







1、weights、bias 参数学习
我们希望有一种学习算法,它能够自动地调整网络中的权重因子和偏置。 但是,我们怎样才能设计出这样的算法神经网络?可以通过学习来解决一些问题。假如,网络的输入是从扫描的原始像素数据,亦或是手写数字的图像。我们希望通过网络可以自动地学习权重和偏差,使输出从网络正确分类的数字。假设我们对网络上的一些权重(或偏置)做一些小的调整,并且希望网络上权重因子和偏差也仅有较小的变化,同样的在输出网络中也只产生一个小的改变。我们想象一下这样的参数学习能否为自适应的形式?如下图所示:
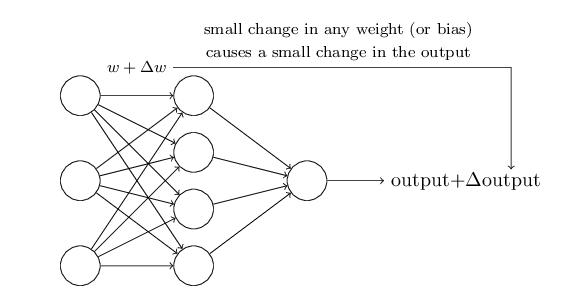
假设一个小的权重变化(或偏置)对输出也产生较小的影响,那么我们通过这一策略来修改的权重(weight)和偏置(bias),让网络学习到更多想要的规则。例如,假设在网络中图像“9”被误分为“8”时。可以通过校正权重和偏(每次做细小的改变),使网络变得更接近分类的图像为“9”。 最终网络将循环校正,不断调整权重(weight)和偏置(bias),使网络得到更好的输出结果。
问题并不是想象的这么简单,在一个网络的众多神经元当中,一个参数的细小改变,也许会发生天翻地覆的变化。实际上,在网络中的任何一个单一的感知器(神经元)的权重或偏差发生变化,即使是细微的变化,有时会导致输出完全相反,就像从 0 到 1 的变化。因此,虽然你的“9”可能被正确分类,但是网络中的感知器就很可能无法学习到为其它数字分类的‘规则’,这也就使得网络中参数学习变得极其困难。也许有一些聪明的方法来解决这个问题,显而易见这不是我们想要的结果。
2、sigmoid 神经元的引入
我们可以通过引入一种人工神经元(即
sigmoid
neurons
)来克服这个问题。
Sigmoid
神经元类似感知器,它使权重和偏置的微小变化对输出也产生较小的变化,因而可以达到微调网络的目的。接下来描述下
sigmoid
神经元:
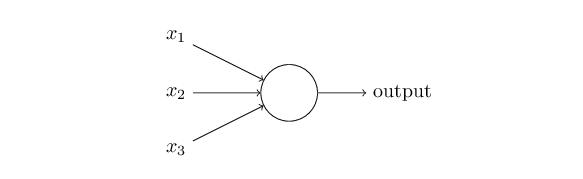
和感知器一样,这里
sigmoid
神经元有输入:
x1,x2,x3,....
,
sigmoid
神经元对于每一个输入都有
weights:w1,w2,w3,....
和一个共有的偏置
b
。不同的是,
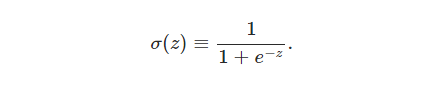
上式中,将输入、即参数带入,形式上可以写为:
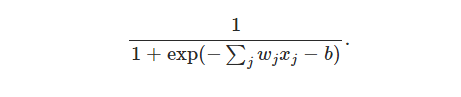
2.1、sigmoid 原理
仅从数学公式上看, sigmoid 神经元和感知器很不同。事实上,感知器和 Sigmoid 神经元之间有许多相似之处。
为了更详细地了解感知器模型,假设
z≡w⋅x+b
为一个极大的正数。 那么
e−z≈0
,则
σ(z)≈1
。换句话说,也就是当
z≡w⋅x+b
为一个很大的正数,sigmoid 神经元的输出近似的为
1
; 如果
sigmoid function:
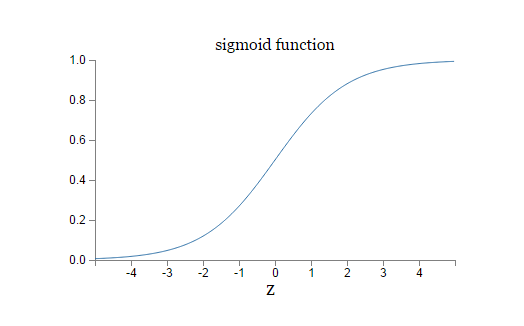
smoothed
step
function:
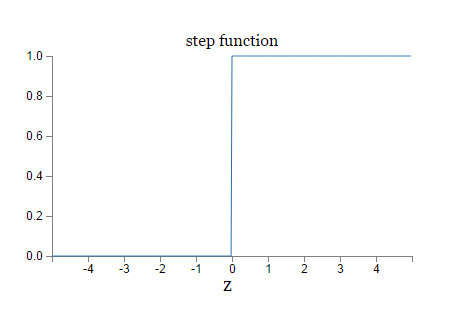
2.2、Sigmoid function
假如
σ
的表现形式为 阶跃函数(
step
function
) ,那么
sigmoid
就是个普通的感知器 ,根据
w⋅x+b
为正还是负,决定输出为 0 or 1 。但实际上,
sigmoid
神经元工作方式为:平滑的
σ
函数表明,权重
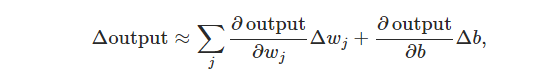
这里 Δoutput 是一个有关于权重( weights )变化量 Δwj 和偏置( bias )变化量 Δb 的线性函数。这种线性函数更有利于网络对 weights 与 bias 进行微调,以至于感知器可以尽可能地学习到“想要”的规则。/font>
3 总结
我们该如何去阐述 sigmoid 神经元的输出,很明显,与感知器所不同的是, sigmoid 神经元的输出不只局限在 0 or 1 。它的输出可以是 0 到 1 之间的任意数值,如 0.124…,0.864…。这样的改变,将对整个神经网络产生质的变化。
代码实现:
class Network(object):
def __init__(self, sizes):
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]
def sigmoid(z):
"""
sigmoid 函数实现
"""
return 1.0/(1.0+np.exp(-z))














 2920
2920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









