







希望尽可能将自己学习过程中参考过的资料进行系统的整理,方便后面的初学者更快的找到自己想要的资料!
笔记持续更新中…
LLM基础学习02:分布式训练核心架构与多级并行策略详解——DDP/FSDP/ZeRO实战代码、显存优化方案及技术资源全景索引
LLM基础学习03:Qwen2.5-1.5B-Instruct指令微调全流程实践——LLaMA Factory框架与GSM8K评估
本文的所有代码都放在了仓库Basic-LLM-Learning中,欢迎star!!!
简介
根据前一篇最后的结论,现在决定选取选取Qwen/Qwen2.5-1.5B作为base model,选取GSM8K作为微调数据集完整整篇文章的实验和记录。
本文主要依据LLaMA Factory中LoRA相关的部分进行原理的学习和代码实验的比较(包括原始LoRA、LoRA+、rsLoRA、DoRA和PiSSA),并且在每个微调方法中贴上对应的论文链接。后文中全部方法中与微调相关的参数均由Deepseek的建议设置,其他参数全部相同(每个方法测试lora_rank为8、16和512),每个方法中的“实验”小节仅展示训练过程的曲线,最终结果在“结果对比”中进行展示。
本文涉及到的代码都是基于LLM基础学习03修改对应的训练配置文件实现的,所以想要跟着一起跑一遍的同学可能需要回头看一下这个。
题外话:本来还是想测一下全参微调方面的代码的,可惜沿着之前的模型和数据集做测试的话显存不够用了。。。所以只能测一下LoRA相关的。
LoRA
原理
论文链接:LoRA: Low-Rank Adaptation of Large Language Models
LoRA方法认为,大模型在参数微调过程中,参数的更新不是在全参数空间上进行的,而是在一个维度更低的空间中进行(即更新的参数所构成的矩阵实际上是一个低秩矩阵),所以模型的优化可以在低维空间进行,也就是低秩分解矩阵(一个低秩的矩阵可以分解为两个简单矩阵的乘积)中进行。另外的一个重要的优点就是,由于LoRA微调的结果是一些比较小的矩阵,在训练后使用时是直接加到原模型上,这就大大方便了细分方向任务的微调,不用每个任务都存一个巨大的模型,而是只要存一个LoRA微调的结果再叠加到原模型后就可以在细分任务中使用。
现在假设一个超级简单的预训练好的模型里面有一个权重矩阵
W
0
W_0
W0,
h
=
W
1
x
=
W
0
x
+
Δ
W
x
=
W
0
x
+
B
A
x
h=W_1x=W_0x+\Delta Wx=W_0x+BAx
h=W1x=W0x+ΔWx=W0x+BAx
现在我们要基于这个权重针对具体任务进行微调,微调后的权重是
W
1
W_1
W1,由于
W
1
W_1
W1是在
W
0
W_0
W0的基础上梯度下降逐步更新来的,所以整个微调过程可以视为是在原权重
W
0
W_0
W0上进行加加减减的操作,我们把整个微调过程中所有的这种操作叠加记为
Δ
W
\Delta W
ΔW,这个实际上就是微调过程中模型学习到的东西(所谓参数的更新),那么根据前面的结论:“模型的优化可以在低维空间进行”,可以进一步使用两个矩阵相乘来表示这个参数更新,即
B
B
B和
A
A
A,可以参考论文中的图示:
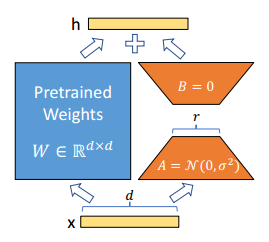
图中 W W W表示原权重矩阵, B B B和 A A A表示微调过程中学习到的参数,按照图中的维度,原来需要训练的参数量是 d × d = d 2 d\times d=d^2 d×d=d2个参数,使用矩阵分解后需要训练的参数量就是 2 d r 2dr 2dr,假如 d = 64 , r = 8 d=64,r=8 d=64,r=8,最终就是 4096 4096 4096和 1024 1024 1024的区别,差了四倍!而按照论文中提到的在GPT3上的训练,显存的需求直接从1.2TB变成了350GB(虽然还是很大就是了)。

参数
finetuning_type: lora # lora微调
lora_target: all
lora_rank: 8 # 16
flash_attn: fa2
实验
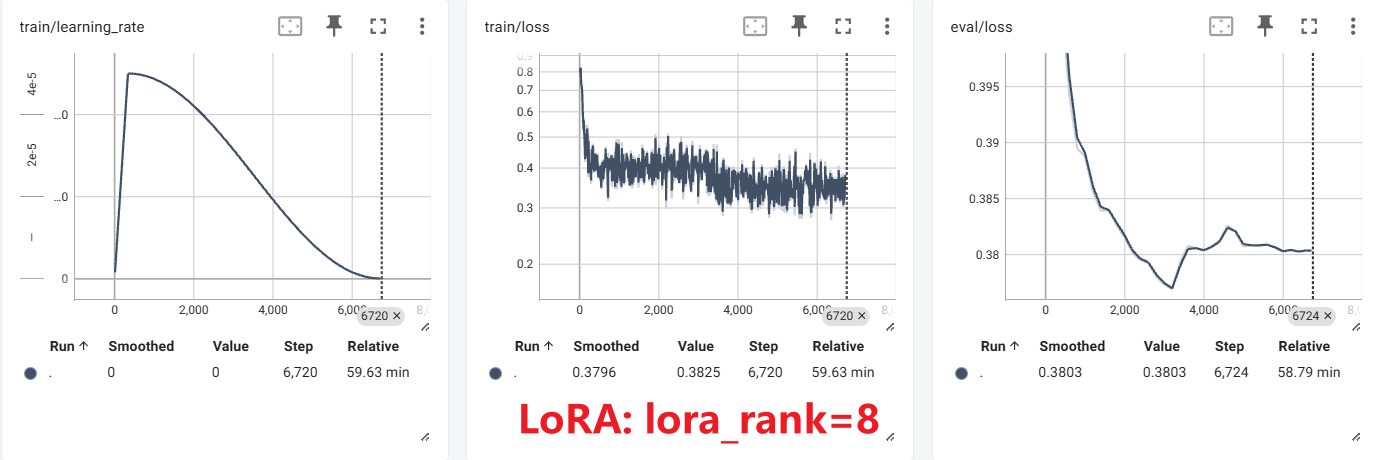
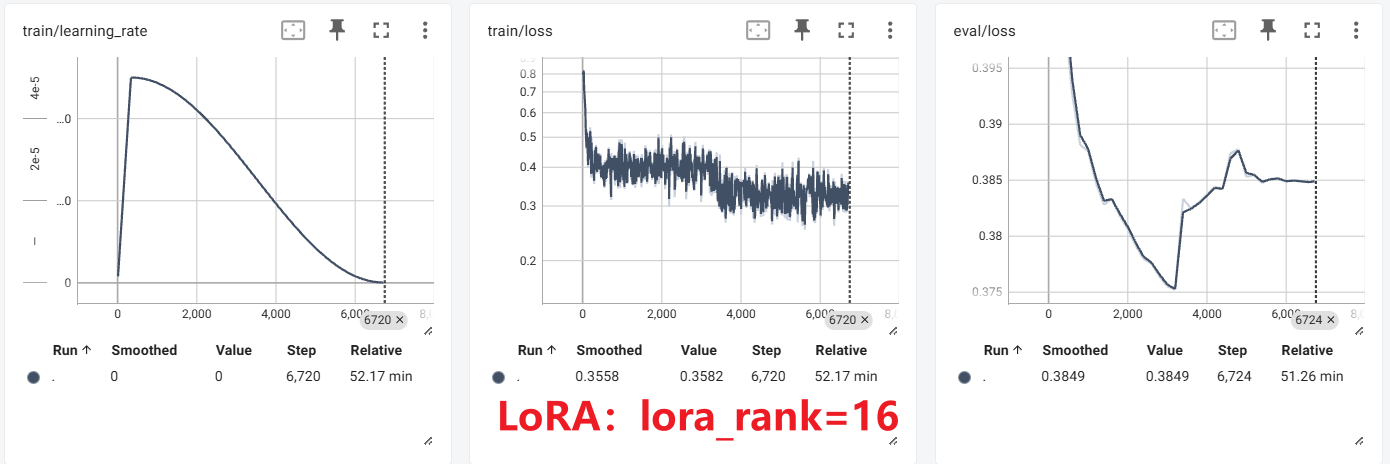
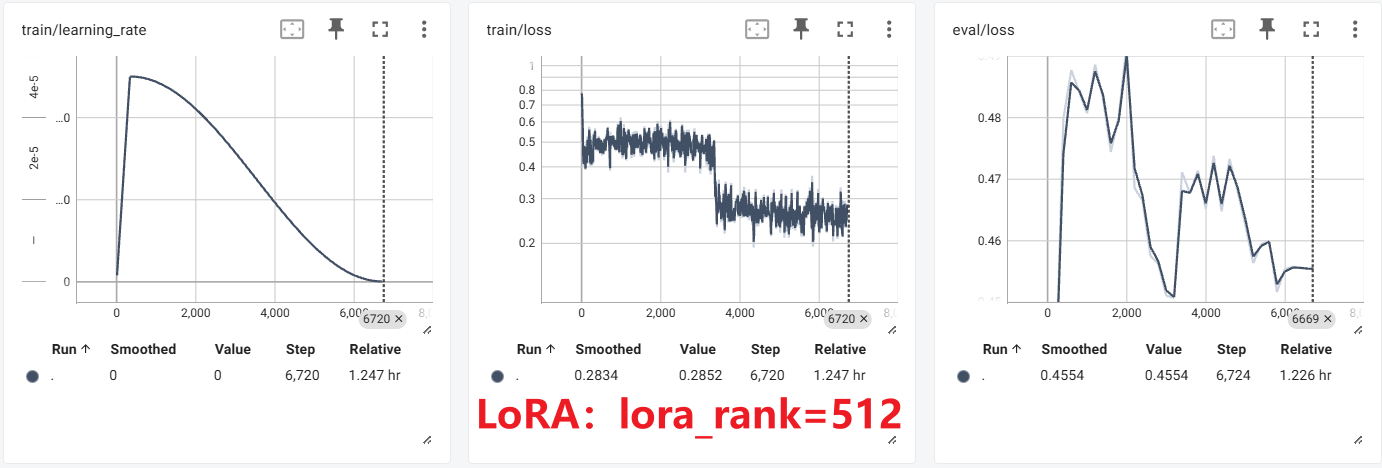
LoRA+
原理
论文链接:LoRA+: Efficient Low Rank Adaptation of Large Models
在LoRA中,矩阵 B B B使用全0初始化,矩阵 A A A使用随机高斯初始化(从高斯分布/正态分布中随机采样初始值);假如有两种初始化方式如下:
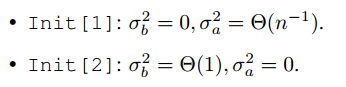
其中
σ
b
,
σ
a
\sigma_{b}, \sigma_{a}
σb,σa分别表示使用高斯初始化时
B
B
B和
A
A
A的正态分布的方差取值。如果假设模型为以下公式的简单情况:
f
(
x
)
=
(
W
∗
+
b
a
⊤
)
x
,
f(x)=(W^*+ba^\top)x,
f(x)=(W∗+ba⊤)x,
W
∗
∈
R
1
×
n
W^*\in\mathbb{R}^{1\times n}
W∗∈R1×n为预训练后的模型权重,
b
∈
R
,
a
∈
R
n
b\in\mathbb{R},a\in \mathbb{R}^{n}
b∈R,a∈Rn为对应的原来的矩阵
B
B
B和
A
A
A。基于这个假设,可以得到下面关于两个矩阵的梯度值,

另外可以得到梯度更新前后的模型输出变化为 Δ f t \Delta f_{t} Δft,这里标出了三个项:第一个项表示固定a或固定b时对模型输出的产生的变化关于学习率是线性的,而两个矩阵的参数同时参与模型更新时,学习率对模型输出产生的变化则是平方影响的。如果 Δ f t = Θ ( 1 ) \Delta f_{t}=\Theta(1) Δft=Θ(1),即模型变化与模型宽度无关时,则公式的三个项中至少有一个项是 Θ ( 1 ) \Theta(1) Θ(1)的。
在微调的理想情况下,我们希望第一和第二个项都是 Θ ( 1 ) \Theta(1) Θ(1)的,否则两个矩阵中就会有一个没有被有效更新(相当于固定了一个矩阵,只对另一个矩阵进行的训练),也就是当第一和第二个项都是 Θ ( 1 ) \Theta(1) Θ(1)时,两个矩阵都对模型的更新起了效果(两个矩阵都有效参与了特征学习),这在论文中被称为是“LoRA是高效的”。
在论文的一通数学证明中,作者给出了这篇论文的第一个命题:

这个命题的含义是:当两个矩阵的参数按照上述提到的两个初始化方法初始化,并且学习率和模型宽度的某个次方相关时, Δ f t \Delta f_{t} Δft中的前两个项就无法保持 Θ ( 1 ) \Theta(1) Θ(1),也就是这时的“LoRA是不够高效的”。基于这个命题,作者认为在原始的LoRA中缺少了一些关键的参数设置!!
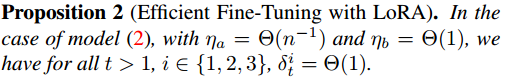
又是一通数学证明,论文认为为不同的矩阵分配不同的学习率时可以使 Δ f t \Delta f_{t} Δft中的所有项都是 Θ ( 1 ) \Theta(1) Θ(1)的,这就得出了这篇论文的第二个命题:只要两个矩阵的学习率分别符合 η a = Θ ( n − 1 ) \eta_{a}=\Theta(n^{-1}) ηa=Θ(n−1)和 η b = Θ ( 1 ) \eta_{b}=\Theta(1) ηb=Θ(1)时(b的学习率比a的学习率大得多),就可以使微调过程中两个矩阵都学习到有效特征。
在论文后面的部分中,可以简单理解为对上述的过程进行更加深入的分析,但是结论还是不变的。由于本文主要是对原理进行简单的介绍,所有就重复一下论文中的结论:对两个矩阵使用同样的学习率是无法学到有效特征的,按照前面的推导设置不同的学习率比例才能使两个矩阵同时学到有效特征。
参数
finetuning_type: lora # lora微调
lora_target: all
lora_rank: 8 # 16
loraplus_lr_ratio: 10
实验
这里与前面的原始LoRA对比可以看出,在相同的训练轮数中,**训练集上会有非常明显的损失值二次下降的过程,说明确实是比原始LoRA学习到了更多的特征。**但是对应的,由于选取的数据集和模型都比较小(学习能力差,数据集信息少),模型立马就在训练集上面过拟合了。
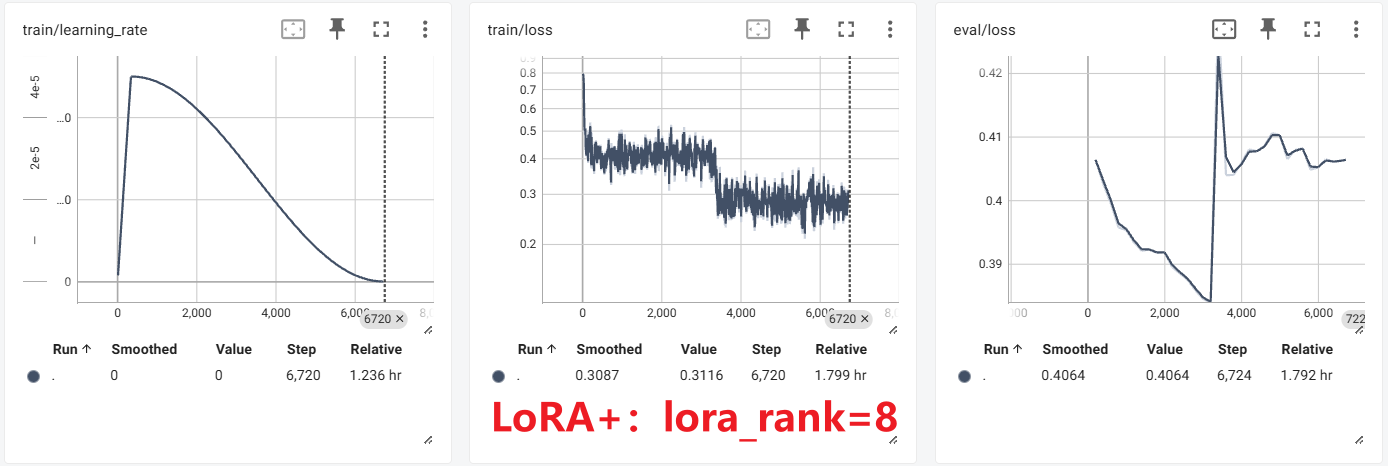
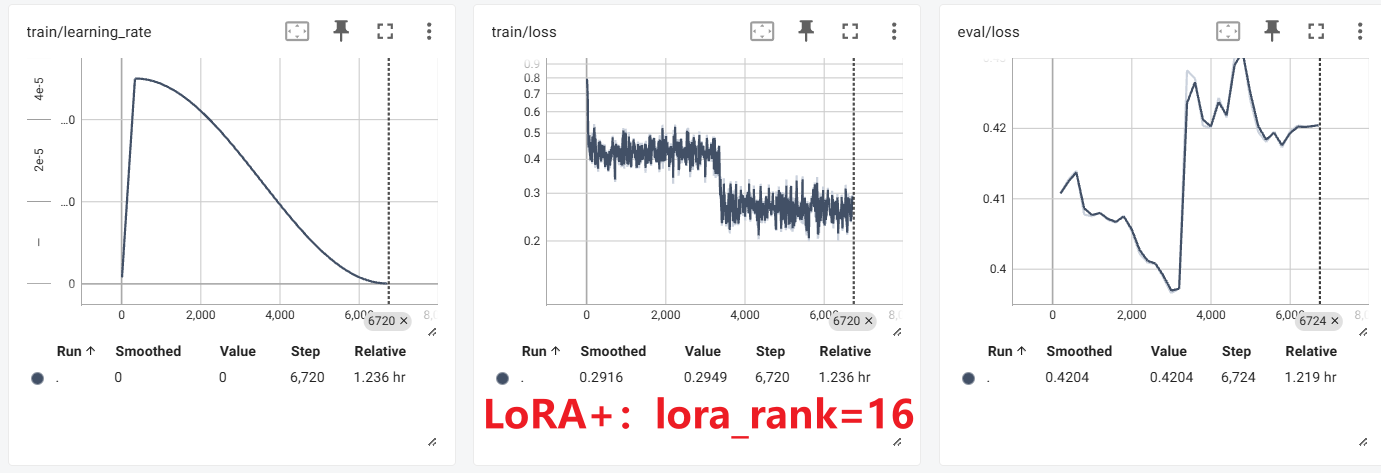
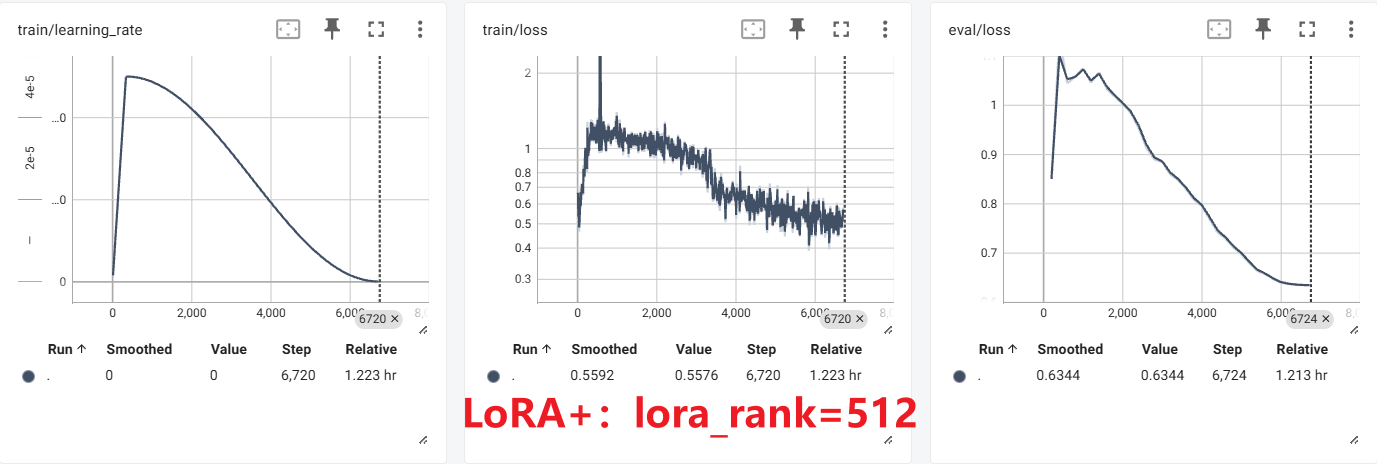
rsLoRA
原理
论文链接:A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA
在LoRA微调中,实际上两个矩阵相乘后前面还要乘以一个缩放因子,即完整的公式为:
W
+
γ
r
B
A
,
W+\gamma_rBA,
W+γrBA,
其中
γ
r
\gamma_r
γr可以看做是关于所设置的lora_rank的一个函数,我们需要保证
γ
r
\gamma_r
γr的设置是符合当前的训练的。为此,论文首先提出了一个关于秩稳定(rank-stabilized)的定义,即前向传播稳定性和反向传播稳定性(下面提到的适配器即为微调过程中的神经网络模块,也就是LoRA中的两个低秩矩阵):
- **前向传播稳定性:**如果适配器输入中的每个元素是独立同分布的,并且每个元素的m阶矩都是 Θ r ( 1 ) \Theta_{r}(1) Θr(1),那么适配器输出的每个元素的m阶矩也保持为 Θ r ( 1 ) \Theta_{r}(1) Θr(1)
- **反向传播稳定性:**如果损失函数对适配器输出的梯度在每个元素上为 Θ r ( 1 ) \Theta_{r}(1) Θr(1),则损失函数对适配器输入的梯度在每个元素上也保持为 Θ r ( 1 ) \Theta_{r}(1) Θr(1)

基于这个定义,论文证明了一个定理:在使用前面提到的第一种初始化方法时,当且仅当 γ r \gamma_r γr的收敛速率属于 Θ r ( 1 r ) \Theta_r(\frac1{\sqrt{r}}) Θr(r1)时,所有适配器是秩稳定的。

参数
finetuning_type: lora # lora微调
lora_target: all
use_rslora: true
lora_rank: 8 # 16
flash_attn: fa2
实验
这个,尴尬了。。。可能是参数没调好,和原LoRA对比没看出太大区别,不过现在只是了解基本概念基本方法,先不管了。
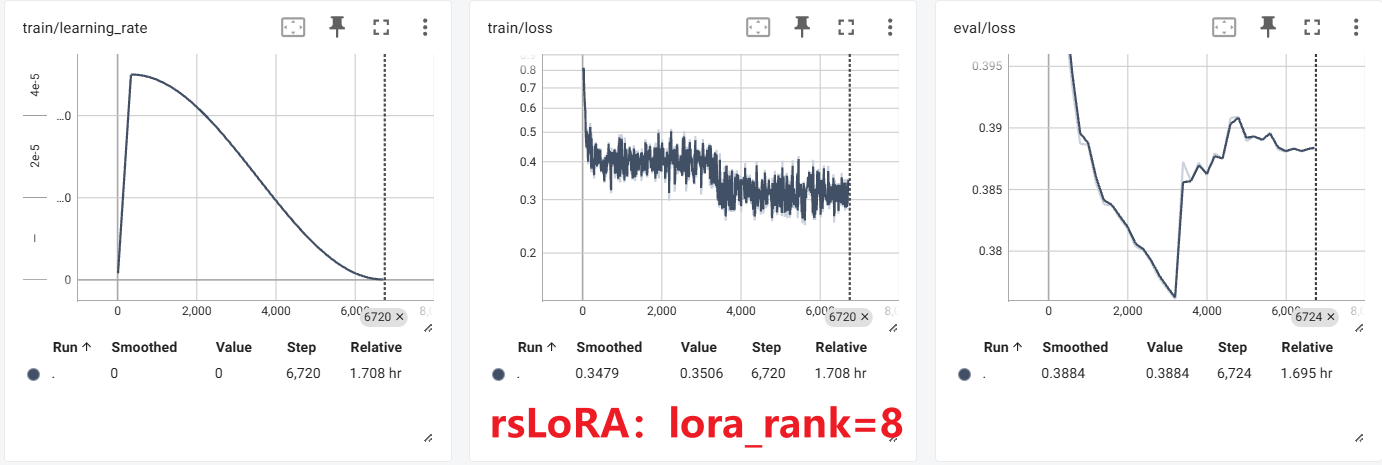
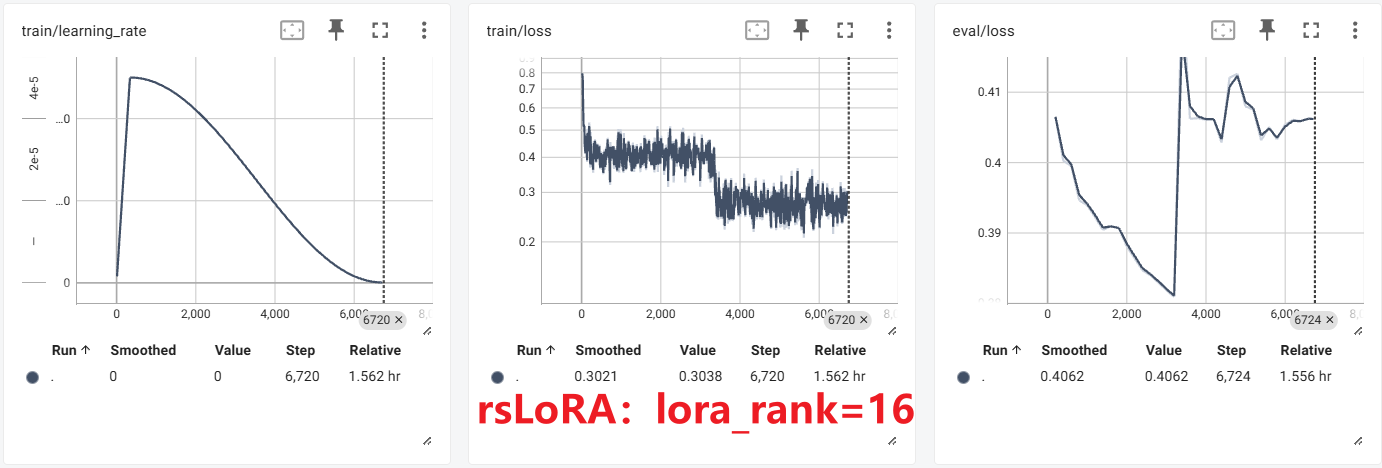
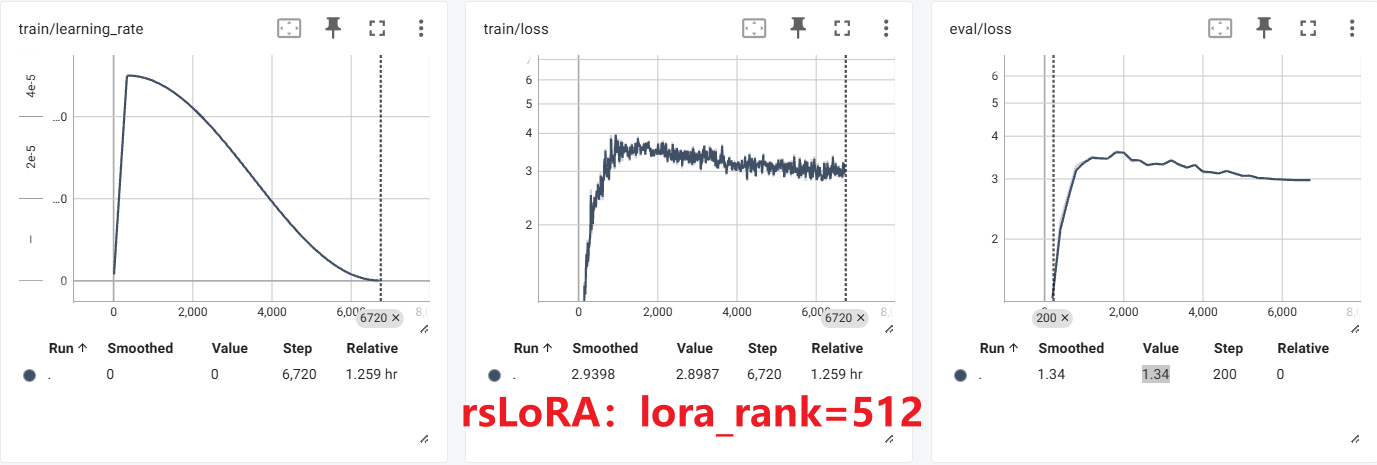
DoRA
原理
论文链接:DoRA: Weight-Decomposed Low-Rank Adaptation
如果说把LoRA+看做是把一起更新的两个矩阵分开来进行看待,那么DoRA就是把权重矩阵更新时的更新方向和更新大小分开来讨论。在LoRA中,微调过程需要同时关注更新大小(量级)和方向两个部分;而在DoRA中,微调过程强制参数专注于方向方面的学习,而量级将作为独立的可调参数。论文认为:通过这种方法进行微调,可以获得和全参微调差不多的效果。
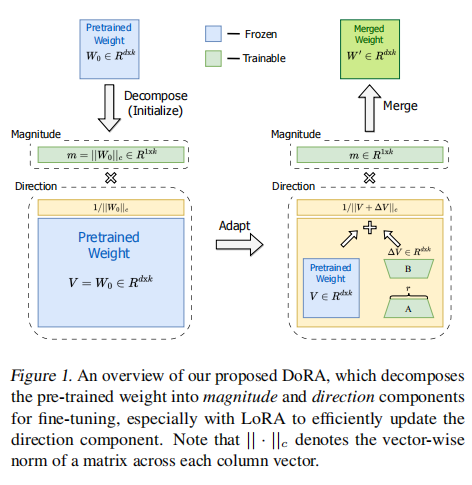
对照原论文中的图如上,首先原始权重可以进行按照公式进行分解得到量级和方向:
W
=
m
V
∣
∣
V
∣
∣
c
=
∥
W
∥
c
W
∣
∣
W
∣
∣
c
,
W=m\frac{V}{||V||_c}=\|W\|_c\frac{W}{||W||_c},
W=m∣∣V∣∣cV=∥W∥c∣∣W∣∣cW,
也就是对预训练权重进行分解,得到原权重矩阵的量级参数和方向参数,其中量级参数将初始化为可训练参数,方向参数则使用LoRA方法进行更新:
W
′
=
m
‾
V
+
Δ
V
∣
∣
V
+
Δ
V
∣
∣
c
=
m
‾
W
0
+
B
A
‾
∣
∣
W
0
+
B
A
‾
∣
∣
c
,
W'=\underline{m}\frac{V+\Delta V}{||V+\Delta V||_c}=\underline{m}\frac{W_0+\underline{BA}}{||W_0+\underline{BA}||_c},
W′=m∣∣V+ΔV∣∣cV+ΔV=m∣∣W0+BA∣∣cW0+BA,
其中带下划线的部分就是可训练参数。按照这个流程进行一次训练并合并所有参数后就可以按照LoRA的方法更新一次参数。
参数
finetuning_type: lora # lora微调
lora_target: all
lora_rank: 8
use_dora: true
实验
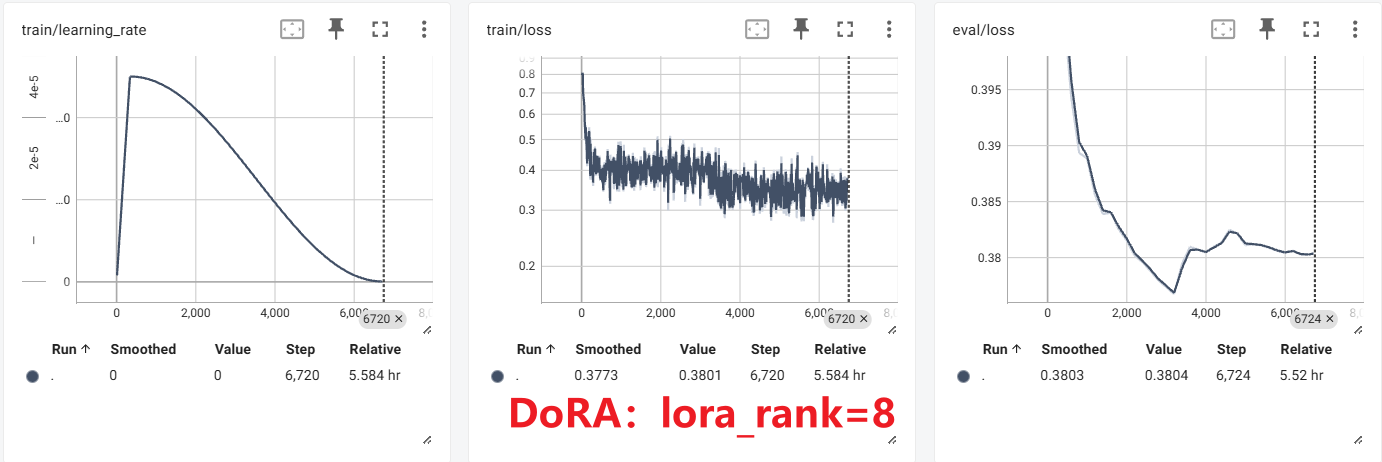
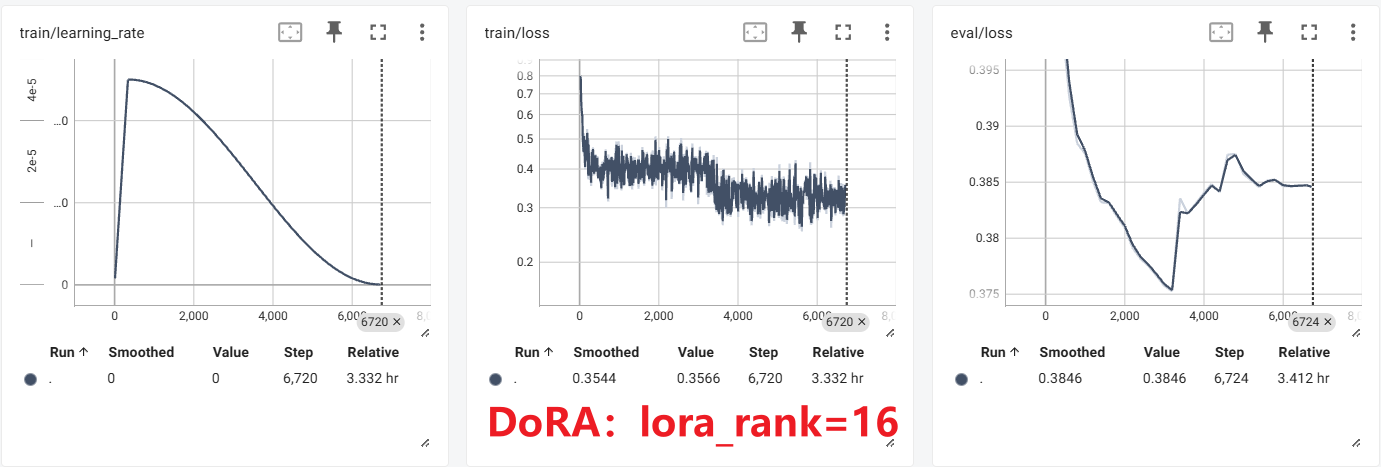
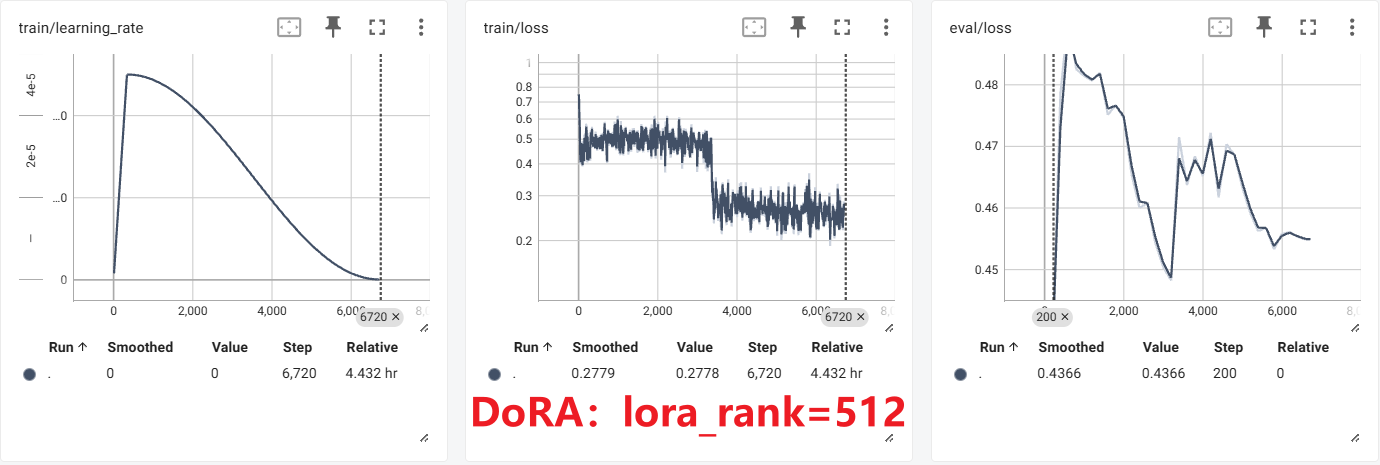
PiSSA
原理
论文链接:PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
LoRA+中讨论过一次关于两个矩阵参数初始化的设置,但是重点放在了两个矩阵学习率的设置上,而PiSSA就是对两个矩阵的参数初始化方法和需要训练的部分进行了讨论。
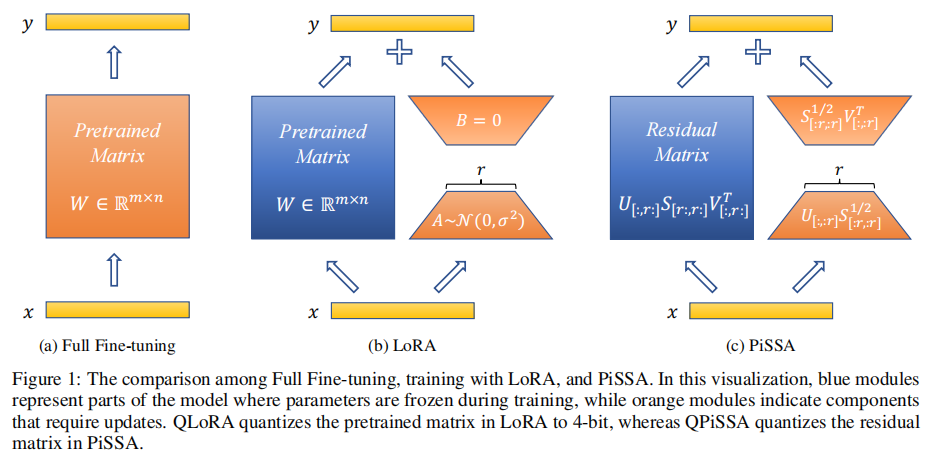
论文认为,原LoRA的初始化方法会导致训练过程中收敛缓慢并且导致刚开始训练时梯度更新方向随机,并且认为在权重更新中,主要是权重矩阵中的主成分对权重矩阵的变化起了主要作用,所以在训练过程中,PiSSA首先对权重矩阵进行奇异值分解(SVD),将原始的权重分为主成分部分和残差部分并基于这部分进行微调参数初始化,然后只对主成分部分使用LoRA方法进行微调。论文认为:这种方法可以加快收敛的速度,并且由于主成分部分包含更多的信息,所以在4-bit量化下也能保持高性能。
参数
finetuning_type: lora # lora微调
lora_target: all
lora_rank: 8
pissa_init: true
实验
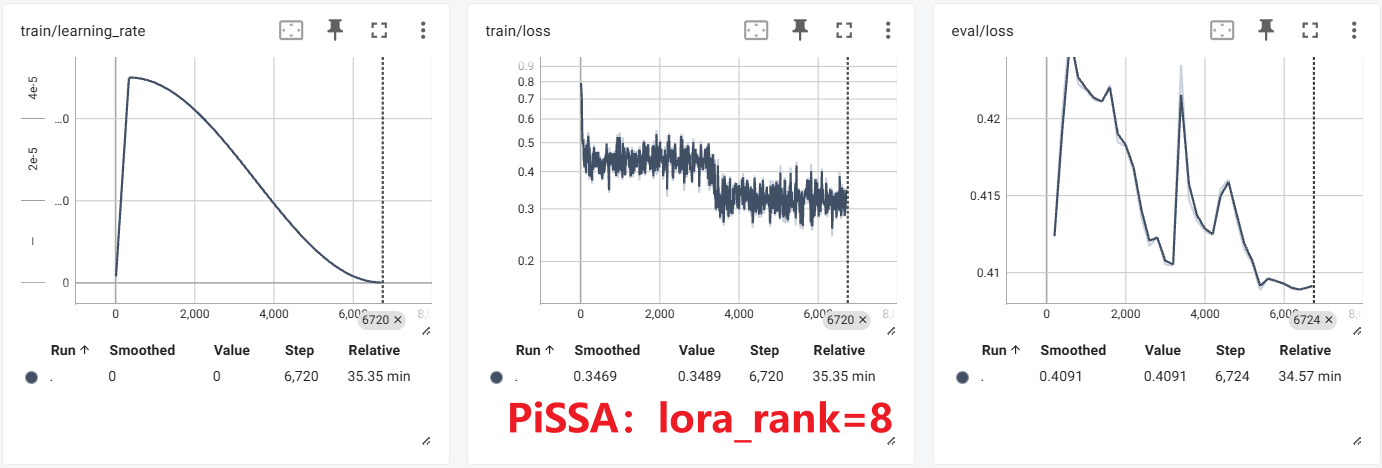
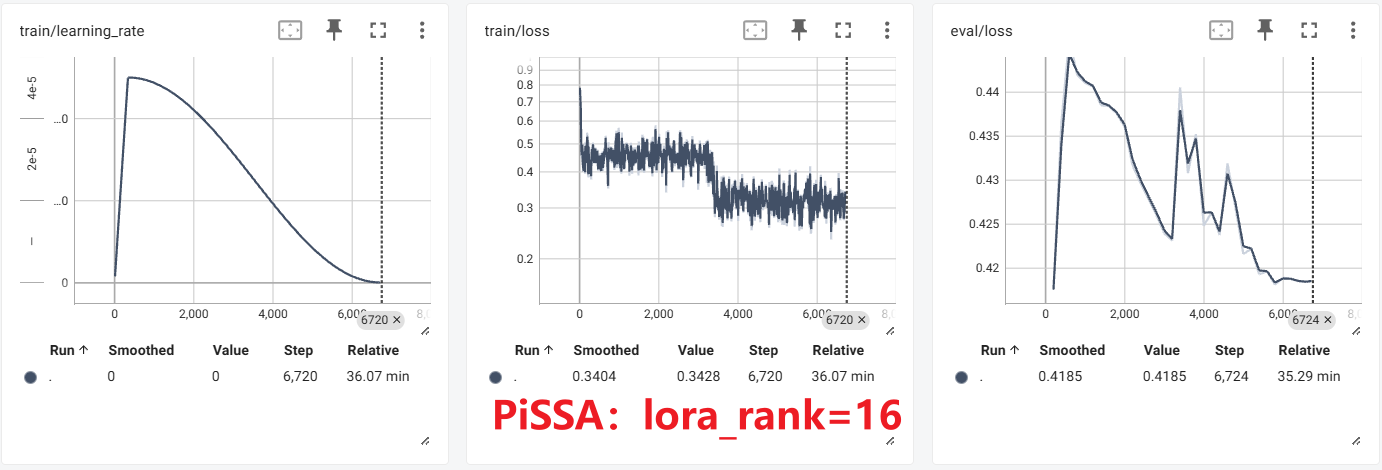
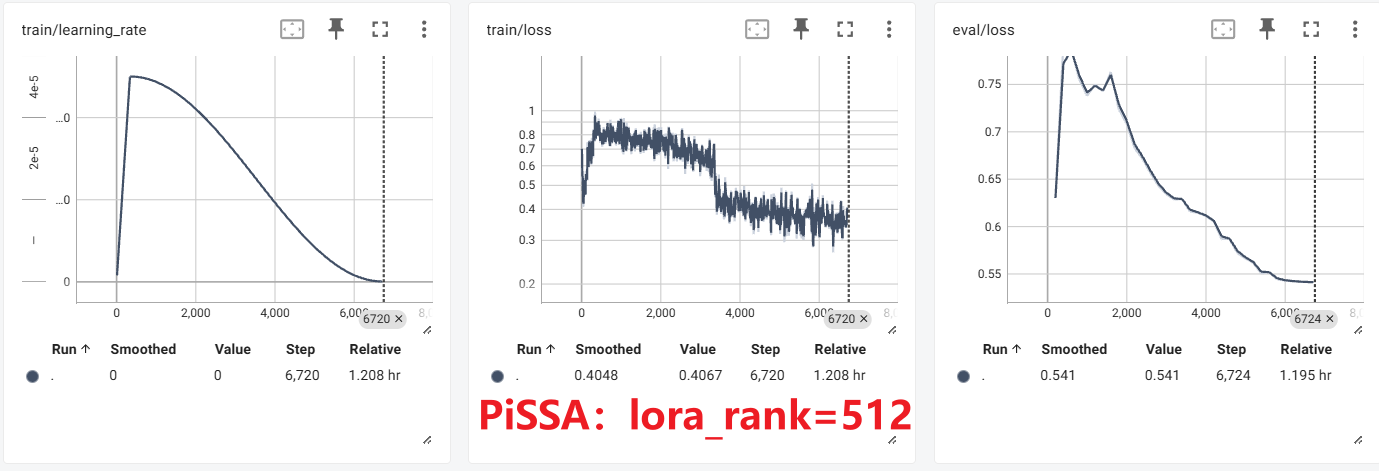
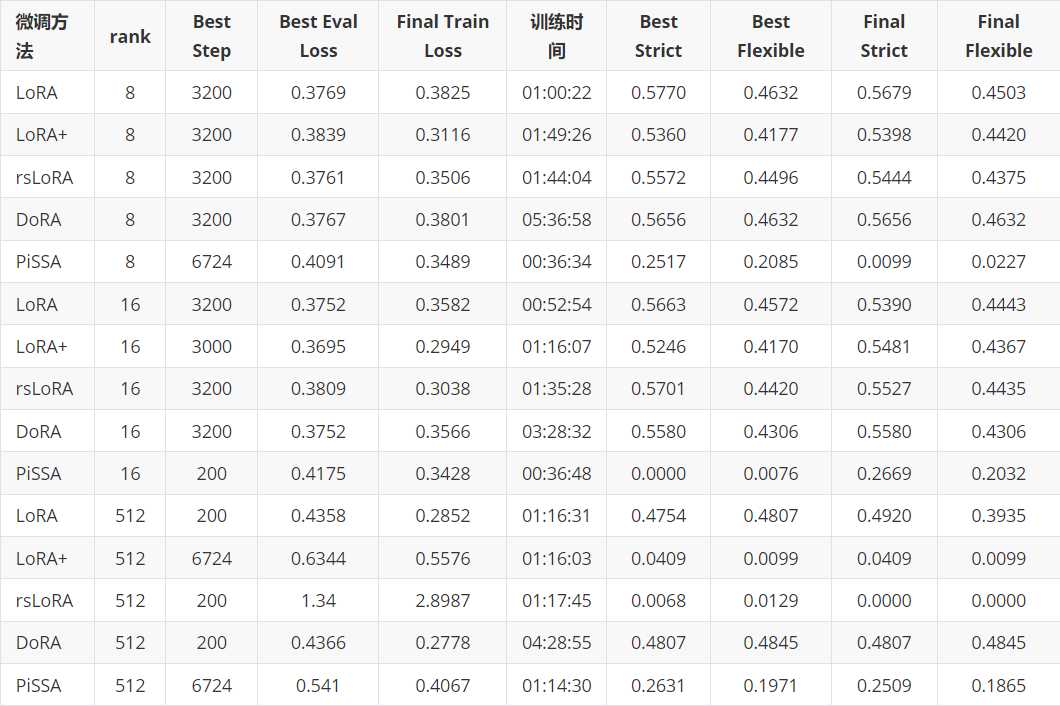
结果对比
疑问
其实在这篇笔记的学习中出现了非常多的疑惑,可以列出的就有以下几点了:
- 大模型的
learning_rate,weight_decay,warmup_ratio的设置好像都是凭经验或者做实验来选出最好的,但是没有一个系统性的这些参数选取的指导(也有可能是我没搜到) - 就本篇文章来说,虽然很大可能是没有选取最好的超参数来做实验,但是确实和最原始的LoRA方法差别有一点大,是理论推导的“假设”不对还是数据集和模型不合适也还不清楚
- 受限于设备,如果可以做更多实验的话,是不是全参微调的效果会更好?更大的模型的模型效果就一定会更好?
所有结果
首先强调一下,这个实验是非常不严谨的,毕竟只是学习期间顺手做的一个实验,有很多东西没考虑到的,比如没有每个方法都找到最优参数、没有用不同随机数种子多次实验求平均等等等等,所以这里把实验结果贴上来只是图一乐。
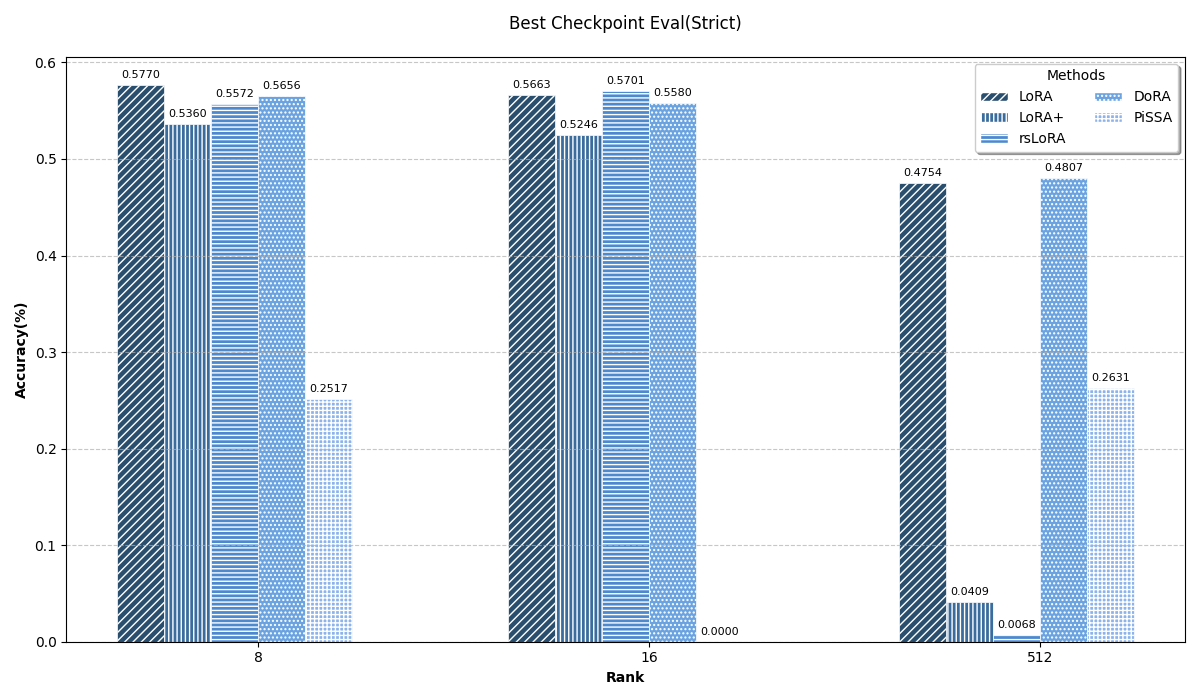
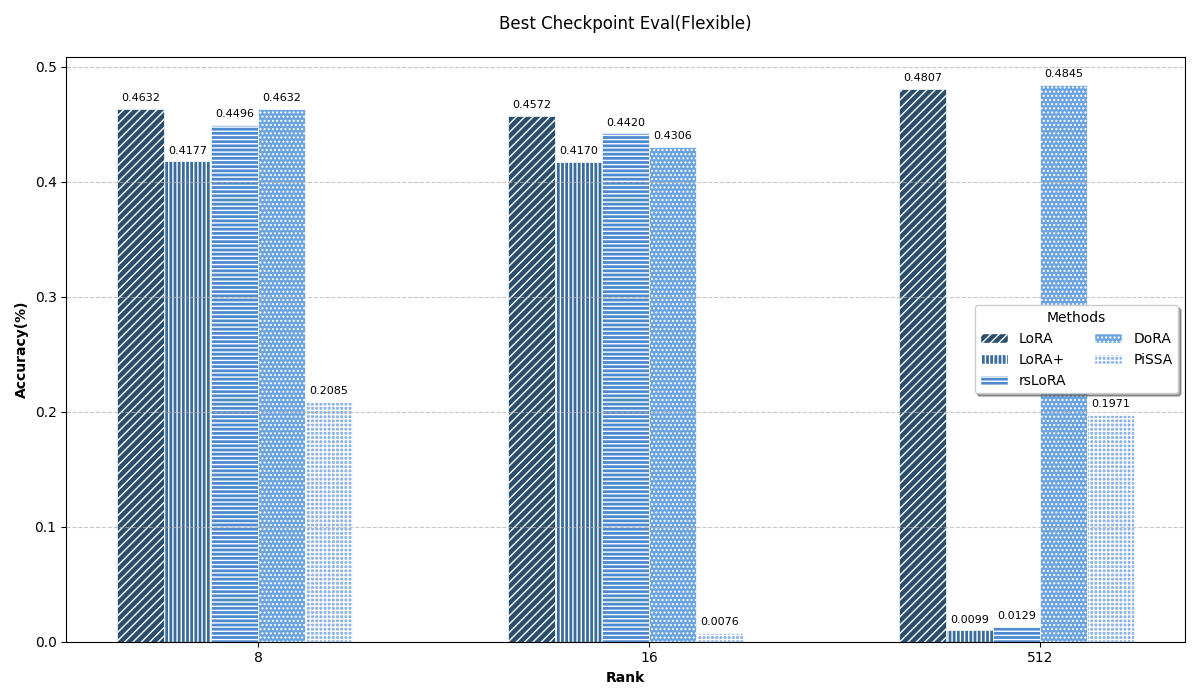
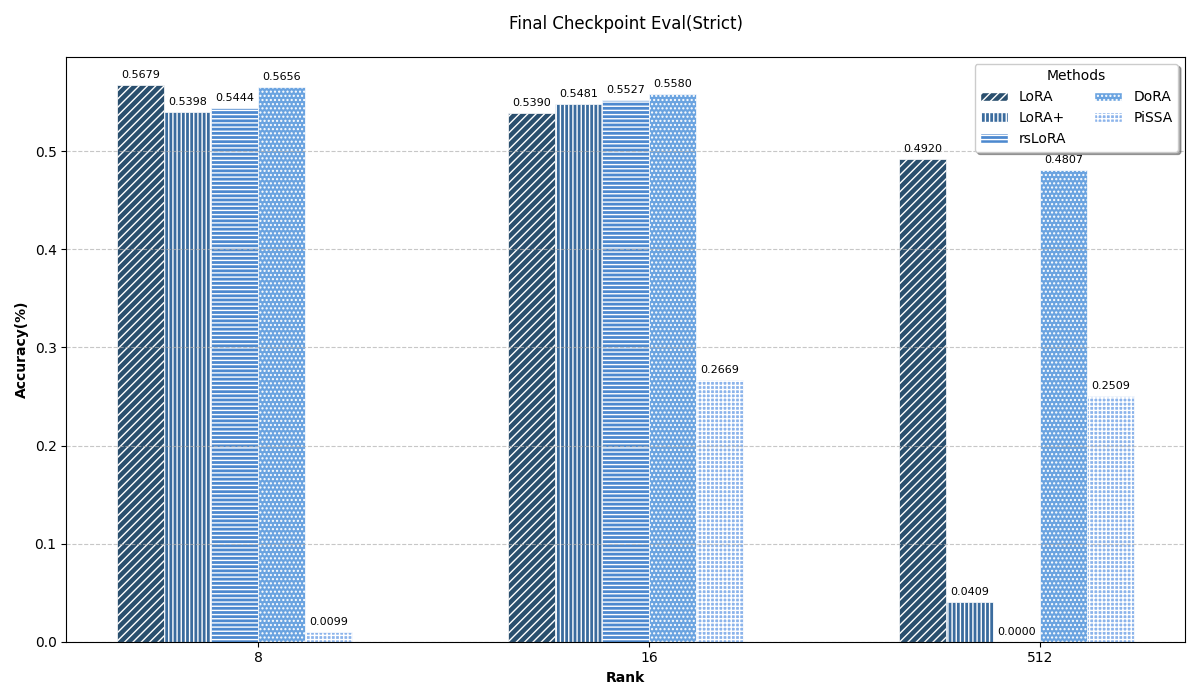
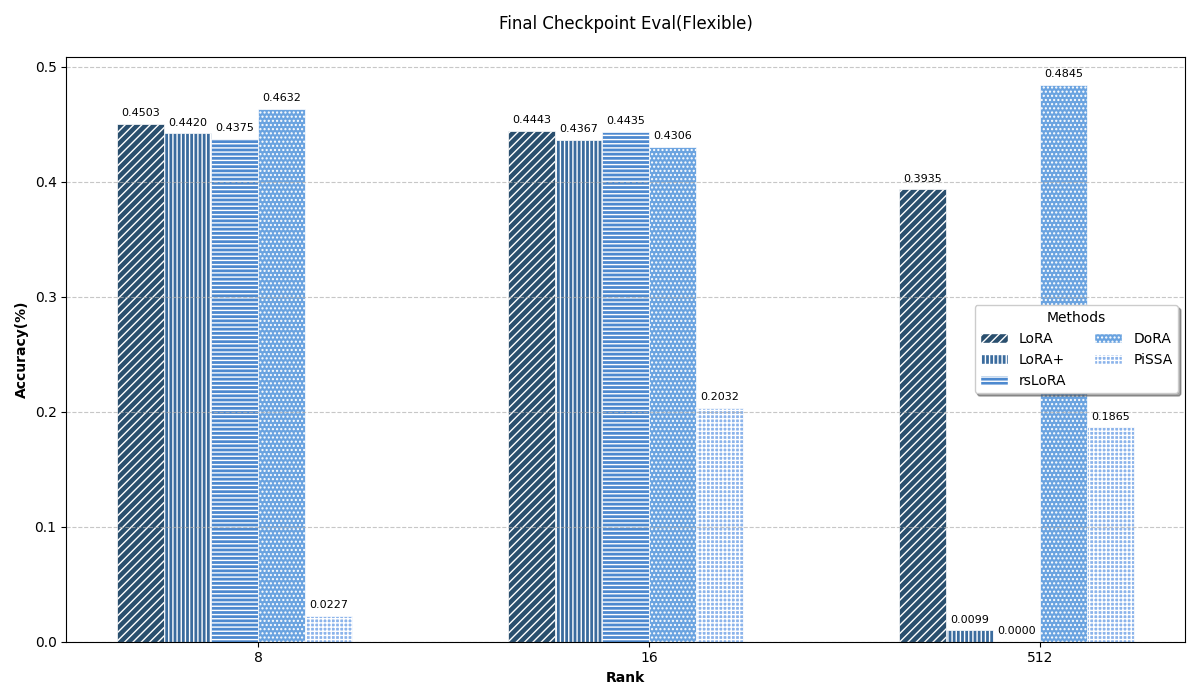
所有的结果以截图形式放在这里(原表格宽度太大会压缩得很丑)。


















 107
107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











