









1.本次课程大纲
- 局部加权回归: 线性回归的变化版本
- Probability interpretation:另一种可能的对于线性回归的解释
- Logistic回归: 基于2的一个分类算法
- 感知器算法: 对于3的延伸,简要讲
- 牛顿方法(用来对logistic进行拟合的算法,这节课没讲)
2.过拟合与欠拟合的距离
评估房子的价格,假设三种拟合算法:
(1)X1=size, 拟合出一条线性曲线;
(2)x1=size,x2=(size)2,拟合出一条二次曲线;
(3)训练集共有7个数据,建立六个特征,拟合出一个六次多项式。
对于第三种方案, J(θ)=0 ,可以完全拟合这7个数据点,但是并不能反映出真实的房价,属于过拟合的一个极端例子;第一种情况由于特征不足,未能捕获到一些数据点,同样未能很好的展示房价的趋势,属于欠拟合的例子;相比于第一和第三,第二种情况较为合理(只是同第一第三相比较,具体是否欠拟合或过拟合,还需验证)
So, two problems:
a) How to judge whether a hypothesis is over fitting or under fitting?
Andrew Ng教授是这么说的:对于一个监督学习模型来说,过小的特征集合使得模型过于简单,过大的特征集合使得模型过于复杂。
Summarize:
对于特征集过小的情况,称之为欠拟合(underfitting);
对于特征集过大的情况,称之为过拟合(overfitting)
b) How to solve these two problems above?
(1) 特征选择算法:一类自动化算法,在这类回归问题中选择用到的特征
(2)非参数学习算法:缓解对于选取特征的需求,引出局部加权回归
3.非参数学习算法:可以不用考虑特征选择
参数学习算法(parametric learning algorithm):参数学习算法是一类有固定数目参数,以用来进行数据拟合的算法。线性回归即使参数学习算法的一个例子。
下面是非参数学习方法
局部加权回归(LOESS):距离较近的点贡献的权重大,用一个波长参数控制距离对贡献的影响大小。(即便是无参的,仍然不能避免过拟合和欠拟合,权重参数仍然影响拟合的准确性),那么如何确定bandwidth parameter?
总结:对于局部加权回归,每进行一次预测,都要重新拟合一条曲线。但如果沿着 x 轴对每个点都进行同样的操作,你会得到对于这个数据集的局部加权回归预测结果,追踪到一条非线性曲线。
4.概论解释
根据经验发现:高斯分布是回归问题中误差分布的很好假设。另外用高斯分布假设误差在数学上也便于处理。
似然性与概率,说法上的区别,数据的概率、参数的似然性。
极大似然估计:chooseθ to maximize the likelihood. In other words, choose the parameter to make the data as probably big as possible. 即选择恰当的参数,使得数据出现的可能性尽可能的大。
为了数学上的便利性,定义θ的似然性L(θ)=log L(θ)(注:在一些实际数学建模应用时经常这样,比如现有一组微博用户的数据,数据中有这样一个维度特征:一个账号所发微博数,假设现在想挖掘微博意见领袖,把账号所发微博数作为一个特征,而我们认为发10条微博与发100条微博用户有明显的活跃度不同,而发1000条微博与发1090条微博的活跃差明显不如10条与100条的,所以此时最好先用LOG对数据进行预处理;同理,对数据的平滑处理也是一个道理)
最小二乘法解决的问题:最小化成本函数,寻找最佳θ拟合曲线。
但为什么是最小二乘,而不是面积绝对值或其他?
由此概率解释引出以下第一个要学习的分类算法
5.Sigmoid function和Logistic回归算法
先介绍一个Sigmoid函数:
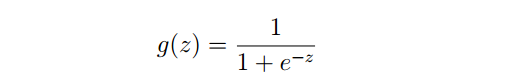
它的函数图如下所示

这是要学习的第一个分类算法。之前的回归问题尝试预测的变量y是连续变量,在这个分类算法中,变量y是离散的,y只取{0,1}两个值。
一般这种离散二值分类问题用线性回归效果不好。比如x<=3,y=0;x>3,y=1,那么当x>3的样本占得比例很大是,线性回归的直线斜率就会越来越小,y=0.5时对应的x判决点就会比3大,造成预测错误。
classification 目标值是离散的,例如0,1.(eg,判断肿瘤是否良性);对此类分类问题应用线性回归是一个糟糕的主意。
解决肿瘤的问题,令

我们会得到一个极大似然函数:

对极大似然函数取对数

接下来怎么去的这个函数的最大值呢?下面是推导过程,对
θ
求偏导;

事实上,我们使用的是 g′(z)=g(z)(1−g(z)) ,因此可以得到下面这个梯度上升算法:
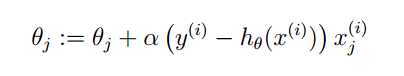
6.感知器算法
在logistic方法中,g(z)会生成[0,1]之间的小数,但如何是g(z)只生成0或1?
所以,感知器算法将g(z)定义如下:
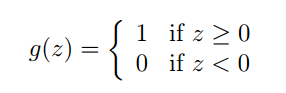
说明:可以根据这个感知器算法对我们的回归结果做一个分类处理。下面是感知学习算法的整个公式:

总结的不是很好,做个笔记,一步一步改善吧。
Referenc
视频链接:http://open.163.com/movie/2008/1/E/B/M6SGF6VB4_M6SGHM4EB.html















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









