






前言
前几天我带大家用ControlNet插件中的Canny模型生成线稿图片,今天再向大家介绍一款叫做“animeLineartStyle"的线稿lora,看看用它的生成线稿图片效果如何。
注:本文所有图片均为AI绘画软件
stable diffusion 生成。
一、文生图,直接生成线稿图

这个图片用的底模为 max.ckpt,种子数为 214638109,正向tag见下方:
best quality, ultra-detailed, illustration, intricate details, 8k, highres, extremely detailed_eyes,
black eyes, long hair,Laughing_face, braided_bangs, white hair, hair ribbon, (blush:0.5), upper body,
(skyscraper:1.3),
(ambient light:1.3), depth of field, easynegative
* 1
* 2
* 3
* 4
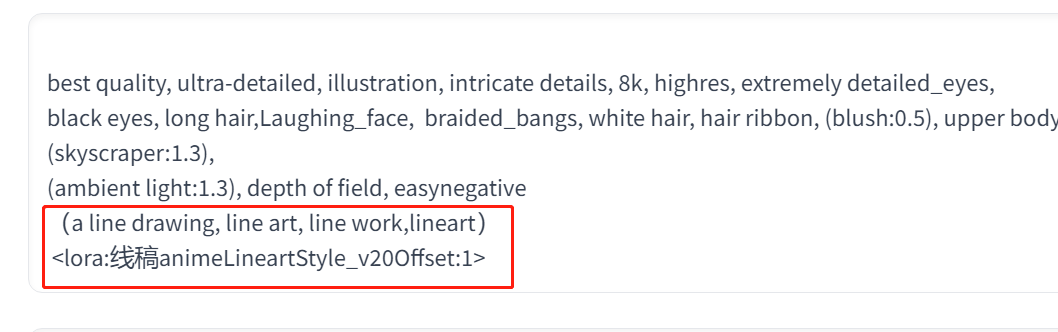
为了让这张照片产生线稿效果,我们还要加入一些线稿的提示词,然后再加入线稿lora:
线稿提示词:(a line drawing, line
art, line
work,lineart),具体正面 tag 见下图,有需要用提示词的朋友,可以点击图片后通过“转片转文字”获取提示词。
生成的线稿见下图。这个线稿效果还是比较不错的。图片中眼睛和嘴部还有颜色,想要解决这个问题我们可以将关键词中的含有颜色的关键词去掉,或者用PS去下色。而我觉得线稿中带一点颜色效果还不错,所以就不再花时间去处理它了。

变换种子数后,还可以得到如下图的线稿图

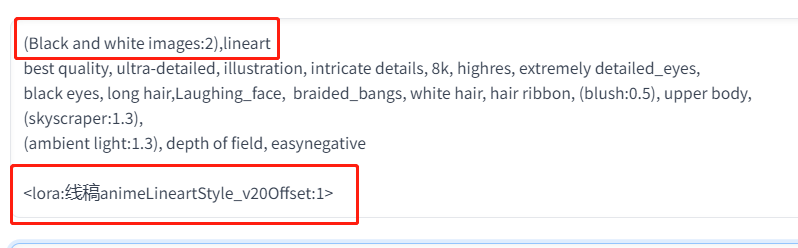
一、图生图,图片转成线稿图
还是刚刚的图片,我们点击图生图按钮,在图生图中,增加关键词:(Black and white
images:2),lineart,我们告诉AI,这是一个黑白图片,是一张线稿,最后再加入线稿的 lora。
具体tag写法见下图。
得到的线稿见下图。我们将原有图片转换成了具体线稿风格的图片,之所以颜色和嘴巴还有颜色,是因为我们用的图生图的原图片中眼睛和嘴巴颜色比较浓一些,可以调整重绘幅度来进行平衡,不过我觉得稍带点颜色也能接受,所以就不调了。

重绘幅度值的大小决定了生成图片多大程度遵从于原稿,如果重绘幅度值太小,线稿效果不明显,反之,如果便绘幅度值比较大,虽然线稿效果明显,但AI自由发挥的空间变大,相较原图变化会比较大,所以不同的数值还需要大家自己去测试,从而找到一个满意的效果。
下面这张是重绘幅度值调高后的效果,具体想要得到什么样的效果,大家自行取舍。

如果你喜欢这篇文章,多谢关注、点赞和评论,你的支持是我最大的动力。
但由于AIGC刚刚爆火,网上相关内容的文章博客五花八门、良莠不齐。要么杂乱、零散、碎片化,看着看着就衔接不上了,要么内容质量太浅,学不到干货。
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以长按下方二维码,免费领取!

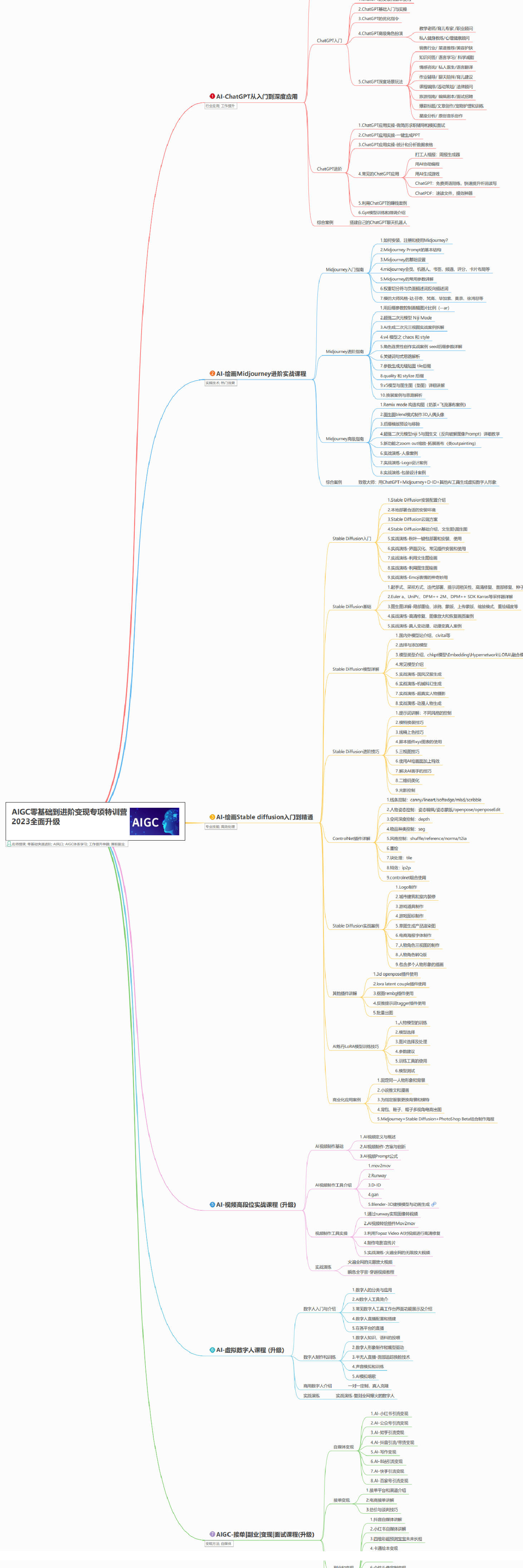
AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!
精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。

有需要的朋友,可以长按下方二维码,免费领取!















 1189
1189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









