







概要
本节课的主要内容有:
1、欠拟合与过拟合
2、 局部加权回归
3、 最小二乘法的概率解释
4、 Logistic回归
5、 感知器算法
一、欠拟合与过拟合
在机器学习中,通常需要选择某种算法来对数据进行预测,而过拟合与欠拟合就是描述对数据的预测与真实数据之间的拟合程度。
例如上次课的例子中,用x1表示房间大小。通过线性回归,在横轴为房间大小,纵轴为价格的图中,画出拟合曲线。回归的曲线方程为: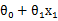

如果再增加特征集合,比如:x1表示房子大小,x2表示房子大小的平方,使用相同的算法,拟合得到一个二次函数,则会在图中形成一个抛物线,即:

如果特征集合一直增加,得到的曲线就会越接近真实的数据;如果特征集合过少,得到的预测可能就会偏离真实数据。
那是否特征集合越多越好呢?答案是否定的。因为特征集合越多,虽然本次数据拟合的很好,但却 失了一般性。即它可能只对这一组数据拟合的很好,而对于其他的数据则拟合很差。
总结:
过拟合就是特征集过大,对某一组数据拟合程度太高, 以至于失了一般性。
欠拟合就是特征集过小,对某一组数据拟合程度太低,描述不出其应有的特点。
参数学习算法(parametric learning algorithm)
定义:参数学习算法是一类有固定数目参数,以用来进行数据拟合的算法。设该固定的参数集合为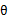
非参数学习算法(Non-parametric learning algorithm)
定义:一个参数数量会随m(训练集大小)增长的算法。通常定义为参数数量随m线性增长。换句话说,就是算法所需要的东西会随着训练集合线性增长,算法的维持是基于整个训练集合的,即使是在学习以后。接下来要讨论的局部加权回归即属于此类。
二、局部加权回归
局部加权回归算法是对线性回归的拓展,当目标假设是线性模型时,使用线性回归自热能拟合的很好,但如果目标假设不是线性模型,比如忽上忽下的函数,这是线性模型就拟合的很差。为了解决这个问题我们在预测一个值时,选择和这个点相近的点而不是全部的点做线性回归。基于这个思想就有了局部加权回归。
对于局部加权回归,当要处理x时:
1) 检查数据集合,并且只考虑位于x周围的固定区域内的数据点
2) 对这个区域内的点做线性回归,拟合出一条直线
3) 根据这条拟合直线对x的输出,作为算法返回的结果

局部加权回归它的目标函数是加权的最小二乘法。如下:
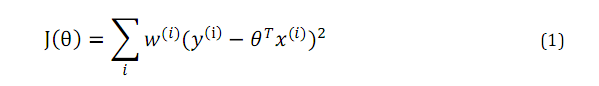
其中w是权值,它的范围是0-1,当离要预测点越远时,权值越小,否则较大。即使得里的较远的点对预测点影响较小,离得较近的点对预测点影响较大。
w可以有很多选择,一个比较好的选择是下面这个函数:

这个函数具有上面所描述的w的性质。虽然它的形状和高斯分布有些相似,但不是高斯分布。
被称作波长函数,它控制了权值随距离下降的速率。它越小,钟形越窄,w衰减的很快;它越大,衰减的就越慢。
局部加权回归的问题:
由于每次进行预测都要根据训练集拟合曲线,若训练集太大,每次进行预测的用到的训练集就会变得很大,Andrew Moore的关于KD-tree的算法可以对该问题进行优化。
三、最小二乘法的概率解释
在线性回归中,为什么选择最小二乘作为计算参数的指标,使得假设预测出的值和真正y值之间面积的平方最小化?
我们提供一组假设,证明在这组假设下最小二乘是有意义的,但是这组假设不唯一,还有其他很多方法可以证明其有意义。
(1) 假设
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3042
3042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









