






1. Graph U-Net(2019)
虽然像U-Nets这样的编码器-解码器架构已经成功地应用于图像像素预测任务,但对于图形数据却缺乏类似的方法。这是因为池化和上采样操作在图数据上并不自然。为了解决这些挑战,我们提出了新的图池化和解池化操作。gPool层根据节点的标量投影值自适应选择节点组成较小的图。我们进一步提出gUnpool层作为gPool层的逆操作。
基于我们提出的方法,我们开发了一个编码器-解码器模型,称为图U-Nets。在节点分类和图分类任务上的实验结果表明,我们的方法始终比以前的模型具有更好的性能。沿着这个方向,我们通过整合注意力机制来扩展我们的方法。在注意算子的基础上,提出了基于注意的池化和解池化层,可以更好地捕获图的拓扑信息。
像U-Net[14]这样的编码器-解码器架构是完成这些任务的最先进的方法。因此,为图形数据开发类似u - net的架构是非常有趣的。除了卷积之外,池化和上采样操作也是这些体系结构中必不可少的组成部分。然而,将这些操作扩展到图形数据是非常具有挑战性的。与类似网格的数据(如图像和文本)不同,图中的节点没有常规池化操作所需的空间局部性和顺序信息。
为了弥补上述差距,我们在这项工作中提出了新的图池(gPool)和解池(gUnpool)操作。基于这两种操作,我们提出了类似u - net的图形数据架构。gPool操作对一些节点进行采样,根据它们在可训练投影向量上的标量投影值形成一个较小的图。作为gPool的逆操作,我们提出了相应的图解池(gUnpool)操作,该操作通过在相应的gPool层中选择节点的位置,将图恢复到其原始结构。在gPool和gUnpool层的基础上,我们开发了图形U-Nets,它允许高层次的特征编码和解码用于网络嵌入。在节点分类和图分类任务上的实验结果证明了本文方法的有效性
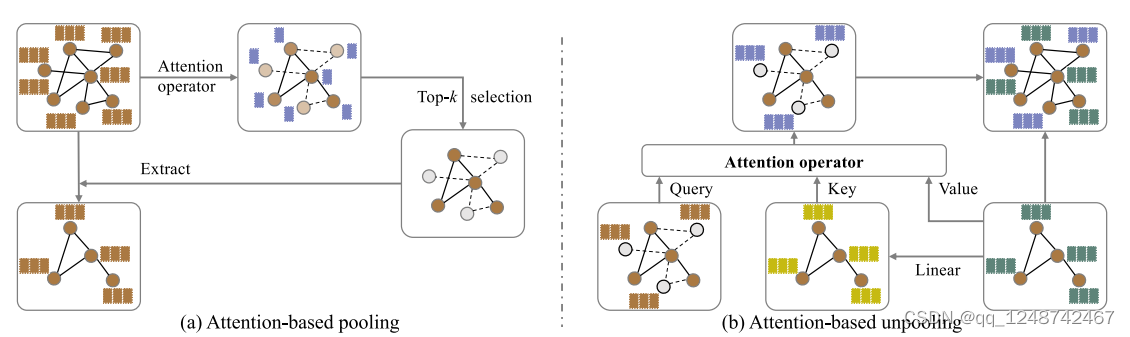
在会议版本的基础上(2019年版本的Graph U-Net),我们继续探索基于注意力的图池化和解池化操作。特别地,我们提出了基于注意力的图池层,它使用一个注意力算子来生成排名分数。注意算子可以帮助捕获图的拓扑信息,从而得到连接更好的粗化图,保留更多的图拓扑信息。在基于注意的图解池层中,我们利用注意算子填充恢复节点的特征向量。具体地说,每个添加的节点都关注其相邻节点和使用注意运算符的输出特征初始化。
1.1 Graph Pooling Layer
局部池化和全局池化
转移到图上遇到的问题:
- 图中的节点之间没有局部性信息—>分区操作不适用于图
- 全局池操作将所有节点缩减为一个节点,这限制了网络的灵活性 k-max
- 池化操作输出可能来自图中不同节点的k个最大单元,从而导致所选节点的连接不一致
graph polling(gPool):自适应地选择节点子集以形成新的但更小的图
池化层在网格类数据cnn中起着重要的作用。它们可以减小特征映射的大小,扩大接受域,从而产生更好的泛化和性能[28]。
对于像图像这样的网格数据,特征映射被分割成不重叠的矩形,在这些矩形上应用非线性下采样函数,如maximum。除了局部池化之外,全局池化层[29]对所有输入单元执行下采样操作,从而将每个特征映射减少到单个数字。相比之下,k-max池化层[30]从每个特征映射中选择k个最大的单元。
然而,**我们不能直接将这些池化操作应用于图。特别是,图中节点之间没有位置信息。特别是图中的每个节点没有固定数量的相邻节点,它们的相邻节点不是自然有序的。**在规则池化层中,输入特征映射根据它们的相对位置进行分区。网格结构可以很好地支持这些分区操作。由于缺乏局部性信息,分区操作不适用于图。
全局池化操作将所有节点减少到一个节点,限制了网络的灵活性。k-max池化操作输出k个最大的单元,这些单元可能来自图中的不同节点,导致所选节点的连通性不一致。————————这也是为什么2022版本的Graph U-Net要对2019年的进行改进

值得注意的是,门运算使得投影向量p可以通过反向传播[1]进行训练。没有门操作,投影向量p产生离散输出,这使得它不能通过反向传播进行训练。图2展示了我们提出的图池化层。与在类网格数据中使用的池化操作相比,我们的图池化层在投影向量p中使用了额外的训练参数。我们将证明,这些额外的参数可以忽略不计,但可以显著提高网络性能
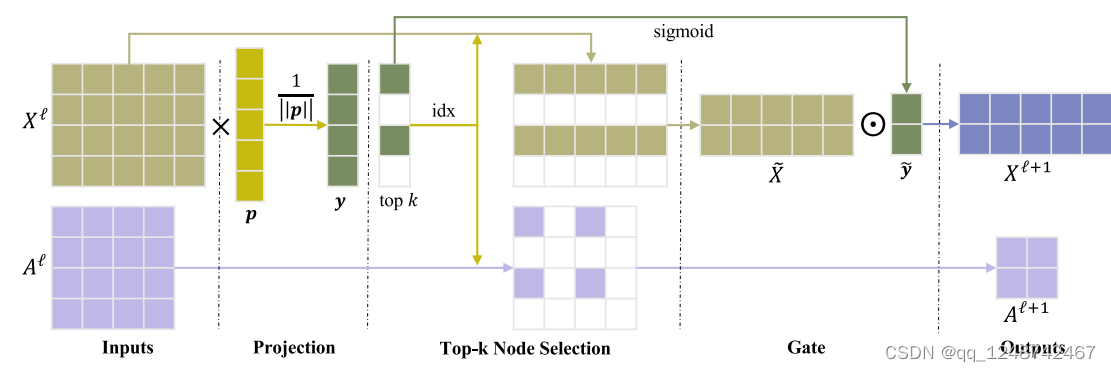
1.2 Graph Unpooling Layer
我们可以利用来自相应池化层的信息。特别是,我们记录了在相应的gPool层中选择的节点的位置,并使用该信息将节点放回到图中的原始位置。
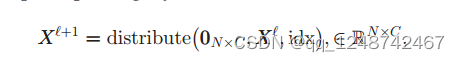
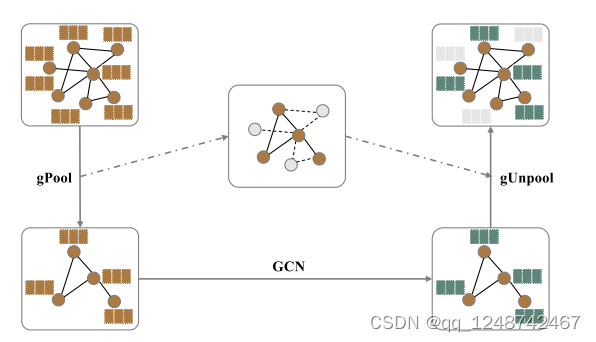
1.3 Graph U-Net结构
在我们的图U-Nets (g-U-Nets)中,我们首先应用图嵌入层将节点转换为低维表示,因为一些数据集(如Cora[34])的原始输入通常具有非常高维的特征向量。在图嵌入层之后,我们通过堆叠几个编码块来构建编码器,每个编码块包含一个gPool层和一个GCN层。gPool层减少图的大小来编码高阶特征,而GCN层负责从每个节点的一阶信息中聚合信息
1.4 Graph Connectivity Augmentation via Graph Power In our propose
在我们提出的gPool层中,我们对一些重要节点进行采样,形成一个用于高级特征编码的新图。
由于在删除gPool中的节点时会删除相关边,因此池图中的节点可能会被隔离。这可能会影响后续层的信息传播,特别是当GCN层用于聚合来自相邻节点的信息时。我们需要增加池图中节点之间的连通性。
对一些重要节点进行采样,形成一个新的图,用于高级特征编码,池化之后,一些边会消失,影响了图的连通性,进而影响到聚合—>我们需要增加池图中节点之间的连通性
方法:使用图幂,邻接矩阵的𝑘=2次方等于𝑘跳机以内可以连接的点
该操作在距离最多为k跳[35]的节点之间建立链路。
在这项工作中,我们使用k=2,因为在每个gPool层之前都有一个GCN层来聚合来自其一阶相邻节点的信息。形式上,我们将(7)式中的第五个方程替换为
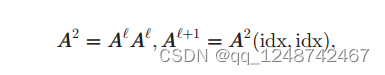
A^2是graph的2次幂图。现在,在连接性更好的增广图上进行图采样
2 Graph U-Net(2022)
在本节中,我们将介绍基于注意力的图池(attnPool)层和基于注意力的图解池(attnUnpool)层。我们基于这两层构建了基于注意力的图U-Nets。
注意算子在解决各个领域的挑战性任务方面已经显示出了它的能力。
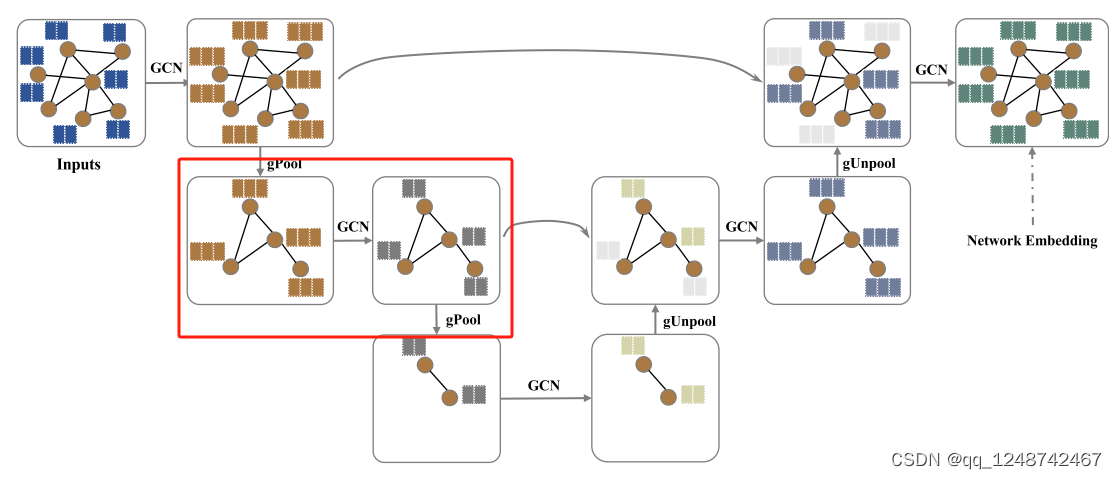
红色部分为一个Block,包干一个卷积和pool操作
3. main.py
# GNet是需要用到的model
net = GNet(G_data.feat_dim, G_data.num_class, args) # graph, 特征维度,类别数,参数
trainer = Trainer(args, net, G_data) #开始训练数据
# 正式开始训练数据
trainer.train()
3.1 network.py
class GNet(nn.Module):
def __init__(self, in_dim, n_classes, args):
super(GNet, self).__init__()
self.n_act = getattr(nn, args.act_n)()# getattr() 是 Python 内置的一个函数,可以用来获取一个对象的属性值或方法
self.c_act = getattr(nn, args.act_c)()# print('GNet1: in_dim=', in_dim, 'n_class=',n_classes) # GNet1: in_dim= 82 n_class= 2
"用的是GCN的框架,输入分别是feat dim、layer dim、network act、drop net(net表示GCN网络本身的参数)"
self.s_gcn = GCN(in_dim, args.l_dim, self.n_act, args.drop_n)
self.g_unet = GraphUnet(args.ks, args.l_dim, args.l_dim, args.l_dim, self.n_act, args.drop_n)
"""nn.Linear定义一个神经网络的线性层,方法如下:
torch.nn.Linear(in_features, # 输入的神经元个数
out_features, # 输出神经元个数
bias=True # 是否包含偏置)"""
self.out_l_1 = nn.Linear(3*args.l_dim*(args.l_num+1), args.h_dim)
self.out_l_2 = nn.Linear(args.h_dim, n_classes)
"nn.Dropout(p = 0.3) # 表示每个神经元有0.3的可能性不被激活"
self.out_drop = nn.Dropout(p=args.drop_c)
Initializer.weights_init(self)
def forward(self, gs, hs, labels):
print('GNet2: gs=',type(gs), len(gs), 'hs=',type(hs), len(hs), 'labels:',type(labels),labels.shape)
# GNet2: gs= <class 'list'> 32 hs= <class 'list'> 32 labels: <class 'torch.Tensor'> torch.Size([32])
hs = self.embed(gs, hs)
print('GNet2: hs=', type(hs), hs.shape)
logits = self.classify(hs)
return self.metric(logits, labels)
3.3 代码对应
输入图中的每个节点都有两个特征
使用GCN层将输入特征向量转换为低维表示
h = self.s_gcn(g, h)
然后堆叠两个编码器块,每个块包含一个gPool层和一个GCN层。
for i in range(self.l_n):
h = self.down_gcns[i](g, h)
adj_ms.append(g)
down_outs.append(h)
g, h, idx = self.pools[i](g, h)
indices_list.append(idx)
对于同一级别的块,编码器块使用skip connection来融合来自编码器块的低级空间特征。
h = h.add(down_outs[up_idx])
在解码器部分,也有两个解码器块。每个块由gUnpool层和GCN层组成。
for i in range(self.l_n):
up_idx = self.l_n - i - 1
g, idx = adj_ms[up_idx], indices_list[up_idx]
g, h = self.unpools[i](g, h, down_outs[up_idx], idx)
h = self.up_gcns[i](g, h)
h = h.add(down_outs[up_idx])
最后一层节点的输出特征向量是网络embedding,可用于节点分类、链路预测等多种任务
幂图来减少独立点的存在在gpool中【未完】
4 Queation
4.1【Question1】
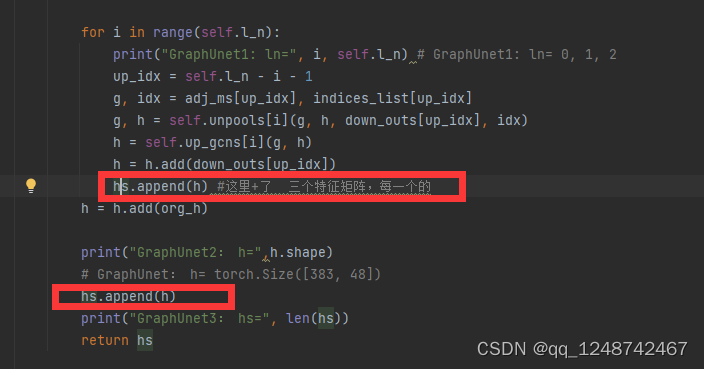
为什么需要hs这个参数呢?意义何在???
4.2【Question2】
def readout(self, hs):
"""input is GraphUnet's output"""
h_max = [torch.max(h, 0)[0] for h in hs]
h_sum = [torch.sum(h, 0) for h in hs]
h_mean = [torch.mean(h, 0) for h in hs]
h = torch.cat(h_max + h_sum + h_mean)
return h
这个readout的作用是啥???
4.3【Question3】
Cnn中进行pooling是为了扩大视野域,而在这种pooling操作下,gcn是无法扩大视野域的,因其采样并非局部性的,并且,多进行几次特征传播,gcn的视野域就可以扩大到k阶相邻的node。
而这种操作的unpooling操作,次数越多,会使得decode之后的graph全0的节点数目越多,肯定会丧失很多的信息。
5. 2019 Vs 2022
Graph U-Net(2019)
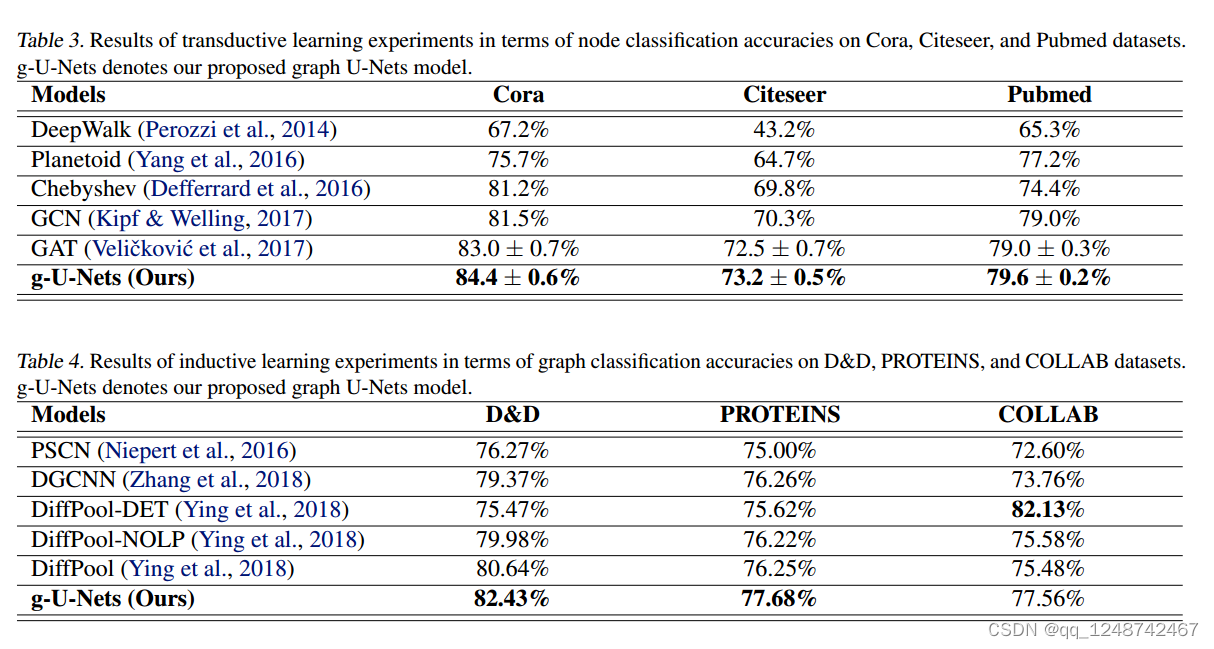
Graph U-Net(2022)
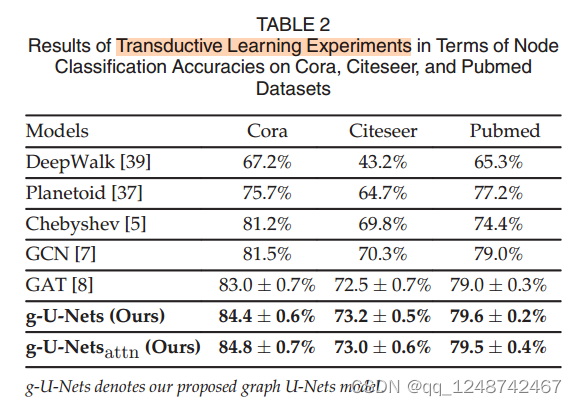
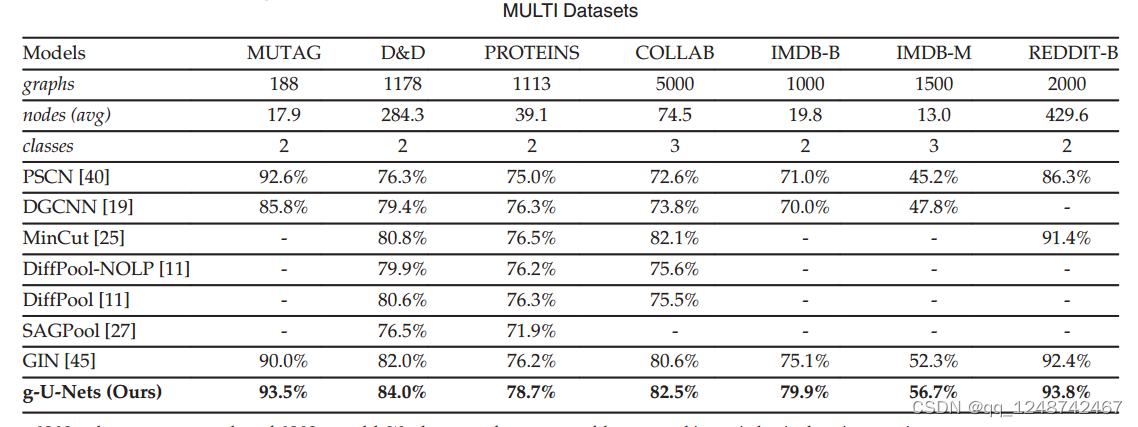















 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









