







由于项目的需要,一周前开始了DSP编程之旅。由于想对DSP有一个全面的掌握,所以进度很慢。到现在也没编一句代码。由于以前学习过51及STM32,所以学起来不是特别吃力。现在在此处做一个对28335的总结,在以后的学习过程中会不断的加入新的内容。另一方面是关于这方面的资料很零碎,也方便自己的实时查阅。
DSP芯片是一种具有特殊结构的微处理器。该芯片的内部采用程序和数据分开的哈佛结构,具有专门的硬件乘法器,广泛采用流水线操作,提供特殊的指令,可以用来快速地实现各种数字信号处理算法。
一、定点与浮点概念说明
一般来说,定点dsp处理器具有速度快,功耗低,价格便宜的特点;而浮点dsp处理器则计算精确,动态范围大,速度快,易于编程,功耗大,价格高。
定点数:通俗的说,小数点固定的数。以人民币为例,我们日常经常说到的如123.45¥,789.34¥等等,默认的情况下,小数点后面有两位小数,即角,分。如果小数点在最高有效位的前面,则这样的数称为纯小数的定点数,如
0.12345,0.78934等。如果小数点在最低有效位的后面,则这样的数称为纯整数的定点数,如12345,78934等。
浮点数:一般说来,小数点不固定的数。比较容易的理解方式是,考虑以下我们日常见到的科学记数法,拿我们上面的数字举例,如123.45,可以写成以下几种形式:
12.345x101
1.2345 x102
0.12345 x103
……
为了表示一个数,小数点的位置可以变化,即小数点不固定。
二、定点数与浮点数的对比
(1)表示的精度与范围不同
例如,我们用4个十进制数来表达一个数字。对于定点数(这里以定点整数为例),我们表示区间[0000,9999]中的任何一个数字,但是如果我们要想表示类似1234.3的数值就无能为力了,因为此时的表示精度为1/100=1;如果采用浮点数来表示(以归整的科学记数法,即小数点前有一位有效位,为例),则可以表示[0.000,9.999]之间的任何一个数字,表示的精度为1/103=0.001,精度比上一种方式提高了很多,但是表示的范围却小了很多。也就是说,一般的,定点数表示的精度较低,但表示的数值范围较大;而浮点数恰恰相反。
(2)计算机中运算的效率不同
一般说来,定点数的运算在计算机中实现起来比较简单,效率较高;而浮点数的运算在计算机中实现起来比较复杂,效率相对较低。
(3)硬件依赖性
一般说来,只要有硬件提供运算部件,就会提供定点数运算的支持(不知道说的确切否,没有听说过不支持定点数运算的硬件),但不一定支持浮点数运算,如有的很多嵌入式开发板就不提供浮点运算的支持。
三、如何选择DSP
选择DSP可以根据以下几方面决定:
1)速度:DSP速度一般用MIPS或FLOPS表示,即百万次/秒钟。根据您对处理速度的要求选择适合的器件。一般选择处理速度不要过高,速度高的DSP,系统实现也较困难。
2)精度:DSP芯片分为定点、浮点处理器,对于运算精度要求很高的处理,可选择浮点处理器。定点处理器也可完成浮点运算,但精度和速度会有影响。
3)寻址空间:不同系列DSP程序、数据、I/O空间大小不一,与普通MCU不同,DSP在一个指令周期内能完成多个操作,所以DSP的指令效率很高,程序空间一般不会有问题,关键是数据空间是否满足。数据空间的大小可以通过DMA的帮助,借助程序空间扩大。
4)成本:一般定点DSP的成本会比浮点DSP的要低,速度也较快。要获得低成本的DSP系统,尽量用定点算法,用定点DSP。
5)实现方便:浮点DSP的结构实现DSP系统较容易,不用考虑寻址空间的问题,指令对C语言支持的效率也较高。
6)内部部件:根据应用要求,选择具有特殊部件的DSP。如:C2000适合于电机控制;OMAP适合于多媒体等。
四、DSP同MCU相比的特点
1)DSP的速度比MCU快,主频较高。
2)DSP适合于数据处理,数据处理的指令效率较高。
3)DSP均为16位以上的处理器,不适合于低档的场合。
4)DSP可以同时处理的事件较多,系统级成本有可能较低。
5)DSP的灵活性较好,大多数算法都可以软件实现。
6)DSP的集成度较高,可靠性较好。五、DSP同嵌入CPU相比的特点
1)DSP是单片机,构成系统简单。 2)DSP的速度快。 3)DSP的成本较低。 4)DSP的性能高,可以处理较多的任务。
下面这句是在书上摘抄的,感觉不错。


五、名词解释
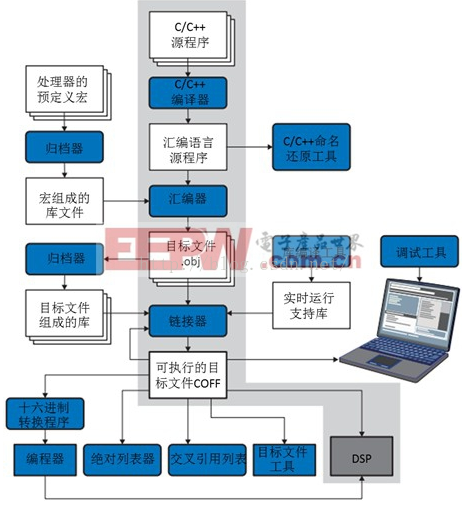
1.在这个流程中,与我们编程效率直接相关的就是C/C++编译器了(如果没有使用汇编直接编写的话),它的直接用途是将C/C++代码编译为针对DSP汇编指令集的汇编代码。
2. 汇编器的作用是将汇编语言代码转换为机器语言(目标文件),这里的汇编代码包括前面由C/C++生成的汇编代码和我们直接编写的汇编代码。
3. 链接器是作用是把所有的库文件、目标文件等链接成为一个可执行的目标文件,其中包含程序的机器代码和数据,以及其他用来链接和加载该程序所需的信息(在TI DSP上是COFF格式,通俗地讲就是.out二进制文件),同时根据内存地址的分配对各目标文件进行重定位,并解析外部参考,例如在一个源程序里引用另一个源程序中定义的变量就可以理解为外部参考,假如一个目标文件引用了一个未定义的符号symbol,则链接器搜索其他目标文件中定义的全局符号,找到匹配的符号修补指令,否则报告一个错误。所以有时候编译所有程序完成在链接的时候会提示xxx symbol为未定义,说明对应的文件没有加到工程里面。
4. 归档器archiver:也可以叫压缩器,看一下我们常用的压缩软件winrar的全称winrar archiver就不难理解了。
5. 实时支持库:包括标准C和C++的运行支持函数、编译器公用程序函数、浮点运算函数和C编译器支持的I/O函数。
6. 十六进制转换程序:把编译、链接等步骤生成的可执行文件,转换为十六进制文件,例如.HEX格式,然后可以烧写到EEPROM、FLASH等外部存储器之中。
7. 绝对列表器:读取目标文件并输出.abs文件,通过汇编.abs文件可产生含有绝对地址的列表文件,从而使得我们不用手工费时费力地去创建列表文件。
8. 交叉引用列表:与3中外部参考解析相关的,它用目标文件产生参照列表文件,可显示符号及其定义,以及符号所在的源文件。
9. C/C++命名还原工具:C/C++编译器会将程序中的变量名、函数名转换成内部名称,这个过程被称作Name Mangling,反过程被称作Name Demangling,即命名还原工具。内部名称包含了变量或函数的更多信息,例如编译 器看到g_var@@3HA,就知道这是:int g_var。具体的还原规则一般是不开放给我们用户的,只要编译器知道就行 了。六、存储器编址方式
存储器统一编址,即从存储空间中划出一部分地址给I/O端口。CPU访问端口和访问存储器的指令在形式上完全相同,只能从地址范围来区分两种操作。
优点是对端口操作的指令类型多,功能全,不仅能对端口进行数据传送,还可以对端口内容进行算术逻辑运算和移位运算;其次是有较大的编址空间;
缺点是端口占用存储器的地址空间,使存储器的可用地址空间变小;端口指令的长度增加,执行时间变长;由于访问I/O与访问内存的指令一样,在程序中不易分清楚是访问I/O端口还是访问内存,使得阅读困难;端口地址译码器较复杂。
I/O 接口独立编址:
这种编址方式是将存储器地址空间和I/O 接口地址空间分开设置,互不影响。设有专门的输入指令(IN)和输出指令(OUT)来完成I/O 操作。
优点是内存地址空间与I/O 接口地址空间分开,互不影响,译码电路较简单,并设有专门的I/O 指令,所以编程序易于区分,且执行时间短,快速性好。
其缺点是只用I/O 指令访问I/O 端口,功能有限且要采用专用I/O周期和专用I/O 控制线,使微处理器复杂化
七、总线
如能对硬件基础有些了解的话,可以帮助写出更好的程序,而且还可以帮助加深对系统的整体理解。首先需要明确什么是总线,其用途是什么?根据wiki的解释,总线是用于连接计算机各部件的子系统,用于各部件间的数据传输。为什么叫做bus呢?大家可以想英文中bus的意思是公共汽车。在这里也有近似的意思,是一个公共传输线路,大家的信号都可以在上面传输。
八、冯诺依曼及哈佛结构


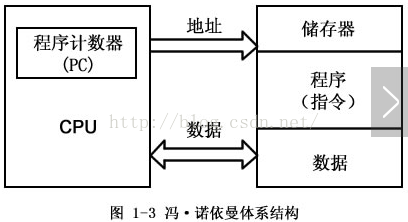
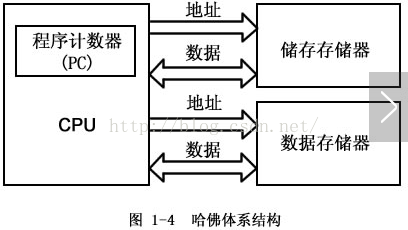
在典型情况下,完成一条指令需要3个步骤,即:取指令、指令译码和执行指令。从指令流的定时关系也可看出冯·诺依曼结构与哈佛结构处理方式的差别。举一个最简单的对存储器进行读写操作的指令,指令1至指令3均为存、取数指令,对冯·诺依曼结构处理器,由于取指令和存取数据要从同一个存储空间存取,经由同一总线传输,因而它们无法重叠执行,只有一个完成后再进行下一个。
如果采用哈佛结构处理以上同样的3条存取数指令,系统中具有程序的数据总线与地址总线及数据的数据总线与地址总线。由于取指令和存取数据分别经由不同的存储空间和不同的总线,使得各条指令可以重叠执行,这样,也就克服了数据流传输的瓶颈,提高了运算速度。


九、28335的结构
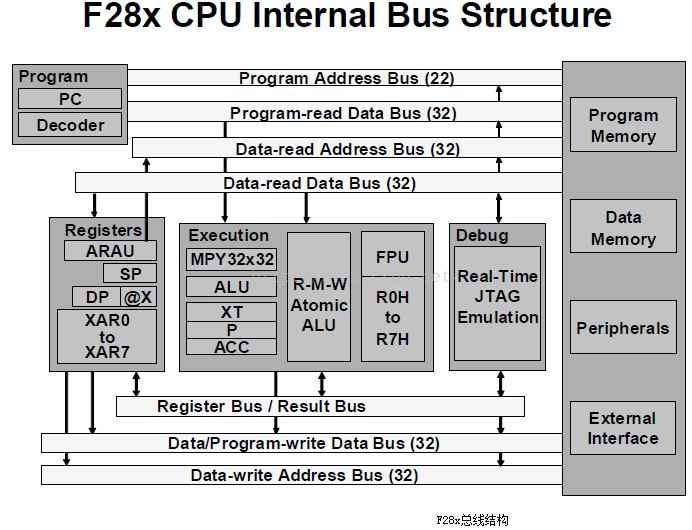


F28335 DSP就是采用多级流水线的增强的哈佛总线结构,能够并行访问程序和数据存储空间。在F28335芯片内部集成了大量的不同的存储介质,F28335片上有256K×16位的FLASH,34K×16位的SARAM,8K×16位的BOOT ROM,2K×16位的OPT ROM,采用统一寻址方式(程序、数据和I/O统一寻址),从而提高了存储空间的利用率,方便程序的开发。除此之外,F28335 DSP还提供了外部并行扩展接口XINTF,可进一步外扩存储空间。F28335的CPU内核本身并不包含任何存储器,通过总线访问芯片内部集成的或者外部扩展的存储器。其总线按照改进哈佛结构,分成了32位的数据读、数据写数据总线,地址读、地址写总线,公用数据总线即程序总线,包括22位的程序地址总线,用于传送程序空间的读/写地址,32位读数据程序总线,用于读取程序空间的指令或者数据。改进的哈佛结构其实是综合了冯.诺依曼结构的简洁,哈佛结构的高效。F28335应用32位数据地址和22位程序地址控制整个存储器以及外设,最大可寻址4M字的数据空间和4M字程序空间。可能会产生这样的疑问,32位的数据地址可寻址空间是4M啊,这个解释在一本书上看到了,不过是2812的,可参考下。

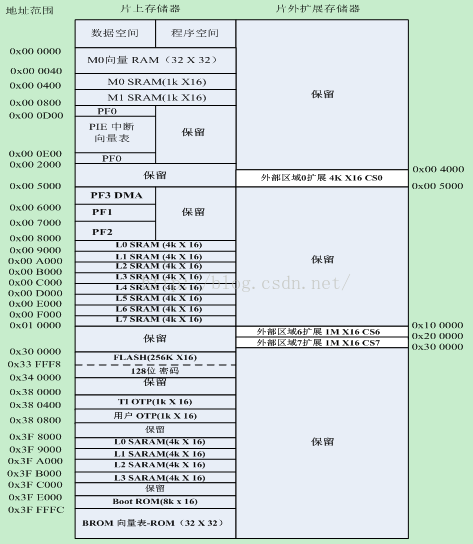

从上面似乎可以看到一个地址对应16位。而且寄存器是16位的。















 476
476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









