入参数的检查,提供明确报错提示。下文所阐述的,按顺序一步步拼凑起来就可以训练你自己的模型啦。
Data 训练样本准备
德国视觉MVTec提供了深度学习标注软件工具Deep Learning Tool

- 创建轴平行矩阵项目(rectangle1)或者自由矩阵项目(rectangle2).dltp项目文件,并根据自己需求完成标签类别创建与标注。

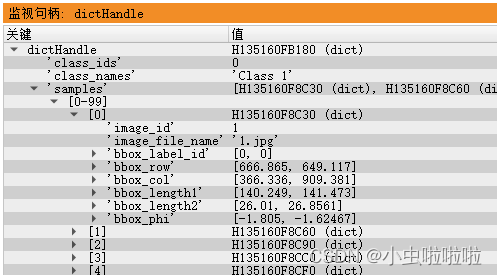
- 完成标注后,导出标注信息文件.hdict文件,.hdict文件包含以下信息:class_ids、class_names、samples(里面包含image_id、image_file_name、bbox_label_id、以及rectangle1或者rectangle2的参数信息)、image_dir(数据根目录);使用read_dict(hdictPath, [], [], dictHandle)函数能查看句柄信息,如果数据集路径发生迁移或者变动,可更改.hdict文件的信息。
backbone 骨干模型准备(预训练模型)
halcon提供了AlexNet、ResNet、MobileNet、enhanced模型四种backbone,需要的时候则在halcon安装路径下寻找对应得.hdl文件即可。在网络选择上,不考虑资源成本的情况下,简单样本可以选择更为轻便的AlexNet、MobileNet结构简单的网络,收敛速度快,同时也不容易过拟合;复杂样本则选择ResNet、enhanced网络,以此获得更高的检测准确率。资源较为受限的情况下根据训练结果情况挑选模型即可。
- pretrained_dl_classifier_alexnet.hdl :AlexNet网络,训练时候占用资源较少,在有限的内存资源中,相比与其他网络能获取更大的batch_size进行训练,加速收敛;
- pretrained_dl_classifier_resnet50.hdl :经典ResNet网络,训练时较为稳定,但耗费资源较大,训练时候需要采用较小的学习率进行训练;
- pretrained_dl_classifier_mobilenet_v2.hdl:MobileNet是经典的轻量级神经网络框架,采用深度可分离卷积进行提取特征,使用更小的参数量能获得等价大小2D卷积核的特征获取方式,拥有体积小、推理功耗低等特点,适合移动及嵌入式设备的使用。训练时候占用资源比AlexNet稍大;
- pretrained_dl_classifier_enhanced.hdl:(未使用过)根据halcon提供的算子描述,该骨干网络架构有更多的隐藏层(即网络架构更为复杂),可以胜任更复杂的分类任务。
Dataset 数据划分(训练集与验证集)
- 设置训练集及验证集划分的百分比
TrainingPercent := 80
ValidationPercent := 20
- 设置随机种子(随机种子不变,验证集与验证集分配结果则不变)
* In order to get a reproducible split we set a random seed. *
* This means that rerunning the script results in the same split of DLDataset. *
SeedRand := 42
set_system('seed_rand',SeedRand)
- 读取数据集并划分
split_dl_dataset(DLDataset,TrainingPercent , ValidationPercent, GenParam)函数:
- 首先会检查GenParam中是否存在‘oversplit’的key,如果不存在该key,并且.hdict文件中本身已经被划分好了训练集与验证集,即samples中的信息带有’split’的key和【train、validation、test】的value,则会报错,一般直接导出的hdict标注文件都不会带有‘split’的key,可以不用管;
- 对.hdict标注文件中‘samples’的key的信息,判断标注的类型的rectangle1还是rectangle2;
- 根据GenParam是否存在‘oversplit’的key,检查或者覆盖samples中是否存在‘split’的key;
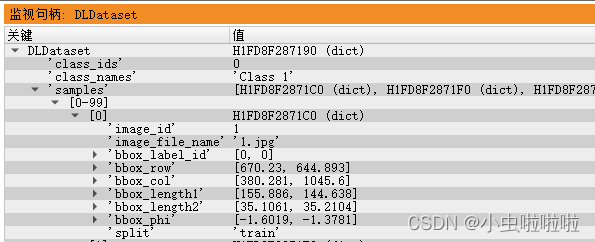
- 把samples中的‘image_id’进行随机分配,并根据提供的比例划分数据集,并赋予‘split’的key和【train、validation、test】的value。
dictFile:=dictPath //.hdict文件的路径
read_dict (dictFile, [], [], DLDataset) //读取标注文件
get_dict_param (DLDataset, 'keys', [], ParamKeyName) //获取标注文件中的键字(用于查看)
split_dl_dataset (DLDataset,TrainingPercent , ValidationPercent, [])
*检查标签方法
create_dict (WindowDict)
get_dict_tuple (DLDataset, 'samples', DatasetSamples)
for Index := 0 to 9 by 1 //根据需求调整数量
*SampleIndex := round(rand(1) * (|DatasetSamples| - 1))
SampleIndex :=Index
read_dl_samples (DLDataset, SampleIndex, DLSample)
dev_display_dl_data (DLSample, [], DLDataset, 'bbox_ground_truth', [], WindowDict)
dev_disp_text ('Press F5 to continue', 'window', 'bottom', 'right', 'black', [], [])
stop ()
endfor
dev_close_window_dict (WindowDict)
*检查数据划分后的结果
get_dict_tuple (DLDataset, 'samples', DatasetSamples)
find_dl_samples (DatasetSamples, 'split', 'train', 'match', TrainSampleIndices)
find_dl_samples (DatasetSamples, 'split', 'test', 'match', testSampleIndices)
find_dl_samples (DatasetSamples, 'split', 'validation', 'match', validationSampleIndices)
DLModelHandle 创建模型句柄
* 获取目标检测模型参数
- 使用determine_dl_model_detection_param ()函数对数据集信息进行统计,计算出min_level & max_level(mulit scale特征获取的层级范围)、achor_num_subscales(多少中anchor缩放等级)、anchor_aspect_ratio(anchor的平均长宽比)、anchor_angles(anchor的平均角度,如果是自由矩形rectangle2才使用);
- determine_dl_model_detection_param (DLDataset, ImageWidth, ImageHeight, GenParam, DLDetectionModelParam)函数:
- 首先会检查GenParam里面的参数(这里可以不需要),检查DLDdataset句柄中是否含有‘image_dir’和‘samples’的key并且是否有效;
- 检查samples[0](你的第一个标注数据)中的信息,判断矩阵类型(rectangle1或者rectangle2);
- 分析标注文件里的图像大小与你设置的模型输入大小,计算长宽比例,计算缩放后的box的面积与宽高比;
- 统计box的面积、长宽比、角度结果信息,并删除异常值(这里规则是按数值大小进行排序,取400个中间值)
- 根据统计数据,利用select_dl_detection_levels和cluster_dl_detection_param函数获得获取特征的层级范围、anchor的缩放等级、anchor的长款比。
(PS:box指的是标注框,anchor指的是模型检测的候选框)
*** 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









