







Ollama :
Ollama 是一个专注于大语言模型(LLM)本地运行的工具,它允许用户在本地计算机上运行和使用各种大型语言模型,而无需依赖云服务。Ollama 的目标是为开发者和研究人员提供一个方便的平台,以便他们能够直接在个人设备上运行类似于 GPT 类的模型,并进行推理和开发应用。
我们使用 Ollama 来部署大模型 ,大模型下载到本地后,直接执行 Ollama 的相关命令,即可和大模型 进行对话或者使用大模型。我们不需要去写任何代码。
用户友好的界面: Ollama 提供了一些易于使用的命令行工具和 API,方便开发者和用户与模型进行交互。这使得它适用于不同的使用场景,不论是开发、研究还是日常使用。
但是:
并不是说所有的大模型 都可以使用 Ollama 部署的 。可是使用 Ollama 部署的大模型的前提条件是 :大模型的开发者 把 大模型 开源到了 Ollama 里 供用户下载使用。
可以理解为 大模型的类型 也是有很多种的调用方式的,这个和大模型的文件后缀有关,一会再来分享 大模型的各种文件后缀。
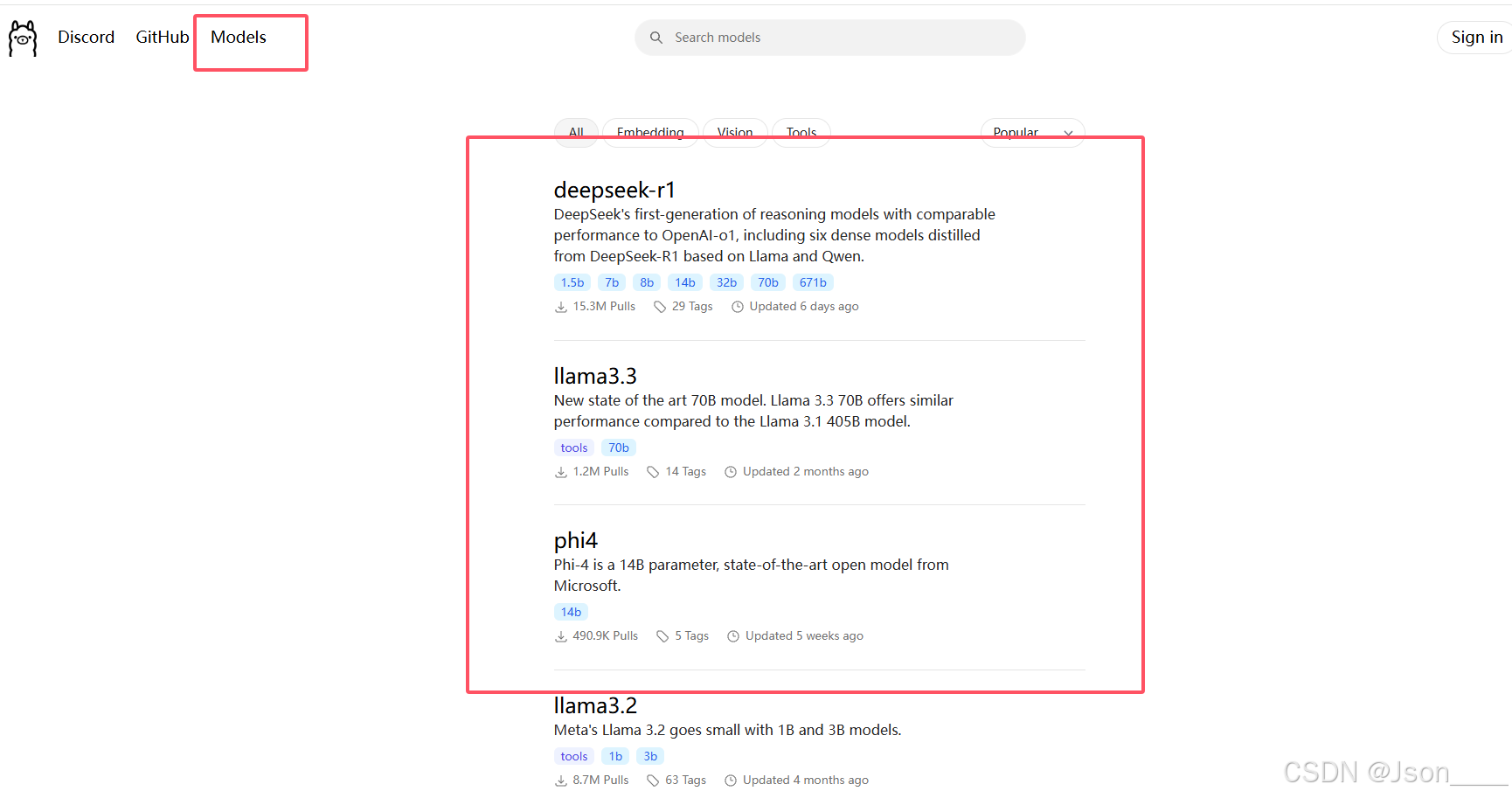
下面这个截图 就是 Ollama 可以支持的大模型 有哪些 ,大佬们开源出来的大模型
我们想下载 Ollama 支持的大模型 去他们官网搜索 即可。
使用 Ollama 来部署大模型 相对于别的方式 就毕竟简单了。
Hugging Face
Hugging Face 是一个非常流行的开源社区和平台,许多开源的大模型(如 BERT、GPT、T5 等)都在这里提供,用户可以方便地下载和使用。Hugging Face 提供了一个非常丰富的模型库,涵盖了各种自然语言处理(NLP)任务(如文本生成、翻译、问答、文本分类等)。
‘
简单的理解 Hugging Face 网站 是提供了 各种各样的开源大模型 ,还有 训练集 。
Hugging Face 平台 所开源的大模型 到底支持什么样的部署和调用 。
参考下面截图
我们在网站上点击 我们需要的大模型 详情后 右边有个按钮 :user this model
在这里可以看到 他支持的调用方式。
截图里的 特意找了有个 多的调用方式的类型,让大家参考 。
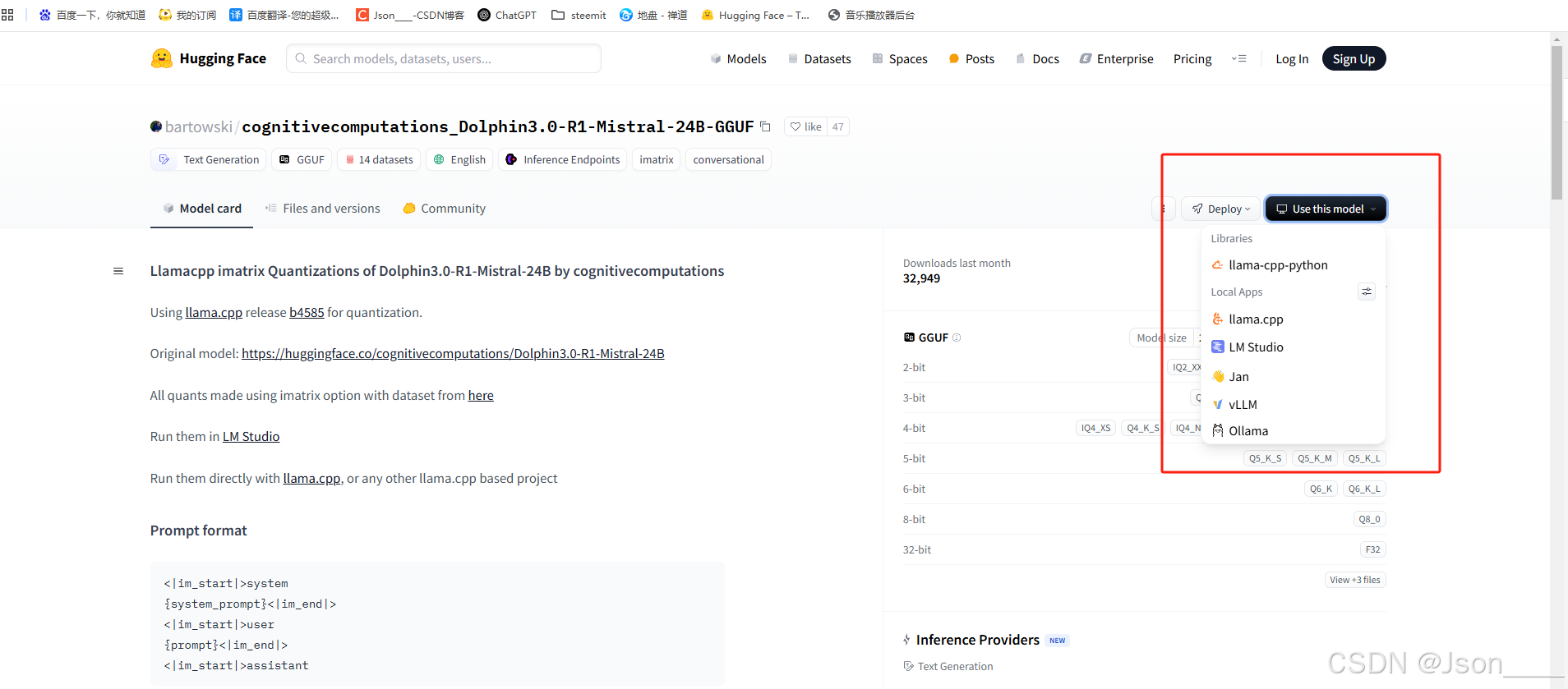
使用 Hugging Face Transformers + PyTorch/TensorFlow(自己写代码)
优点:
高度灵活性:可以完全控制模型的加载、推理过程和优化方式。你可以自定义和调整各种参数,进行模型微调,或执行特定的处理。
广泛的模型支持:Hugging Face 提供了大量的预训练模型,支持各种 Transformer 类型的大模型。
丰富的社区和文档:Hugging Face 的文档、教程和社区非常活跃,你可以轻松找到关于如何使用和优化模型的资源。
缺点:
需要更多的代码:需要编写加载模型、准备输入、处理输出的代码。对于没有经验的人来说,可能需要时间来学习如何使用相关库。
计算资源要求较高:如果不优化,使用 PyTorch/TensorFlow 等框架可能需要较多的内存和计算资源,尤其对于超大模型。
适合情况:
如果你需要对模型进行深入的定制、微调,或者集成到自己的应用中,选择使用 Transformers + PyTorch/TensorFlow 是最合适的。
如果你需要对推理流程有完全的控制,或者你对性能优化(例如量化、并行计算等)有要求,自己编写代码将提供最大的灵活性。
vLLM
Hugging Face 平台的大模型 大多数 都支持 vLLM 。
那么 vLLM 是什么呢?
vLLM(全称 “Very Large Language Model”)是一个专门针对 大规模语言模型(尤其是需要进行推理的 LLMs,如 GPT 系列、BERT 等)优化的框架。它的设计目的是为了使得在本地或者云端部署大模型时,能够更高效地进行 推理(Inference),尤其是在 资源消耗 和 性能 方面的优化。
主要特点:
高效的推理:
vLLM 通过优化模型的推理流程,提升了对大规模语言模型的运行效率。
它特别针对 低延迟推理(low-latency inference)和 高吞吐量推理(high-throughput inference)进行了优化,这使得即便是非常大的语言模型,也能在较少资源的情况下高效运行。
内存优化:
vLLM 通过高效的 内存管理,尽可能减少内存消耗。这对于大规模模型尤其重要,因为这些模型往往需要大量内存来存储参数和中间计算结果。
它利用 混合精度计算 和 模型并行化 来降低内存需求。
分布式支持:
vLLM 具有 分布式推理 功能,允许多个机器或多张 GPU 协同工作,以支持处理超大规模的语言模型。
易于集成:
vLLM 是一个开源框架,旨在与 Hugging Face Transformers 和其他主流框架兼容。这意味着你可以很容易地将其集成到已有的模型中,提升性能。
它支持与 PyTorch 或 TensorFlow 等流行深度学习框架无缝对接。
灵活性:
vLLM 支持各种 大语言模型,包括 GPT、BERT、T5 等主流模型,并能处理不同种类的自然语言处理任务,如文本生成、文本理解、问答等。
使用场景:
大规模模型部署:如果你需要在有限的硬件资源上高效运行大型语言模型,vLLM 能帮助你在 低延迟 和 高吞吐量 下进行推理。
云端部署:对于需要在多个服务器或 GPU 集群上运行大规模模型的场景,vLLM 通过 分布式推理 提供支持。
本地推理优化:如果你在本地机器上运行大模型,vLLM 会通过内存优化和计算效率提升,减少硬件资源的消耗。
典型工作流程:
模型加载:加载预训练的大模型,通常是通过像 Hugging Face 这样的模型库。
优化推理:使用 vLLM 进行模型推理,这时候它会自动进行内存和计算优化。
分布式推理(可选):如果模型过大,可以使用 vLLM 支持的分布式推理方式,跨多个 GPU 或机器进行并行计算。
总结:
vLLM 是一个针对 大规模语言模型 推理的高效框架,通过优化内存管理、支持分布式计算、以及减少计算资源消耗,提供了 高性能和低延迟 的推理能力。它适用于需要处理超大语言模型的任务,并且能够有效地在本地或分布式环境中运行。
好了 这三个 知识点 说完了 ,接下来 再来总结一下
大模型都有哪些文件后缀
介绍几种常见的大模型类型
HDF5 (.h5):
H5 是指 HDF5 (Hierarchical Data Format version 5) 文件格式,通常用于存储神经网络模型。这个格式常见于 Keras 和 TensorFlow 这样的深度学习框架。
Protocol Buffers (.pb):
Protocol Buffers(或protobuf)是Google开发的一种语言无关、平台无关的可扩展机制,用于序列化结构化数据。TensorFlow通常使用这种格式来保存和加载模型。
ONNX (.onnx):
Open Neural Network Exchange(ONNX)是一个开放格式,用于表示深度学习模型。ONNX旨在使模型可以在不同的深度学习框架之间轻松移植。
PyTorch (.pt 或 .pth):
PyTorch框架通常使用其自身的序列化格式来保存模型,文件扩展名可以是.pt或.pth。
Checkpoint Files (.ckpt):
TensorFlow等框架使用checkpoint文件保存模型的权重和参数,以便于训练过程中的恢复和持续训练。
JSON (.json):
JSON是一种轻量级的数据交换格式,一些模型架构可以被导出成JSON格式的文件,尤其是模型的结构,而权重通常会被保存在分开的文件中。
Pickle (.pkl):
Python的pickle模块能够序列化对象,使得Python对象可以被保存到文件中并在需要时恢复。一些Python框架或自定义模型可能会使用此格式。
TorchScript (.ts):
TorchScript是PyTorch的一个方式,可以将PyTorch模型转化为可以跨平台运行的格式。
Zip (.zip):
有时,模型的不同组成部分(如结构、权重、配置文件等)可能会被打包到一个压缩文件中以便传输。
.safetensors 文件:
这是 TensorFlow 2.x 中新增的文件格式,用于保存模型参数和优化器状态。
它采用的是 TensorFlow 的自定义序列化格式,不能直接用于其他框架。
可以使用 TensorFlow 的 tf.train.Checkpoint 类来加载和保存 .safetensors 文件。
GGUF 格式
GUF 是一个相对较新的格式,通常与 GGML (Generative Models Library) 相关,它是一个特定框架或库用于处理和存储大规模生成模型的格式。
在 Hugging Face 这样的社区平台,你可能会看到一些模型支持 .gguf 格式,通常是为了优化性能或是为了兼容某些特定的推理引擎。
这个格式的模型通常能够在更高效的硬件上进行推理,尤其是在像量化、大规模模型推理等场景中,它有其独特的优势。
Weights & Biases (.hdf5, .weights):
特定于某些框架的权重文件,用于保存模型的训练参数,如权重和偏差。
因为大模型 是不同的框架 训练出来的 所以 调用的时候 要找对对应的框架 才可以调用。
不同的框架和平台使用不同的格式来保存和加载模型。.h5 是 TensorFlow/Keras 领域常用的格式,而 .gguf 是新兴的、可能与某些特定框架或推理引擎相关的格式。如果你使用 Hugging Face 这样的开源平台,可以查看模型的文档,通常会有明确说明使用哪种格式以及如何加载和使用它们。
最后再分享一下 python 下的 常用 大模型框架:
-
PyTorch
概述:PyTorch 是一个广泛使用的深度学习框架,支持动态计算图,非常适合进行大规模深度学习模型的训练,尤其是在自然语言处理和计算机视觉领域。 -
TensorFlow
概述:TensorFlow 是 Google 开发的一个深度学习框架,提供了全面的支持,用于训练各种类型的神经网络模型。它特别适用于大规模的分布式训练和生产环境部署。
等等
这也就是 为什么 python 这些年 这么火,因为这门语言 在AI方向 有很大的优势。



















 3315
3315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











