







通信 vs 计算
Kepler架构来说,其峰值处理性能达到了3900Gflops,而其带宽只有250GB/s,约等于63Gflops。计算/通信约等于60。也就是说我们编写的程序达到的计算/通信极限是60左右,一般来说很难达到这个数值,但是我们需要朝着这个目标而努力。
计算/通信比还有一个叫法:Compute to Global Memory Access(CGMA)ratio。
具体来说,执行一个计算指令只需要1~4个时钟周期,而从global memory中访问一个数据需要400 ~ 800个时钟周期,从shared memory中访问需要1 ~ 20 个时钟周期。
数据预取与重用
尽量复用GPU中更快的内存空间,比如shared memory、register。即将频繁使用的数据从global memory中预取数据到shared memory中。
针对不同内存层次的优化技术

Host memory
-
Pined memory:通过将host端分配的内存进行page lock,从而提高host端内存分配的性能。
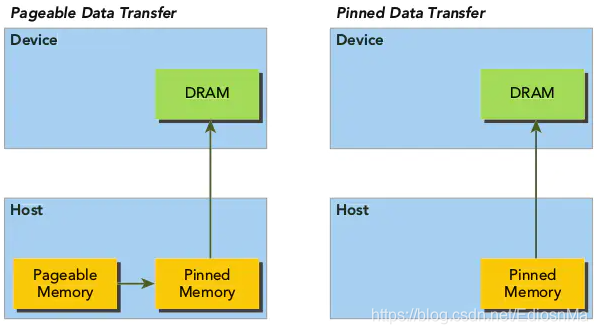
从上图可以看出,pageable 的host到device的数据拷贝需要先分配一个临时的Pinned memory才能将host内存的物理地址映射到device中。而pinned 数据传输直接将设备端的内存进行page lock,放置重新创建临时pinned memory,因此可以提高效率。但是过多的分配page-locked的memory也会影响host端的性能。 -
Asynchronous computation & data transfer
异步计算就是让cpu和gpu没有数据依赖的逻辑并执行,例如下图所示

异步数据传输:
将数据拷贝的过程也进行异步,不等待device端内存拷贝完成,直接返回。cudaMemcpyAsync(dst, src, size, dir, stream)。

使用cudaMemcpyAsync需要注意的是需要使用cudaMallocHost去pinned住host的内存。 -
Streams:是一种将数据传输与计算进行overlap的技术。
一般情况下一个kernel的执行过程为:

而利用stream之后其执行过程会pipeline化,如下图:

将数据集进行分块的传输与计算可以将计算与数据传输重合。具体的使用方法为:

举个栗子:

Global memory/ Local memory
local memory虽然是片外内存,但是其有L1&L2两级缓存。如下图所示:

L1级缓存是偏上缓存,其访存速度和share memory一样快;而L2级缓存是在片外,其访存速度和global memory一样。
-
Memory coalescing
从GPU硬件的角度来看,对于global memory来说如果一个warp中的所有线程访问的是一个连续的内存地址,那么就可以批量的读取(也就是将多个线程的io request变成一个io request)内存中的数据。
因此当从global memory中读写数据的时候,尽量使得线程进行连续的内存访问,可以提高访存效率。 -
Tiled 算法
为了加快访存的速度,我们通常会将global的数据拷贝到shared memory当中,但是一个shared memory的内存是有限的,将global memory中的数据一次性拷贝到shared memory 的这种做法不适用与一些大的数据计算。
tiled 算法就是将数据进行切分到shared memory的大小。

Shared memory
- bank conflict
为了提高内存读写带宽,共享内存被分割成了32个等大小的内存块,即Bank。因为一个Warp有32个线程,相当于一个线程对应一个内存Bank。
理想情况下就是不同的线程访问不同的bank,可能是规则的访问,如线程0读写bank0,线程1读写bank1,也可能是不规则的,如线程0读写bank1,线程1读写bank0。这种同一个时刻每个bank只被最多1个线程访问的情况下不会出现Bank conflict。
如下图所示:

特殊情况**如果有多个线程(一半warp数量)同时访问同一个bank的时候也不会产生Bank conflict,即broadcast。但当多个线程同时访问同不同bank时,Bank conflict就产生了。**例如线程0访问地址0,而线程1访问地址32,由于它们在同一个bank,就导致了这种冲突。
避免bank冲突的方式有:
- 线性的访存
- 1:1对应
- broadcast
4. Memory padding:额外的增加内存避免bank 冲突,比如下面看到32个warp同时访问32个bank就会有bank冲突:

但是如果我们多加一列的话,就不会存在bank 冲突了:
















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









