






 本文介绍了深度学习中的WaveNet模型,其利用扩张卷积和门控激活函数生成高质量语音。同时,对比了Tacotron系列,特别是从Tacotron1到Tacotron2的改进,强调了声码器从Griffin-Lim到WaveNet的变化。文章详细解析了网络架构和关键组件如CBHG和LSTM的作用。
本文介绍了深度学习中的WaveNet模型,其利用扩张卷积和门控激活函数生成高质量语音。同时,对比了Tacotron系列,特别是从Tacotron1到Tacotron2的改进,强调了声码器从Griffin-Lim到WaveNet的变化。文章详细解析了网络架构和关键组件如CBHG和LSTM的作用。
WaveNet
论文链接:https://arxiv.org/pdf/1609.03499.pdf
Wavenet模型是一种序列生成模型(不是传统意义上的端到端模型),可以用于语音生成建模。在语音合成的声学模型建模中,Wavenet可以直接学习到采样值序列的映射,因此具有很好的合成效果,相当于传统TTS的后端部分。
1.核心创新点扩大卷积网络Dilated causal convolutionWavenet
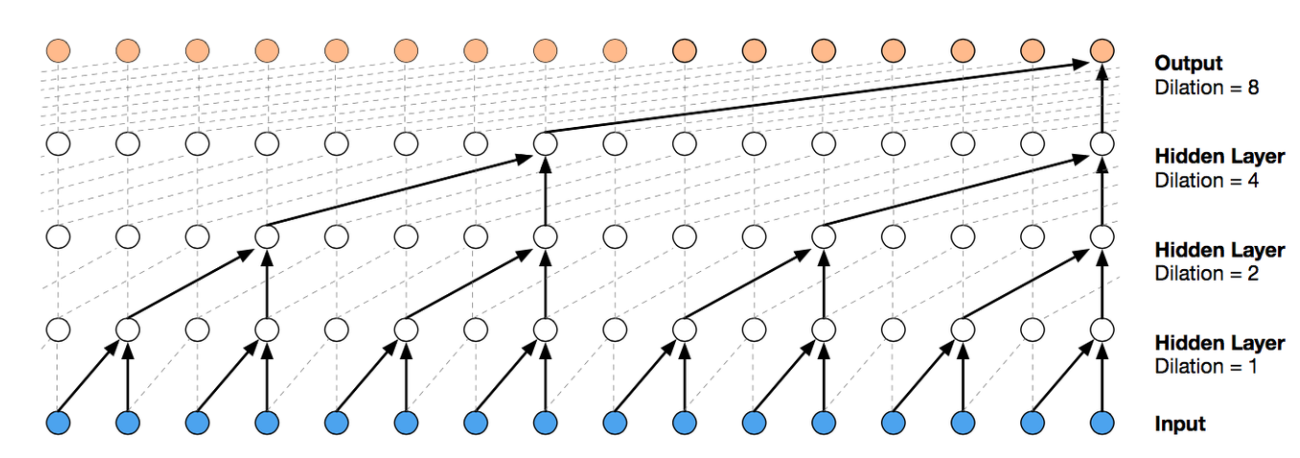
1.Dilation:输入的数据间隔是多少。
2.Kernel:核是多少,即每次输入几个数。(一个黑色箭头,代表一个输入个数)
2.网络架构
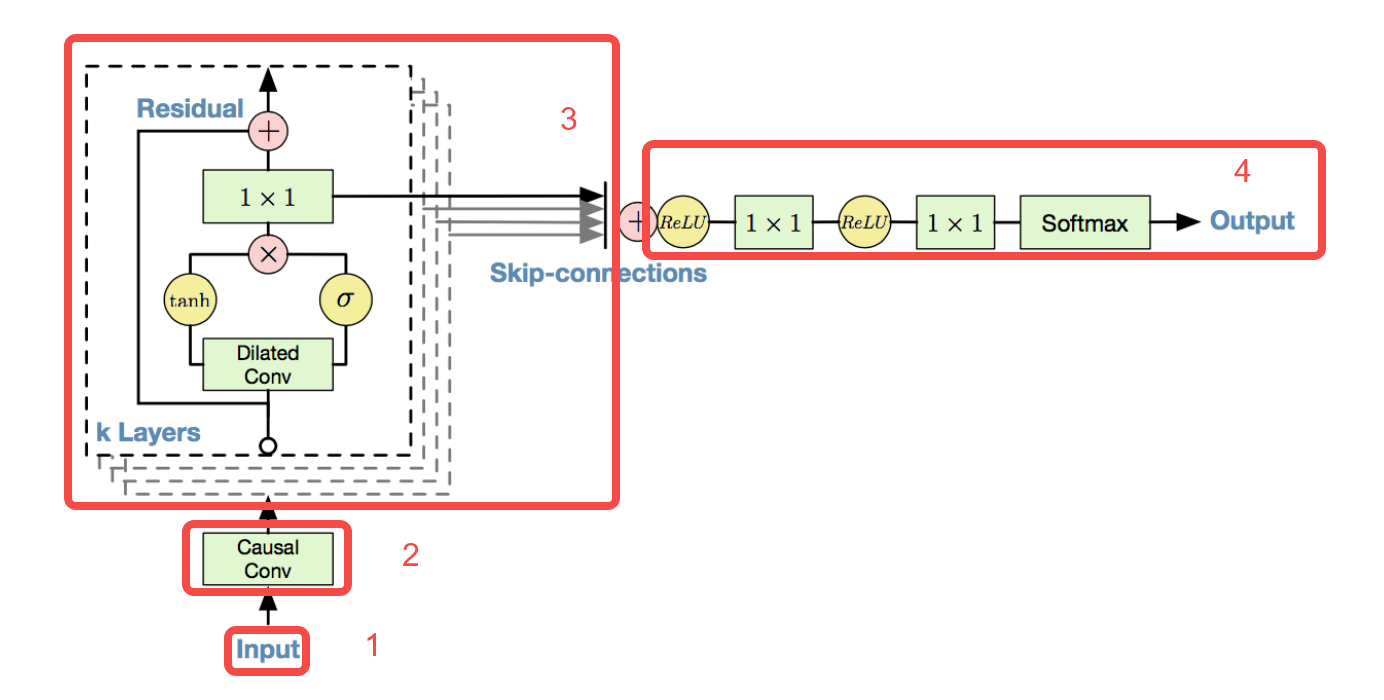
1.输入
2.因果卷积层
3.扩大卷积网络是Wavenet核心网络层,铺开来之后,每一层的输出不是直接作为下一层的输入,而是和输入合并后输出给下一层(Residual部分),也就是说这是一个残差网络,每一层再训练和目标的差值。
4.输出
3.激活函数
WaveNet是一种基于深度学习的生成式语音合成系统,它使用了一种名为门控的激活函数(Gated Activation Unit)。门控激活函数在很多深度学习模型中也被广泛应用,例如循环神经网络(RNN)和长短时记忆网络(LSTM)中的遗忘门和输入门等。
WaveNet中的门控激活单元可以理解为一种特殊的激活函数,它可以在网络中学习到长距离的依赖关系。为了实现这一点,WaveNet使用了一种基于卷积神经网络(CNN)的扩张卷积结构。卷积层的每一层都应用了门控激活单元。
在WaveNet中,门控激活单元的公式如下:
z = tanh(W_f * x) ⊙ σ(W_g * x)其中,x 是输入,W_f 和 W_g 是卷积层的权重矩阵, ⊙ 表示元素乘法(Hadamard乘法),tanh 和 σ 分别代表双曲正切激活函数和Sigmoid激活函数。上式中,tanh(W_f * x) 代表用于提取特征的变换,而 σ(W_g * x) 是门控机制,它控制着输入中每个特征的信息流。
通过组合 tanh 和 sigmoid 函数,门控激活单元可以实现对输入信息的选择性保留和过滤。这使得WaveNet能够捕捉不同时间尺度的信息,从而有效地生成高质量的自然语音。
门控激活函数在深度学习模型中有很多作用和优势。这种特殊的激活函数可以帮助模型在训练过程中保留和过滤输入信息,从而实现更好的性能。以下是门控激活函数的一些作用和好处:
- 捕捉长距离依赖关系:门控激活函数通过选择性地保留或抑制输入特征,使得模型可以捕捉长距离的依赖关系。这对于处理时序数据(如自然语言和音频信号)特别重要,因为这些数据中的信息往往具有长期依赖性。
- 解决梯度消失/梯度爆炸问题:在训练深度神经网络时,梯度消失和梯度爆炸是常见的问题。门控激活函数可以帮助模型在训练过程中稳定梯度,从而缓解这些问题。例如,在长短时记忆网络(LSTM)中,遗忘门和输入门就是使用门控激活函数来控制信息流,从而解决了梯度消失的问题。
- 动态信息选择:门控激活函数允许模型在训练过程中动态地选择和过滤输入数据的不同部分。这种选择性可以提高模型的泛化能力和表示能力,帮助模型捕捉更复杂的模式。
- 网络容量控制:门控激活函数可以控制网络的容量。通过调整门控结构的数量和参数,可以增加或减少模型的容量。这使得模型在训练过程中可以平衡拟合能力和泛化能力,从而避免过拟合或欠拟合。
总之,门控激活函数是一种非常有效的激活函数,可以帮助深度学习模型在训练过程中学习复杂的模式、捕捉长距离依赖关系,并提高泛化能力。这些优势使得门控激活函数在很多深度学习应用中(如自然语言处理、语音合成和时间序列分析等)具有广泛的应用前景。
Tacotron
论文链接:https://arxiv.org/pdf/1703.10135.pdf
Tacotron是Google于2017年提出的第一个真正意义上的端到端语音合成系统,其工作流程主要是输入待合成的文字,输出梅尔语谱图,再通过Griffin-Lim声码器将语谱图转换成波形图。目前模型共有两代,Tacotron2主要的改进是简化了模型,同时将声码器替换为WaveNet,提高了语音合成的自然度。
1.Tacotron1的网络架构
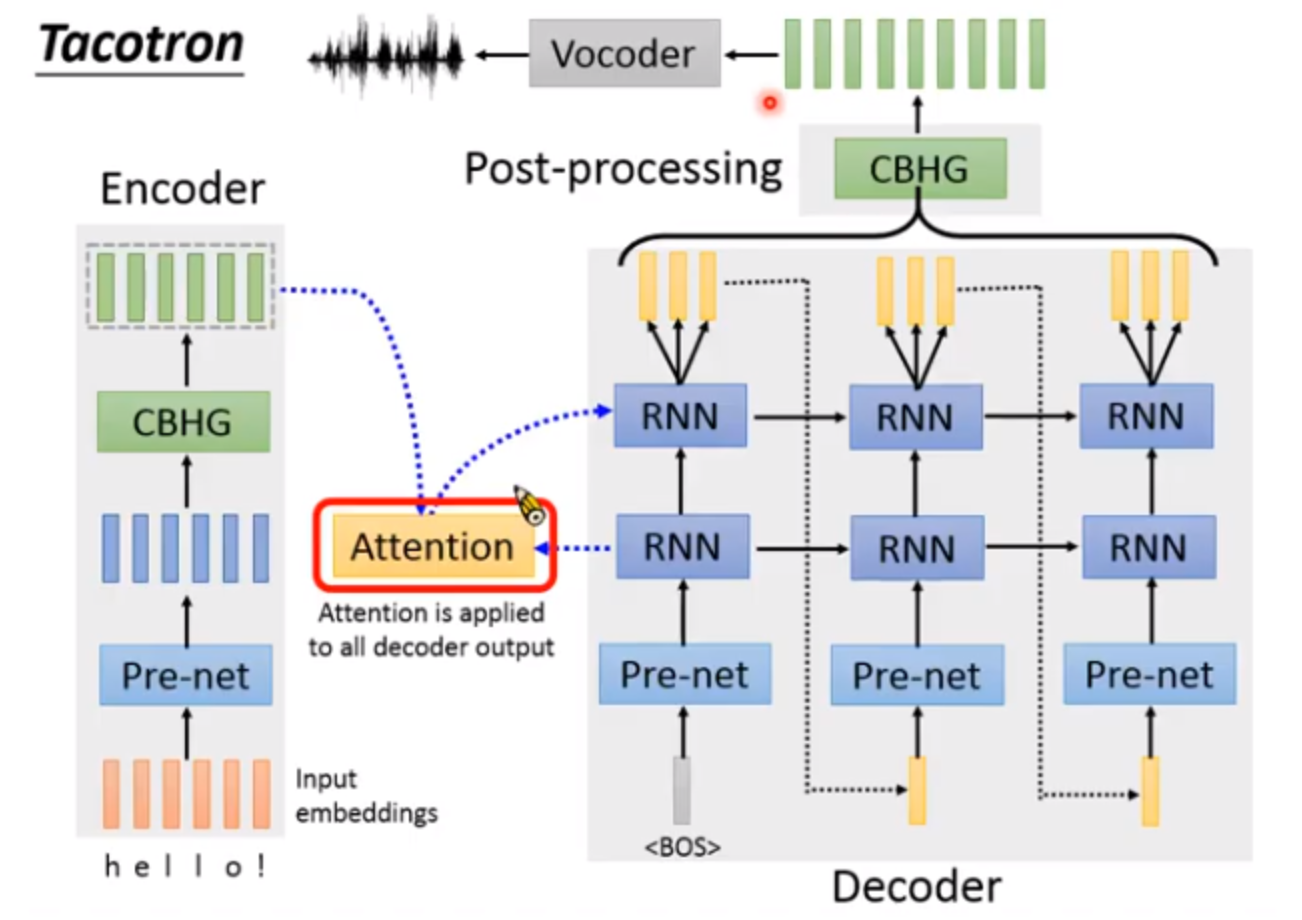
- Encoder:解码器,将输入的文字text-embedding转换成一组向量。
- Attention:自注意力机制,学习如何对齐文本序列和语音帧,序列中的每个字符编码通常对应多个语音帧并且相邻的语音帧一般也具有相关性。
- Decoder:将Encoder编码的向量解码成语谱。
- Post-processing:后处理网络用于将该Seq2Seq模型输出的声谱转换为目标音频的波形,在Tacotron中先将预测频谱的振幅提高(谐波增强),再使用Griffin-Lim算法即Vocoder(声码器)估计相位从而合成波形。
Griffin-Lim算法是一种用于从短时傅里叶变换(STFT)的幅度谱(magnitude spectrum)重构音频信号的算法。换句话说,在给定一个音频信号的幅度谱但不知道相位信息的情况下,Griffin-Lim算法可以近似地还原原始音频信号。
该算法的基本思想是通过迭代更新相位信息,直到满足特定的收敛标准。下面是Griffin-Lim算法的基本步骤:
- 从给定的幅度谱中使用随机相位初始化音频信号。
- 对音频信号执行STFT,从结果中提取相位信息。
- 使用给定的幅度谱和新的相位信息构造一个新的复数谱。
- 对新的复数谱执行逆短时傅里叶变换(ISTFT),还原音频信号。
- 如果算法未达到预定的迭代次数,回到步骤2。
Griffin-Lim算法不断迭代更新相位信息,以便最终近似地还原原始音频信号。这种算法在语音处理、音频生成和频谱修复等应用中非常有用,尤其是当我们没有原始音频信号的相位信息时。需要注意的是,Griffin-Lim算法能够实现的音频重建是近似的,并不是完美的原始信号还原。
Griffin-Lim算法合成的音频会携带特有的人工痕迹并且语音质量较
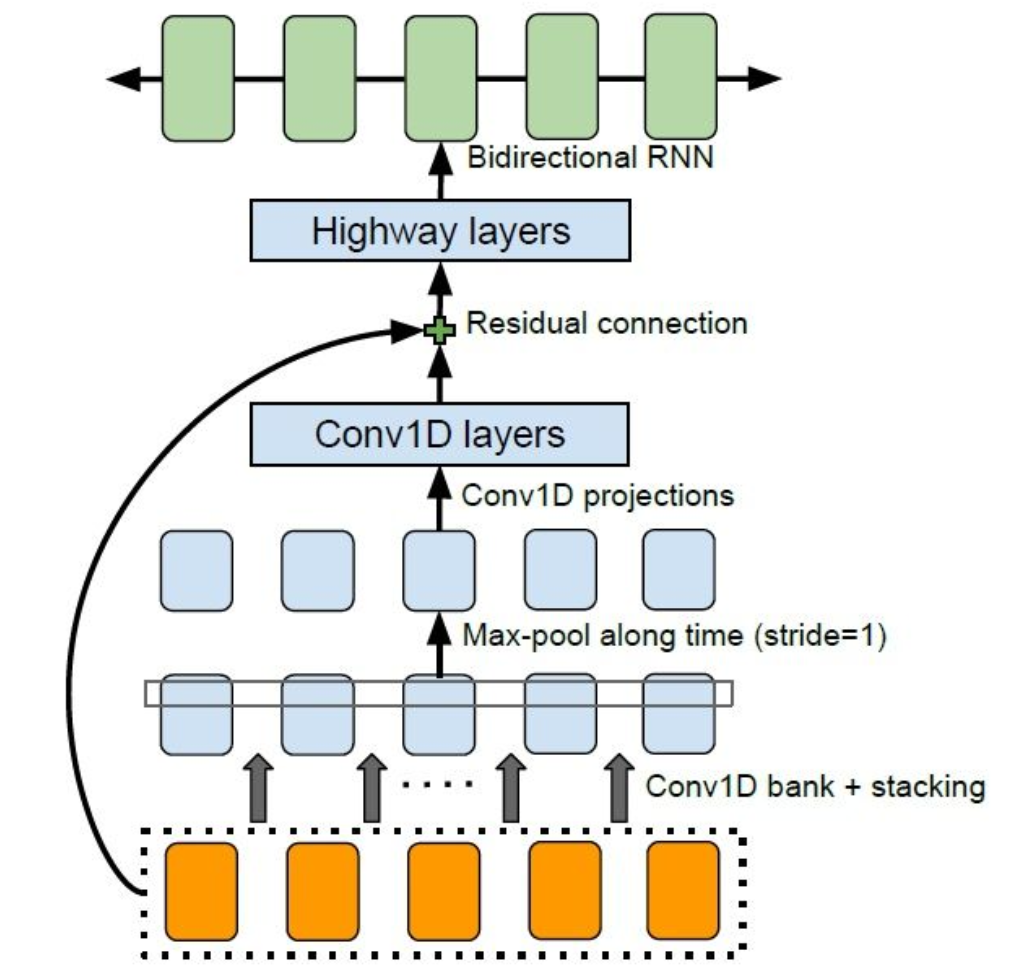
- CBHG:它由一维卷积滤波器(1D-Convolution Bank)、高速公路网络(Highway Network)、双向门控递归单元(Bidirectional GRU)和循环神经网络(Recurrent Neural Network,RNN)组成,被用于从序列中提取高层次特征。
2.Tacotron2的网络架构
论文链接:https://arxiv.org/pdf/1712.05884.pdf
这位博主讲解的非常好,大家可以去这里参考学习:http://t.csdnimg.cn/qJQxU
在Tacotron改进版Tacotron2中:去除了CBHG模块,改为使用更普遍的长短期记忆网络(Long Short-Term Memory,LSTM)和卷积层代替CBHG;在后处理网络中Tacotron2使用可训练的WaveNet声码器代替了Griffin-Lim算法。
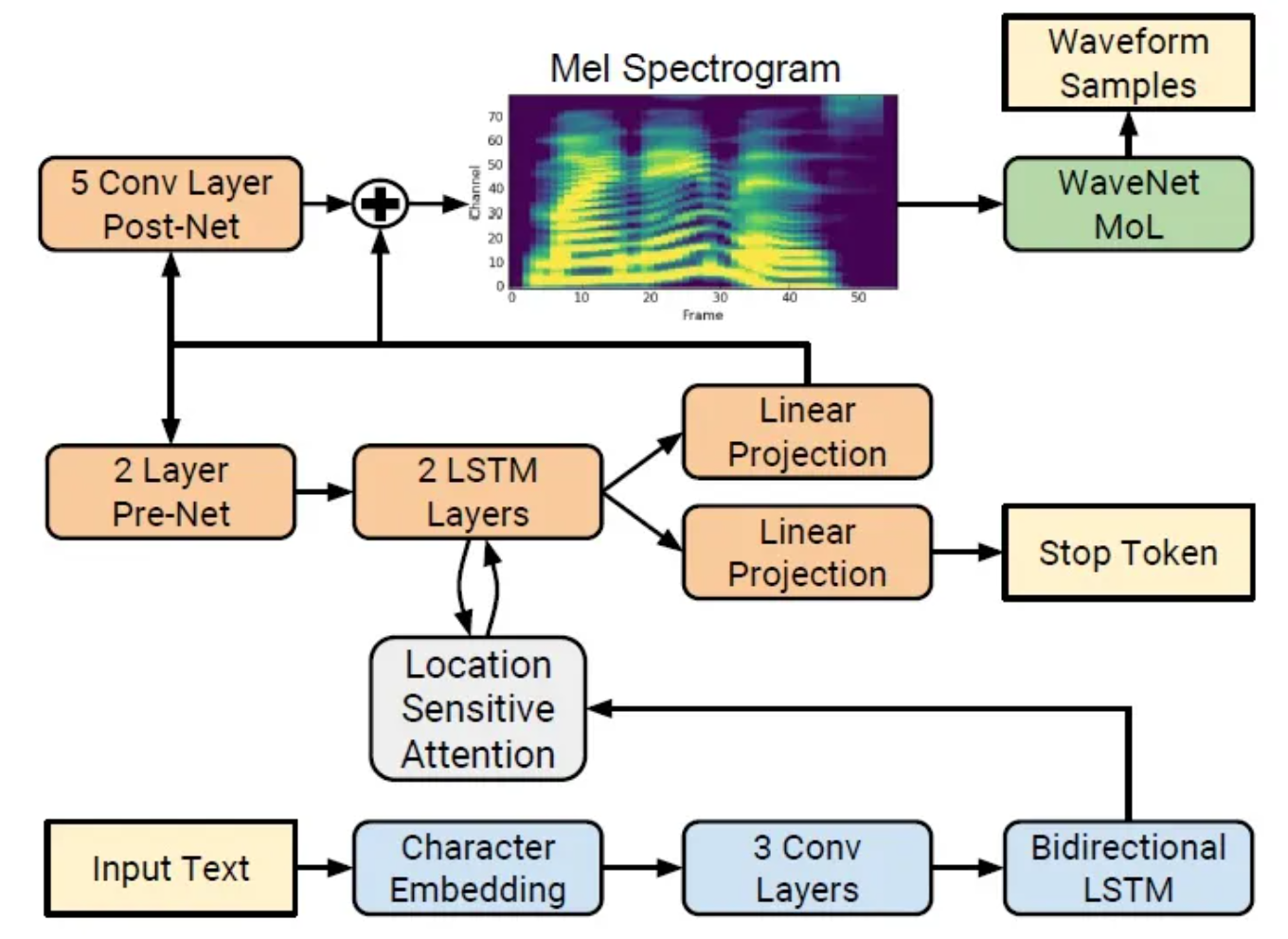
在csdn上看到有一个博主讲解的十分详细,大家可以去看看这位博主的,链接:http://t.csdnimg.cn/HJ5PC
模型从下到上可以看作两部分,声谱预测网络和声码器。声谱预测网络是一个Encoder-Attention-Decoder网络,用于将输入的字符序列预测为梅尔频谱的帧序列;声码器(vocoder):一个WaveNet的修订版,用于将预测的梅尔频谱帧序列产生时域波形。
1.编码器
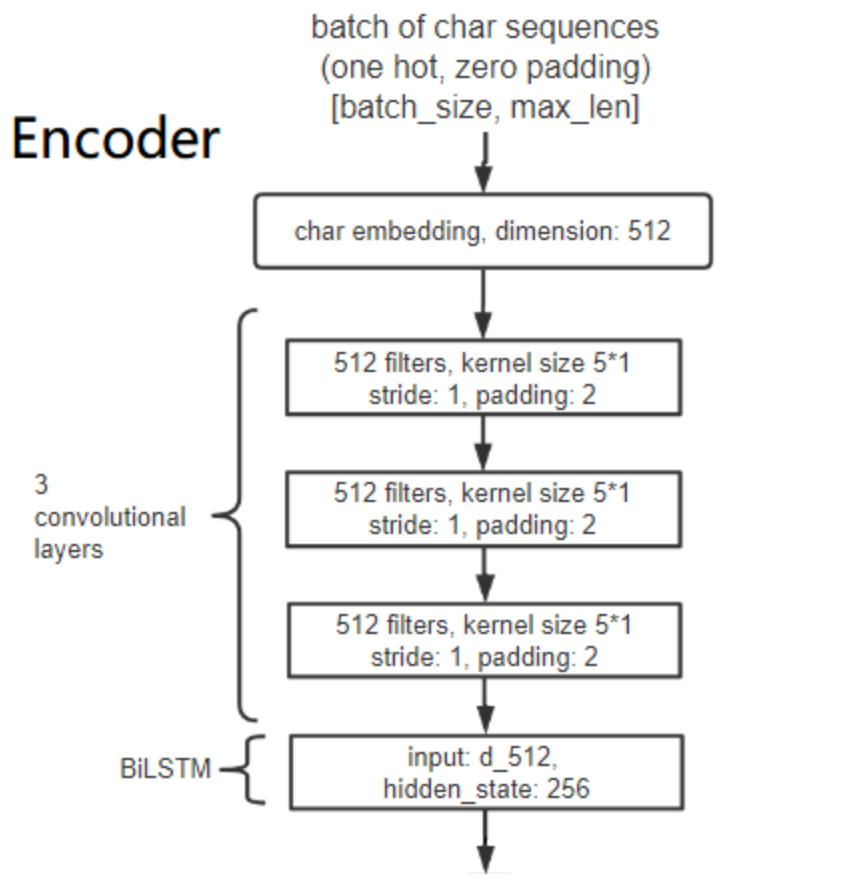
如上图所示,Encoder的具体流程为:
输入的数据维度为[batch_size, char_seq_length],使用512维的Character Embedding,把每个character映射为512维的向量,输出维度为[batch_size, char_seq_length, 512]
3个一维卷积,每个卷积包括512个kernel,每个kernel的大小是5*1(即每次看5个characters)。每做完一次卷积,进行一次BatchNorm、ReLU以及Dropout。输出维度为[batch_size, char_seq_length, 512](为了保证每次卷积的维度不变,因此使用了pad)
上面得到的输出,扔给一个单层BiLSTM,隐藏层维度是256,由于这是双向的LSTM,因此最终输出维度是[batch_size, char_seq_length, 512]
单层BiLSTM(单层双向长短时记忆网络)是一种特殊的循环神经网络(RNN)架构,它处理序列数据并捕捉长距离依赖关系。让我们分解这个概念,以便更好地理解其中的每个部分。
- 单层(Single Layer):在神经网络中,层数是指模型中堆叠在一起的层的数量。在这里,“单层”意味着仅使用一个LSTM层来处理输入数据。如果模型包含多层LSTM,我们将它称为深度LSTM模型,这可以帮助捕捉更复杂的数据表示和更强大的学习能力。然而,在这个例子中,只有一个LSTM层。
- BiLSTM(双向长短时记忆网络):双向LSTM是一种特殊的LSTM架构,其中两个单向LSTM层沿着相反的方向处理输入序列。其中一个LSTM层正向处理序列,另一个LSTM层反向处理序列。这种架构允许模型捕捉序列中的前后依赖关系。在处理过程结束时,正向和反向LSTM的输出结果合并在一起。
所以,当我们说“单层BiLSTM”,它表示使用单层双向长短时记忆网络处理输入序列。一个正向LSTM在单层中处理输入序列,而一个反向LSTM处理输入序列的逆序。它们的输出结果合并后作为最终输出。在您的例子中,最终的输出维度为 [batch_size, char_seq_length, 512]。
其中一些各种概念的解释:
- BatchNorm(批量归一化):批量归一化是一种在神经网络中用于加速训练、减少过拟合和提高模型泛化性能的技术。在神经网络训练过程中,BatchNorm通过对每个层的激活值进行归一化(即使它们具有零均值和单位方差)来减少内部协变量偏移(Internal Covariate Shift)。这使得网络在各个层之间可以更好地进行训练,并允许使用更高的学习率,从而加快收敛速度。
- ReLU(Rectified Linear Unit,修正线性单元):ReLU是一种常见的非线性激活函数,主要用于神经网络中为神经元添加非线性特性。ReLU定义为 f(x) = max(0, x),即输入为正时输出等于输入值,而输入为负时输出为0。由于ReLU的计算简单且能有效地缓解梯度消失问题,因此在各种深度学习模型中广泛使用。
- Dropout:Dropout是一种用于神经网络的正则化技术,旨在减少模型过拟合并提高泛化性能。Dropout在训练过程中随机丢弃(即将激活值设为0)一定比例的神经元。这迫使网络在训练过程中不依赖于单个神经元,从而促使网络学习到更多独立的特征表示。通常,Dropout仅在训练过程中使用,在验证和测试过程中保持网络的完整结构。
- Pad(填充):填充是一种在卷积神经网络中用于调整输入数据维度的技术。卷积操作会导致输入数据边缘的丢失,从而可能影响网络提取的特征质量。填充是一种在输入数据的边缘添加额外值(通常为0)以保持数据维度的方法。在您的例子中,使用填充是为了保持卷积后的数据维度与输入数据相同,即[batch_size, char_seq_length, 512]。
- LSTM(Long Short-Term Memory,长短时记忆网络):LSTM是一种特殊类型的循环神经网络(RNN),用于处理序列数据和捕捉长距离依赖关系。与传统RNN不同,LSTM通过使用门控单元(gated units)来解决梯度消失和梯度爆炸问题。这使得LSTM能够在长序列中捕捉相关性。在给定的例子中,使用了单层双向LSTM(BiLSTM)。这意味着LSTM分为两个方向,一个正向处理序列,另一个反向处理序列。这样可以捕捉序列中的前后依赖关系。最后将两个方向的输出合并到512维向量中,输出维度为[batch_size, char_seq_length, 512]。



















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











