






ps:个人理解,欢迎讨论。
on-policy、off-policy和offline的区别
强化学习中的在线学习是指使用当前策略收集的轨迹进行训练,离策略学习则是将当前策略收集到的轨迹和之前收集的轨迹一起进行训练,而离线学习是使用之前收集的轨迹进行训练。

离线强化学习的问题
分布偏移和分布转移
离线强化学习面对的问题就是由于使用过去的数据集进行训练,导致行为策略和目标策略的分布不同,从而导致Q函数的估计值不准,可能会出现高估的情况。分布外动作是指在训练过程中,模型选择了一些未曾遇到的动作,这些动作的收益值无法准确估计,从而影响了模型的训练和决策。
未曾遇到的动作可能是因为在训练过程中,模型选择了一些未曾遇到的情况,这些情况下的轨迹并不在原始的数据集中,导致模型无法准确地估计收益值。另外,即使是相同的情况,但由于离线学习中使用的数据集有限,可能无法涵盖所有可能的轨迹,从而导致模型无法准确地预测相应的动作。
在线强化学习也可能会遇到分布外的动作,但相比离线学习,由于在线学习的数据集是实时更新的,所以可以更及时地进行策略改进,从而减少分布外动作的出现。此外,在线学习中也可以采用一些探索策略来增加模型对未曾遇到情况的学习能力,从而减少分布外动作的影响。
人话:Q(s’,a’)里的a’的可能不在数据集里 因此对Q(s’,a’)的估计不准进而影响Q函数的估计偏差 所谓的ood action可以理解为目标策略中采样的动作
致命三元组
致命三元组:1.bootstrapping 2.off-policy learning 3.function approximations
bootstrapping:使用下一步的状态动作对来估计当前的Q(s,a)
如果使用函数近似的话,(s,a)可能会和(s’,a’)十分接近从而影响Q(s,a)≈Q(s’,a’)
解决办法:使用蒙特卡洛近似 获得真实值 避免出现两个 Q 值发散的相似状态
离政策学习
通过离策略学习方法,我们使用下一状态的最佳Q值来更新策略。如果我们每次使用此近似值时都访问此状态(策略学习的做法,例如 SARSA),我们将更新此 Q 值以使其收敛到其真实值。离策略的问题是我们可能不会经常更新这个值来防止它发散。
BCQ 2019
background:离策略算法因为没有相关的数据集而不能在离线强化学习上很好的运用,解决离线强化学习在固定数据集上训练不能探索数据的问题。
阅读源码
发现:VAE模型用来学习行为策略,也就是数据集的策略分布。Actor算法选取VAE产生的动作加上扰动之后的动作(即探索),Critic的更新中计算未来Q值时选用从VAE中采样的扰动actions(Q(s’,a’)),Actor更新最大化从VAE中采样的扰动actions的q值(Q(s,a))。
Q:如何解决离线的问题,用相似的动作和学习的分布去近似改进后的策略分布的数据分布,那执行动作的奖励如何得到?
A:依然使用原有数据集,没有更新轨迹,BCQ只是对q值估计的动作进行了限制,将离线中的动作限制在了见过的范围内(扰动actions)避免ood action,减少高估误差,在行为策略上增加一点泛化。原本的actor-critic选取所有动作内的最大值,但BCQ改为只在它选取范围内的动作进行评估更新。

r
+
γ
max
a
i
[
λ
min
j
=
1
,
2
Q
θ
j
′
(
s
′
,
a
i
)
+
(
1
−
λ
)
max
j
=
1
,
2
Q
θ
j
′
(
s
′
,
a
i
)
]
r+\gamma\operatorname*{max}_{a_{i}}\left[\lambda\operatorname*{min}_{j=1,2}Q_{\theta_{j}^{\prime}}(s',a_{i})+(1-\lambda)\operatorname*{max}_{j=1,2}Q_{\theta_{j}^{\prime}}(s',a_{i})\right]
r+γaimax[λj=1,2minQθj′(s′,ai)+(1−λ)j=1,2maxQθj′(s′,ai)]
重参数化技巧
重参数化是分离随机变量的不确定性,使得先前无法求导/梯度传播的中间节点可以求导。例如直接从分布
p
θ
(
z
)
p_\theta(z)
pθ(z)中进行采样,没有梯度信息,重参数化之后能保留梯度信息。重参数详解

连续函数(取高斯分布),离散分布 Gumbel-softmax
eg. z = N ( μ , σ 2 ) z=\mathcal{N}(\mu,\sigma^2) z=N(μ,σ2)从这个分布中采样,重参数化将其变为先从均值为0,标准差为1的高斯分布中采样,再放缩平移得到 z z z.从 ϵ \epsilon ϵ到 z z z只涉及线性操作, ϵ \epsilon ϵ看成一个常数,可导。
z i = μ i + σ i ∗ ϵ , ϵ ∼ N ( 0 , I ) \mathbf{z}_{i}=\mu_{i}+\sigma_{i}*\epsilon,\epsilon\sim\mathcal{N}(0,\mathbf{I}) zi=μi+σi∗ϵ,ϵ∼N(0,I)
SAC 2019
background:探索如何为连续状态和动作空间设计高效且稳定的无模型深度强化学习算法。
critic的目标:获得准确的q值
actor的目标:获得q值最大动作的同时最大化熵。
熵是不确定性的度量,熵越大不确定性越大,
H
(
X
)
=
−
∑
i
=
1
n
p
(
x
i
)
log
p
(
x
i
)
H(X)=-\sum_{i=1}^np\left(x_i\right)\log p\left(x_i\right)
H(X)=−∑i=1np(xi)logp(xi)
SAC算法最大化熵也就是在增加探索。其目标公式为:
J
(
π
)
=
∑
t
=
0
T
E
(
s
t
,
a
t
)
∼
ρ
π
[
r
(
s
t
,
a
t
)
+
α
H
(
π
(
⋅
∣
s
t
)
)
]
J(\pi)=\sum_{t=0}^T\mathbb{E}_{(\mathbf{s}_t,\mathbf{a}_t)\sim\rho_\pi}\left[r(\mathbf{s}_t,\mathbf{a}_t)+\alpha\mathcal{H}(\pi(\cdot|\mathbf{s}_t))\right]
J(π)=∑t=0TE(st,at)∼ρπ[r(st,at)+αH(π(⋅∣st))]
转换一下就等于下面的式子:
T
π
Q
(
s
t
,
a
t
)
≜
r
(
s
t
,
a
t
)
+
γ
E
s
t
+
1
∼
p
[
V
(
s
t
+
1
)
]
,
\mathcal{T}^{\pi}Q(\mathrm{s}_{t},\mathrm{a}_{t})\triangleq r(\mathrm{s}_{t},\mathrm{a}_{t})+\gamma\mathbb{E}_{\mathbf{s}_{t+1}\sim p}\left[V(\mathrm{s}_{t+1})\right],
TπQ(st,at)≜r(st,at)+γEst+1∼p[V(st+1)],
V
(
s
t
)
=
E
a
t
∼
π
[
Q
(
s
t
,
a
t
)
−
log
π
(
a
t
∣
s
t
)
]
V(\mathrm{s}_{t})=\mathbb{E}_{\mathbf{a}_{t}\sim\pi}\left[Q(\mathrm{s}_{t},\mathrm{a}_{t})-\log\pi(\mathrm{a}_{t}|\mathrm{s}_{t})\right]
V(st)=Eat∼π[Q(st,at)−logπ(at∣st)]
将策略更新为Q函数的指数且限制策略更新的范围:
π
n
e
w
=
arg
min
π
′
∈
Π
D
K
L
(
π
′
(
⋅
∣
s
t
)
∥
exp
(
Q
π
o
l
d
(
s
t
,
⋅
)
)
Z
π
o
l
d
(
s
t
)
)
.
\pi_{\mathrm{new}}=\arg\min_{\pi^{\prime}\in\Pi}\mathrm{D}_{\mathrm{KL}}\left(\pi^{\prime}(\cdot|\mathrm{s}_{t})\parallel\frac{\exp\left(Q^{\pi_{\mathrm{old}}}(\mathrm{s}_{t},\cdot)\right)}{Z^{\pi_{\mathrm{old}}}(\mathrm{s}_{t})}\right).
πnew=argminπ′∈ΠDKL(π′(⋅∣st)∥Zπold(st)exp(Qπold(st,⋅))).
用 V ψ ( s t ) V_ψ(s_t) Vψ(st)逼近数据集内状态和目标策略的v值,用 Q θ ( s t , a t ) Q_θ(s_t, a_t) Qθ(st,at)近似数据集内状态动作对的q值,策略更新为目标策略与Q函数的指数KL散度最小的策略。
看的这个代码,下面两个函数写了但代码里也没用上,先放着。
这里就是求输入t的log p(t),p(t)是对数概率密度函数,t指策略。
def create_log_gaussian(mean, log_std, t):
quadratic = -((0.5 * (t - mean) / (log_std.exp())).pow(2))
l = mean.shape
log_z = log_std
z = l[-1] * math.log(2 * math.pi)
log_p = quadratic.sum(dim=-1) - log_z.sum(dim=-1) - 0.5 * z
return log_p
求得指数差的和的对数?这个torch库里有,可以直接用
def logsumexp(inputs, dim=None, keepdim=False):
if dim is None:
inputs = inputs.view(-1)
dim = 0
#没太理解这下面两行
s, _ = torch.max(inputs, dim=dim, keepdim=True)
outputs = s + (inputs - s).exp().sum(dim=dim, keepdim=True).log()
if not keepdim:
outputs = outputs.squeeze(dim)
return outputs
def sample(self, state):
mean, log_std = self.forward(state)
std = log_std.exp()
normal = Normal(mean, std)
x_t = normal.rsample() # for reparameterization trick (mean + std * N(0,1))
y_t = torch.tanh(x_t)
action = y_t * self.action_scale + self.action_bias
log_prob = normal.log_prob(x_t)
# Enforcing Action Bound
#下面这两个行 将对数概率转换为tanh(x_t)
log_prob -= torch.log(self.action_scale * (1 - y_t.pow(2)) + epsilon)
log_prob = log_prob.sum(1, keepdim=True)
mean = torch.tanh(mean) * self.action_scale + self.action_bias
return action, log_prob, mean
代码里还有个好奇的地方是replay buffer采样的时候先采样从动作空间里的随机动作的数据集轨迹条数,然后采样agent根据目标策略选择的动作?
高斯分布
单变量正态分布概率密度函数定义为:
f
(
x
)
=
1
2
π
σ
e
x
p
(
−
(
x
−
μ
)
2
2
σ
2
)
f(x)=\frac1{\sqrt{2\pi}\sigma}exp(-\frac{(x-\mu)^2}{2\sigma^2})
f(x)=2πσ1exp(−2σ2(x−μ)2)
l
o
g
(
f
(
x
)
)
=
−
(
x
−
μ
)
2
2
σ
2
−
l
o
g
(
σ
)
−
l
o
g
(
2
π
)
log(f(x))=-\frac{(x-\mu)^2}{2\sigma^2}-log(\sigma)-log(\sqrt{2\pi})
log(f(x))=−2σ2(x−μ)2−log(σ)−log(2π)
import torch
from torch.distributions import Normal
dist=Normal(mean,std)
dist.sample() #在均值为mean标准差为std的分布上采样
dist.rsample() #先对标准正态分布N(0,1)进行采样 然后输出mean+std*采样值
dist.log_prob(value) #计算value在定义的正态分布中对应的概率的对数
dist.log_prob(result).exp() #还原对应的概率
dist.entropy() #分布的熵
( 详细推导过程)
KL散度 计算N(0,1)和N(mean,std) 公式
CQL 2020
background:解决离线强化学习中由于分布偏移和过度拟合的高估问题,学习价值函数的保守估计。
用来更新q值的损失里计算的未来q值是用目标策略生成的动作,目标策略更新时计算的q值也是当前状态下对目标策略采样的动作的q值。replay_buffer直接从离线数据集获得。
state distribution shift:训练期间不会受到影响,因为状态都在数据集内,但在测试时可能会出现分布外state。
action distribution shift: 训练期间策略评估从学习策略中采样的动作,但Q函数仅对行为策略中采样的数据集中的动作进行训练。
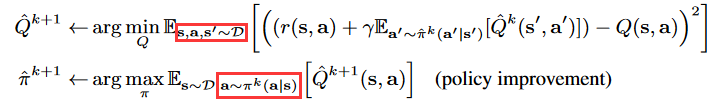
阅读源码,将策略建模为带有参数的高斯分布,并对其进行更新。选择确定的动作可看成action = tanh(mean),否则对分布进行一次采样。
CQL在SAC的基础上对Q函数改进进行了约束,主要是这部分:
random_actions_tensor = torch.FloatTensor(q2_pred.shape[0] * self.num_random, actions.shape[-1]).uniform_(-1, 1) # .cuda()
curr_actions_tensor, curr_log_pis = self._get_policy_actions(obs, num_actions=self.num_random, network=self.policy)
new_curr_actions_tensor, new_log_pis = self._get_policy_actions(next_obs, num_actions=self.num_random, network=self.policy)
q1_rand = self._get_tensor_values(obs, random_actions_tensor, network=self.qf1)
q2_rand = self._get_tensor_values(obs, random_actions_tensor, network=self.qf2)
q1_curr_actions = self._get_tensor_values(obs, curr_actions_tensor, network=self.qf1)
q2_curr_actions = self._get_tensor_values(obs, curr_actions_tensor, network=self.qf2)
q1_next_actions = self._get_tensor_values(obs, new_curr_actions_tensor, network=self.qf1)
q2_next_actions = self._get_tensor_values(obs, new_curr_actions_tensor, network=self.qf2)
cat_q1 = torch.cat(
[q1_rand, q1_pred.unsqueeze(1), q1_next_actions, q1_curr_actions], 1
)
cat_q2 = torch.cat(
[q2_rand, q2_pred.unsqueeze(1), q2_next_actions, q2_curr_actions], 1
)
std_q1 = torch.std(cat_q1, dim=1)
std_q2 = torch.std(cat_q2, dim=1)
if self.min_q_version == 3:
# importance sammpled version
random_density = np.log(0.5 ** curr_actions_tensor.shape[-1])
cat_q1 = torch.cat(
[q1_rand - random_density, q1_next_actions - new_log_pis.detach(), q1_curr_actions - curr_log_pis.detach()], 1
)
cat_q2 = torch.cat(
[q2_rand - random_density, q2_next_actions - new_log_pis.detach(), q2_curr_actions - curr_log_pis.detach()], 1
)
min_qf1_loss = torch.logsumexp(cat_q1 / self.temp, dim=1,).mean() * self.min_q_weight * self.temp
min_qf2_loss = torch.logsumexp(cat_q2 / self.temp, dim=1,).mean() * self.min_q_weight * self.temp
"""Subtract the log likelihood of data"""
min_qf1_loss = min_qf1_loss - q1_pred.mean() * self.min_q_weight
min_qf2_loss = min_qf2_loss - q2_pred.mean() * self.min_q_weight
if self.with_lagrange:
alpha_prime = torch.clamp(self.log_alpha_prime.exp(), min=0.0, max=1000000.0)
min_qf1_loss = alpha_prime * (min_qf1_loss - self.target_action_gap)
min_qf2_loss = alpha_prime * (min_qf2_loss - self.target_action_gap)
self.alpha_prime_optimizer.zero_grad()
alpha_prime_loss = (-min_qf1_loss - min_qf2_loss)*0.5
alpha_prime_loss.backward(retain_graph=True)
self.alpha_prime_optimizer.step()
qf1_loss = qf1_loss + min_qf1_loss
qf2_loss = qf2_loss + min_qf2_loss
min Q α E s ∼ D [ log ∑ a exp ( Q ( s , a ) ) − E a ∼ π ^ β ( a ∣ s ) [ Q ( s , a ) ] ] ( m i n q f 1 l o s s ) + 1 2 E s , a , s ′ ∼ D [ ( Q − B ^ π k Q ^ k ) 2 ] . ( q f 1 l o s s ) \min_{Q}\alpha\mathbb{E}_{s\sim\mathcal{D}}\left[\log\sum_{\mathbf{a}}\exp(Q(\mathbf{s},\mathbf{a}))-\mathbb{E}_{\mathbf{a}\sim\hat{\pi}_{\beta}(\mathbf{a}|\mathbf{s})}\left[Q(\mathbf{s},\mathbf{a})\right]\right](min_qf1_loss)+ \\\frac12\mathbb{E}_{\mathbf{s},\mathbf{a},\mathbf{s}^{\prime}\sim\mathcal{D}}\left[\left(Q-\hat{\mathcal{B}}^{\pi_{k}}\hat{Q}^{k}\right)^{2}\right].(qf1_loss) QminαEs∼D[loga∑exp(Q(s,a))−Ea∼π^β(a∣s)[Q(s,a)]](minqf1loss)+21Es,a,s′∼D[(Q−B^πkQ^k)2].(qf1loss)
Q:不理解这里为什么要对随机动作采样,计算当前状态下的所有动作a的Q(s,a)求和包括a来自动作空间的随机动作、行为策略的动作、目标策略的动作和下一个时刻的动作?
MCQ 2022
MCQ在CQL的基础上引入了CVAE近似行为策略。
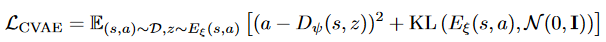
用VAE生成的动作视为pesudo action,直接从目标策略里采样的视为OOD action,将这两者的动作q值的差值作为ood loss,只计算ood 高估的那部分,q值比pesudo的小的忽略掉。
更新Q网络的时候对ood action增加了一个约束:
L
c
r
i
t
i
c
=
λ
E
(
s
,
a
,
r
,
s
′
)
∼
D
[
(
Q
θ
i
(
s
,
a
)
−
y
)
2
]
+
(
1
−
λ
)
E
s
i
n
∼
D
,
a
o
o
d
∼
π
[
(
Q
θ
i
(
s
i
n
,
a
o
o
d
)
−
y
′
)
2
]
(
o
o
d
l
o
s
s
)
\mathcal{L}_{\mathrm{critic}}=\lambda\mathbb{E}_{(s,a,r,s^{\prime})\sim\mathcal{D}}\left[(Q_{\theta_i}(s,a)-y)^2\right]+\\(1-\lambda)\mathbb{E}_{s^{\mathrm{in}}\sim\mathcal{D},a^{\mathrm{ood}}\sim\pi}\left[(Q_{\theta_i}(s^{\mathrm{in}},a^{\mathrm{ood}})-y^{\prime})^2\right] (oodloss)
Lcritic=λE(s,a,r,s′)∼D[(Qθi(s,a)−y)2]+(1−λ)Esin∼D,aood∼π[(Qθi(sin,aood)−y′)2](oodloss)
RWR
优化策略搜索,引入了相对熵,输入是特征,用了拉格朗日乘子法,其他的看不懂TT
AWR
基于RWR提出期望最大框架解决策略迭代:
π
k
+
1
=
arg
max
π
E
s
∼
d
π
k
(
s
)
E
a
∼
π
k
(
a
∣
s
)
[
log
π
(
a
∣
s
)
exp
(
1
β
R
s
,
a
)
]
,
R
s
,
a
=
∑
t
=
0
∞
γ
t
r
t
\pi_{k+1}=\arg\max_{\pi}\quad\mathbb{E}_{\mathbf{s}\sim d_{\pi_{k}}(\mathbf{s})}\mathbb{E}_{\mathbf{a}\sim\pi_{k}(\mathbf{a}|\mathbf{s})}\left[\log\pi(\mathbf{a}|\mathbf{s})\exp\left(\frac{1}{\beta}\mathcal{R}_{\mathbf{s},\mathbf{a}}\right)\right],\mathcal{R}_{\mathbf{s},\mathbf{a}}=\sum_{t=0}^\infty\gamma^tr_t
πk+1=argπmaxEs∼dπk(s)Ea∼πk(a∣s)[logπ(a∣s)exp(β1Rs,a)],Rs,a=t=0∑∞γtrt
本来用策略梯度应该是Q函数的,这里跟RWR一样用指数代替Q函数,拉格朗日乘子法得出的结果。

阅读源码
IQL 2021
标准离线强化学习中
a
′
a'
a′可能是分布外动作导致
Q
θ
^
(
s
′
,
a
′
)
Q_{\hat{\theta}}(s^{\prime},a^{\prime})
Qθ^(s′,a′)高估从而影响
Q
θ
(
s
,
a
)
Q_\theta(s,a)
Qθ(s,a),造成累积误差:
L
T
D
(
θ
)
=
E
(
s
,
a
,
s
′
)
∼
D
[
(
r
(
s
,
a
)
+
γ
max
a
′
Q
θ
^
(
s
′
,
a
′
)
−
Q
θ
(
s
,
a
)
)
2
]
,
L_{TD}(\theta)=\mathbb{E}_{(s,a,s^{\prime})\sim\mathcal{D}}[(r(s,a)+\gamma\max_{a^{\prime}}Q_{\hat{\theta}}(s^{\prime},a^{\prime})-Q_{\theta}(s,a))^{2}],
LTD(θ)=E(s,a,s′)∼D[(r(s,a)+γa′maxQθ^(s′,a′)−Qθ(s,a))2],IQL避免对分布外动作的q值评估,确保
a
′
a'
a′在数据集内,
Q
θ
^
(
s
′
,
a
′
)
Q_{\hat{\theta}}(s^{\prime},a^{\prime})
Qθ^(s′,a′)的值是相对准确的,在固定数据集上学习准确的Q值和V值,使用分布数回归:
L
V
(
ψ
)
=
E
(
s
,
a
)
∼
D
[
L
2
τ
(
Q
θ
^
(
s
,
a
)
−
V
ψ
(
s
)
)
]
.
L_{V}(\psi)=\mathbb{E}_{(s,a)\sim\mathcal{D}}[L_{2}^{\tau}(Q_{\hat{\theta}}(s,a)-V_{\psi}(s))].
LV(ψ)=E(s,a)∼D[L2τ(Qθ^(s,a)−Vψ(s))].
L
Q
(
θ
)
=
E
(
s
,
a
,
s
′
)
∼
D
[
(
r
(
s
,
a
)
+
γ
V
ψ
(
s
′
)
−
Q
θ
(
s
,
a
)
)
2
]
.
L_Q(\theta)=\mathbb{E}_{(s,a,s')\sim\mathcal{D}}[(r(s,a)+\gamma V_\psi(s')-Q_\theta(s,a))^2].
LQ(θ)=E(s,a,s′)∼D[(r(s,a)+γVψ(s′)−Qθ(s,a))2].使用AWR来进行策略提取:
L
π
(
ϕ
)
=
E
(
s
,
a
)
∼
D
[
exp
(
β
(
Q
θ
^
(
s
,
a
)
−
V
ψ
(
s
)
)
)
log
π
ϕ
(
a
∣
s
)
]
,
L_{\pi}(\phi)=\mathbb{E}_{(s,a)\sim\mathcal{D}}[\exp(\beta(Q_{\hat{\theta}}(s,a)-V_{\psi}(s)))\log\pi_{\phi}(a|s)],
Lπ(ϕ)=E(s,a)∼D[exp(β(Qθ^(s,a)−Vψ(s)))logπϕ(a∣s)],
阅读源码

TD3
使用确定性策略梯度更新:
π
=
a
r
g
m
a
x
π
E
(
s
,
a
)
∼
D
[
Q
(
s
,
π
(
s
)
)
]
.
\pi=\mathop{\mathrm{argmax}}_{\pi}\mathbb{E}_{(s,a)\sim\mathcal{D}}[Q(s,\pi(s))].
π=argmaxπE(s,a)∼D[Q(s,π(s))].

代码里这块是直接最大化q值,但是算法流程里写的是求导,和之前比对一下,印象里应该没区别。所以TD3的创新是什么TT
# Compute actor losse
actor_loss = -self.critic.Q1(state, self.actor(state)).mean()
TD3+BC
添加一个行为克隆项的约束:
π
=
argmax
π
E
(
s
,
a
)
∼
D
[
λ
Q
(
s
,
π
(
s
)
)
−
(
π
(
s
)
−
a
)
2
]
\pi=\operatorname*{argmax}_\pi\mathbb{E}_{(s,a)\sim\mathcal{D}}\left[\lambda Q(s,\pi(s))-\left(\pi(s)-a\right)^2\right]
π=πargmaxE(s,a)∼D[λQ(s,π(s))−(π(s)−a)2]
BEAR
引入支撑集和MMD距离,限制目标策略在支持集的范围内,
π
ϕ
(
s
)
:
=
max
π
∈
Π
ϵ
E
a
∼
π
(
∣
s
)
[
min
j
=
1
,
.
.
,
K
Q
^
j
(
s
,
a
)
]
\pi_\phi(s):=\max_{\pi\in\Pi_\epsilon}\mathbb{E}_{a\sim\pi(}|s)\left[\min_{j=1,..,K}\hat{Q}_j(s,a)\right]
πϕ(s):=π∈ΠϵmaxEa∼π(∣s)[j=1,..,KminQ^j(s,a)]
策略评估:
π
ϕ
:
=
max
π
∈
Δ
∣
S
∣
E
s
∼
D
E
a
∼
π
(
⋅
∣
s
)
[
min
j
=
1
,
…
,
K
Q
^
j
(
s
,
a
)
]
s
.
t
.
E
s
∼
D
[
M
M
D
(
D
(
s
)
,
π
(
⋅
∣
s
)
)
]
≤
ε
\begin{aligned}\pi_{\phi}:=\max_{\pi\in\Delta_{|S|}}\mathbb{E}_{s\sim\mathcal{D}}\mathbb{E}_{a\sim\pi(\cdot|s)}\left[\min_{j=1,\ldots,K}\hat{Q}_{j}(s,a)\right]\quad\mathrm{s.t.~}\mathbb{E}_{s\sim\mathcal{D}}[\mathrm{MMD}(\mathcal{D}(s),\pi(\cdot|s))]\leq\varepsilon\end{aligned}
πϕ:=π∈Δ∣S∣maxEs∼DEa∼π(⋅∣s)[j=1,…,KminQ^j(s,a)]s.t. Es∼D[MMD(D(s),π(⋅∣s))]≤ε
M
M
D
2
(
{
x
1
,
⋯
,
x
n
}
,
{
y
1
,
⋯
,
y
m
}
)
=
1
n
2
∑
i
,
i
′
k
(
x
i
,
x
i
′
)
−
2
n
m
∑
i
,
j
k
(
x
i
,
y
j
)
+
1
m
2
∑
j
,
j
′
k
(
y
j
,
y
j
′
)
.
\mathrm{MMD}^2(\{x_1,\cdots,x_n\},\{y_1,\cdots,y_m\})=\frac{1}{n^2}\sum_{i,i^{\prime}}k(x_i,x_{i^{\prime}})-\frac{2}{nm}\sum_{i,j}k(x_i,y_j)+\frac{1}{m^2}\sum_{j,j^{\prime}}k(y_j,y_{j^{\prime}}).
MMD2({x1,⋯,xn},{y1,⋯,ym})=n21i,i′∑k(xi,xi′)−nm2i,j∑k(xi,yj)+m21j,j′∑k(yj,yj′).

MORel
在离线数据集上学习环境模型
M
\mathcal{M}
M,建模为高斯分布,构建一个未知动作检测器,构建一个悲观的MDP环境,使用行为克隆策略学习行为策略,输出在悲观MDP环境下从行为策略开始优化的策略。
USAD使用不确定性估计,将保证模型准确的状态操作标记为“已知”,而将无法确定这种保证的状态操作标记为“未知”,
D
T
V
D_{TV}
DTV为总方差距离。
U
α
(
s
,
a
)
=
{
F
ALSE
(
i
.
e
.
K
n
o
w
n
)
i
f
D
T
V
(
P
^
(
⋅
∣
s
,
a
)
,
P
(
⋅
∣
s
,
a
)
)
≤
α
c
a
n
b
e
g
u
a
r
a
n
t
e
e
d
T
RUE
(
i
.
e
.
U
n
k
n
o
w
n
)
o
t
h
e
r
w
i
s
e
U^{\alpha}(s,a)=\begin{cases}F\text{ALSE}(i.e.Known)&\mathrm{if}D_{TV}\left(\hat{P}(\cdot|s,a),P(\cdot|s,a)\right)\leq\alpha \, can\, be\, guaranteed\\T\text{RUE}(i.e.Unknown)&otherwise\end{cases}
Uα(s,a)={FALSE(i.e.Known)TRUE(i.e.Unknown)ifDTV(P^(⋅∣s,a),P(⋅∣s,a))≤αcanbeguaranteedotherwise
悲观MDP,对环境模型估计不准确的概率和HALT的状态进行惩罚,将其状态转移概率设为迪利克雷函数,奖励设置为-k:
P
^
p
(
s
′
∣
s
,
a
)
=
{
δ
(
s
′
=
HALT
)
if
U
α
(
s
,
a
)
=
TRUE
or
s
=
HALT
P
^
(
s
′
∣
s
,
a
)
otherwise
r
p
(
s
,
a
)
=
{
−
κ
if
s
=
HALT
r
(
s
,
a
)
otherwise
\hat P_p(s'|s,a)=\begin{cases}\delta(s'=\text{HALT})&\text{if}U^\alpha(s,a)=\text{TRUE}\\&\text{or}s=\text{HALT}\\\hat P(s'|s,a)&\textit{otherwise}\end{cases}\quad r_p(s,a)=\begin{cases}-\kappa&\text{if}s=\text{HALT}\\r(s,a)&\textit{otherwise}\end{cases}
P^p(s′∣s,a)=⎩
⎨
⎧δ(s′=HALT)P^(s′∣s,a)ifUα(s,a)=TRUEors=HALTotherwiserp(s,a)={−κr(s,a)ifs=HALTotherwise
实践代码中将模型的不确定性定义为不同模型的差值,具体USAD为:
U
practical
(
s
,
a
)
=
{
FALSE(i.e. Known)
if disc
(
s
,
a
)
≤
threshold
TRUE(i.e. Unknown)
if disc
(
s
,
a
)
>
threshold
U_\text{practical}(s,a)=\begin{cases}\text{FALSE(i.e. Known)}&\text{if disc}(s,a)\leq\text{threshold}\\\text{TRUE(i.e. Unknown)}&\text{if disc}(s,a)>\text{threshold}\end{cases}
Upractical(s,a)={FALSE(i.e. Known)TRUE(i.e. Unknown)if disc(s,a)≤thresholdif disc(s,a)>threshold
COMBO
background:由于分布偏移的存在,对环境进行建模也可能不准确,MOPO和MORel使用不确定性估计,但并不准确,COMBO能够优化策略性能的下限,但不需要不确定性量化。
使用离线数据集学习环境,将环境建模为高斯分布,使用离线数据集以及模型综合生成的数据来学习价值函数,通过惩罚不支持离线数据集的状态-动作元组中的价值函数来学习保守的批评函数。
状态转移概率建模为,不太理解为啥是这个损失函数:
min
T
^
E
(
s
,
a
,
s
′
)
∼
D
[
log
T
^
(
s
′
∣
s
,
a
)
]
\min_{\widehat{T}}\mathbb{E}_{(\mathbf{s},\mathbf{a},\mathbf{s}^{\prime})\sim\mathcal{D}}\left[\log\widehat{T}(\mathbf{s}^{\prime}|\mathbf{s},\mathbf{a})\right]
T
minE(s,a,s′)∼D[logT
(s′∣s,a)]
策略提升选取q值最大的策略,q值更新: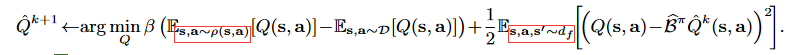
这里的
ρ
(
s
,
a
)
\rho(s,a)
ρ(s,a)是在学习的环境中执行行为策略的结果,
d
f
d_f
df是真实环境和学习的模拟环境的混合分布。降低(或保守估计)来自模型推出的状态-动作元组的 Q 值(from
ρ
(
s
,
a
)
\rho(s,a)
ρ(s,a)),并提高来自离线数据集的真实状态-动作对的 Q 值(from
d
f
d_f
df)。
d
f
μ
(
s
,
a
)
:
=
f
d
(
s
,
a
)
+
(
1
−
f
)
d
M
^
μ
(
s
,
a
)
,
d_f^\mu(\mathrm{s},\mathrm{a}):=\textit{ f }d(\mathrm{s},\mathrm{a})+(1-f)\mathrm{~}d_{\widehat{\mathcal{M}}}^\mu(\mathrm{s},\mathrm{a}),
dfμ(s,a):= f d(s,a)+(1−f) dM
μ(s,a),
Diffusion-QL
我们学习动作价值函数,并将最大化动作价值的项添加到条件扩散模型的训练损失中,这会导致寻求接近行为策略的最佳行动的损失。
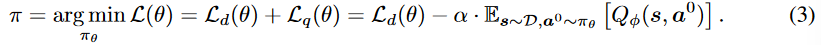
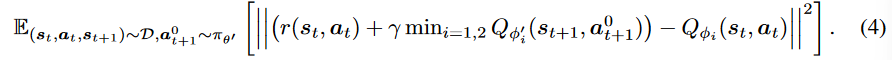

Combined Constraint on Behavior Cloning and Discriminator in Offline Reinforcement Learning IEEE ACCESS(随便看看)
TD3+BC强烈依赖于数据集D的性能,因为抑制分布偏移约束的方法是行为克隆。文章提出行为克隆和判别器混合正则化(BDB),在GAN中使用判别器D允许执行不包含在数据集D中的动作。
BDB是数据集正则化,在TD3+BC的基础上增加了判别器约束,简单点说就是选择数据集之外的动作时TD3+BC的损失会变大,
1
−
β
1-\beta
1−β惩罚数据集之外的操作,但是加上判别器约束(判断该分布外动作是否在数据集内或者目标策略分布内)能抵消部分使其选择分布外动作,与数据集中的动作接近的动作会被积极评估,放宽限制:
π
=
a
r
g
m
a
x
π
E
(
s
,
a
)
∼
D
[
λ
Q
(
s
,
π
(
s
)
)
−
(
1
−
β
)
(
π
(
s
)
−
a
)
2
+
β
l
o
g
(
D
(
s
,
π
(
s
)
)
)
]
\begin{aligned}\pi&=\underset{\pi}{\mathrm{argmax}}\mathbb{E}_{(s,a)\sim\mathcal{D}}[\lambda Q(s,\pi(s))\\&-(1-\beta)(\pi(s)-a)^2+\beta log(D(s,\pi(s)))]\end{aligned}
π=πargmaxE(s,a)∼D[λQ(s,π(s))−(1−β)(π(s)−a)2+βlog(D(s,π(s)))]
可调整参数,通过从 Q(s, a) 的方差中采样 Q 值来估计不确定性,当发生分布偏移时,Q(s, a) 的不确定性增加导致 β 值减小,从而收紧 BC 约束。相反,当Q函数准确估计Q(s,a)时,对判别器的约束比例增加,有利于数据集外行为的学习。
波束搜索
全局搜索和贪婪搜索的折中,每次选取概率最大的k个进行比较。
预测的时候,假设词表大小为3,内容为a,b,c。beam size是2,decoder解码的时候:
1: 生成第1个词的时候,从词表中选择概率分最大的2个词。这里假设a和c的分最高,那么当前的2个序列就是a和c。
2:生成第2个词的时候,我们将当前序列a和c,分别与词表中的所有词进行组合,得到新的6个序列aa ab ac ca cb cc,计算每个序列的得分并选择得分最高2个序列,作为新的当前序列,假如为cb cc。
3:后面会不断重复这个过程,直到遇到结束符或者达到最大长度为止。最终输出得分最高的2个序列。
建模为序列预测问题使用Transformer
将其转化为在初始状态下给定奖励生成轨迹的问题,不存在策略评估从而避免OOD action带来的误差。但是初始最高的奖励怎么选取?
Transformer的缺点
Transformer 目前的训练速度较慢,资源消耗较大。当时序上下文窗口过大时,需要相对较长的时间去计算动作,实时控制场景中很难部署应用。当需要处理纯粹的反应型环境,且数据维度较低时,使用 Transformer 架构的优势并不明显,因为它在性能和效率方面都不会带来任何好处。
数据覆盖范围有限,不能覆盖整个状态和动作空间;训练数据量太少。
改进方法:数据增强,训练额外的模型学习环境动态。
DT
TT
没搞懂TT里为什么要离散化,连续状态和动作转化为离散的?
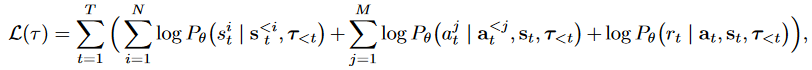
Bootstrapped Transformer
background:使用学习模型本身来生成数据并弥补训练数据集的局限性。
BooT 使用 Transformer 生成数据,然后使用生成的高置信度序列数据进一步训练模型进行 bootstrapping。一种使用自回归生成,另一种使用教师强制策略。
DT和TT都是直接使用transformer生成轨迹近似最优策略,BooT在其基础上用策略生成的模型来进一步训练得到最优策略。
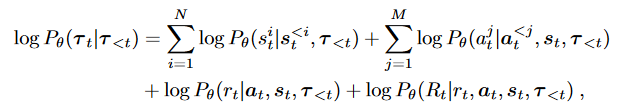
L
(
τ
)
=
∑
t
=
1
T
log
P
θ
(
τ
ι
∣
τ
<
t
)
,
\mathcal{L}(\tau)=\sum_{t=1}^{T}\log P_{\theta}(\tau_{\iota}|\tau_{<t}),
L(τ)=t=1∑TlogPθ(τι∣τ<t),

代码
Q:为什么要对actor里分布中采样的值进行tanh操作?
A:将其转化到[-1,1]区间
t
a
n
h
(
x
)
=
s
i
n
h
(
x
)
c
o
s
h
(
x
)
=
e
x
−
e
−
x
e
x
+
e
−
x
tanh(x)=\frac{sinh(x)}{cosh(x)}=\frac{e^x-e^{-x}}{e^x+e^{-x}}
tanh(x)=cosh(x)sinh(x)=ex+e−xex−e−x



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









