






先挂一下我自己学习并且参考的链接,b站迪哥1-slowfast核心思想解读.mp4_哔哩哔哩_bilibili
先说一下我的配置,我自己是用的Windows的Win11,然后通过远程桌面连接实验室服务器的Linux+RTX4090(不建议Windows,当然Windows也能成功配置slowfast)。
亮点:
1.能够避免RTX4090显卡对cuda高要求(cuda>11.8)的问题,并且自动安装torchvision,torch,以及虚拟环境的cuda相关包。其中torchvision=0.14.1,torch=1.13.1,虚拟环境里cuda相关包是cuda11.1。
2.附带一些错误的解决办法。
目录
3.3安装torch、torchvision、cuda等(成功解决RTX4090显卡对cuda>11.8高版本要求的问题,这会导致torch和torchvision也得高版本,高版本容易报错)
3.6安装ffmpeg、PyYaml、tqdm、iopath
3.9安装tensorboard、moviepy、pytorchvideo
3.12Pytorch、PySlowFast、环境变量的添加
1.先在Linux终端配置基本的虚拟环境
先创建一个虚拟环境吧,这里命名为slowfast1是因为我自己已经有一个能用的slowfast环境了,python版本是3.8:
conda create -n slowfast1 python=3.8

这里输入y就可以了,环境创建好之后,我们激活这个环境,输入这一行:
conda activate slowfast1
此时刚刚创建的基本虚拟环境已经激活了,括号的base变成了slowfast1:
2.准备下slowfast项目文件
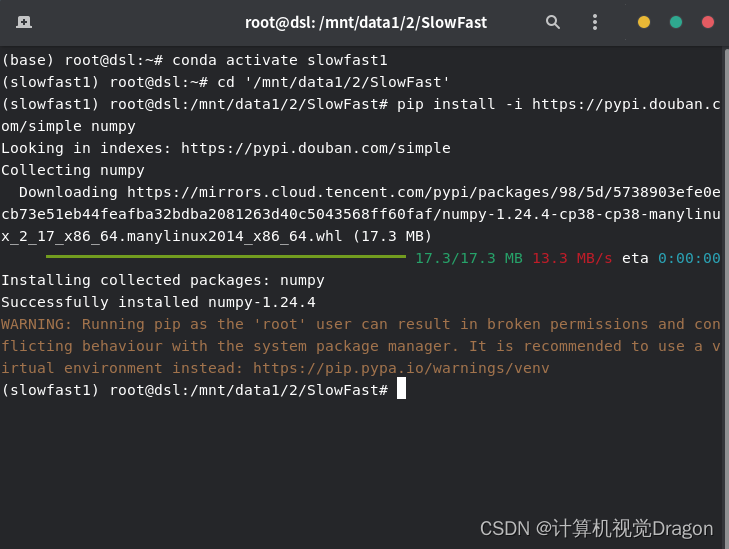
先得给你的slowfast项目找个容身之地,我这里是/mnt/data1/2
然后在终端cd进这个目录,在我的终端输入,哦不,输入目录是一件很麻烦的事情,特别是目录很长的时候,所以这里我直接返回上一级目录,点击2这个文件夹然后拖动到终端上面,终端就会自动生成文件路径了,但是在拖动之前,不要忘记先在终端输入cd+空格!!!!!
在终端回车之后就可以了。slowfast官网的链接是https://github.com/facebookresearch/slowfast
但是由于我git不下来,所以我在windows上爬梯子下载到我的windows上面了(这个时候解压一下,然后重命名为slowfast),然后通过Winscp这个软件传输到实验室服务器Linux系统的/mnt/data1/2目录下面,这里我把项目包直接给你们准备好了,上滑到顶端下载。
项目弄过来之后,在同级目录创建两个文件夹,一个是input,一个是output,方面项目部署好之后测试效果。
3.继续准备相关的虚拟环境
在终端activate一下虚拟环境然后cd进目录
现在点击并且阅读SlowFast文件夹下面的INSTALL.md文件,一行一行地安装
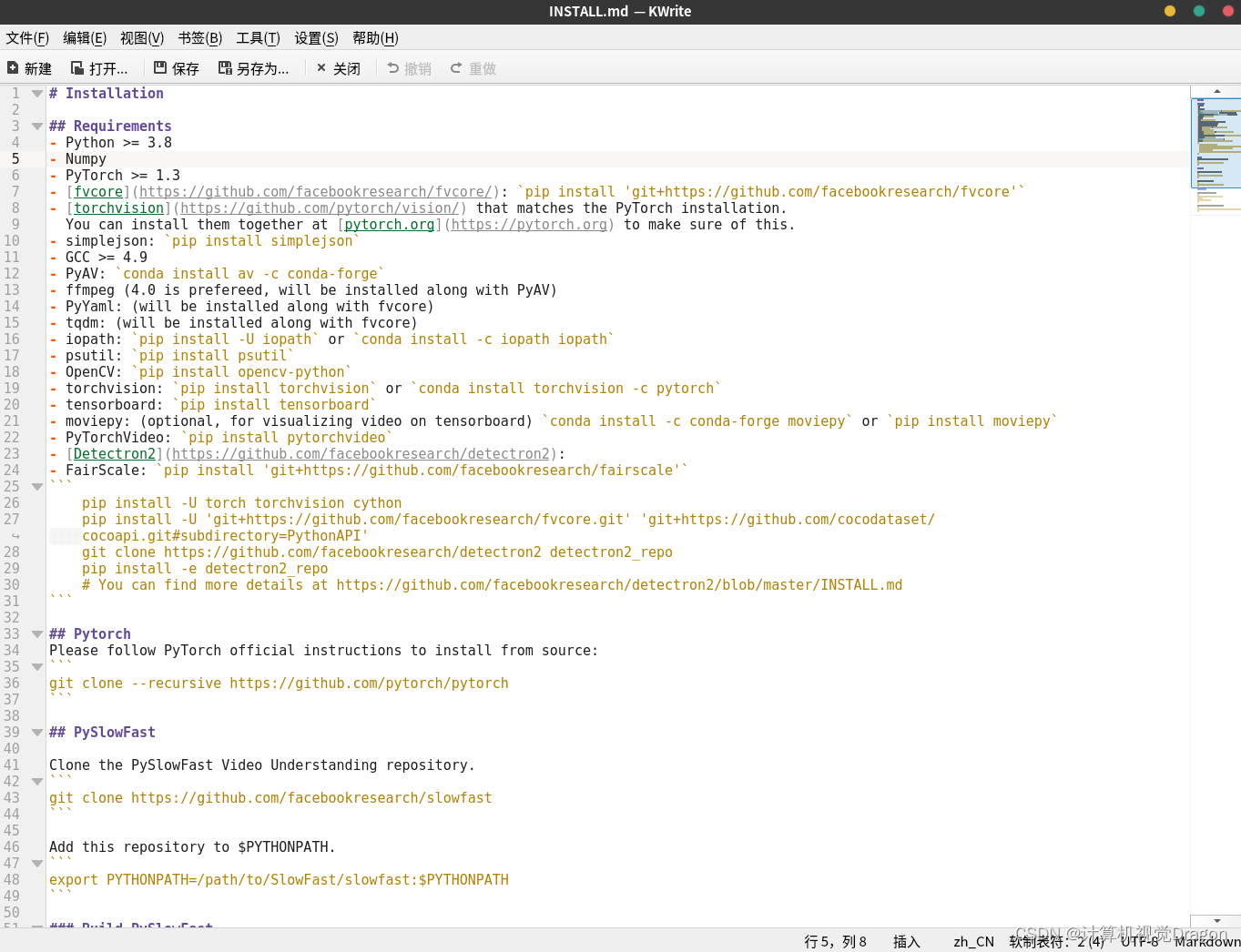
3.1安装numpy
我这里直接用pip install -i https://pypi.douban.com/simple+(一个空格)安装包名称,用的是豆瓣的镜像,下载还挺快,所以先安装numpy
pip install -i https://pypi.douban.com/simple numpy
下载嘎嘎快
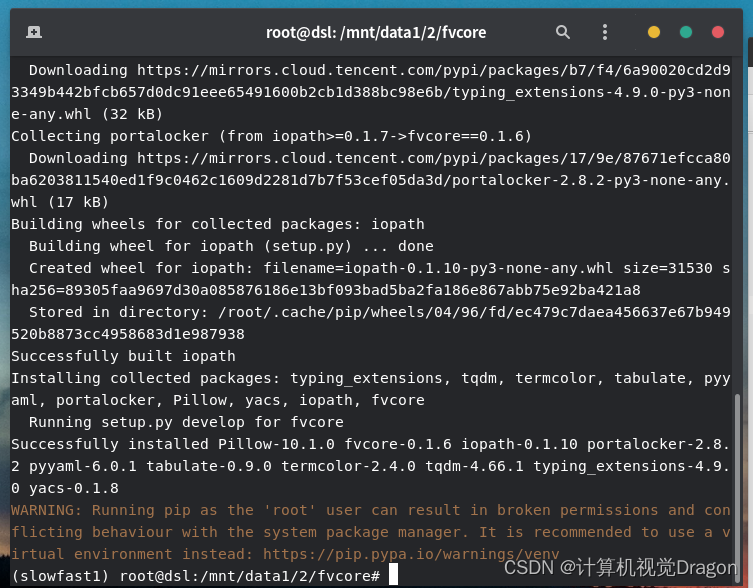
3.2安装fvcore
继续安装,但这里执行官方给的代码:
pip install 'git+https://github.com/facebookresearch/fvcore'半天卡着不动,无语,并且最后失败了(我代理梯子关了),那就这样:
打开这个网站GitHub - facebookresearch/fvcore: Collection of common code that's shared among different research projects in FAIR computer vision team.(打开之前梯子挂上,但是好像现在csdn自动代理加速来着?csdn这一点很强),然后下载压缩包到我的windows上面,解压,然后通过winscp这个fvcore文件夹传输到我的linux上面
然后在终端cd进fvcore目录(cd然后点击fvcore文件夹拖动到终端里面就行),然后输入
pip install -i https://pypi.douban.com/simple -e .
如果没有中间那一段而是pip install -e .安装就贼慢,很烦,我后面改成了上面 这段代码。
3.3安装torch、torchvision、cuda等(成功解决RTX4090显卡对cuda>11.8高版本要求的问题,这会导致torch和torchvision也得高版本,高版本容易报错)
安装完fvcore之后我们安装torch和torchvision吧,这里我有一些个人的小技巧分享给各位,把cuda之类的也一并安装了,由于我学习这些并没有很久,也没有经验,所以踩了很多坑,自己总结的一点经验,显然一般的项目都尽量不要用太高版本的包,虽然rtx4090这款显卡官方要求cuda11.8以上才能驱动(这必然导致torch和torchvision也得高版本,就会出现一些难以更改的错误),然后我是在linux系统里面装了cuda12.2,然后在conda虚拟环境里面装cuda11.1的低版本,就能够正常使用torch和torchvision低版本的包了。通过我的很多次被搞心态,很多次摸索之后发现:在终端键入
pip install -i https://pypi.douban.com/simple torchvision=0.14.1会安装torchvision,并且自动安装
torch1.13.1以及
nvidia-cublas-cu11-11.10.3.66
nvidia-cuda-nvrtc-cu11-11.7.99
nvidia-cuda-runtime-cu11-11.7.99
nvidia-cudnn-cu11-8.5.0.96(这四个文件应该就是虚拟环境的cuda11.1相关包了)。下载速度还嘎嘎快,所以,直接执行这条命令即可。

到这里,个人认为环境搭建最麻烦的一步已经搞定了,继续耐心部署吧......
3.4安装simplejson
pip install -i https://pypi.douban.com/simple simplejson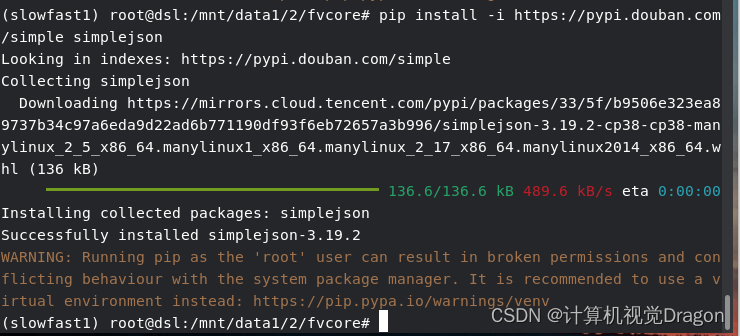
秒了
3.5安装PyAV
直接执行官方这行代码
conda install av -c conda-forge等待一会,然后输入y
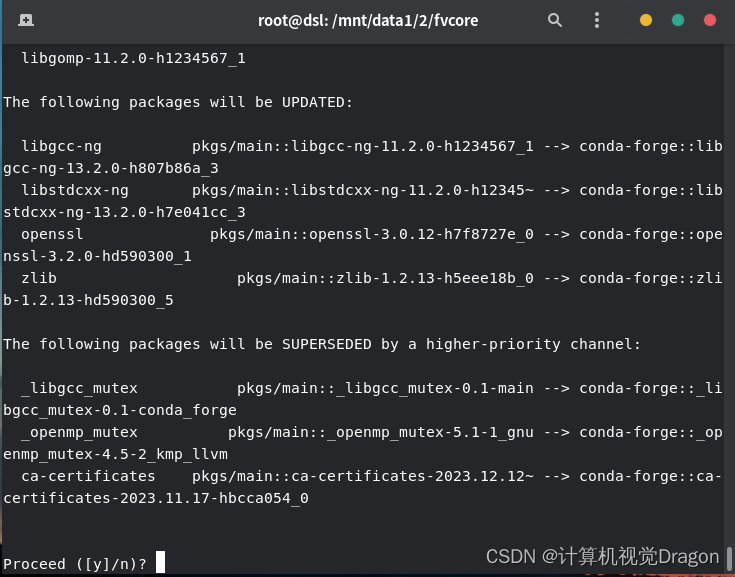
就成功了,如果执行官方的代码没有成功可以评论区留言交流一下
3.6安装ffmpeg、PyYaml、tqdm、iopath
这个直接pass,在上一步已经被一起安装了
3.7安装psutil
pip install -i https://pypi.douban.com/simple psutil

成功
3. 8安装opencv
老规矩输入
pip install -i https://pypi.douban.com/simple opencv
发现找不到包,这里是豆瓣源,那就换别的源,换了阿里源也没用,那我就干脆去这个网站Links for opencv-python (tsinghua.edu.cn)把opencv安装包扒下来到我的windows上面然后通过winscp传输到linux上,我是选的opencv_python-4.5.4.60-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl这个安装包,直接ctrl+f搜索这个版本就行。下载之后是whl文件直接通过winscp软件传输到linux上面就行
所以这里直接
pip install '/mnt/data1/2/opencv_python-4.5.4.60-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl'
3.9安装tensorboard、moviepy、pytorchvideo
pip install -i https://pypi.douban.com/simple tensorboard
pip install -i https://pypi.douban.com/simple moviepy
pip install -i https://pypi.douban.com/simple pytorchvideo秒了
3.10安装detectron2
参见3.2的安装,步骤是一样的,梯子挂上去facebookresearch/detectron2: Detectron2 is a platform for object detection, segmentation and other visual recognition tasks. (github.com)下载压缩包到windows本地,然后解压改名传输到linux文件夹里面
然后cd进去,执行代码
pip install -i https://pypi.douban.com/simple -e .如果执行的是pip install -e .可能会慢很多。但是发现报错

意思是说cuda12.2版本太高了,RTX4090真该死,查找了解决办法之后我把我的cuda降到11.8了(因为RTX4090至少需要cuda11.8以上才能驱动),这里解释一下,怕大家搞混,我安装了两个cuda,一个是linux服务器的cuda(版本号12.2),一个是虚拟环境里面的cuda(版本11.1,就是步骤3.3说的那四个文件),这里我们不需要动虚拟环境里的cuda,将linux系统的cuda降到11.8版本即可。降版本这件事情大概花了我半天时间,因为中途还碰到安装cuda设备空间(/tmp)不足的问题,安装cuda但是提示/tmp空间不足的解决办法请查看我的另一篇博客。
降低cuda版本之后重新执行就能成功安装detectron2:
pip install -i https://pypi.douban.com/simple -e .
Successfully!!!
3.11安装fairscale之类的
看到第一行,我们还是挂梯子从GitHub - facebookresearch/fairscale: PyTorch extensions for high performance and large scale training.弄下来到我的windows上,然后通过winscp传输到linux上面,最后本地安装

 这是弄下来之后
这是弄下来之后
然后在终端
cd '/mnt/data1/2/fairscale'
pip install -i https://pypi.douban.com/simple -e .看到第二行,让我们安装torch、torchvision、cython,这里我们安装最后一个就行,前面两个装过了
pip install -i https://pypi.douban.com/simple cython第三行的fvcore我们装过了,我们安装后面这个PythonAPI,还是去这个网站https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI
把压缩包弄到我的windows上然后弄到linux上,进入这个目录
在终端cd进去/mnt/data1/2/cocoapi/PythonAPI,然后
pip install -i https://pypi.douban.com/simple -e .
第五行的detectron2在上一步已经安装完成了。
3.12Pytorch、PySlowFast、环境变量的添加
Pytorch和slowfast前面的步骤已经搞定了,这里直接pass
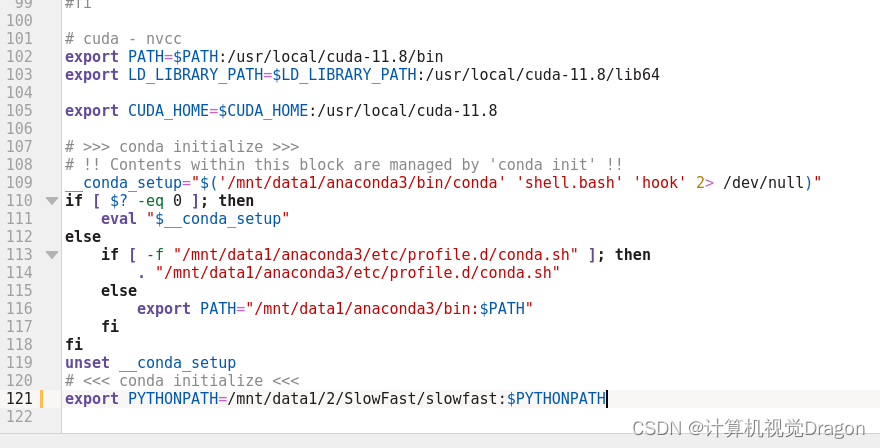
install.md文件第33行提示添加环境变量
然后把
export PYTHONPATH=/path/to/SlowFast/slowfast:$PYTHONPATH这一行修改成你的slowfast项目路径,我这里是
export PYTHONPATH=/mnt/data1/2/SlowFast/slowfast:$PYTHONPATH并且添加到/root/.bashrc(记得显示隐藏文件)文件里面,我添加到末尾了:
3.13Build一下
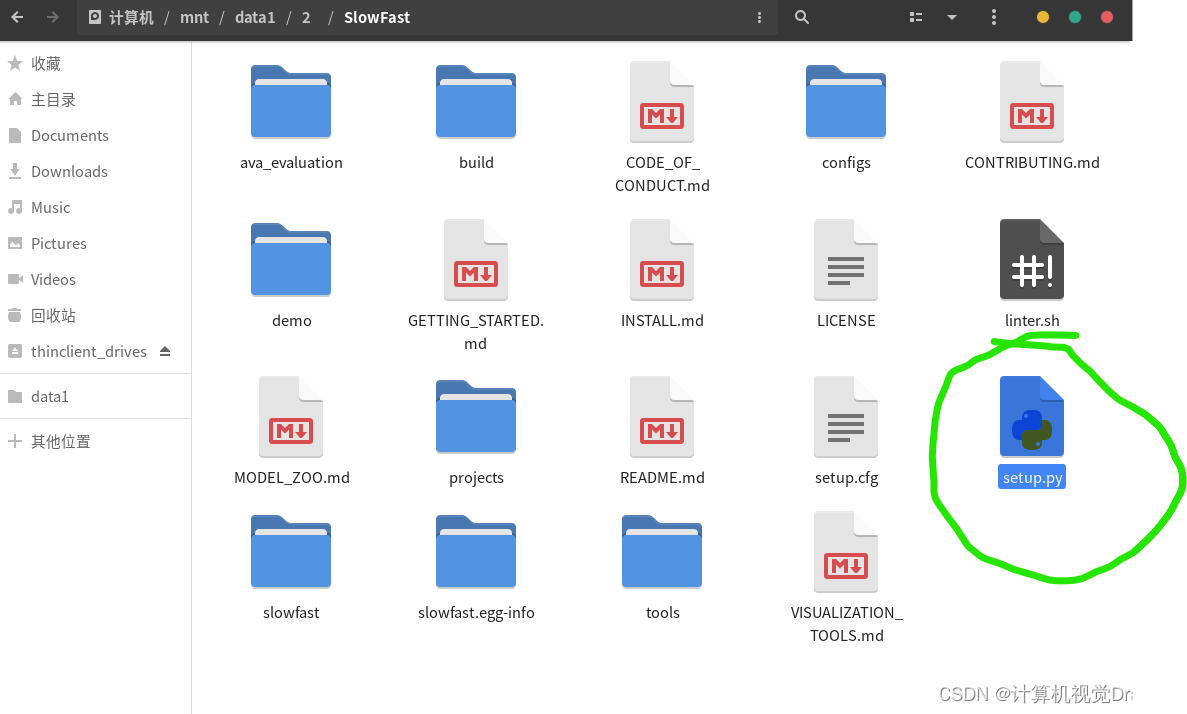
终端cd进SlowFast,注意不是SlowFast下面的那个小写的slowfast
 然后执行
然后执行
python setup.py build develop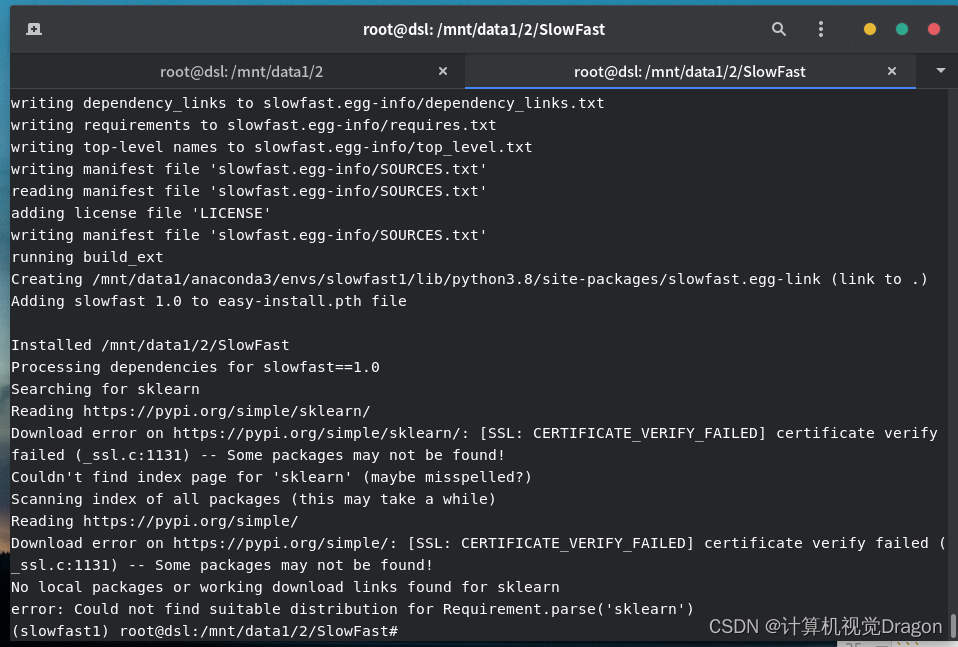
这里提示我没有安装sklearn,那么我们把它的setup.py文件打开修改一下
#!/usr/bin/env python3
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
from setuptools import find_packages, setup
setup(
name="slowfast",
version="1.0",
author="FAIR",
url="unknown",
description="SlowFast Video Understanding",
install_requires=[
"yacs>=0.1.6",
"pyyaml>=5.1",
"av",
"matplotlib",
"termcolor>=1.1",
"simplejson",
"tqdm",
"psutil",
"matplotlib",
"detectron2",
"opencv-python",
"pandas",
"torchvision>=0.4.2",
"PILLOW",
"scikit-learn",
"tensorboard",
"fairscale",
],
extras_require={"tensorboard_video_visualization": ["moviepy"]},
packages=find_packages(exclude=("configs", "tests")),
)
内容替换一下,修改了第26行的PIL以及27行的sklearn,它们两个由于版本的迭代被收进了PILLOW以及scikit-learn。
改完之后我们安装一下scikit-learn,终端输入,把pandas一起装了否则后面还要装
pip install -i https://pypi.douban.com/simple scikit-learn
pip install -i https://pypi.douban.com/simple pandas安装成功
重新在终端执行
python setup.py build develop安装成功
现在环境已经搭建好了,接下来我们准备并且修改一些文件,来测试一下slowfast效果如何。
4.预训练文件、动作标签文件等文件的准备及修改
4.1预训练文件来源
下拉找到Model Zoo,点击

找到这个并且点击下载
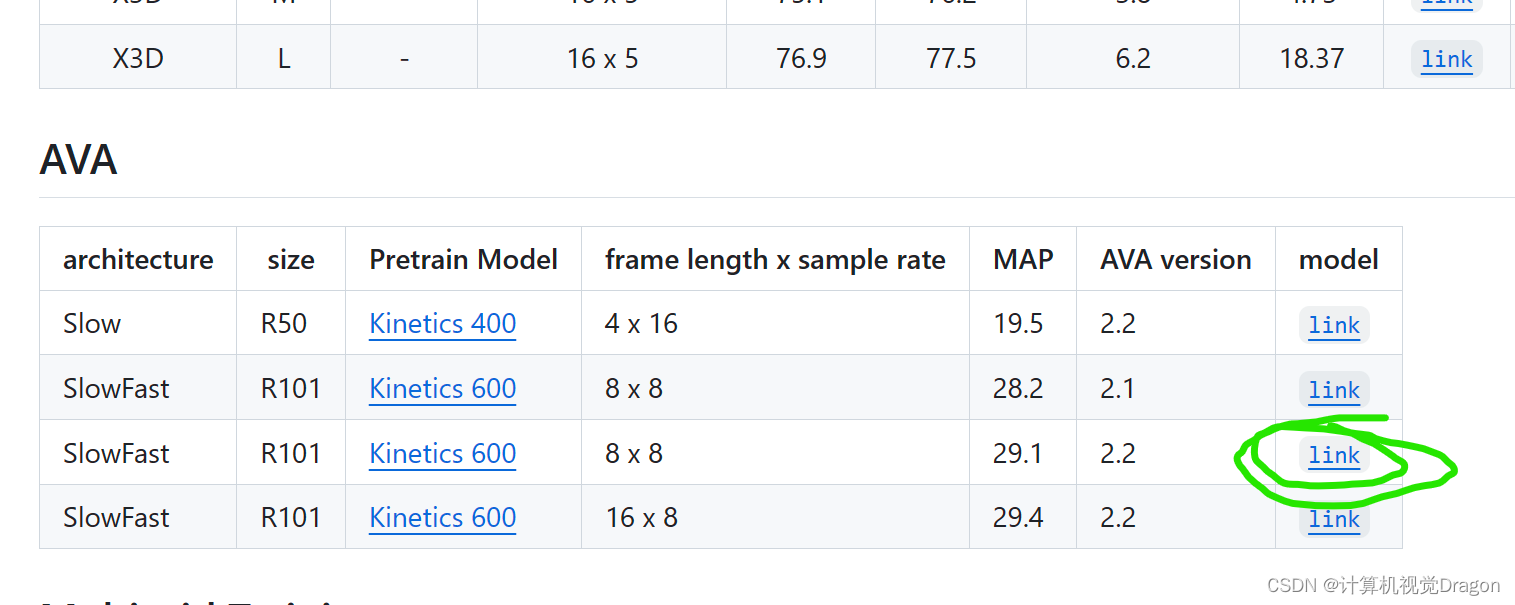
在windows下载好之后传输到linux上面,并且最终放到这个目录下面
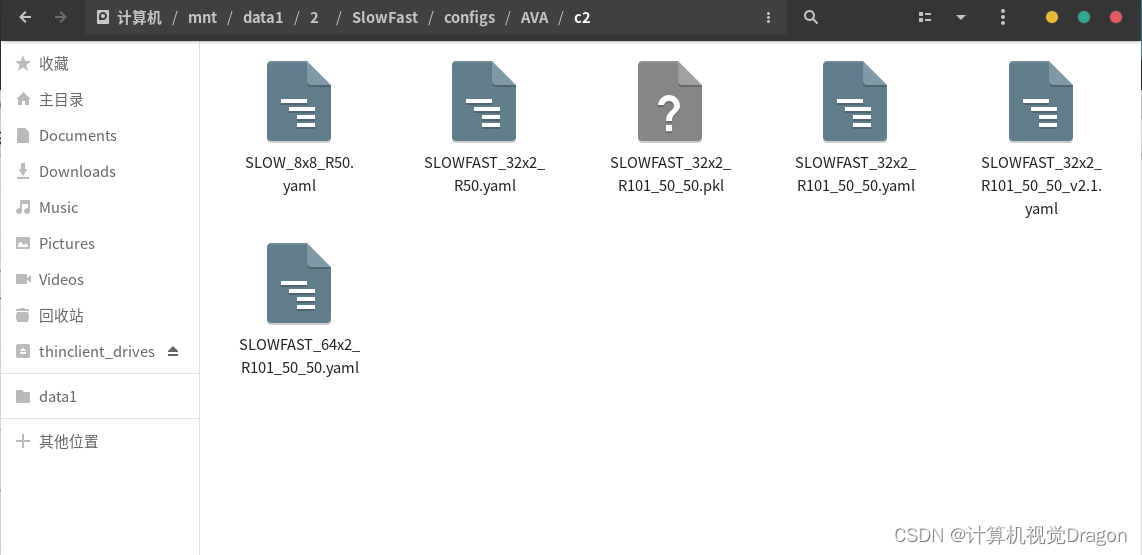
4.2动作标签文件
在/mnt/data1/2/SlowFast/demo/AVA目录下面创建一个叫做ava.json的文件,在终端输入
cd '/mnt/data1/2/SlowFast/demo/AVA'
vim ava.json
在弹出的窗口先输入i,这个时候可以编辑了,然后把下面的复制进去ctrl+shift+v:
{
"bend/bow (at the waist)": 0,
"crawl": 1,
"crouch/kneel": 2,
"dance": 3,
"fall down": 4,
"get up": 5,
"jump/leap": 6,
"lie/sleep": 7,
"martial art": 8,
"run/jog": 9,
"sit": 10,
"stand": 11,
"swim": 12,
"walk": 13,
"answer phone": 14,
"brush teeth": 15,
"carry/hold (an object)": 16,
"catch (an object)": 17,
"chop": 18,
"climb (e.g., a mountain)": 19,
"clink glass": 20,
"close (e.g., a door, a box)": 21,
"cook": 22,
"cut": 23,
"dig": 24,
"dress/put on clothing": 25,
"drink": 26,
"drive (e.g., a car, a truck)": 27,
"eat": 28,
"enter": 29,
"exit": 30,
"extract": 31,
"fishing": 32,
"hit (an object)": 33,
"kick (an object)": 34,
"lift/pick up": 35,
"listen (e.g., to music)": 36,
"open (e.g., a window, a car door)": 37,
"paint": 38,
"play board game": 39,
"play musical instrument": 40,
"play with pets": 41,
"point to (an object)": 42,
"press": 43,
"pull (an object)": 44,
"push (an object)": 45,
"put down": 46,
"read": 47,
"ride (e.g., a bike, a car, a horse)": 48,
"row boat": 49,
"sail boat": 50,
"shoot": 51,
"shovel": 52,
"smoke": 53,
"stir": 54,
"take a photo": 55,
"text on/look at a cellphone": 56,
"throw": 57,
"touch (an object)": 58,
"turn (e.g., a screwdriver)": 59,
"watch (e.g., TV)": 60,
"work on a computer": 61,
"write": 62,
"fight/hit (a person)": 63,
"give/serve (an object) to (a person)": 64,
"grab (a person)": 65,
"hand clap": 66,
"hand shake": 67,
"hand wave": 68,
"hug (a person)": 69,
"kick (a person)": 70,
"kiss (a person)": 71,
"lift (a person)": 72,
"listen to (a person)": 73,
"play with kids": 74,
"push (another person)": 75,
"sing to (e.g., self, a person, a group)": 76,
"take (an object) from (a person)": 77,
"talk to (e.g., self, a person, a group)": 78,
"watch (a person)": 79
}然后键盘依次按下Esc、大写键、Z、Z,一共两个Z,成功退出保存。
4.3修改配置文件
这个文件点开
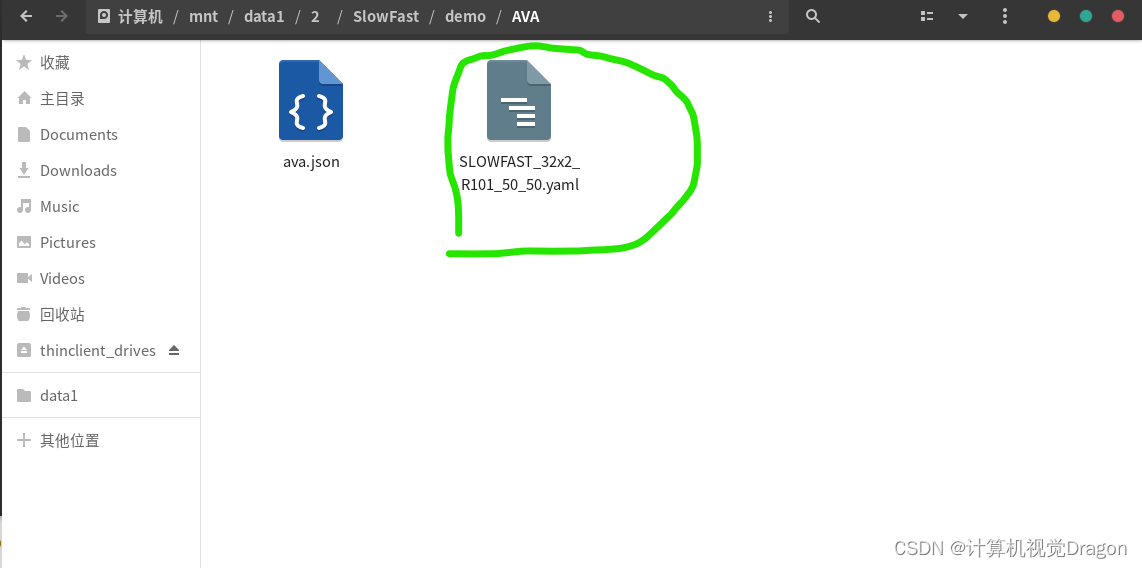
输入:
TRAIN:
ENABLE: False
DATASET: ava
BATCH_SIZE: 16
EVAL_PERIOD: 1
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: '/mnt/data1/2/SlowFast/configs/AVA/c2/SLOWFAST_32x2_R101_50_50.pkl' #path to pretrain model
CHECKPOINT_TYPE: pytorch
DATA:
NUM_FRAMES: 32
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 256
INPUT_CHANNEL_NUM: [3, 3]
DETECTION:
ENABLE: True
ALIGNED: False
AVA:
BGR: False
DETECTION_SCORE_THRESH: 0.8
TEST_PREDICT_BOX_LISTS: ["person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 5
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 101
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[6, 13, 20], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 80
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: False
DATASET: ava
BATCH_SIZE: 8
DATA_LOADER:
NUM_WORKERS: 2
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .
#TENSORBOARD:
#MODEL_VIS:
#TOPK: 2
DEMO:
ENABLE: True
LABEL_FILE_PATH: '/mnt/data1/2/SlowFast/demo/AVA/ava.json'
INPUT_VIDEO: "/mnt/data1/2/input/1.mp4"
OUTPUT_FILE: "/mnt/data1/2/output/1.mp4"
#WEBCAM: 0
DETECTRON2_CFG: "COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml"
DETECTRON2_WEIGHTS: detectron2://COCO-Detection/faster_rcnn_R_50_FPN_3x/137849458/model_final_280758.pkl
修改了第8行的预训练文件路径,pkl结尾那个
注释掉了70、71、72、78行
并且添加了两行路径作为视频输入inputt和输出output,这两个文件夹已经在第2步创建过了。
修改了动作标签文件的路径,第75行ava.json文件
保存退出。
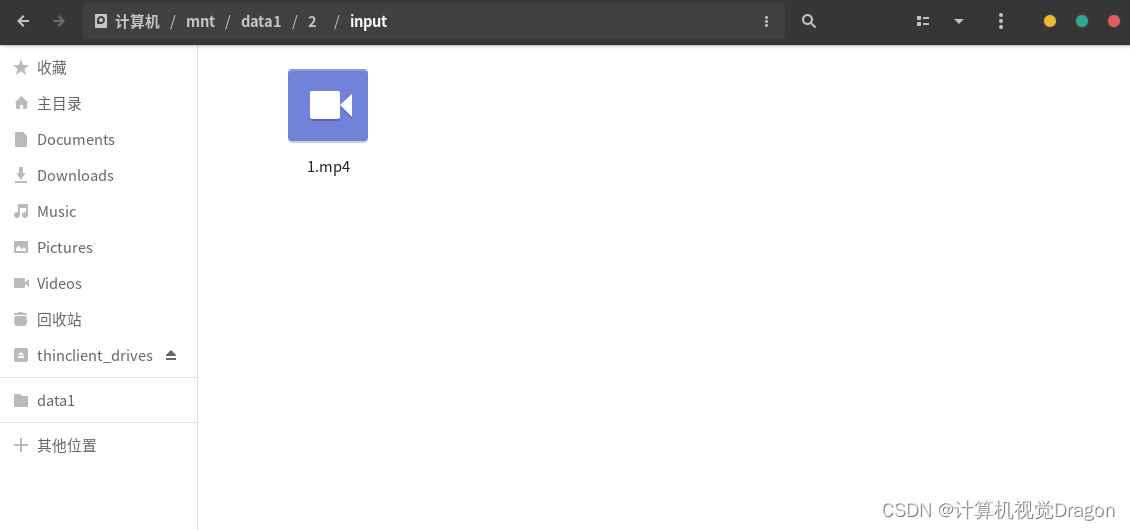
4.4准备一个视频准备测试
随便找一个MP4格式的视频文件,我这里是准备的叶问打架。并且将文件名改成1.mp4放到/mnt/data1/2/input路径下面,这与我们4.3的配置文件的第76行是对应的。
在终端激活环境并且cd进这个
cd '/mnt/data1/2/SlowFast'
然后输入:
python tools/run_net.py --cfg demo/AVA/SLOWFAST_32x2_R101_50_50.yaml报错?????汗流浃背了家人们,虽然我以前碰到过
4.5错误解决
第一个错误
ImportError: cannot import name 'cat_all_gather' from 'pytorchvideo.layers.distributed' (/mnt/data1/anaconda3/envs/slowfast1/lib/python3.8/site-packages/pytorchvideo/layers/distributed.py)
把压缩包下载下来解压,然后传到我的Linux服务器上面,放在/mnt/data1/2这个目录
然后终端cd进去,并且安装
cd '/mnt/data1/2/pytorchvideo'
pip install -i https://pypi.douban.com/simple -e .4.6视频测试
终端输入
cd '/mnt/data1/2/SlowFast'
python tools/run_net.py --cfg demo/AVA/SLOWFAST_32x2_R101_50_50.yaml
等待一会
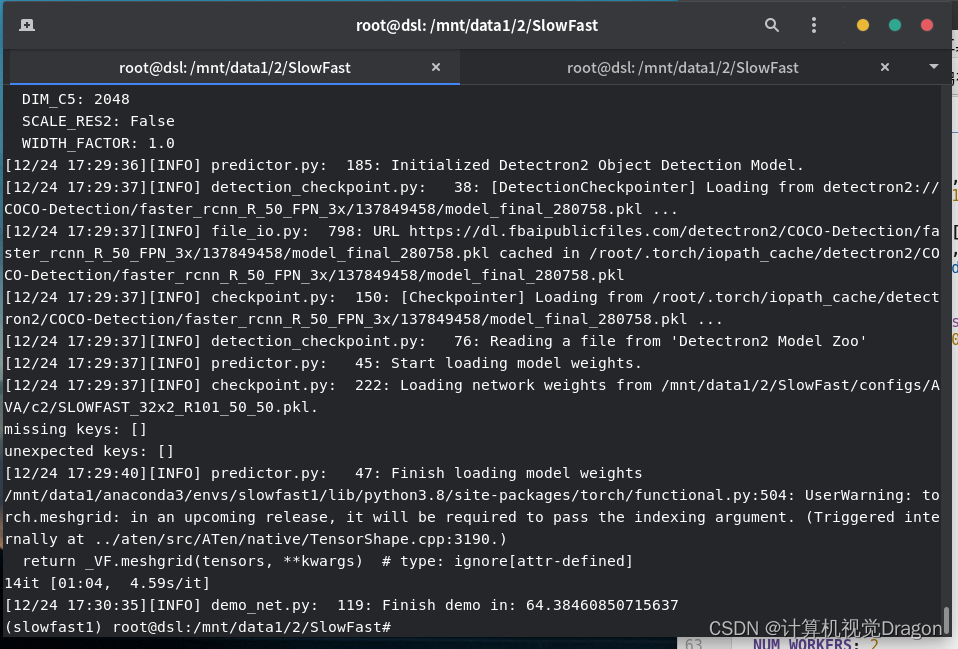
最后成功生成的视频保存在
这个路径是我们在4.3修改配置文件那里指定好的路径。
我的linux没搞播放器,我用winscp传输到Windows之后看效果:
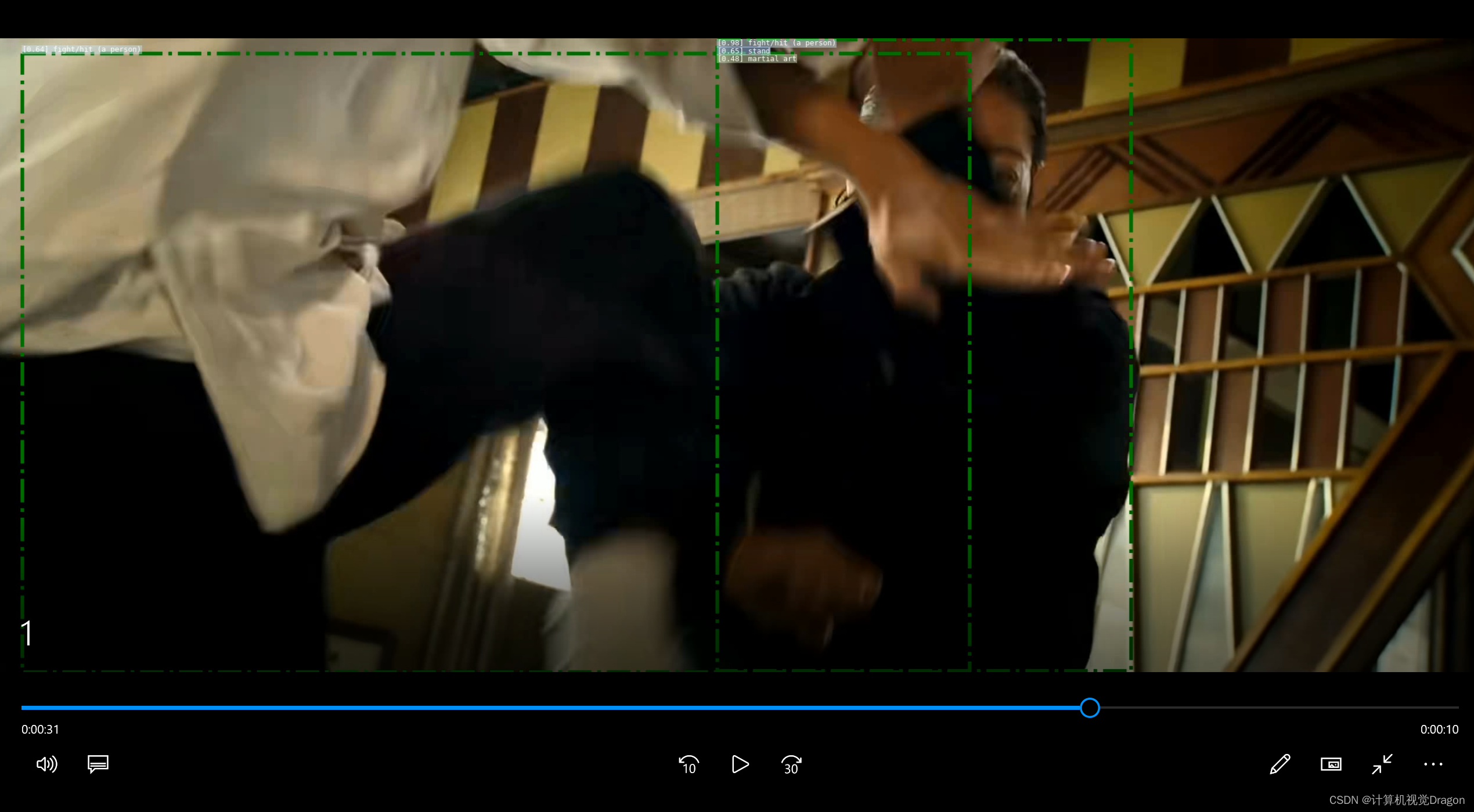
放大看看框框左上角标签,我截图的是右边框的标签,是fight没错了
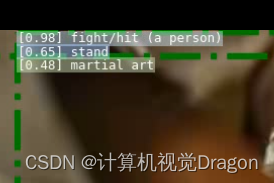
搞定!















 7447
7447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









